一种基于kafka的大数据报表统计的测试方法及其系统与流程
1.本发明涉及计算机通讯技术领域,特别是一种基于kafka的大数据报表统计的测试方法及其系统。
背景技术:
2.随着软件技术的不断更新迭代,更多的企业软件开始依赖借助于kafka数据消费的大数据平台来完成对自身产品使用情况的数据进行分析,它一方面呈现产品当前的运营情况,另一方面影响着产品未来的决策方向。因为其重要程度,在进行数据采集统计分析时的报表数据的准确性变得尤为重要。
3.例如1:统计类软件通过采集数据推送到kafka的对应集群,进行消费入库处理;例如2:搜索引擎类应用通过数据采集分析,可以过滤出用户关注度高的话题;例如3:电商类应用通过分析用户浏览行为,进行产品热度和销量详细分析进行推荐产品。
4.为保证各统计数据的准确性,数据统计算法在发布之前都会由测试人员进行数据准确性测试,目前该工作多有测试人员手工完成,仍存在以下缺点:(1)用户的数据采集需要大量的数据样本上报kafka采集消费后保存进数据库存储,但是在测试人员手中并无那么多用户数据可制造,对数据的采集和量级制造也存在一定的局限性。
5.(2)多个统计数据存在业务逻辑关联性,比如对所有设备下发一条指令的指令条数和设备的总数统计数据,应该需要保持一致性。因此,测试过程除了验证单一维度指标的准确性,还需要比对关联性统计维度数据的准确性,而人工测试时间和操作有限,很难在短时内完成相关联数据的对比,效率低下。
6.kafka是一个分布式消息队列。具有高性能、持久化、多副本备份、横向扩展能力。生产者往队列里写消息,消费者从队列里取消息进行业务逻辑。一般在架构设计中起到解耦、削峰、异步处理的作用。kafka对外使用topic的概念,生产者往topic里写消息,消费者从读消息。为了做到水平扩展,一个topic实际是由多个partition函数组成的,遇到瓶颈时,可以通过增加partition的数量来进行横向扩容。单个parition内是保证消息有序。每新写一条消息,kafka就是在对应的文件append写,所以性能非常高。
7.topic是消息中间件里一个重要的概念,每一个topic代表了一类消息,有了多个topic,就可以对消息进行归类与隔离。
技术实现要素:
8.为克服上述问题,本发明的目的是提供一种基于kafka的大数据报表统计的测试方法,将重复耗时的手工操作,通过自动化实现,提升了测试效率。
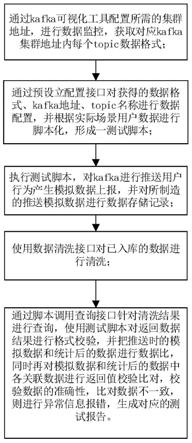
9.本发明采用以下方案实现:一种基于kafka的大数据报表统计的测试方法,所述测试方法包括如下步骤:
步骤s1、通过kafka可视化工具配置所需的集群地址,进行数据监控,获取对应kafka集群地址内每个topic数据格式;步骤s2、通过预设立配置接口对获得的数据格式、kafka地址、topic名称进行数据配置,并根据实际场景用户数据进行脚本化,形成一测试脚本;步骤s3、执行测试脚本,对kafka进行推送用户行为产生模拟数据上报,并对所制造的推送模拟数据进行数据存储记录;步骤s4、使用数据清洗接口对已入库的数据进行清洗;步骤s5、通过脚本调用查询接口针对清洗结果进行查询,使用测试脚本对返回数据结果进行格式校验,并把推送时的模拟数据和统计后的数据进行数据比,同时再对模拟数据和统计后的数据中各关联数据进行返回值校验比对,校验数据的准确性,比对数据不一致,则进行异常信息报错,生成对应的测试报告。
10.进一步的,所述步骤s1进一步具体为:通过kafka可视化工具配置所需的集群地址,进行数据监控,获取对应kafka集群地址内每个topic数据格式,把获取到的数据格式配置到接口的参数里面,通过请求进行测试数据模拟制造来得到后续需要的模拟数据。
11.进一步的,所述步骤s3进一步包括:测试脚本通过python代码编写实现,根据实际描述的场景,设置对应的请求参数类型和数值,传入指定的服务端接口内,进行网络请求,并传入服务端的数据库内供后续统计查询,即设置n台设备上报设备名称场景,则根据前文所解析的设备名称数据格式,编写对应的数据格式name取n个不同的值进行设置执行次数n次,传入指定的服务端接口,进行网络请求,把用例所编写的n条设备名称模拟数据信息通过接口传入kafka对应topic,服务端针对收到的测试数据消息进行消费后保存到数据库进行数据存储,预期数据库内新增n个设备名称的测试数据,供后续统计查询使用,n为正整数。
12.本发明还提供了一种基于kafka的大数据报表统计的测试系统,所述测试系统包括:配置模块、测试脚本生成模块、模拟数据上报模块、数据清洗模块、以及校验模块;所述配置模块,用于通过kafka可视化工具配置所需的集群地址,进行数据监控,获取对应kafka集群地址内每个topic数据格式;所述测试脚本生成模块,通过预设立配置接口对获得的数据格式、kafka地址、topic名称进行数据配置,并根据实际场景用户数据进行脚本化,形成一测试脚本;所述模拟数据上报模块,用于执行测试脚本,对kafka进行推送用户行为产生模拟数据上报,并对所制造的推送模拟数据进行数据存储记录;所述数据清洗模块,使用数据清洗接口对已入库的数据进行清洗;所述校验模块,通过脚本调用查询接口针对清洗结果进行查询,使用测试脚本对返回数据结果进行格式校验,并把推送时的模拟数据和统计后的数据进行数据比,同时再对模拟数据和统计后的数据中各关联数据进行返回值校验比对,校验数据的准确性,比对数据不一致,则进行异常信息报错,生成对应的测试报告。
13.进一步的,所述配置模块的实现方式进一步具体为:通过kafka可视化工具配置所需的集群地址,进行数据监控,获取对应kafka集群地址内每个topic数据格式,把获取到的数据格式配置到接口的参数里面,通过请求进行测试数据模拟制造来得到后续需要的模拟数据。
14.进一步的,所述模拟数据上报模块进一步包括:测试脚本通过python代码编写实现,根据实际描述的场景,设置对应的请求参数类型和数值,传入指定的服务端接口内,进行网络请求,并传入服务端的数据库内供后续统计查询,即设置n台设备上报设备名称场景,则根据前文所解析的设备名称数据格式,编写对应的数据格式name取n个不同的值进行设置执行次数n次,传入指定的服务端接口,进行网络请求,把用例所编写的n条设备名称模拟数据信息通过接口传入kafka对应topic,服务端针对收到的测试数据消息进行消费后保存到数据库进行数据存储,预期数据库内新增n个设备名称的测试数据,供后续统计查询使用,n为正整数。
15.本发明的有益效果在于:1、该种测试方法将重复耗时的手工操作,通过自动化实现,释放了人力,提升了测试效率。
16.2、有效的做了一个创建,突破了以往的测试局限,能够对基于kafka实现的大数据统计功能数据准确性测试提供保障。
17.3、测试结果信息完整,数据结果明了,便于基于kafka大数据处理功能的测试结果提供数据。
附图说明
18.图1是本发明的方法流程示意图。
19.图2是本发明一实施例的流程示意图。
20.图3是本发明的系统原理框图。
具体实施方式
21.下面结合附图对本发明做进一步说明。
22.请参阅图1所示,本发明的一种基于kafka的大数据报表统计的测试方法,所述测试方法包括如下步骤:步骤s1、通过kafka可视化工具配置所需的集群地址,进行数据监控,获取对应kafka集群地址内每个topic数据格式;步骤s2、通过预设立配置接口对获得的数据格式、kafka地址、topic名称进行数据配置,并根据实际场景用户数据进行脚本化,形成一测试脚本;步骤s3、执行测试脚本,对kafka进行推送用户行为产生模拟数据上报,并对所制造的推送模拟数据进行数据存储记录;步骤s4、使用数据清洗接口对已入库的数据进行清洗;步骤s5、通过脚本调用查询接口针对清洗结果进行查询,使用测试脚本对返回数据结果进行格式校验,并把推送时的模拟数据和统计后的数据进行数据比,同时再对模拟数据和统计后的数据中各关联数据进行返回值校验比对,校验数据的准确性,比对数据不一致,则进行异常信息报错,生成对应的测试报告。
23.下面结合一具体实施例对本发明作进一步说明:请参阅图2所示,本发明的一种基于kafka的大数据报表统计的测试方法,该测试方法为:1. 通过kafka tool配置所需的集群地址,监控获取其中每个topic内的数据json格式进行解析获取每个约定的参数字段 (参数字段指客户端和服务端进行数据传输的时候约
定好的数据格式,比如:服务端功能需要统计设备名称,则客户端就需要上传服务端的时候,通过网络请求传入这个设备名称name的参数字段,服务端进行保存数据库里,才可以正常的查询到这个name的统计信息,这是程序开发人员设计约定好的一种数据格式,即该参数字段为需要采集的数据参数);把获取到的数据格式配置到接口的参数里面,通过请求进行测试数据模拟制造来得到后续需要的模拟数据(如:获取到的数据格式解析得到的格式,配置到接口的参数里面,通过请求进行测试数据模拟制造。比如:获取到了测试设备a1上报到kafka里的数据格式,捕获这个格式后,进行模拟该格式a2、a3...a(n)数据信息推送kafka里至服务端,制造这种测试数据。)。
24.2. 通过脚本调用预先设立配置对应的kafka地址和topic名称接口进行数据配置,并根据实际场景用户数据进行数据制造算法脚本的设计编写 (该脚本通过python代码编写实现),进行测试用例化;3. 执行算法脚本运行测试用例,对kafka进行推送用户行为产生数据模拟上报,并对所制造的推送数据进行数据存储记录;即根据实际描述的场景,设置对应的请求参数类型和数值,传入指定的服务端接口内,进行网络请求,并传入服务端的数据库内供后续统计查询,即设置n台设备上报设备名称场景,则根据前文所解析的设备名称的数据格式,编写对应的数据格式name取n个不同的值进行设置执行次数n次,传入指定的服务端接口,进行网络请求,把用例所编写的n条(如n=1000)设备名称模拟数据信息通过接口传入kafka对应topic,服务端针对收到的测试数据消息进行消费后保存到数据库进行数据存储,预期数据库内新增n个设备名称的测试数据(即写入了n条的模拟数据),供后续统计查询使用,n为正整数。(如:通过python语言进行脚本代码编写,配置请求所需要的数据;比如:真实用户场景是在1000(n)台移动设备上报使用数据进行数据统计,则可使用代码根据测试用例场景,模拟移动上报数据请求1000(n)条进行编写。通过python代码进行http接口请求,设置参数1000(n)执行次数,通过循环算法进行测试数据模拟制造1~n,然后进行脚本的测试用例执行,对最终查询到的结果和预写的1000(n)进行对比,验证前后数据正确性。)4. 使用服务端接口调用数据清洗算法对已入库的数据进行清洗;(数据清洗算法是服务端开发人员通过程序代码实现提供的一种对数据库数据进行统计保存的接口,比如:用户需要查询每日设备的总数功能,则设计清洗算法把每日0点后至次日0点前所接收的数据库进行查询计算,并返回每日时间内的所保存进数据库的设备数量。即通过代码对保存数据库内的数据进行一个清洗计算。)5. 通过脚本调用查询接口针对清洗结果进行查询,使用脚本对返回数据结构进行格式校验,并把统计结果和步骤3里的创建输入数据(即模拟数据)进行比对,验证是否和输入一致,数量不一致返回步骤3;一致,继续步骤6;6. 通过脚本调用具有关联性数据查询接口,不同且具有关联性的接口的根据数据特性进行关联数据一致性比对,进行返回值校验比对(即(关联性数据,比如:数量维度上看,预写测试场景的时候设置了n条数据制造,那么测试结果所统计得到的数据量和这个n是对应关系的,推送了n那么预期也应该是n,则是正确的结果;返回值是指服务端所需要进行测试的接口,服务端对数据库查询后返回的一个数据,可通过脚本去请求接口进行数据库查询结果的获取,并验证功能正确性);数量不一致返回3步骤;7. 生成测试报告至指定路径,根据测试报告结果判断数据准确性是否正常,报告正
常,则测试通过;报告异常,则进行错误排查。
25.请参阅图3所示,本发明还提供了一种基于kafka的大数据报表统计的测试系统,所述测试系统包括:配置模块、测试脚本生成模块、模拟数据上报模块、数据清洗模块、以及校验模块;所述配置模块,用于通过kafka可视化工具配置所需的集群地址,进行数据监控,获取对应kafka集群地址内每个topic数据格式;所述测试脚本生成模块,通过预设立配置接口对获得的数据格式、kafka地址、topic名称进行数据配置,并根据实际场景用户数据进行脚本化,形成一测试脚本;所述模拟数据上报模块,用于执行测试脚本,对kafka进行推送用户行为产生模拟数据上报,并对所制造的推送模拟数据进行数据存储记录;所述数据清洗模块,使用数据清洗接口对已入库的数据进行清洗;所述校验模块,通过脚本调用查询接口针对清洗结果进行查询,使用测试脚本对返回数据结果进行格式校验,并把推送时的模拟数据和统计后的数据进行数据比,同时再对模拟数据和统计后的数据中各关联数据进行返回值校验比对,校验数据的准确性,比对数据不一致,则进行异常信息报错,生成对应的测试报告。
26.其中,所述配置模块的实现方式进一步具体为:通过kafka可视化工具配置所需的集群地址,进行数据监控,获取对应kafka集群地址内每个topic数据格式,把获取到的数据格式配置到接口的参数里面,通过请求进行测试数据模拟制造来得到后续需要的模拟数据。
27.进一步的,所述模拟数据上报模块进一步包括:测试脚本通过python代码编写实现,根据实际描述的场景,设置对应的请求参数类型和数值,传入指定的服务端接口内,进行网络请求,并传入服务端的数据库内供后续统计查询,即设置n台设备上报设备名称场景,则根据前文所解析的设备名称数据格式,编写对应的数据格式name取n个不同的值进行设置执行次数n次,传入指定的服务端接口,进行网络请求,把用例所编写的n条设备名称模拟数据信息通过接口传入kafka对应topic,服务端针对收到的测试数据消息进行消费后保存到数据库进行数据存储,预期数据库内新增n个设备名称的测试数据,供后续统计查询使用,n为正整数。
28.总之,本发明通过kafka监控获取每个topic的数据解析格式,把约定的数据格式通过预先设立的接口配置到指定对应的kafka地址和topic里,再通过脚本配置进行数据模拟预写,并且根据项目的用户数据实际量级执行脚本直接对kafka进行数据推送,并且对所制造的推送模拟数据进行数据存储,kafka收到模拟数据(不同场景数据使用上报)进行消费入库存储。通过数据清洗算法对已入库的数据进行清洗后查询统计返回结果,通过脚本调用具有关联性数据查询接口,把推送时的模拟数据和统计后的数据进行数据比,同时再对把各关联数据进行返回值校验比对,校验数据的准确性,比对数据不一致,则进行异常信息报错,生成对应的测试报告。
29.以上所述仅为本发明的较佳实施例,凡依本发明申请专利范围所做的均等变化与修饰,皆应属本发明的涵盖范围。
相关技术
网友询问留言
已有0条留言
- 还没有人留言评论。精彩留言会获得点赞!
1