一种建议提案精确分类方法与流程
本发明涉及议案分类算法技术领域,特别涉及一种建议提案精确分类方法。
背景技术:
目前的代表建议提案工作中,已基本上实现了代表议案各个工作环节的信息化管理,在一定的时期内,为提高议案处理工作的效率起到了积极的作用。随着代表议案工作的不断深入,如何借助科学手段,提高对代表议案资源的充分利用、如何提高传统管理方式中一些业务处理、数据分析等工作环节(如议案查重、议案分类等)的工作效率,迫切需要新的信息化手段辅助解决。现有技术中对文本的分类方法准确率较低,导致工作效率低。
技术实现要素:
为了解决上述问题,本发明的目的在于提供一种建议提案精确分类方法。本发明通过构建文本表示模型、文本特征抽取、分类器模型,自动从海量非结构化的文本中获取到大量的有用信息,提高了建议提案的分类效率和准确率,为后续对议案进行管理、统计、查询、分析等工作提供了技术支撑。
本发明的上述目的通过以下技术方案实现:
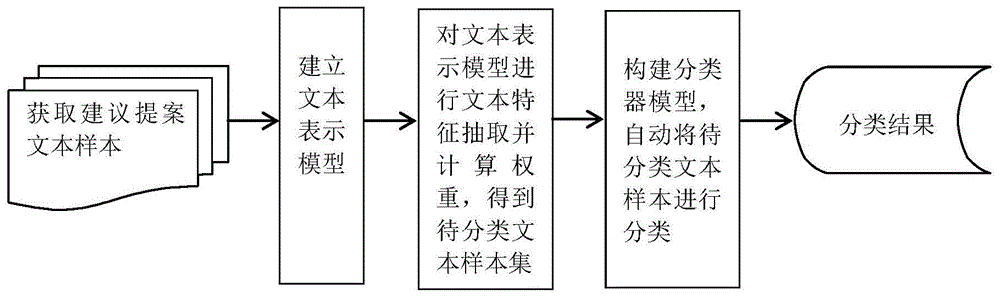
一种建议提案精确分类方法,具体包括以下步骤:
s1、获取建议提案文本样本;
s2、建立文本表示模型;
s3、对文本表示模型进行文本特征抽取并计算权重,得到待分类文本样本集;
s4、构建分类器模型,自动将文本样本进行分类,最终得到建议提案分类结果。
进一步地,所述步骤s1具体为:
获取建议提案文本样本,对所述文本样本进行数据清洗和去除噪声数据,获得干净的文本样本。
进一步地,所述步骤s2具体包括:
在向量空间模型中,对一个文本集合d,其中每一个文本d表示为向量
d=((t1:w1),(t2:w2),…,(tk:wk),…,(tn:wn))(1)
其中,tk(k=1,…,n)为文档空间的一个特征,wk为tk的权重,文本集合d可以看作是由一组正交词所构成的向量空间,构成文本表示模型;
进一步地,所述步骤s3具体包括:
假设,文本集合d中的一个文本片段s,由n个有序的词语构成,记为词语序列w1,w2,…,wn,选取词袋方法作为最基本的文本特征表示形式,词袋方法本身也是向量空间模型的基础,在这种文本特征表示方法中,假设各个词语间是相互独立的一维特征,这样文本片段s的特征集合即可表示为{w1,w2,…wn},权重公式表述为特征i在文本集合d中的权重wi,公式如下:
其中,tf表示特征i在文本集合d中出现的次数,idef为特征i在全部文档中出现的文本频数,n为全部文档总数,df为包含特征i的文档的个数;
式(2)反应了特征i在所有类中全部文档的分布情况,并不能体现该特征i在某一类中的额外信息,因此,将文件集合d中的文本随机分成两个训练集类,分别计算两个训练集类中的idf使idf局部化,然后对两个值进行相减操作,得到特征i在文本集合d中的权重,可以表示如下:
其中,n1和n2分别为两个训练集类内的文档总数,dfi,1和dfi,2分别指两个训练集类中包含特征i的文档总数;tfi表示特征i在文本集合d中出现的次数;
引入bm25模式,wi的表示模型如下:
其中,
进一步地,所述步骤s4具体包括以下步骤:
一、将步骤s3处理后的文本样本中的标点符号进行文本段划分,得到预处理后文本集,并建立一个主题词字典,包括初始的主题词类和非主题词类;
二、对预处理后文本集的所有特征进行分类计算,得到确定分类集和不确定分类集,具体为:
(1)采用公式(4)对预处理后文本集的所有特征进行特征得分计算,如果得分为正则先标记为positive,得分为负则先标记为negative;
(2)计算cmin=min(cpositive,cnegative),即计算标记为positive的文本数量和negative的文本数量中较少的一类文本数量,作为确定分类集中要取的文本数量;其中cpositive代表标记为正的文本数量,cnegative代表标记为负的文本数量;
(3)同时将预处理后文本集的所有特征根据步骤(1)计算得到的特征得分由大到小进行排序;
(4)特征极性标记:按照步骤(3)的特征得分排序结果,按照步骤(2)计算得到的文本数量cmin,在排序后的预处理文本集中取得分最高的cmin个文本和得分最低的cmin个文本,且将得分最高的cmin个文本标记为positive,得分最低的cmin个文本标记为negative,构成确定分类集,剩余其他的文本标记为不确定,构成不确定分类集;
三、将确定分类集的文本中的绝对词频大于2的所有特征词作为候选特征词扩充到主题词字典中,更新主题词字典,其中绝对词频的计算公式为
四、对不确定分类集的文本进行下一次分类计算,进入迭代过程,当主题词字典不再有扩充,分类结果不再变更的情况下,迭代过程结束,得到最终的分类集合,得到建议提案分类结果。
本发明的有益效果在于:本发明的分类方法不仅对一些有明确特征倾向的文本有较高的分类精确率,同时对于一些模棱两可的文本,即文本中既有positive的特征词,也有negative的特征词,以分类正确率高的一部分作为训练集,对其余得分居中,特征极性不确定的部分文本进行有效分类。从分类后得到的确定分类集中筛选得到候选特征词并更新到主题词字典中去,扩充后的主题词字典,可帮助分类更多的文本,在这个迭代的过程中,主题词字典和分类集被一次又一次的更新,能显著提高分类的精确率。
本发明通过构建文本表示模型、文本特征抽取、分类器模型,自动从海量非结构化的文本中获取到大量的有用信息,提高了建议提案的分类效率和准确率,为后续对议案进行管理、统计、查询、分析等工作提供了技术支撑。
附图说明
此处所说明的附图用来提供对本发明的进一步理解,构成本申请的一部分,本发明的示意性实例及其说明用于解释本发明,并不构成对本发明的不当限定。
图1为本发明的流程图;
图2为步骤s1的数据预处理示意图;
图3是步骤s4的分类器流程图;
具体实施方式
下面结合附图及具体实施例进一步说明本发明的详细内容及其具体实施方式。
实施例
参照图1,本实施例提供一种建议提案精确分类方法,具体包括以下步骤:
s1、获取建议提案文本样本;
s2、建立文本表示模型;
s3、对文本表示模型进行文本特征抽取并计算权重,得到待分类文本样本集;
s4、构建分类器模型,自动将文本样本进行分类,最终得到建议提案分类结果。
所述步骤s1具体为:
获取建议提案文本样本,收集到的数据可能会出现没有预先分类、议案标题为空或乱码等各种不同的情况,这些情况都会对分类效果有着负面的影响,因此需要对数据进行清洗和过滤,如图2所示,对所述文本样本进行数据清洗和去除噪声数据,获得干净的文本样本。
所述步骤s2具体包括:
在向量空间模型中,对一个文本集合d,其中每一个文本d表示为向量
d=((t1:w1),(t2:w2),…,(tk:wk),…,(tn:wn))(1)
其中,tk(k=1,…,n)为文档空间的一个特征,wk为tk的权重,文本集合d可以看作是由一组正交词所构成的向量空间,构成文本表示模型;
所述步骤s3具体包括:
对步骤2构成的文本表示模型进行文本特征抽取,文本转化成数学模型后,文本d往往是一个高维的空间,需要对特征进行选择,选出更具有代表性的特征,以达到降维的目的;此外,文本空间中的每个特征在各个文本向量中的重要程度各不相同,也需要对文本特征进行加权。
假设,文本集合d中的一个文本片段s,由n个有序的词语构成,记为词语序列w1,w2,…,wn,选取词袋方法作为最基本的文本特征表示形式,词袋方法本身也是向量空间模型的基础,在这种文本特征表示方法中,假设各个词语间是相互独立的一维特征,这样文本片段s的特征集合即可表示为{w1,w2,…wn},权重公式表述为特征i在文本集合d中的权重wi,公式如下:
其中,tf表示特征i在文本集合d中出现的次数,idef为特征i在全部文档中出现的文本频数,n为全部文档总数,df为包含特征i的文档的个数;
式(2)反应了特征i在所有类中全部文档的分布情况,并不能体现该特征i在某一类中的额外信息,因此,将文件集合d中的文本随机分成两个训练集类,分别计算两个训练集类中的idf使idf局部化,然后对两个值进行相减操作,得到特征i在文本集合d中的权重,可以表示如下:
其中,n1和n2分别为两个训练集类内的文档总数,dfi,1和dfi,2分别指两个训练集类中包含特征i的文档总数;tfi表示特征i在文本集合d中出现的次数;
引入bm25模式,wi的表示模型如下:
其中,
如图3所示,所述步骤s4具体包括以下步骤:
一、将步骤s3处理后的文本样本中的标点符号进行文本段划分,得到预处理后文本集,并建立一个主题词字典,包括初始的主题词类和非主题词类;
二、对预处理后文本集的所有特征进行分类计算,得到确定分类集和不确定分类集,具体为:
(1)采用公式(4)对预处理后文本集的所有特征进行特征得分计算,如果得分为正则先标记为positive,得分为负则先标记为negative;
(2)计算cmin=min(cpositive,cnegative),即计算标记为positive的文本数量和negative的文本数量中较少的一类文本数量,作为确定分类集中要取的文本数量;其中cpositive代表标记为正的文本数量,cnegative代表标记为负的文本数量;
(3)同时将预处理后文本集的所有特征根据步骤(1)计算得到的特征得分由大到小进行排序;
(4)特征极性标记:按照步骤(3)的特征得分排序结果,按照步骤(2)计算得到的文本数量cmin,在排序后的预处理文本集中取得分最高的cmin个文本和得分最低的cmin个文本,且将得分最高的cmin个文本标记为positive,得分最低的cmin个文本标记为negative,构成确定分类集,剩余其他的文本标记为不确定,构成不确定分类集;
三、将确定分类集的文本中的绝对词频大于2的所有特征词作为候选特征词扩充到主题词字典中,更新主题词字典,其中绝对词频的计算公式为
四、对不确定分类集的文本进行下一次分类计算,进入迭代过程,当主题词字典不再有扩充,分类结果不再变更的情况下,迭代过程结束,得到最终的分类集合,得到建议提案分类结果。
本发明的分类方法不仅对一些有明确特征倾向的文本有较高的分类精确率,同时对于一些模棱两可的文本,即文本中既有positive的特征词,也有negative的特征词,以分类正确率高的一部分作为训练集,对其余得分居中,特征极性不确定的部分文本进行有效分类。从分类后得到的确定分类集中筛选得到候选特征词并更新到主题词字典中去,扩充后的主题词字典,可帮助分类更多的文本,在这个迭代的过程中,主题词字典和分类集被一次又一次的更新,能显著提高分类的精确率。
以上所述仅为本发明的优选实例而已,并不用于限制本发明,对于本领域的技术人员来说,本发明可以有各种更改和变化。凡对本发明所作的任何修改、等同替换、改进等,均应包含在本发明的保护范围之内。
- 还没有人留言评论。精彩留言会获得点赞!