针对资源受限设备视频处理的深度学习网络裁剪方法与流程
本发明属于神经网络技术,具体为一种针对资源受限设备视频处理的深度学习网络裁剪方法。
背景技术:
传统深度学习在云端服务器进行处理,但面对海量数据的冲击,网络带宽和云服务器压力巨大,促使包括视频处理在内的智能计算从云端迈向端侧嵌入式设备。然而,嵌入式设备计算资源和存储资源有限,移动端难以承载较大规模的网络模型,较高的视频处理训练与推理时间,难以满足嵌入式平台的视频处理要求。深度强化学习(deepreinforcementlearning)能够减少主存占用开销,但是其cpu计算开销仍然较大,难以广泛在计算能力有限的嵌入式设备中进行部署。对于移动设备,部署学习技术面临资源有限的挑战。由于现代的神经网络众所周知是计算/内存密集型的,因此在移动设备上训练常规大小的网络的成本非常高。先前的工作建议使神经网络更轻量级,同时保持接近的性能。深度强化学习是视频处理中常用的算法,基于表格的rl将表中的学习结果保持在表格中,在处理具有高维特征的数据时可能会导致显着的内存开销。为了克服这个限制,“v.mnih,k.kavukcuoglu,d.silver,a.graves,i.antonoglou,d.wierstra,andm.riedmiller.playingatariwithdeepreinforcementlearning.inarxivpreprintarxiv:1312.5602,2013.”提出了一种深度rl模型,该模型被称为deep-q-network(dqn)。dqn采用神经网络函数逼近器来近似每个状态-动作对的q值。在深度监督学习方法中,假定所有样本都是独立的。但是,所有状态在强化学习中都高度相关。这给模型训练带来了挑战,因为高度相关的状态样本可能会影响后续状态-动作对的训练效率。
在目前的深度学习应用场景中,很难根据场景需求来制定合适的神经网络参数,例如隐层数目以及网络深度等。在这种情况下,通常的做法是设定足够复杂度的神经网络来确保计算能力足够强大以应对场景需求。在嵌入式边缘节点硬件框架中,由于计算资源有限,无法满足高复杂度的神经网络的需求。因此,多种神经网络的裁剪算法被推出。传统的神经网络裁剪算法可以被归为两类,非结构性裁剪算法和结构性裁剪算法。
(1)非结构性裁剪,如图1所示。该类裁剪需要消耗计算资源,算法所裁剪的权重不规则分布在整个权重空间中,只可以减少内存空间开销,而无法减少训练和预测开销。非结构化修剪方法来修剪多余的净重。一个简单的图示可以在图1中找到。这些方法有两个普遍的缺点。首先,修剪方法本身需要更多的计算,因此训练效率低下;其次,修剪后的权重会不规则地分布在权重矩阵上。结果,将这些方法直接应用于建议的框架是不适用的,因为增强学习(reinforcementlearning,rl)框架需要频繁更新神经网络权重。同时,这种量化只能减少内存使用,而无法获得实际的加速。原因是,修剪后的加权始终被视为零,而不是在计算过程中被消除。
(2)结构性裁剪,如图2所示。结构性裁剪算法能够解决非结构性裁剪算法的缺陷。该类算法将整个神经网络分成若干个组,对每个组使用grouplasso一次正则化进行稀疏处理。该方法无额外的计算开销,可以提升预测速度,但训练效率较低。结构化修剪方法通过在卷积层的通道或密集层的行和列的通道上应用组lasso来解决上述问题。这些基于正则化的方法可以结构化的稀疏性来加速网络,而不会产生任何不必要的计算成本。但是,这些方法不能提高网络的训练效率。
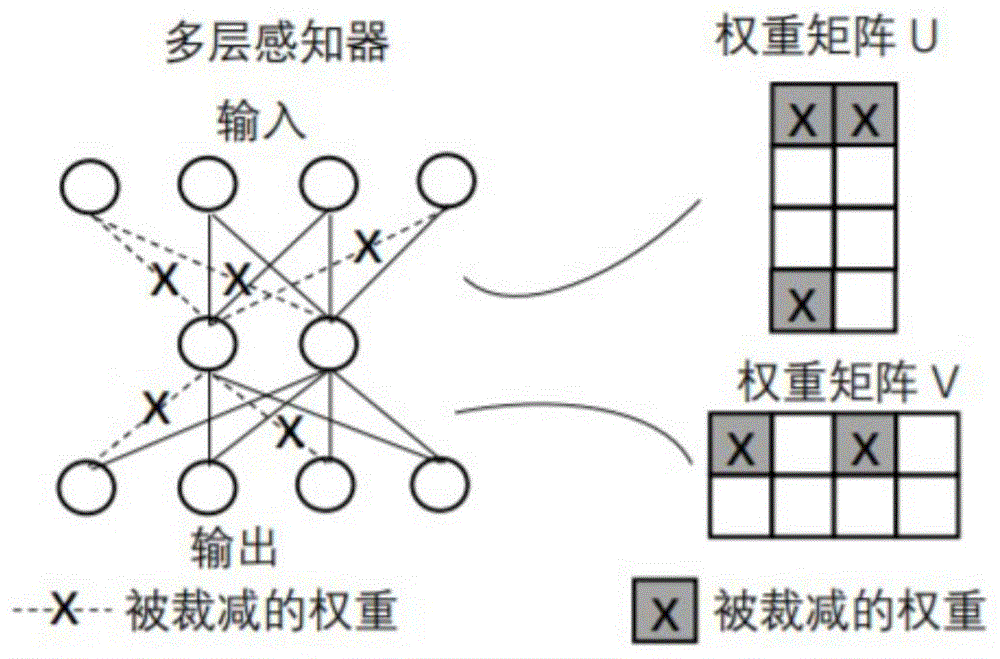
结构化修剪方法将隐藏表示定义为h=[h1;h2]。假定链接到h1的所有权重都通过结构化修剪方法修剪。因此h1,h1v1;1;h1v1;2;:::;h1v1;4均为零。但是,cpu/gpu并不知道这一点。结果,仍将计算由连接到h1的箭头表示的梯度,这将导致不必要的计算。由于rl方法要求经常更新净重,因此这些不必要的计算可能会显着影响mdrl(multi-objectivedeepreinforcementlearning)的训练效率。
技术实现要素:
本发明的目的在于提出了一种针对资源受限设备视频处理的深度学习网络裁剪方法。
实现本发明目的的技术解决方案为:一种针对资源受限设备视频处理的深度学习网络裁剪方法,具体步骤为:
步骤1:根据网络收敛精度,确定子网络个数;
步骤2:根据确定的子网络个数将深度学习网络分成若干个独立子网络;
步骤3:采用grouplasso算法对每个子网络进行稀疏化处理,使可裁剪的网络权重逼近0;
步骤4:计算每一个子网络的所有权重和,将权重和小于设定阈值的子网络进行裁剪。
优选地,根据网络收敛精度,确定子网络个数的具体方法为:
在深度学习网络训练过程中,从2开始递增子网络的个数,并确定对应的网络收敛精度,当网络收敛精度下降到设定阈值,停止递增,选择收敛精度高于设定阈值的子网络个数为确定子网络个数。
优选地,在训练过程中反向传播时,利用下式对子网络进行训练:
其中,l(θ)是稀疏化的训练目标,lo(θ),是神经网络原始训练方程,r(θ)是针对每一个网络权重θ的非结构化正则项,
本发明与现有技术相比,其显著优点为:
本发明能够对神经网络进行稀疏化裁剪,移除不必要的权重分支网络,通过本发明,提高了计算效率,降低了计算开销;
本发明针对嵌入式应用深度学习网络精度需求,评估网络裁剪对网络精度的影响,进而对网络进行裁剪,同时降低训练和预测的开销。
下面结合附图对本发明做进一步详细的描述。
附图说明
图1是非结构性裁剪方法示意图。
图2是结构性裁剪方法示意图。
图3是结构化修剪方法和本发明的比较示意图。
图4是全连接神经网络示意图。
图5为裁剪后的多路径多层次神经元架构示意图
具体实施方式
一种针对资源受限设备视频处理的深度学习网络裁剪方法,具体步骤为:
步骤1:根据网络收敛精度,学习子网络个数对收敛精度的影响,根据学习结果确定子网络个数;
进一步地,在深度学习网络训练过程中,从2开始递增子网络的个数,并确定对应的网络收敛精度,当网络收敛精度下降到设定阈值,停止递增,选择收敛精度高于设定阈值的子网络个数为确定子网络个数;
步骤2:根据确定的子网络个数将深度学习网络分成若干个独立子网络;
进一步地,对深度学习网络进行划分,使得子网络之间没有任何节点互相连接。如图5所示,其中,h11,h12,h21,h22为一个独立子网络,h13,h14,h23,h24为一个独立子网络。
经过子网络划分,获得彼此没有任何节点相连接的子网络区域。通过本步骤有效减少了网络权重的数目,例如,图4中有36个权重,而图5中仅有28个网络权重。
步骤3:对每个子网络进行稀疏化处理,使独立子网络权重低于设定阈值。
进一步地,采用grouplasso算法对每个子网络进行稀疏化处理。即,对每个子网络权重训练加上惩罚因子。
具体地,在训练过程中反向传播时,根据每一个子网络原有的训练公式,在这个训练公式后面加上l1正则项和l2正则项,即利用下式对子网络进行训练:
上述公式表示grouplasso稀疏算法的训练方程,其中l(θ)是稀疏化的训练目标,lo(θ)是神经网络原始训练方程,r(θ)是针对每一个网络权重θ的非结构化正则项,即l1正则项。
步骤4:计算每一个子网络的所有权重和,将权重和小于设定阈值的子网络进行裁剪。
如图3所示,本发明适用于深度强化网络的线上学习策略。由于线上学习策略需要实时训练和预测,传统裁剪算法,如结构性裁剪算法,只能减少神经网络的预测开销,无法减少训练开销。而本发明提出的算法则可以同时有效减少训练和预测开销,从而提高神经网络在嵌入式边缘节点的效率。
- 还没有人留言评论。精彩留言会获得点赞!