发言人识别方法、装置、电子设备、存储介质及系统与流程
本发明涉及视频会议技术领域,具体涉及发言人识别方法、装置、电子设备、存储介质及系统。
背景技术:
在视频会议中为了保证会议效果,通常需要标记出会场中的发言人,那么就需要在与会者中识别出发言人。现有技术中一般是利用定焦镜头采集会场内的所有与会者的全景图像,确定与会者在会场内的位置;利用声源定位模块确定会场内的声源;利用声源与与会者在会场内的位置进行匹配,确定发言人;最后在全景图像中标识出发言人的图像。
然而,上述的发言人识别中,最后是在全景图像中标识出发言人的图像的,而对于与会者数量较多的会场中,即使在全景图像中标识出发言人的图像,与会者也不能准确地定位到发言人。基于此,发明人试图通过在会场内设置两个或两个以上的镜头,即定焦镜头与变焦镜头的组合,实现发言人的识别。但是,如何利用者两个镜头实现在高准确率和实时性的基础上识别出会场内的是亟待解决的问题。
技术实现要素:
有鉴于此,本发明实施例提供了一种发言人识别方法、装置、电子设备、存储介质及系统,以解决发言人识别的问题。
根据第一方面,本发明实施例提供了一种发言人识别方法,包括:
获取会场内的声源定位信息以及定焦镜头采集的全景图像;其中,所述声源定位信息为声源相对于声源定位模块的位置信息;
基于所述全景图像中人脸的位置信息,确定所述会场内的各个人脸相对于所述定焦镜头的位置信息,得到第一位置信息;
利用所述声源定位模块以及所述定焦镜头与变焦镜头的位置关系,将所述声源定位信息以及所述第一位置信息转换为所述声源以及所述会场内的各个人脸相对于所述变焦镜头的位置信息,分别得到第二位置信息以及第三位置信息;
根据所述第二位置信息以及所述第三位置信息,确定发言人以及所述变焦镜头的转动信息,以使得所述变焦镜头采集所述发言人的图像。
本实施例提供的发言人识别方法,利用声源定位模块以及定焦镜头与变焦镜头的位置关系,实现位置信息的转换,从而实现利用声源定位模块、定焦镜头与变焦镜头的配合识别出发言人;且由于在发言人的识别过程中主要处理的是位置信息的转换,保证了发言人识别的准确性和实时性,实现会场内发言人的精准切换,相比较传统的视频会议中发言人单一的摄像场景,能够做到言到人到,跟踪到说话的人物对象,增加视频会议终端的智能化。
结合第一方面,在第一方面第一实施方式中,所述基于所述全景图像中人脸图像的位置信息,确定所述会场内的各个人脸相对于所述定焦镜头的位置信息,得到第一位置信息,包括:
利用所述全景图像中人脸的位置信息,确定所述全景图像中的各个人脸中心点与所述全景图像中心点的位置关系;
获取所述定焦镜头的视场角以及所述全景图像的参数;
基于所述定焦镜头的视场角、所述全景图像的参数以及各个人脸中心点与所述全景图像中心点的位置关系,确定所述第一位置信息。
本实施例提供的发言人识别方法,基于定焦镜头的视场角确定会场内的人脸相对于定焦镜头的位置信息,该处理过程中仅涉及到定焦镜头的视场角、全景图像的参数,以及位置关系,利用较少的数据处理量就可以确定出第一位置信息,提高了发言人识别的实时性。
结合第一方面第一实施方式,在第一方面第二实施方式中,所述基于所述定焦镜头的视场角、所述全景图像的参数以及各个人脸中心点与所述全景图像中心点的位置关系,确定所述第一位置信息,包括:
利用所述定焦镜头的视场角、所述全景图像的参数以及各个人脸中心点与所述全景图像中心点的位置关系,确定所述会场内的各个人脸相对于所述定焦镜头的角度信息;
利用所述全景图像的参数以及所述定焦镜头的视场角,计算所述定焦镜头的焦距;
获取预设人脸高度;
利用所述预设人脸高度、所述定焦镜头的焦距以及所述全景图像的参数,计算所述会场内的各个人脸到所述定焦镜头的距离;
基于所述会场内的各个人脸到所述定焦镜头的距离以及会场内的各个人脸相对于所述定焦镜头的角度信息,确定所述会场内的各个人脸相对于所述定焦镜头的坐标信息。
本实施例提供的发言人识别方法,在确定出会场内的人脸相对于定焦镜头的角度信息之后,利用人脸高度、定焦镜头的焦距以及全景图像的参数,确定人脸相对于定焦镜头的坐标信息,而上述的人脸高度、定焦镜头的焦距以及全景图像的参数均是固定值,利用固定值直接进行坐标信息的确定,可以保证计算结果的准确性与实时性。
结合第一方面,在第一方面第三实施方式中,所述将所述声源定位信息以及所述第一位置信息转换为所述声源以及所述会场内的各个人脸相对于所述变焦镜头的位置信息,分别得到第二位置信息以及第三位置信息,包括:
利用所述声源定位模块与所述变焦镜头的位置关系,将所述声源定位信息转换为所述声源相对于所述变焦镜头的角度信息,得到所述第二位置信息;
利用所述定焦镜头与所述变焦镜头的位置关系,将所述第一位置信息转换为所述会场内的人脸相对于所述变焦镜头的坐标信息;
基于所述会场内的人脸相对于所述变焦镜头的坐标信息,确定所述会场内的各个人脸相对所述变焦镜头的角度信息,得到所述第三位置信息。
本实施例提供的发言人识别方法,在确定出会场内的人脸相对于所述变焦镜头的坐标信息之后,利用简单的数据处理就可以确定出对应的角度信息,减少了数据处理量,保证了第三位置信息确定的实时性。
结合第一方面,或第一方面第一实施方式至第三实施方式中任一项,在第一方面第四实施方式中,所述声源以及所述会场内的各个人脸相对于所述变焦镜头的位置信息包括所述声源以及所述会场内的各个人脸相对于所述变焦镜头的角度信息;其中,所述根据所述第二位置信息以及所述第三位置信息,确定发言人以及所述变焦镜头的转动信息,以使得所述变焦镜头采集所述发言人的图像,包括:
计算所述第二位置信息与所述第三位置信息的差值的绝对值;
判断所述差值的绝对值是否在预设范围内;
当所述差值的绝对值在预设范围内时,确定所述声源对应的人脸;
基于所述声源对应的人脸,确定所述发言人以及所述变焦镜头的转动信息,以使得所述变焦镜头采集所述发言人的图像。
本实施例提供的发言人识别方法,通过将声源对应的第二位置信息与人脸对应的第三位置信息进行差值比较,若误差的绝对值在预设范围内就确定为发言人,通过声源和定焦镜头采集的人脸图像进行比较,提高发言人识别的准确性。
结合第一方面第四实施方式,在第一方面第五实施方式中,所述基于所述声源对应的人脸,确定所述发言人以及所述变焦镜头的转动信息,以使得所述变焦镜头采集所述发言人的图像,包括:
基于所述声源对应的人脸相对于所述变焦镜头的角度信息,确定所述变焦镜头的转动信息;
获取转动后的所述变焦镜头采集的图像;
基于所述变焦镜头采集的图像中的人脸在所述采集的图像中的位置,确定所述发言人;
控制所述变焦镜头采集的所述发言人的图像。
本发明实施例提供的发言人识别方法,利用转动后的变焦镜头采集图像,再利用采集的图像中的人脸位置,再次进行发言人的确定,最终使得变焦镜头采集发言人的图像,提高了所采集的发言人图像的准确性。
结合第一方面第五实施方式,在第一方面第六实施方式中,所述控制所述变焦镜头采集的所述发言人的图像,包括:
获取所述发言人的图像;
判断所述发言人的图像中所述发言人的人脸区域的位置是否满足预设条件;
当所述发言人的图像中所述发言人的人脸区域的位置不满足预设条件时,调整所述变焦镜头以调整所述发言人的人脸区域在所述发言人的图像中的位置,确定所述发言人在所述变焦镜头中的图像;
显示所述发言人在所述变焦镜头中的图像。
本实施例提供的发言人识别方法,通过对变焦镜头进行微调,实现发言人的精确定位,保证了变焦镜头中发言人图像的人脸最优比。
根据第二方面,本发明实施例还提供了一种发言人识别装置,包括:
获取模块,用于获取会场内的声源定位信息以及定焦镜头采集的全景图像;其中,所述声源定位信息为声源相对于声源定位模块的位置信息;
第一确定模块,用于基于所述全景图像中人脸的位置信息,确定所述会场内的各个人脸相对于所述定焦镜头的位置信息,得到第一位置信息;
转换模块,用于利用所述声源定位模块以及所述定焦镜头与变焦镜头的位置关系,将所述声源定位信息以及所述第一位置信息转换为所述声源以及所述会场内的各个人脸相对于所述变焦镜头的位置信息,分别得到第二位置信息以及第三位置信息;
第二确定模块,用于根据所述第二位置信息以及所述第三位置信息,确定发言人以及所述变焦镜头的转动信息,以使得所述变焦镜头采集所述发言人的图像。
本发明实施例提供的发言人识别装置,利用声源定位模块以及定焦镜头与变焦镜头的位置关系,实现位置信息的转换,从而实现利用声源定位模块、定焦镜头与变焦镜头的配合识别出发言人;且由于在发言人的识别过程中主要处理的是位置信息的转换,保证了发言人识别的准确性和实时性,实现会场内发言人的精准切换,相比较传统的视频会议中发言人单一的摄像场景,能够做到言到人到,跟踪到说话的人物对象,增加视频会议终端的智能化。
根据第三方面,本发明实施例提供了一种电子设备,包括:存储器和处理器,所述存储器和所述处理器之间互相通信连接,所述存储器中存储有计算机指令,所述处理器通过执行所述计算机指令,从而执行第一方面或者第一方面的任意一种实施方式中所述的发言人识别方法。
根据第四方面,本发明实施例提供了一种计算机可读存储介质,所述计算机可读存储介质存储计算机指令,所述计算机指令用于使所述计算机执行第一方面或者第一方面的任意一种实施方式中所述的发言人识别方法。
根据第五方面,本发明实施例提供了一种视频会议系统,包括:
声源定位模块,用于确定会场内的声源定位信息;
定焦镜头,用于采集会场内的全景图像;
至少一个变焦镜头,用于采集发言人的图像;
本发明第三方面所述的电子设备,所述电子设备与所述声源定位模块、所述定焦镜头以及所述变焦镜头连接。
附图说明
为了更清楚地说明本发明具体实施方式或现有技术中的技术方案,下面将对具体实施方式或现有技术描述中所需要使用的附图作简单地介绍,显而易见地,下面描述中的附图是本发明的一些实施方式,对于本领域普通技术人员来讲,在不付出创造性劳动的前提下,还可以根据这些附图获得其他的附图。
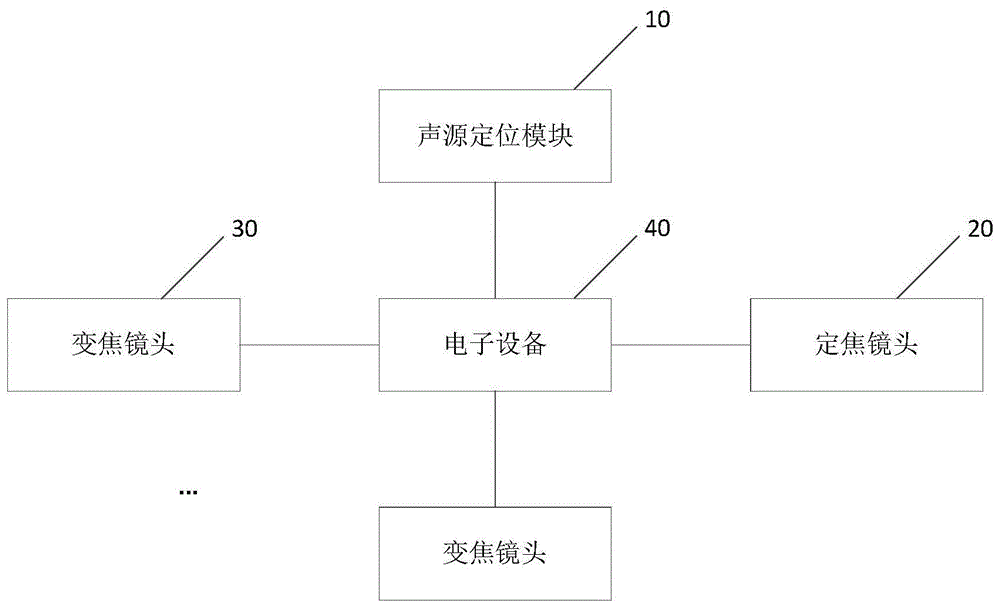
图1示出了本发明实施例中会议系统的结构图;
图2是根据本发明实施例的发言人识别方法的流程图;
图3是根据本发明实施例的发言人识别方法的流程图;
图4是根据本发明实施例的声源定位信息相对于声源定位模块的位置信息示意图;
图5是根据本发明实施例的人脸相对于定焦镜头的位置信息示意图;
图6是根据本发明实施例的人脸相对于变焦镜头的位置信息示意图;
图7是根据本发明实施例的发言人识别方法的流程图;
图8a-图8b是根据本发明实施例的确定发言人在变焦镜头中的图像示意图;
图9是根据本发明实施例的发言人识别装置的结构框图;
图10是本发明实施例提供的电子设备的硬件结构示意图。
具体实施方式
为使本发明实施例的目的、技术方案和优点更加清楚,下面将结合本发明实施例中的附图,对本发明实施例中的技术方案进行清楚、完整地描述,显然,所描述的实施例是本发明一部分实施例,而不是全部的实施例。基于本发明中的实施例,本领域技术人员在没有做出创造性劳动前提下所获得的所有其他实施例,都属于本发明保护的范围。
本发明实施例提供了一种会议系统,如图1所示,该会议系统包括:声源定位模块10、至少一个定焦镜头20、至少一个变焦镜头30以及电子设备40。其中,声源定位模块10、至少一个定焦镜头20、至少一个变焦镜头30以及电子设备40在会场内的设置位置可以根据实际情况进行相应的设置,一旦设置完成之后,可以将声源定位模块10、至少一个定焦镜头20、至少一个变焦镜头30与电子设备40之间的位置关系存储在电子设备40中,也可以存储在其他地方,当需要用到是电子设备从其他地方提取相应的位置关系。
其中,声源定位模块10、至少一个定焦镜头20以及至少一个变焦镜头30均与电子设备40连接。声源定位模块10用于对会场内的声源进行定位,确定声源相对于声源定位模块的位置信息得到声源定位信息,并将声源定位信息发送给电子设备40。定焦镜头20用于采集会场内的全景图像,并将全景图像发送给电子设备40,电子设备40基于全景图像中人脸的位置信息,确定会场内的各个人脸相对于定焦镜头的位置信息,得到第一位置信息。
电子设备40利用声源定位模块发送的声源定位信息,以及会场内的各个人脸相对于定焦镜头的位置信息,确定会场内的发言人。在确定发言人之后,控制变焦镜头采集发言人的图像。
其中,电子设备可以利用声源定位信息从至少一个变焦镜头中确定出一个变焦镜头用于后续发言人的图像采集;也可以是在确定出发言人之后,利用发言人的位置信息,从至少一个变焦镜头中确定出一个变焦镜头采集发言人的图像等等。
根据本发明实施例,提供了一种发言人识别方法实施例,需要说明的是,在附图的流程图示出的步骤可以在诸如一组计算机可执行指令的计算机系统中执行,并且,虽然在流程图中示出了逻辑顺序,但是在某些情况下,可以以不同于此处的顺序执行所示出或描述的步骤。
在本实施例中提供了一种发言人识别方法,可用于上述的电子设备,如电脑、平板电脑、服务器等,图2是根据本发明实施例的发言人识别方法的流程图,如图2所示,该流程包括如下步骤:
s11,获取会场内的声源定位信息以及定焦镜头采集的全景图像。
其中,所述声源定位信息为声源相对于声源定位模块的位置信息。
在视频会议中声源定位模块实时采集会场内的声源,得到会场内的声源定位信息,并将该声源声源定位信息发送给电子设备,相应地,电子设备就能够获取到会场内的声源定位信息。所述的声源定位信息可以认为是以声源定位模块为坐标原点,得到的声源的坐标信息和/或角度信息。
定焦镜头实时采集会场内的全景图像,并将采集到的全景图像发送给电子设备,相应地,电子设备就能够获取到会场内的全景图像。所述全景图像中包括会场内所有与会人员的人脸图像。
s12,基于全景图像中人脸的位置信息,确定会场内的各个人脸相对于定焦镜头的位置信息,得到第一位置信息。
电子设备在获取到会场内的全景图像之后,对全景图像进行人脸识别处理,确定全景图像中的人脸的位置信息。例如,可以将全景图像输入至人脸识别网络中,输出为全景图像中所有的人脸的位置信息,人脸的位置信息可以采用人脸对应的标识框的左上角坐标以及标识框的宽和高表示,也可以采用人脸对应的标识框的左上角坐标以及右下角坐标表示等等。
由于人脸在全景图像中的位置信息取决于人脸与定焦镜头的位置关系,那么电子设备就可以利用人脸在全景图像中的位置信息确定会场内的各个人脸相对于定焦镜头的位置信息,得到第一位置信息。关于该步骤具体将在下文中进行详细描述。
s13,利用声源定位模块以及定焦镜头与变焦镜头的位置关系,将声源定位信息以及第一位置信息转换为声源以及会场内的各个人脸相对于变焦镜头的位置信息,分别得到第二位置信息以及第三位置信息。
电子设备在上述s11中获取到声源相对于声源定位模块的位置信息,即,获取到以声源定位模块为坐标原点的声源的位置信息;电子设备在上述s12中得到会场内的人脸相对于定焦镜头的位置信息,即,获取到以定焦镜头为坐标原点的会场内的人脸的位置信息。
由于声源定位模块与变焦镜头的位置关系固定,且定焦镜头与变焦镜头的位置关系固定,那么电子设备就可以利用坐标平移的原理,分别将声源相对于声源定位模块的位置信息转换为以变焦镜头为坐标原点的位置信息,得到第二位置信息,将第一位置信息转换为以变焦镜头为坐标原的位置信息,得到第三位置信息。其中,会场内的每个人脸均对应于一个第三位置信息。
s14,根据第二位置信息以及第三位置信息,确定发言人以及变焦镜头的转动信息,以使得变焦镜头采集发言人的图像。
声源是来源于发言人的,声源相对于变焦镜头的位置信息,与发言人的人脸相对于变焦镜头的位置信息之间的误差是在预设范围内的。因此,电子设备就可以将会场内的各个人脸对应的第三位置信息与第二位置信息,确定会场内的发言人所在区域,再控制变焦镜头转动采集发言人所在区域的人脸图像,最终确认发言人的图像。
具体将在下文中对该步骤进行详细描述。
本实施例提供的发言人识别方法,利用声源定位模块以及定焦镜头与变焦镜头的位置关系,实现位置信息的转换,从而实现利用声源定位模块、定焦镜头与变焦镜头的配合识别出发言人;且由于在发言人的识别过程中主要处理的是位置信息的转换,保证了发言人识别的准确性和实时性,实现会场内发言人的精准切换,相比较传统的视频会议中发言人单一的摄像场景,能够做到言到人到,跟踪到说话的人物对象,增加视频会议终端的智能化。
在本实施例中提供了一种发言人识别方法,可用于上述的电子设备,如电脑、平板电脑、服务器等,图3是根据本发明实施例的发言人识别方法的流程图,如图3所示,该流程包括如下步骤:
s21,获取会场内的声源定位信息以及定焦镜头采集的全景图像。
其中,所述声源定位信息为声源相对于声源定位模块的位置信息。
图4示出了声源定位信息对应的坐标示意图,其中,原点0为声源定位模块的位置,p(x,y,z)表示声源的坐标。θ为声音水平角度,即波达方向与水平线夹角,θ为0-180°。
详细请参见图2所示实施例的s11,在此不再赘述。
s22,基于全景图像中人脸的位置信息,确定会场内的各个人脸相对于定焦镜头的位置信息,得到第一位置信息。
具体地,上述s22包括如下步骤:
s221,利用全景图像中人脸的位置信息,确定全景图像中的各个人脸中心点与全景图像中心点的位置关系。
如上文所述,电子设备在获取到全景图像之后,可以利用人脸识别网络识别出全景图像中人脸的位置信息,在得到位置信息之后,就可以确定出全景图像中各个人脸的中心点。由于定焦镜头所采集的全景图像的尺寸是固定的,电子设备可以确定出该全景图像的中心点位置。
电子设备在得到全景图像中各个人脸的中心点,以及全景图像的中心点之后,通过计算就可以得到全景图像中各个人脸的中心点到全景图像的中心点的垂直距离,以及全景图像中各个人脸的中心点到全景图像的中心点的水平距离。
例如,人脸的位置信息表示为:(x,y,w,h),其中,x为人脸的左上角坐标,y为人脸的右上角坐标,w为人脸的高度,h为人脸的宽度。电子设备根据人脸矩形区域可以得到人脸中心点坐标(fcenterx,fcentery):
fcenterx=x+w/2;
fcentery=y+h/2。
全景图像的中心点为(centerx,centery)。
人脸中心点与全景图像的中心点之间的水平距离为:fcenterx–centerx;
人脸中心点与全景图像的中心点之间的垂直距离为:fcentery–centery。
s222,获取定焦镜头的视场角以及全景图像的参数。
定焦镜头的视场角包括全景镜头的水平视场角以及全景镜头的垂直视场角,定焦镜头的视场角可以是存储在电子设备中,也可以是电子设备从外界获取到的。其中,所述的全景图像的参数为全景图像的高度以及宽度。
例如,水平视场角:angel_h=112.0,垂直视场角:angel_v=76.0。
s223,基于定焦镜头的视场角、全景图像的参数以及各个人脸中心点与全景图像中心点的位置关系,确定第一位置信息。
如图5所示,α为人脸相对于定焦镜头的垂直角度,β为定焦镜头的垂直视场角的一半,f为定焦镜头的焦距,fh为人脸中心点与全景图像的中心点的垂直距离,h为全景图像的宽度。
(1)利用定焦镜头的视场角、全景图像的参数以及各个人脸中心点与全景图像中心点的位置关系,确定会场内的各个人脸相对于定焦镜头的角度信息。
图5示出了计算人脸相对于摄像机的垂直角度的示意图,依据相似三角形原理,求出α就求出人脸相对于定焦镜头的垂直角度。如图5所示,根据三角函数计算:
tanα=fh/f,
tanβ=h/f,
tanα/tanβ=fh/h,
α=actan(tanβ*fh/h)。
其中,β、fh以及h均为已知参数,利用上述公式可以计算得到人脸相对于定焦镜头的垂直角度α。同理,可以利用定焦镜头的水平视场角的一半、人脸中心点与全景图像的中心点的水平距离以及全景图像的高度,可求出人脸相对于定焦镜头的水平角度。
(2)利用全景图像的参数以及定焦镜头的视场角,计算定焦镜头的焦距。
如图5所示,tanβ=h/f,那么定焦镜头的焦距f表示如下:
f=h/tanβ。
(3)获取预设人脸高度。
预设人脸高度可以是在电子设备中预先设置好的,也可以是电子设备从其他地方获取到的。其中,由于人脸的高度变化不大,可以将全景图像中的所有人脸的高度认为是相等的,估计为25cm。
(4)利用预设人脸高度、定焦镜头的焦距以及全景图像的参数,计算会场内的各个人脸到定焦镜头的距离。
根据相似三角形原理,
人脸高度/人脸到定焦镜头的实际距离=全景图像的宽度/定焦镜头的焦距。
相应地,可以得到如下表达式:
h/d=h/f,
由此就可求出人脸到定焦镜头的实际距离d,即d=h*f/h。
(5)基于会场内的各个人脸到定焦镜头的距离以及会场内的各个人脸相对于定焦镜头的角度信息,确定会场内的各个人脸相对于定焦镜头的坐标信息。
其中,人脸到定焦镜头的实际距离就相当于人脸的y坐标,即,y=h*f/h。
根据三角函数,就可以确定出人脸的x坐标,以及z坐标。
x=y/tan(180-α)
z=y/(sin(180-α)*tan(180-α'))
其中,α'为人脸相对于定焦镜头的水平角度。
由此即可确定出会场内的各个人脸相对于定焦镜头的坐标信息(x,y,z)。
在确定出会场内的人脸相对于定焦镜头的角度信息之后,利用人脸高度、定焦镜头的焦距以及全景图像的参数,确定人脸相对于定焦镜头的坐标信息,而上述的人脸高度、定焦镜头的焦距以及全景图像的参数均是固定值,利用固定值直接进行坐标信息的确定,可以保证计算结果的准确性与实时性。
s23,利用声源定位模块以及定焦镜头与变焦镜头的位置关系,将声源定位信息以及第一位置信息转换为声源以及会场内的各个人脸相对于变焦镜头的位置信息,分别得到第二位置信息以及第三位置信息。
具体地,上述s23包括如下步骤:
s231,利用声源定位模块与变焦镜头的位置关系,将声源定位信息转换为声源相对于变焦镜头的角度信息,得到第二位置信息。
图6示出了转换后的声源相对于变焦镜头的位置信息的示意图。其中,电子设备利用声源定位模块与变焦镜头的位置关系,即,利用坐标变换原理得到声源相对于变焦镜头的坐标信息(x',y',z'),再由声源相对于变焦镜头的坐标信息得到声源相对于变焦镜头的角度信息。具体如下所示:
π-θ'=actan(y/x')
其中,θ'为声源相对于变焦镜头的水平角度信息,
s232,利用定焦镜头与变焦镜头的位置关系,将第一位置信息转换为会场内的人脸相对于变焦镜头的坐标信息。
电子设备在上述s22中得到会场内的各个人脸相对于定焦镜头的位置信息,即会场内的各个人脸相对于定焦镜头的坐标信息。电子设备再利用定焦镜头与变焦镜头的位置关系,将会场内的各个人脸相对于定焦镜头的坐标信息转换为相对于变焦镜头的坐标信息。
s233,基于会场内的人脸相对于变焦镜头的坐标信息,确定会场内的各个人脸相对变焦镜头的角度信息,得到第三位置信息。
与上述声源定位信息的处理方式类似,电子设备再确定出会场内的人脸相对于变焦镜头的坐标信息之后,再利用三角函数的关系,确定会场内的各个人脸相对变焦镜头的角度信息,得到第三位置信息。
s24,根据第二位置信息以及第三位置信息,确定发言人以及变焦镜头的转动信息,以使得变焦镜头采集发言人的图像。
详细请参见图2所示实施例的s14,在此不再赘述。
本实施例提供的发言人识别方法,基于定焦镜头的视场角确定会场内的人脸相对于定焦镜头的位置信息,该处理过程中仅涉及到定焦镜头的视场角、全景图像的参数,以及位置关系,利用较少的数据处理量就可以确定出第一位置信息,提高了发言人识别的实时性。
在本实施例中提供了一种发言人识别方法,可用于上述的电子设备,如电脑、平板电脑、服务器等,图7是根据本发明实施例的发言人识别方法的流程图,如图7所示,该流程包括如下步骤:
s31,获取会场内的声源定位信息以及定焦镜头采集的全景图像。
其中,所述声源定位信息为声源相对于声源定位模块的位置信息。
详细请参见图3所示实施例的s21,在此不再赘述。
s32,基于全景图像中人脸的位置信息,确定会场内的各个人脸相对于定焦镜头的位置信息,得到第一位置信息。
详细请参见图3所示实施例的s22,在此不再赘述。
s33,利用声源定位模块以及定焦镜头与变焦镜头的位置关系,将声源定位信息以及第一位置信息转换为声源以及会场内的各个人脸相对于变焦镜头的位置信息,分别得到第二位置信息以及第三位置信息。
详细请参见图3所示实施例的s23,在此不再赘述。
s34,根据第二位置信息以及第三位置信息,确定发言人以及变焦镜头的转动信息,以使得变焦镜头采集发言人的图像。
具体地,上述s34包括如下步骤:
s341,计算第二位置信息与第三位置信息的差值的绝对值。
其中,第二位置信息用于表示声源相对于变焦镜头的角度信息,第三位置信息用于表示会场内的人脸相对于变焦镜头的角度信息。电子设备计算这两者角度信息的差值的绝对值。
s342,判断差值的绝对值是否在预设范围内。
当差值的绝对值在预设范围内时,说明说话的地方有检测到人脸,则执行s343;否则,提取下一个人脸相对于变焦镜头的位置信息,即提取下一个第三位置信息,执行s341。
s343,确定声源对应的人脸。
需要说明的是,此处检测到的人脸可能是一个,也可能大于1个。
s344,基于声源对应的人脸,确定发言人以及变焦镜头的转动信息,以使得变焦镜头采集发言人的图像。
电子设备在确定出声源对应的人脸之后,利用声源对应的人脸相对于变焦镜头的角度信息确定变焦镜头的转动信息。电子设备在确定出变焦镜头的转动信息之后,变焦镜头的云台转动采集发言人的图像。具体地,上述s344包括如下步骤:
(1)基于声源对应的人脸相对于变焦镜头的角度信息,确定变焦镜头的转动信息。
当声源对应的人脸为1个时,直接利用该人脸相对于变焦镜头的角度信息确定变焦镜头的转动信息;当声源对应的人脸大于1个时,就可以利用统计学的方式确定变焦镜头的转动信息,例如,可以计算声源对应的所有人脸的中心点,利用声源对应的所有人脸的一个中心点,确定变焦镜头的转动信息等等。
(2)获取转动后的变焦镜头采集的图像。
变焦镜头的云台基于上述步骤中确定出的转动信息进行转动,利用变焦镜头采集相应的图像并发送至电子设备。
当变焦镜头没有检测到人脸,则用变焦距镜头是人脸缩小,即zoomout;检测到人脸在1-3个之间则直接执行下述步骤(3);检测到人脸大于3个,则用变焦距镜头使人脸放大,即zoomin。
(3)基于变焦镜头采集的图像中的人脸在采集的图像中的位置,确定发言人。
如图8a所示,变焦镜头采集的图像中具有3个人脸,分别为人脸a、人脸b以及人脸c,电子设备计算各个人脸中心点与图像中心点(即,屏幕中心点)之间的距离,将距离最小的人脸确定人发言人的人脸。如图8a所示的人脸b。
(4)控制变焦镜头采集的发言人的图像。
电子设备在确定出人脸b为发言人的人脸之后,可以控制变焦镜头采集发言人的图像,也可以先对变焦镜头进行微调再采集发言人的图像。
利用转动后的变焦镜头采集图像,再利用采集的图像中的人脸位置,再次进行发言人的确定,最终使得变焦镜头采集发言人的图像,提高了所采集的发言人图像的准确性。
具体地,上述步骤(4)包括如下步骤:
4.1)获取发言人的图像。
如图8a所示,电子设备获取到变焦镜头采集的发言人的图像。
4.2)判断发言人的图像中发言人的人脸区域的位置是否满足预设条件。
如图8a所示,电子设备可以计算发言人的人脸区域在整个图像中的占比,以及人脸中心点与整个图像中心点之间的偏移,并判断其是否满足预设条件。例如,通过计算人脸b中心点以及宽高是否满足预设条件,当发言人的图像中发言人的人脸区域的位置不满足预设条件时,执行4.3);否则,执行4.4)。
4.3)调整变焦镜头以调整发言人的人脸区域在发言人的图像中的位置。
在发言人的图像中发言人的人脸区域的位置不满足预设条件时,电子设备调整变焦镜头,即对变焦镜头进行微调,以准确定位到发言人的人脸。
4.4)确定发言人在变焦镜头中的图像。
在变焦镜头微调之后,如图8b所示,确定发言人在变焦镜头中的图像,即人脸b。
4.5)显示发言人在变焦镜头中的图像。
在确定出发言人在变焦镜头中的图像之后,切换输出变焦镜头中的图像,即显示当前的发言人图像。
本实施例提供的发言人识别方法,通过将声源对应的第二位置信息与人脸对应的第三位置信息进行差值比较,若误差的绝对值在预设范围内就确定为发言人,通过声源和定焦镜头采集的人脸图像进行比较,提高发言人识别的准确性;且通过对变焦镜头进行微调,实现发言人的精确定位,保证了变焦镜头中发言人图像的人脸最优比。
在本实施例中还提供了一种发言人识别装置,该装置用于实现上述实施例及优选实施方式,已经进行过说明的不再赘述。如以下所使用的,术语“模块”可以实现预定功能的软件和/或硬件的组合。尽管以下实施例所描述的装置较佳地以软件来实现,但是硬件,或者软件和硬件的组合的实现也是可能并被构想的。
本实施例提供一种发言人识别装置,如图9所示,包括:
获取模块41,用于获取会场内的声源定位信息以及定焦镜头采集的全景图像;其中,所述声源定位信息为声源相对于声源定位模块的位置信息。
第一确定模块42,用于基于所述全景图像中人脸的位置信息,确定所述会场内的各个人脸相对于所述定焦镜头的位置信息,得到第一位置信息。
转换模块43,用于利用所述声源定位模块以及所述定焦镜头与变焦镜头的位置关系,将所述声源定位信息以及所述第一位置信息转换为所述声源以及所述会场内的各个人脸相对于所述变焦镜头的位置信息,分别得到第二位置信息以及第三位置信息。
第二确定模块44,用于根据所述第二位置信息以及所述第三位置信息,确定发言人以及所述变焦镜头的转动信息,以使得所述变焦镜头采集所述发言人的图像。
本实施例提供的发言人识别装置,利用声源定位模块以及定焦镜头与变焦镜头的位置关系,实现位置信息的转换,从而实现利用定焦镜头与变焦镜头的配合识别出发言人;且由于在发言人的识别过程中主要处理的是位置信息的转换,保证了发言人识别的准确性和实时性,实现会场内发言人的精准切换,相比较传统的视频会议中发言人单一的摄像场景,能够做到言到人到,跟踪到说话的人物对象,增加视频会议终端的智能化。
本实施例中的发言人识别装置是以功能单元的形式来呈现,这里的单元是指asic电路,执行一个或多个软件或固定程序的处理器和存储器,和/或其他可以提供上述功能的器件。
上述各个模块的更进一步的功能描述与上述对应实施例相同,在此不再赘述。
本发明实施例还提供一种电子设备,具有上述图9所示的发言人识别装置。
请参阅图10,图10是本发明可选实施例提供的一种电子设备的结构示意图,如图10所示,该电子设备可以包括:至少一个处理器51,例如cpu(centralprocessingunit,中央处理器),至少一个通信接口53,存储器54,至少一个通信总线52。其中,通信总线52用于实现这些组件之间的连接通信。其中,通信接口53可以包括显示屏(display)、键盘(keyboard),可选通信接口53还可以包括标准的有线接口、无线接口。存储器54可以是高速ram存储器(randomaccessmemory,易挥发性随机存取存储器),也可以是非不稳定的存储器(non-volatilememory),例如至少一个磁盘存储器。存储器54可选的还可以是至少一个位于远离前述处理器51的存储装置。其中处理器51可以结合图9所描述的装置,存储器54中存储应用程序,且处理器51调用存储器54中存储的程序代码,以用于执行上述任一方法步骤。
其中,通信总线52可以是外设部件互连标准(peripheralcomponentinterconnect,简称pci)总线或扩展工业标准结构(extendedindustrystandardarchitecture,简称eisa)总线等。通信总线52可以分为地址总线、数据总线、控制总线等。为便于表示,图10中仅用一条粗线表示,但并不表示仅有一根总线或一种类型的总线。
其中,存储器54可以包括易失性存储器(英文:volatilememory),例如随机存取存储器(英文:random-accessmemory,缩写:ram);存储器也可以包括非易失性存储器(英文:non-volatilememory),例如快闪存储器(英文:flashmemory),硬盘(英文:harddiskdrive,缩写:hdd)或固态硬盘(英文:solid-statedrive,缩写:ssd);存储器54还可以包括上述种类的存储器的组合。
其中,处理器51可以是中央处理器(英文:centralprocessingunit,缩写:cpu),网络处理器(英文:networkprocessor,缩写:np)或者cpu和np的组合。
其中,处理器51还可以进一步包括硬件芯片。上述硬件芯片可以是专用集成电路(英文:application-specificintegratedcircuit,缩写:asic),可编程逻辑器件(英文:programmablelogicdevice,缩写:pld)或其组合。上述pld可以是复杂可编程逻辑器件(英文:complexprogrammablelogicdevice,缩写:cpld),现场可编程逻辑门阵列(英文:field-programmablegatearray,缩写:fpga),通用阵列逻辑(英文:genericarraylogic,缩写:gal)或其任意组合。
可选地,存储器54还用于存储程序指令。处理器51可以调用程序指令,实现如本申请图2、3以及7实施例中所示的发言人识别方法。
本发明实施例还提供了一种非暂态计算机存储介质,所述计算机存储介质存储有计算机可执行指令,该计算机可执行指令可执行上述任意方法实施例中的发言人方法。其中,所述存储介质可为磁碟、光盘、只读存储记忆体(read-onlymemory,rom)、随机存储记忆体(randomaccessmemory,ram)、快闪存储器(flashmemory)、硬盘(harddiskdrive,缩写:hdd)或固态硬盘(solid-statedrive,ssd)等;所述存储介质还可以包括上述种类的存储器的组合。
虽然结合附图描述了本发明的实施例,但是本领域技术人员可以在不脱离本发明的精神和范围的情况下做出各种修改和变型,这样的修改和变型均落入由所附权利要求所限定的范围之内。
- 还没有人留言评论。精彩留言会获得点赞!