一种基于机器学习的web访问越权识别方法及系统与流程
[0001]
本发明涉及一种web访问越权,具体涉及一种基于机器学习的web访问越权识别方法及系统。
背景技术:
[0002]
随着电网企业信息化建设的快速发展,电网企业根据业务要求,部署和实施了多套应用系统,其中这些信息系统与互联网或其或其他网络互联,使信息系统早场攻击的概率增加。黑客利用信息系统漏洞入侵电力系统,将给公司和用户造成损失。目前针对电力系统的测评工作表明,现有安全测试工具中可以发现信息泄露、sql注入,xss等传统的web访问安全漏洞,但对于业务逻辑漏洞缺乏有效的检测手段。
[0003]
我们传统的方法是人工进行渗透测试发现业务逻辑漏洞。这种方式识别过程是:
[0004]
第一步:在系统中申请两个相同权限的a\b两个用户。
[0005]
第二部:登录用户a系统中有可能存在web访问越权的页面。例如:修改密码、个人信息等依赖身份信息的页面,得到响应内容。
[0006]
第三步:登录用户b系统中和a用户同样的功能,得到响应内容。
[0007]
第四步:对用户a响应内容和用户b响应内容做逐字对比,如果相似度特别高则说明此功能存在水平越权漏洞。
[0008]
上述方式不难发现人为识别对人员能力的依赖程度特别大,受个人主观因素的影响页很大,而且效率低下。而且逐字对比有可能页面存在时间戳等无关信息,即使结果相似度不一样也不会存在越权,但是这种情况上述方式无法识别,最终会造成很多误报或者漏报信息。
技术实现要素:
[0009]
针对现有技术进行渗透测试发现业务逻辑漏洞,测试速度慢,准确度较低,本发明提供了一种基于机器学习的web访问越权识别方法,包括:
[0010]
获取至少两个用户的登录请求对应的网页响应内容;
[0011]
利用训练好的word2vec算法模型,将所述网页响应内容转化为数据向量;
[0012]
基于所有用户对应的数据向量,通过欧几里得度量进行计算获得任意两个用户的相似度值;
[0013]
基于所述相似度值判断web访问是否存在越权。
[0014]
优选的,所述word2vec算法模型的训练,包括:
[0015]
获取用户登陆的历史数据,计历史数据中的高频信息并将所述高频信息转化为设定形式;
[0016]
通过设定形式的高频信息进行切词、向量化表示获得数据向量;
[0017]
将设定形式的高频信息和数据向量作为word2vec算法模型的训练样本;
[0018]
以设定形式的高频信息作为word2vec算法模型的输入,数据向量作为word2vec算
法模型的输出对word2vec算法模型进行训练。
[0019]
优选的,所述对至少两个用户的登录请求对应的网页响应内容进行数据清洗,包括:
[0020]
根据至少两个用户请求url,获得每个用户信息;
[0021]
基于每个用户信息,对缺失信息进行填补;
[0022]
获取填补后的信息中的高频信息并按设定格式进行处理。
[0023]
优选的,所述基于所有用户对应的数据向量,通过欧几里得度量进行计算获得任意两个用户的相似度值,包括:
[0024]
基于任意两个用户的数据向量,采用欧几里得度量公式计算向量长度;
[0025]
基于所述向量长度,采用相似度公式计算相似度值。
[0026]
优选的,所述基于所述相似度值,判断web访问是否存在越权,包括:
[0027]
当相似度值处于设定阈值范围时,web访问存在越权,否则,web访问不存在越权。
[0028]
优选的,所述向量长度,按下式计算:
[0029][0030]
式中,d为向量的自然长度;x和y为向量d的方向坐标。
[0031]
优选的,所述相似度值,按下式计算:
[0032][0033]
式中,n为相似度值;d为向量的自然长度;x和y为向量d的方向坐标。
[0034]
基于同一发明构思,本发明提供了一种基于机器学习的web访问越权识别技术系统,包括获取信息模块、转化向量模块、计算模块和判断模块;
[0035]
所述获取信息模块:获取至少两个用户的登录请求对应的网页响应内容;
[0036]
所述转化向量模块:利用训练好的word2vec算法模型,将所述网页响应内容转化为数据向量;
[0037]
所述计算模块:基于所有用户对应的数据向量,通过欧几里得度量进行计算获得任意两个用户的相似度值;
[0038]
所述判断模块:基于所述相似度值判断web访问是否存在越权。
[0039]
优选的,还包括清洗模块;
[0040]
根据至少两个用户请求url,获得每个用户信息;
[0041]
基于每个用户信息,对缺失信息进行填补;
[0042]
获取填补后的信息中的高频信息并按设定格式进行处理。
[0043]
优选的,所述计算模块包括计算向量长度子模块、计算相似度值子模块和判断子模块;
[0044]
所述计算向量长度子模块:基于各用户数据向量,采用欧几里得度量公式计算向量长度;
[0045]
所述计算相似度值子模块:基于所述向量长度,采用相似度公式计算相似度值。
[0046]
与现有技术相比,本发明的有益效果为:
[0047]
1、本发明提供了一种基于机器学习的web访问越权识别方法,包括:获取至少两个用户的登录请求对应的网页响应内容,利用训练好的word2vec算法模型,将所述网页响应内容转化为数据向量,基于所有用户对应的数据向量,通过欧几里得度量进行计算获得任意两个用户的相似度值,基于所述相似度值判断web访问是否存在越权;本发明通过word2vec算法模型获得用户数据向量并通过采用欧几里得度量计算向量长度获得相似度值,由相似度值可以更快速准确的判断web访问是否存在越权。
[0048]
2、本发明通过采用历史用户信息数据和数据向量对word2vec算法模型进行训练;再通过用户登录web访问时,获取用户信息进行向量转化,使向量通过向量相似度公式计算得到向量相似度值,再通过相似度值快速、准确的判断web访问是否存在越权。
附图说明
[0049]
图1为本发明的基于机器学习的web访问越权识别方法示意图;
[0050]
图2为本发明的基于机器学习的web访问越权识别系统示意图。
具体实施方式
[0051]
实施例1
[0052]
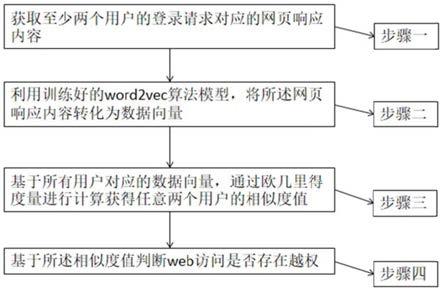
结合图1,本发明提供了一种基于机器学习的web访问越权识别方法,包括:
[0053]
步骤一:获取至少两个用户的登录请求对应的网页响应内容;
[0054]
步骤二:利用训练好的word2vec算法模型,将所述网页响应内容转化为数据向量;
[0055]
步骤三:基于所有用户对应的数据向量,通过欧几里得度量进行计算获得任意两个用户的相似度值;
[0056]
步骤四:基于相似度值判断web访问是否存在越权。
[0057]
word2vec算法模型的训练,包括:
[0058]
获取用户登陆的历史数据,计历史数据中的高频信息并将高频信息转化为设定形式;
[0059]
通过设定形式的高频信息进行切词、向量化表示获得数据向量;
[0060]
将设定形式的高频信息和数据向量作为word2vec算法模型的训练样本;
[0061]
以设定形式的高频信息作为word2vec算法模型的输入,数据向量作为word2vec算法模型的输出对word2vec算法模型进行训练。
[0062]
其中,步骤一:获取至少两个用户的登录请求对应的网页响应内容,包括:
[0063]
根据至少两个用户请求url,获得每个用户信息;
[0064]
基于每个用户信息,对缺失信息进行填补;
[0065]
获取填补后的信息中的高频信息并按设定格式进行处理。
[0066]
其中,步骤三:基于所有用户对应的数据向量,通过欧几里得度量进行计算获得任意两个用户的相似度值,包括:
[0067]
基于任意两个用户的数据向量,采用欧几里得度量公式计算向量长度;
[0068]
基于向量长度,采用相似度公式计算相似度值。
[0069]
其中,步骤四:基于相似度值,判断web访问是否存在越权,包括:
[0070]
当相似度值处于设定阈值范围时,web访问存在越权,否则,web访问不存在越权。
[0071]
向量长度,按下式计算:
[0072][0073]
式中,d为向量的自然长度;x和y为向量d的方向坐标。
[0074]
相似度值,按下式计算:
[0075][0076]
式中,n为相似度值;d为向量的自然长度;x和y为向量d的方向坐标。
[0077]
实施例2
[0078]
结合图2,在一个实施例中,所述方法包括:
[0079]
1.获取响应数据
[0080]
2.进行特征工程处理
[0081]
3.向量化表示
[0082]
4.计算相似度
[0083]
在第一步中,根据a/b两个用户请求url,得到两个不同的网页响应内容,为后期的计算相似度提供数据支撑。
[0084]
第二步我们对获取的数据进行清洗脏数据,对缺失值进行补全、并统计高频词汇和低频词汇然后去除低频词汇,用以提高相似度的准确性,最后我们并把数据整理成统一格式。
[0085]
第三步把清洗好的数据使用word2vec算法进行向量化表示,word2vec模型其实就是简单化的神经网络。word2vec,是用来产生词向量的相关模型。模型为浅而双层的神经网络,用来训练以重新建构语言学之词文本。网络以词表现,并且需猜测相邻位置的输入词,在word2vec中词袋模型假设下,词的顺序是不重要的。训练完成之后,word2vec模型可用来映射每个词到一个向量,可用来表示词对词之间的关系,该向量为神经网络之隐藏层。
[0086]
第四步根据得到的向量进行欧几里得度量,得到相似度值,根据相似度值判断是否存在越权。
[0087]
欧几里得度量(euclidean metric)(也称欧氏距离)是一个通常采用的距离定义,指在m维空间中两个点之间的真实距离,或者向量的自然长度(即该点到原点的距离),
[0088]
欧氏距离越小,两个用户相似度就越大,欧氏距离越大,两个用户相似度就越小。
[0089]
计算所得距离+1取倒数得到0-1范围内的相似值。+1的原因是防止距离为0,无法取倒数。当n值处于0.7-1的范围内时,表示web访问存在越权,相似值越高越相似。计算公式如下:
[0090][0091]
式中,d为向量的自然长度;x和y为向量d的方向坐标。
[0092]
实施例3
[0093]
基于同一发明构思,本发明提供了一种基于机器学习的web访问越权识别系统,包括获取信息模块、转化向量模块、计算模块和判断模块;
[0094]
获取信息模块:获取至少两个用户的登录请求对应的网页响应内容;
[0095]
转化向量模块:利用训练好的word2vec算法模型,将网页响应内容转化为数据向量;
[0096]
计算模块:基于所有用户对应的数据向量,通过欧几里得度量进行计算获得任意两个用户的相似度值;
[0097]
判断模块:基于相似度值判断web访问是否存在越权。
[0098]
还包括清洗模块;
[0099]
根据至少两个用户请求url,获得每个用户信息;
[0100]
基于每个用户信息,对缺失信息进行填补;
[0101]
获取填补后的信息中的高频信息并按设定格式进行处理。
[0102]
计算模块包括计算向量长度子模块、计算相似度值子模块和判断子模块;
[0103]
计算向量长度子模块:基于各用户数据向量,采用欧几里得度量公式计算向量长度;
[0104]
计算相似度值子模块:基于向量长度,采用相似度公式计算相似度值。
[0105]
本领域内的技术人员应明白,本申请的实施例可提供为方法、系统、或计算机程序产品。因此,本申请可采用完全硬件实施例、完全软件实施例、或结合软件和硬件方面的实施例的形式。而且,本申请可采用在一个或多个其中包含有计算机可用程序代码的计算机可用存储介质(包括但不限于磁盘存储器、cd-rom、光学存储器等)上实施的计算机程序产品的形式。
[0106]
本申请是参照根据本申请实施例的方法、设备(系统)、和计算机程序产品的流程图和/或方框图来描述的。应理解可由计算机程序指令实现流程图和/或方框图中的每一流程和/或方框、以及流程图和/或方框图中的流程和/或方框的结合。可提供这些计算机程序指令到通用计算机、专用计算机、嵌入式处理机或其他可编程数据处理设备的处理器以产生一个机器,使得通过计算机或其他可编程数据处理设备的处理器执行的指令产生用于实现在流程图一个流程或多个流程和/或方框图一个方框或多个方框中指定的功能的装置。
[0107]
这些计算机程序指令也可存储在能引导计算机或其他可编程数据处理设备以特定方式工作的计算机可读存储器中,使得存储在该计算机可读存储器中的指令产生包括指令装置的制造品,该指令装置实现在流程图一个流程或多个流程和/或方框图一个方框或多个方框中指定的功能。
[0108]
这些计算机程序指令也可装载到计算机或其他可编程数据处理设备上,使得在计算机或其他可编程设备上执行一系列操作步骤以产生计算机实现的处理,从而在计算机或其他可编程设备上执行的指令提供用于实现在流程图一个流程或多个流程和/或方框图一个方框或多个方框中指定的功能的步骤。
[0109]
以上仅为本发明的实施例而已,并不用于限制本发明,凡在本发明的精神和原则之内,所做的任何修改、等同替换、改进等,均包含在申请待批的本发明的权利要求范围之内。
相关技术
网友询问留言
已有0条留言
- 还没有人留言评论。精彩留言会获得点赞!
1