一种在分布式学术数据仓库中检测热点学术研究话题的方法与流程
本发明涉及数据挖掘,更具体的说:是一种涉及在分布式学术数据仓库中检测热点学术研究话题的方法框架。
背景技术:
近些年来随着国内学术研究的水平和规模稳步上升,发表的学术论文数量与日俱增。例如,一份由美国国家科学基金会发布的《科学和工程指标报告》显示,2016年中国发表的学术论文已经超过42.6万份,相当于国际总数量的18.6%,这一数据已经超越美国,让中国成为学术论文数量的第一大国。但是,伴随着发表的论文数量的增长以及学术研究方向的不断发散,把握当前学术热点以及跟踪相应的研究进度越来越困难,进而增大了科研人员新人跟进学术研究前沿的难度;此外对于科研管理机构,合理安排科研项目及资金也成了难题。
近些年来,已经有一些研究工作开始关注学术热点话题的检测,有如下限制:(1)只能在集中式学术仓库中检测热点话题;(2)不能支持持续不断的科研文件更新;(3)需要大量网络带宽及内存资源来支撑检测过程。考虑到现有的学术仓库的部署方式都是分布式部署以及在实际中需要明确热点研究话题的要求,已有研究工作都具有一定局限性,不能直接用于在分布式数据仓库中检测学术研究热点话题,因而已有工作不能解决本发明中提出的目标。
因此,提供一种能在分布式数据仓库中检测热点研究话题,并且能有效的降低分布式环境下需要传输的数据量,保证检测出热点话题的热度的准确度,是本领域技术人员亟待解决的问题。
技术实现要素:
本发明目的是:在保持低通信量的前提下,在分布式数据仓库中检测热点研究话题。
为实现上述目的,本发明的技术方案是:一种在分布式学术数据仓库中检测热点学术研究话题的方法,其特征在于;包括在分布式数据仓库中的数据数据采样压缩编码,传输阶段,以及中央服务器上的数据恢复和检测阶段;
其中:
数据采样压缩编码阶段负责维护一组编码型布谷鸟过滤器,并对每个从学术文档中提取出的学术词进行多重采样决定是否进入组内每个编码型布谷鸟过滤器,成功采样的词汇将进入数据编码阶段;
数据编码阶段负责在每个分布式数据仓库中扫描所有的文档,并利用分词器从文档中提取学术研究词汇,并对提取出的学术词汇及其频数压缩编码并记录进入编码型布谷鸟过滤器(codingcuckoofilter)存储结构中;
数据传输阶段负责将每个分布式数据仓库中记录压缩数据的编码型布谷鸟过滤器传输至中央服务器;
数据恢复和检测阶段是在中央服务器上将从各个分布式数据集上构建起来编码布谷鸟过滤器中解码恢复出原始词汇并估算其热度(频数),并根据用户给定的学术话题热度(频数)要求输出热点研究话题。即在各个分布式服务器发送的编码布谷鸟过滤器基础上,根据存储在其中的压缩数据,将潜在的热点研究话题词汇连同其热度恢复出来,并计算在所有分布式数据仓库中的总热度,最后根据总热度输出热点研究话题。
所述的在分布式学术数据仓库中检测热点学术研究话题,(1)在数据存储阶段维护一组编码型布谷鸟过滤器,对于每个学术词汇经多重采样决定是否存储进入每个过滤器。(2)在数据编码和传输阶段,不存储原始数据,而是存储原始数据的编码,指纹信息及采样的频数信息;(2)在数据编码阶段,每个学术词汇的频数经采样后和与其编码及指纹一同被记录;(3)然后在数据恢复和检测阶段,根据指纹信息,将从属于同一元素的编码汇聚然后解码恢复出原始数据;(4)然后在数据恢复和检测阶段,根据指纹信息,将从属于研究词汇的编码汇聚然后解码恢复出原始数据;
在数据编码和传输阶段,将数据先多重采样然后再压缩编码后存储进入编码布谷鸟过滤器的过程。
在数据数据恢复和检测阶段,学术词汇的热度是通过最大似然估计的方法恢复。
本发明旨在提出在分布式学术数据仓库中检测热点研究话题,过程包含:设计分布式计算检测的系统模型;提出利用编码技术压缩学术话题词汇的存储量;提出利用多重采样技术进一步降低数据存储和通信量;提出利用编码布谷鸟过滤器存储提高数据处理过程的速度。具体而言,本发明:1、设计热点学术话题检测系统模型;2、提出分布式扫描学术文档并提取出热点词汇然后压缩编码存储学术词汇和热度;3、提出将编码后的数据存储进入编码布谷鸟过滤器加快数据处理速度;
学术热点话题话题是指在学术研究中被广大研究这共同研究的问题,问题的形式也词汇的形式表现出来。本发明首先提出在分布式学术数据仓库中检测学术热点话题的系统模型;其次在数据采样阶段,采用多重采样的技术从而在降低数据存储量的同时保持较高的准确度;在数据编码和传输阶段,在每个分布式的数据仓库中,提出利用编码技术来压缩每个分布式数据仓库中记录的学术文件中含有的话题词汇,然后将编码后的数据存储进去编码布谷鸟过滤器;在数据传输阶段,我们将压缩后的数据传输到指定的中央服务器,进行热点话题及其出现频数的恢复并最终根据用户提供的话题热度要求输出所有热点学术话题。本发明首次提出在分布式学术数据仓库中检测学术研究热点话题的方法,其有效地减少了在分布式环境下为了检测学术研究热点而产生的大量数据通信量,并针对性的给出了有效的理论性能保障,可以用于检测学术热点话题并计算话题热度。
本发明的有益效果是:1、提出使用编码压缩数据从而有效地降低了分布式数据环境下学术热点话题所需传输的数据量;2、提出利用多重采样技术进一步降低存储和传输的数据量;3、提出将编码后的数据存储进入编码布谷鸟过滤器并将其作为一个整体传输,极大地加快了数据处理和传输的时间。
附图说明
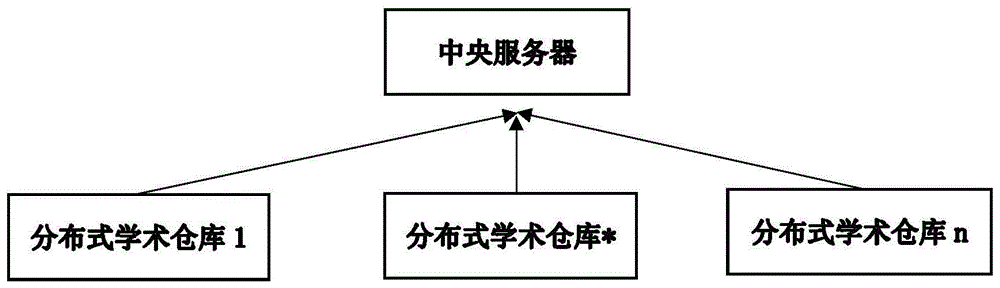
图1本发明的系统架构图;
图2为数据采样阶段流程图;
图3为数据解码恢复和检测流程图。
具体实施方式
本发明的系统架构如图1所示,包含中央服务器和分布式学术仓库。本发明有两个阶段分别是:(1)分布式数据仓库内完成的数据采样,数据压缩编码阶段以及传输阶段;(2)中央服务器上数据解码恢复和热点话题检测阶段。数据压缩编码阶段又可以细分为3个步骤分别是:数据采样,数据编码和指纹信息获取,数据存储,以及数据传输;数据解码恢复和检测阶段可分为2个步骤:数据解码恢复和热点词汇检测。
阶段1.1:数据采样阶段
在数据采样阶段,为每个分布式数据仓库维护一组编码型布谷鸟过滤器,进而扫描该数据仓库中的学术文档并利用分词器提取出其中的学术研究词汇,最后多重采样决定该词汇如何存储。多重采样的过程如下:(1)每一组内的编码型布谷鸟过滤器的采样概率按照序号增大呈几何衰减,如:第一个过滤器的采样概率1%,第二个0.2%,第三个0.04%,以此类推;(2)每个学术词汇在该组内所有的编码型布谷鸟过滤器上独立地按照该过滤器的预设的采样频率进行采样,多个过滤器的采样过程构成了多重采样。被成功采样的学术词汇将进入后续编码阶段。
阶段1.2:数据编码阶段
在数据编码阶段,我们需要首先压缩学术词汇,然后获取该词汇指纹信息,之后将获取的编码和指纹信息一同插入编码型布谷鸟过滤器,同时将插入位置的计数器增加1。
压缩过程:每一个学术词汇都有一个识别编号(id),该编号可直接由英文字符或者中文编码的二进制表示获得。由于该编号通常很长,直接传输会引起过大的通信量。为了解决通信量的问题,我们先对数据进行有损压缩(raptorcode)码,过程如下:
指纹获取,给定词汇id,和哈希函数hf(·),指纹信息f(长度为p)获取方式如下:
f=hf(id)%2p,其中%表示取模运算。
在获取到编码和指纹后,我们按照普通布谷鸟过滤器的插入方式将该编码信息和指纹信息插入:(1)利用两个哈希函数计算潜在的两个可以插入数据桶;(2)如果这两个位置内有可以插入的空间就直接插入;(3)如果这两个位置内没有可插入空间则直接踢出一个元素空出位置插入,然后被提出的元素则重复上述过程重新插入。
阶段1.3:数据传输
当每个分布式数据仓库的编码阶段完成,现在我们需要将存有压缩数据信息编码布谷鸟过滤器发送给指定的中央服务器。
阶段2.1:数据恢复和检测
在所有数据集中发送到某个中央服务器之后,我们需要从来自不同分布式学术仓库的的编码布谷鸟过滤器提取压缩数据,然后解码恢复原始数据并估算热度。
压缩数据提取:在获取到各个服务器发送过来的编码布谷鸟过滤器后,我们将其排列对齐进行处理。对所有的布谷鸟过滤器,遍历所有的数据桶,选中当前的数据桶,然后取出其中的元素,然后依据该元素的指纹信息将所有分布式数据仓库传来的过滤器在相同插入位置的且指纹信息相同的元素提取出来构成一个同类编码群。如图3所示,先遍历遇到1元素,然后依据1将其余与其在同一个编码群内的元素全部提取出来。
解码:针对提取出的编码,将其代入公式1中去解码出原始词汇id。
热度估计:针对解码出的词汇id,将其计数器中的值连同对应的采样概率,利用最大似然估计计算出一个估计的热度值,然后输出解码出的词汇和对应的热度。
- 还没有人留言评论。精彩留言会获得点赞!