一种服装一线员工生产订单批量系数精算方法与流程
本发明涉及资源、工作流、人员或项目管理,例如组织、规划、调度或分配时间、人员或机器资源;企业规划;组织模型的技术领域,特别涉及一种服装一线员工生产订单批量系数精算方法。
背景技术:
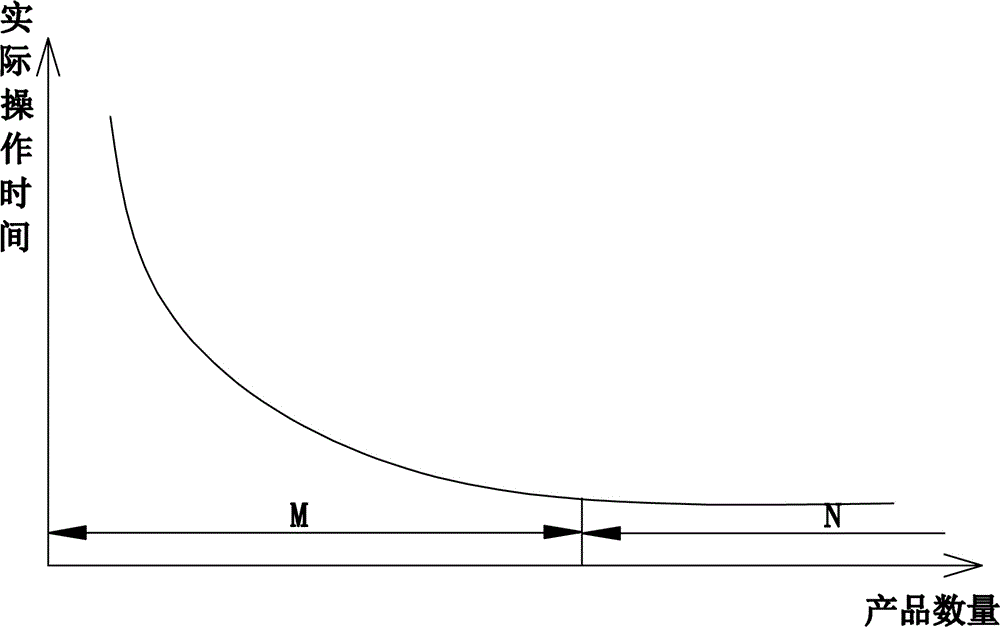
服装在生产加工的过程中,订单在进行流水线生产时,绝大部分员工都存在学习成长曲线,学习成长曲线是一种动态的生产函数,是指在产品的生产过程中随累计生产产量的增加,其单个产品的生产时间会逐渐下降,但累计产量达到一定数量后,实际操作时间趋于稳定,即,随着操作时间的累积、员工的操作越来越熟练、效率越来越高,员工生产效率与订单的数量成正比关系。影响操作时间的直接因素之一就是订单的数量大小(即批量),累计产量越少则用时越多。
进一步来说,款式结构的难易度亦直接影响员工成长曲线的变化规律、员工成长的速度、成长达到稳定所需要的时间、及稳定时的状态值,是影响操作时间的另一个直接因素。款式结构的难易度通过标准工时和订单批量来体现,订单标准工时越大表明该产品工艺越复杂,订单批量越小则员工适应的时间越短、操作熟练度越低、越难达到标准;款式结构系数随着标准总工时的递增而递增,随着订单批量数的递增而递减。
基于上述两方面的因素,通过批量系数来调整不同批量和不同难易度产品的工价,才能够实现更加科学的公平性,批量越大、则员工越有机会成长到效率更高的状态,款式越难则员工成长的越缓慢,最佳的状态就是订单批量足够大且款式的结构难易程度与其匹配,能在操作过程中被员工熟悉到学习成长曲线趋于稳定的值并维持尽可能长的时间。
传统的批量系数是根据生产经验划分区域范围的,每个区域给一个固定的系数。然而,传统的批量系数相对于一定的范围较为合理,但是主观性较强,对于边缘区域数据的取值极为不合理,为很多管理者和一线工人不能接受;举例来说,订单中100-1000件的单量,系数为1.35,而1001-2000件的单量,系数仅为1.3,也就是说,可能存在仅多了一件待处理服装、系数就降低一个层次的问题,往往在工作中带来很大争议。
现有技术中,完全根据经验而拟定批量系数的方法缺乏公平性和科学性。
技术实现要素:
本发明解决了现有技术中存在的问题,提供了一种优化的服装一线员工生产订单批量系数精算方法。
本发明所采用的技术方案是,一种服装一线员工生产订单批量系数精算方法,所述方法包括以下步骤:
步骤1:划分客户类型gk,k对应任一客户;
步骤2:对任一客户类型gk获取生产数据;以订单内产品数量为x轴、实际操作时间为y轴,建立xoy坐标系;
步骤3:基于订单内产品数量将x轴划分为若干个区间,获得任一客户类型gk在任一区间对应的区域系数rkx,建立客户等级数量系数模型,其中,x为待加工订单内的服装件数;
步骤4:基于操作时间和订单内产品数量将xoy坐标系划分为若干个区块,获得任一客户类型gk对应的款式结构系数hxy,建立款式结构系数模型;
步骤5:输入待加工订单内的服装件数和标准工时,计算客户等级数量系数和款式结构系数,取乘积为批量系数。
优选地,所述步骤1中,客户类型gk基于任一客户的检验aql值进行划分。
优选地,所述步骤2中,生产数据包括服装生产自动化传输工具及配套运行系统的测量数据、服装一线生产管理系统收集数据和人工现场实际测量数据中的一种或多种。
优选地,所述步骤3中,建立客户等级数量系数模型包括以下步骤:
步骤3.1:基于订单内产品数量将所述xoy坐标系的x轴划分为若干个区间;
步骤3.2:获得任一客户类型gk在每个区间的历史客户等级数量系数;
步骤3.3:求得所述相邻的两个区间的系数调节值αn;
步骤3.4:获得所述相邻的两个区间对应的区域系数rkx;
步骤3.5:建立新的客户等级数量系数模型。
优选地,所述步骤3.1中,若干个区间的起点和终点间的距离在x轴方向上随x值的增大而增大。
优选地,以订单内产品数量将x轴划分为n个区间;
第i个区间的单个订单的产品数量为ai至ai+1,中位数为mi,
相邻的两个区间的系数调节值
以x和对应的rkx值建立坐标系,为新的客户等级数量系数模型。
优选地,所述步骤4中,建立款式结构系数模型包括以下步骤:
步骤4.1:基于标准工时和订单内产品数量将xoy坐标系划分为若干个区块;
步骤4.2:获得任一客户类型gk在每个区块的历史款式结构系数;
步骤4.3:获取款式结构二维系数表,构建区间模型;
步骤4.4:获得客户类型gk在四邻域区块对应的款式结构系数hxy;
步骤4.5:建立新的款式结构系数模型。
优选地,所述步骤4.1中,若干个区间的x轴的起点和终点间的距离在x轴方向上随x值的增大而增大。
优选地,基于标准工时和订单内产品数量将xoy坐标系划分为m*p个区间;
对单个订单的产品数量为aj至aj+1、标准工时为bp至bp+1的区间,分别计算中位数
令区间模型的四邻域的坐标点顺次分别为(bk,aq)、(bk+1,aq)、(bk+1,aq+1)、(bk,aq+1),对应的历史款式结构系数分别为k1、k2、k4、k3;
计算每个四邻域中坐标点(bx,ay)对应的款式结构系数模型hxy,hxy=k1+(bx-bk)×tx-(ay-aq)×ty+(ay-aq)×ly×(bx-bk)×lx,其中,件数变化率
优选地,根据实际生产数据库中不同批量产品的目标达成率对比,调整中位数系数值。
本发明涉及一种优化的服装一线员工生产订单批量系数精算方法,按照预设维度,将客户划分类型,显然,不同类型的客户、其对应员工的学习成长曲线亦不同,则处理方式不同,对任一客户类型gk获取生产数据,并以订单内产品数量为x轴、实际操作时间为y轴建立xoy坐标系,分别建立新的客户等级数量系数模型和款式结构系数模型,在输入待加工订单内的服装件数和标准工时后,计算客户等级数量系数和款式结构系数,取乘积为批量系数。
本发明充分利用历史数据,在传统经验区域划分的基础上对批量系数进行数据化研究,结合定量和定性的方法计算出不同区域内的产品所对应的批量系数关联因子的变化,进而可以将新增订单以关联数据进行分区处理,使得计算得到的批量系数更为客观、合理,达到工作分配中的相对公平性和科学性。
附图说明
图1为本发明中以订单内产品数量为x轴、实际操作时间为y轴建立的xoy坐标系,m段为成长阶段、n段为稳定阶段,曲线最终将趋于稳定值。
具体实施方式
下面结合实施例对本发明做进一步的详细描述,但本发明的保护范围并不限于此。
本发明涉及一种服装一线员工生产订单批量系数精算方法,首先定义:
批量综合系数=客户等级数量系数*款式结构数量系数。
所述方法包括以下步骤。
步骤1:划分客户类型gk,k对应任一客户。
所述步骤1中,客户类型gk基于任一客户的检验aql值进行划分。
本发明中,客户等级数量系数与客户等级和实际加工时间密切相关。一般来说,不同的企业会根据自己的特点进行客户等级的划分,在服装行业,可以是以客户对产品的质量要求严格程度为依据进行分类,如基于aql标准,aql抽样时,抽取数量相同,而aql后面跟的数值越小则品质要求越高、检验就越严格;可以依据客户对质量的要求高低将客户划分为不同的等级。
本发明中,不同等级的客户对产品的质量要求往往存在较大差异,这导致了同种工序在操作上实际所花费的时间和精力是不一样的,相同款式的产品,质量要求越严格的客户对应的产品越难做、加工速度越慢,而要求严格的客户对应着产品加工时工人实际耗费的时间更长,需要成倍关注质量;即,等级越高的客户的订单生产时,对应的学习成长曲线达到稳定所需要的时间会更长,成长更为缓慢。然而,对于企业建立的标准工时数据库来说,各工序的标准应当是统一的,这个标准并不能根据客户而变化,因此,对实际加工时间的影响需要通过相应的系数来体现和调整。
步骤2:对任一客户类型gk获取生产数据;以订单内产品数量为x轴、实际操作时间为y轴,建立xoy坐标系。
所述步骤2中,生产数据包括服装生产自动化传输工具及配套运行系统的测量数据、服装一线生产管理系统收集数据和人工现场实际测量数据中的一种或多种。
本发明中,生产数据来源于实际生产线每天的产量效率数据,其中,服装生产自动化传输工具及配套运行系统一般为吊挂线、流水线等,服装一线生产管理系统一般包括rfid芯片等;生产数据可以独立使用,亦可以整合后共同配合测量,最终得出各个区域对应的系数。
步骤3:基于订单内产品数量将x轴划分为若干个区间,获得任一客户类型gk在任一区间对应的区域系数rkx,建立客户等级数量系数模型,其中,x为待加工订单内的服装件数。
所述步骤3中,建立客户等级数量系数模型包括以下步骤:
步骤3.1:基于订单内产品数量将所述xoy坐标系的x轴划分为若干个区间;
所述步骤3.1中,若干个区间的起点和终点间的距离在x轴方向上随x值的增大而增大。
步骤3.2:获得任一客户类型gk在每个区间的历史客户等级数量系数;
步骤3.3:求得所述相邻的两个区间的系数调节值αn;
步骤3.4:获得所述相邻的两个区间对应的区域系数rkx;
步骤3.5:建立新的客户等级数量系数模型。
具体来说,以订单内产品数量将x轴划分为n个区间;
第i个区间的单个订单的产品数量为ai至ai+1,中位数为mi,
相邻的两个区间的系数调节值
以x和对应的rkx值建立坐标系,为新的客户等级数量系数模型。
根据实际生产数据库中不同批量产品的目标达成率对比,调整中位数系数值。
本发明中,根据实际生产数据库中不同批量产品的目标达成率对比略微调整中位数系数值,使之更加合理有效。
本发明中,取xoy坐标系中的任意两个区间,一般为相邻区间,以区间的中位数和历史客户等级数量系数参与、计算系数调节值,并最终作用在此区域对应的系数中。
本发明中,新构建的客户等级数量系数模型以每个中位数构建为x轴,当需要计算件数对应的rkx值时,只需要将x对应到某两个中位数间,取这两个中位数间、此x对应的系数即可。
本发明中,事实上,x轴的区间是可以持续划分的,故i为大于0的整数即可,当然,最后得到的中位数的个数不可能大于n。
步骤4:基于操作时间和订单内产品数量将xoy坐标系划分为若干个区块,获得任一客户类型gk对应的款式结构系数hxy,建立款式结构系数模型。
所述步骤4中,建立款式结构系数模型包括以下步骤:
步骤4.1:基于标准工时和订单内产品数量将xoy坐标系划分为若干个区块;
所述步骤4.1中,若干个区间的x轴的起点和终点间的距离在x轴方向上随x值的增大而增大。
步骤4.2:获得任一客户类型gk在每个区块的历史款式结构系数;
步骤4.3:获取款式结构二维系数表,构建区间模型;
步骤4.4:获得客户类型gk在四邻域区块对应的款式结构系数hxy;
步骤4.5:建立新的款式结构系数模型。
具体来说,基于标准工时和订单内产品数量将xoy坐标系划分为m*p个区间;
对单个订单的产品数量为aj至aj+1、标准工时为bp至bp+1的区间,分别计算中位数
令区间模型的四邻域的坐标点顺次分别为(bk,aq)、(bk+1,aq)、(bk+1,aq+1)、(bk,aq+1),对应的历史款式结构系数分别为k1、k2、k4、k3;
计算每个四邻域中坐标点(bx,ay)对应的款式结构系数模型hxy,hxy=k1+(bx-bk)×tx-(ay-aq)×ty+(ay-aq)×ly×(bx-bk)×lx,其中,件数变化率
根据实际生产数据库中不同批量产品的目标达成率对比,调整中位数系数值。
本发明中,区块划分从体现订单内产品数量的x轴来说,一般产品数量的跨度为从小到大,因为随着产品数量的增加、系数增加的幅度将逐渐变缓,最终将趋于稳定值,跨度从小到大能更好的体现区块的准确性、适用性。
本发明中,在初始的xoy坐标系中,取每个区块的横坐标和纵坐标的中位数建立区间模型,即横坐标和纵坐标分别为计算中位数后的标准工时和计算中位数后的件数,坐标系上的每个点对应的值则是历史款式结构系数,可以查表获取;以每个四邻域作为独立的计算区块,最终得到的结果为在四邻域的坐标点所构成的区间内,每个不同的(bx,ay)对应的修正后的款式结构系数值。
本发明中,在计算每个不同的(bx,ay)对应的修正后的款式结构系数值时,需要将bx和ay对应到某一个中位数构成的四邻域中,然后以四邻域的四个角点对应的k值及相关值进行计算。
本发明中,四邻域是指以某个点为中心,包围其左上、左下、右上、右下的四个区块。
本发明中,事实上对于初始的xoy坐标系,基于x轴和y轴的区块划分是可以持续进行的,故j和p为大于0的整数即可,当然,最后得到的、构建新的x轴和y轴的中位数的个数不可能大于m和p。
本发明中,根据实际生产数据库中不同批量产品的目标达成率对比略微调整中位数系数值,使之更加合理有效。
步骤5:输入待加工订单内的服装件数和标准工时,计算客户等级数量系数和款式结构系数,取乘积为批量系数。
- 还没有人留言评论。精彩留言会获得点赞!