参数自适应的光伏功率爬坡事件的分级概率性预测方法与流程
本发明属于电力系统预测与控制技术领域,具体涉及一种参数自适应的光伏功率爬坡事件的分级概率性预测方法。
背景技术:
随着经济的快速发展,全球能源短缺、生态恶化等问题日益突出,为了应对传统化石能源的短缺以及全球范围内严峻的环境问题,以光伏发电为代表的大规模可再生能源并网发电在在电力系统装机容量中的占比越来越大。光伏发电受太阳辐射强度、温度、风速、湿度等自然条件影响,因而具有强烈的间隙性和波动性,极易发生光伏功率爬坡事件,即在较短时间内光伏功率发生大幅度的变化,这种大幅度的变化会造成电网波动,严重时影响系统的稳定运行,甚至导致大面积停电事故,从而产生重大经济损失。因此,光伏功率爬坡事件的准确预测和安全预警在电力系统安全、平稳、经济运行过程具有重要意义。
传统的光伏功率爬坡事件预测属于一种“事件预测”,主要分为间接预测法和直接预测法。目前广泛使用的是间接预测法,以光伏功率为预测对象,在此基础上识别爬坡事件,该类方法在进行光伏功率预测过程中,为提高整体预测精度,往往会忽略极端数据,从而导致爬坡信息的丢失;直接预测法根据历史爬坡数据,以光伏爬坡率作为预测对象,根据阈值判断是否发生爬坡事件。无论是直接预测还是间接预测,目前的光伏功率爬坡事件预测方法大多根据光伏功率爬坡定义,预测是否发生爬坡事件,均属于确定性预测,难以度量预测过程中的不确定性。
技术实现要素:
本发明是为了解决上述现有技术存在的不足之处,提出一种参数自适应的光伏功率爬坡事件的分级概率性预测方法,以期能对光伏功率不同程度的爬坡事件进行分级概率性预测与度量,从而能针对各类爬坡事件采取相应的控制策略,降低爬坡事件对电力系统的不利影响,为电力系统的经济调度、安全运行提供有力支撑。
本发明为达到上述发明目的,采用如下技术方案:
本发明一种参数自适应的光伏功率爬坡事件的分级概率性预测方法的特点在于,包括以下步骤:
s1)获取光伏功率数据及其影响因子并进行预处理,从而得到预处理后的数据集,包括:预处理后的光伏功率{p(t)}t=1,2,...,t和光伏功率的s个影响因子{fs(t)}s=1,2,...,s;t=1,2,...,t,其中,p(t)和fs(t)分别为第t个时间点的光伏功率及相应第t个时间点的第s个影响因子的数据;
从所述预处理后的数据集中提取光伏功率{p(t)}t=1,2,...,t,并根据爬坡事件的定义,计算t个时间点的光伏爬坡率{r(t)}t=1,2,...,t,其中,r(t)表示第t个时间点的光伏爬坡率;
s2)利用vmd方法将光伏爬坡率{r(t)}t=1,2,...,t分解成k个本征模态分量{rk(t)}k=1,2,...,k;t=1,2,...,t,且满足
定义优化的参数组合为<k,α>,α表示vmd方法求解过程中的惩罚因子,k表示vmd分解出的本征模态分量个数;
以k个本征模态分量{rk(t)}k=1,2,...,k;t=1,2,...,t的能量熵之和作为适应度函数,利用pso算法对参数组合<k,α>进行寻优;
获取最小适应度函数值所对应的最优参数组合<k0,α0>,从而根据所述最优参数组合<k0,α0>,利用vmd方法计算得到t个时间点的光伏爬坡率{r(t)}t=1,2,...,t的最佳本征模态分量
s3)利用第k个本征模态分量
将所述数据集[xk(t),yk(t)]t=p+1,p+2,...,t划分为训练集
建立lasso-qr预测模型,利用非对称损失函数建立如式(1)所示的目标函数:
式(1)中,τh表示第h个分位点,且τh∈(0,1),h=1,2,...,h,h表示分位点的数量;βk(τh)表示第k个本征模态分量所对应的lasso-qr预测模型中第h个分位点下解释变量的系数集合,
式(1)中,
式(2)中,v为随机变量,在式(1)的目标函数中,v满足:
式(1)中,η为l1正则化惩罚参数;
利用式(4)将所述lasso-qr预测模型的目标函数转化成线性不等式约束规划问题:
式(4)中,γ是与η对应的约束参数;
利用lars算法在所述训练集train上对式(4)进行求解,获得训练后的lasso-qr预测模型;
将所述测试集test中的解释变量
s4)根据步骤s3,对每个本征模态分量分别建立lasso-qr预测模型并训练,从而得到k个本征模态分量在h个分位点下的条件分位数预测结果
利用式(5)将相同分位点下的条件分位数预测结果相加,从而得到第t个时间点第h个分位点下的条件分位数最终预测结果qh(t),进而得到第t个时间点h个分位点下的条件分位数最终预测结果{qh(t)}h=1,2,...,h:
将h个分位点下的条件分位数最终预测结果{qh(t)}h=1,2,...,h作为核密度估计kde方法的输入,并确定带宽与核函数,从而求得每个时间点的概率密度函数;
将每个时间点的概率密度函数离散化,从而得到第t个时间点的j个预测值{rj(t)}j=1,2,...,j以及相应的概率{πj(t)}j=1,2,...,j,其中,rj(t)和πj(t)分别为第t个时间点的第j个预测值及其对应的概率,且r1(t)≤r2(t)≤...≤rj(t);
s5)将光伏功率爬坡事件分成未爬坡事件、上爬坡事件以及下爬坡事件,并将上爬坡事件和下爬坡事件分别设置i个等级,最小程度的上爬坡事件和下爬坡事件分别为1级,最大程度上爬坡事件和下爬坡事件分别为i级;
设置i+1个阈值集合{δi}i=1,2,...,i+1,则各类爬坡事件的判断依据如式(7)所示:
式(7)中,δi和δi+1分别为i级上爬坡事件的阈值下限和阈值上限,-δi+1和-δi分别为i级下爬坡事件的阈值下限和阈值上限;
针对第t个时间点的j个预测值{rj(t)}j=1,2,...,j,根据所述判断依据确定每个预测值所在的阈值区间,并计算各个区间内的预测值对应的概率之和,即为该相应时刻点各类爬坡事件发生的概率。
与现有技术相比,本发明的有益效果在于:
1.本发明利用vmd方法对具有高度波动性和非平稳性的光伏爬坡率进行分解,可以全面分析和利用光伏功率的数据信息,获得一系列简单平稳的子序列,解决了当前光伏爬坡率难以有效预测的难题;并结合pso优化算法进行寻优,获得了最佳分解结果,实现了vmd方法的参数自适应,针对不同数据无需进行重复调参来获取最优结果,为电力系统运行提供了便利;
2.本发明建立lasso-qr预测模型对光伏功率爬坡率进行预测分析;qr模型能够克服传统均值回归无法全面分析响应变量的缺点,有效刻画光伏爬坡率的整体分布特征,得到更为全面的预测结果,从而降低了爬坡事件错误预报的风险;同时,光伏爬坡率预测问题建模中存在大量复杂多变的气象数据影响因子,在qr模型的基础上增加l1正则化惩罚项,将部分对光伏爬坡率没有影响或者影响较小的变量系数压缩为0,不仅大幅度地节约了时间成本,同时也避免了模型过拟合,提高了光伏爬坡率的预测精度,提高了爬坡事件正确预报的概率;
3.本发明结合kde方法,实现了光伏爬坡率的非参数概率性预测,有效度量了爬坡事件预测结果的不确定;同时,对爬坡事件进行不同程度的划分,将传统的爬坡事件预测的二分类问题转化成分级概率性预测问题,实现了光伏功率爬坡事件的分级概率性预报。
附图说明
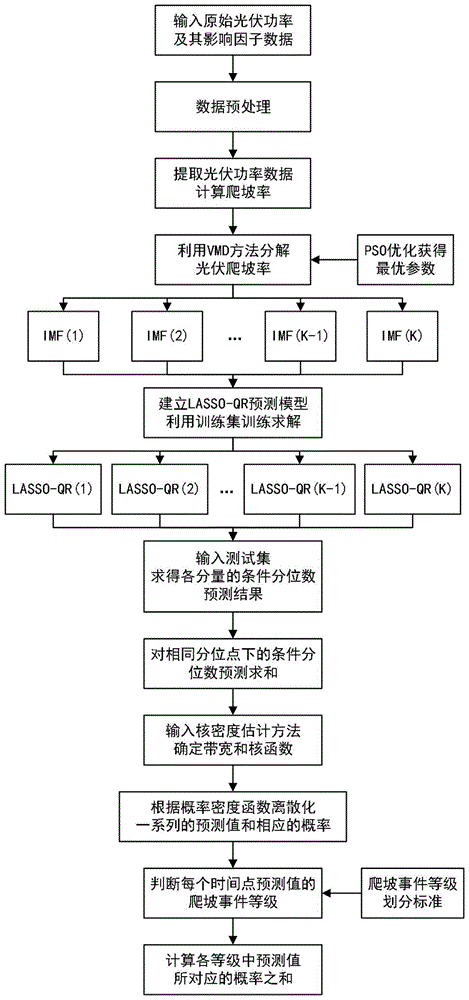
图1为本发明的整体流程图;
图2为本发明参数自适应的vmd分解流程图。
具体实施方式
下面结合具体实施案例对本专利的技术方案做进一步详细地说明。
如图1所示,一种参数自适应的光伏功率爬坡事件的分级概率性预测方法,包括如下步骤:
s1)获取光伏功率数据及其影响因子,包括太阳辐射强度、温度、风速以及湿度,删除光伏功率中的异常数据以及无功率输出时间点对应的影响因子数据,从而得到预处理后的数据集,包括:预处理后的光伏功率{p(t)}t=1,2,...,t和光伏功率的s=4个影响因子{fs(t)}s=1,2,...,s;t=1,2,...,t,其中,p(t)和fs(t)分别为第t个时间点的光伏功率及相应第t个时间点的第s个影响因子的数据;
从预处理后的数据集中提取光伏功率{p(t)}t=1,2,...,t,并根据爬坡事件的定义,计算t个时间点的光伏爬坡率{r(t)}t=1,2,...,t,其中,r(t)表示第t个时间点的光伏爬坡率,爬坡事件的定义为连续一段时间内的光伏功率变化量超过一定的阈值范围,可以表示为式(1):
式(1)中,δt为时间窗口,根据不同的电力系统实际情况可以设置为30分钟、60分钟,120分钟等。
s2)利用vmd方法将光伏爬坡率{r(t)}t=1,2,...,t分解成k个本征模态分量{rk(t)}k=1,2,,k;t=1,2,...,t,且满足
定义优化的参数组合为<k,α>,α表示vmd方法求解过程中的惩罚因子,k表示vmd分解出的本征模态分量个数;
如图2所示,参数自适应的vmd分解方法以k个本征模态分量{rk(t)}k=1,2,,k;t=1,2,...,t的能量熵之和作为适应度函数,利用pso算法对参数组合<k,α>进行寻优,具体过程如下:
1)确定参数k的寻优范围为[2,10],α的寻优范围为[1000,2000]
2)初始化粒子群,将vmd参数组合<k,α>作为粒子的位置信息;
3)在参数<k,α>下进行vmd分解,得到k个本征模态分量,计算相应的适应度函数值;
4)比较所有粒子的适应度函数值,更新粒子信息;
5)重复步骤3)和4),直到达到迭代停止条件。
获取最小适应度函数值所对应的最优参数组合<k0,α0>,从而根据最优参数组合<k0,α0>,计算得到t个时间点的光伏爬坡率{r(t)}t=1,2,...,t的最佳本征模态分量
s3)利用第k个本征模态分量
将数据集[xk(t),yk(t)]t=p+1,p+2,...,t划分为训练集
建立lasso-qr预测模型,利用非对称损失函数建立如式(2)所示的目标函数:
式(2)中,τh表示第h个分位点,且τh∈(0,1),h=1,2,...,h,h表示分位点的数量;βk(τh)表示第k个本征模态分量所对应的lasso-qr预测模型中第h个分位点下解释变量的系数集合,
式(2)中,
式(3)中,v为随机变量,在式(1)的目标函数中,v满足:
式(2)中,η为l1正则化惩罚参数;
利用式(5)将lasso-qr预测模型的目标函数转化成线性不等式约束规划问题:
式(5)中,γ是与η对应的约束参数;
利用lars算法在训练集train上对式(5)进行求解,获得训练后的lasso-qr预测模型;
将测试集test中的解释变量
s4)根据步骤s3,对每个本征模态分量分别建立lasso-qr预测模型并训练,从而得到k个本征模态分量在h个分位点下的条件分位数预测结果
利用式(6)将相同分位点下的条件分位数预测结果相加,从而得到第t个时间点第h个分位点下的条件分位数最终预测结果qh(t),进而得到第t个时间点h个分位点下的条件分位数最终预测结果{qh(t)}h=1,2,...,h:
将h个分位点下的条件分位数最终预测结果{qh(t)}h=1,2,...,h作为核密度估计kde方法的输入,并确定带宽为d,epanechnikov核函数e(.),从而求得每个时间点的概率密度函数,则第t个时间点的预测值的概率密度函数可以表示为式(7):
将每个时间点的概率密度函数离散化,从而得到第t个时间点的j个预测值{rj(t)}j=1,2,...,j以及相应的概率{πj(t)}j=1,2,...,j,其中,rj(t)和πj(t)分别为第t个时间点的第j个预测值及其对应的概率,且r1(t)≤r2(t)≤...≤rj(t);
s5)将光伏功率爬坡事件分成未爬坡事件、上爬坡事件以及下爬坡事件;并将上爬坡事件和下爬坡事件分别设置i个等级,最小程度的上爬坡事件和下爬坡事件分别为1级,最大程度上爬坡事件和下爬坡事件分别为i级;
设置i+1个阈值集合{δi}i=1,2,...,i+1,则各类爬坡事件的判断依据如式(8)所示:
式(8)中,δi和δi+1分别为i级上爬坡事件的阈值下限和阈值上限,-δi+1和-δi分别为i级下爬坡事件的阈值下限和阈值上限;
针对第t个时间点的j个预测值{rj(t)}j=1,2,...,j,根据判断依据确定每个预测值所在的阈值区间,并计算各个区间内的预测值对应的概率之和,即为该相应时刻点各类爬坡事件发生的概率,针对较高概率的光伏功率爬坡事件,采取相应的控制策略,做好防御准备。
- 还没有人留言评论。精彩留言会获得点赞!