一种基于深度学习的时空双向土壤含水量插值方法与流程
[0001]
本发明涉及一种土壤含水量插值方法,尤其涉及一种基于深度学习的时空双向土壤含水量插值方法。
背景技术:
[0002]
土壤水是地球表层系统的重要组成部分,为陆地生态系统植被、微生物的生长提供了重要环境,对土壤-植被-大气系统中水分、能量、物质交换起到关键调节作用。大范围的土壤含水量的监测是水文过程研究和洪旱灾害分析的重要组成部分,而区域尺度甚至全球范围的土壤水环境反演更是陆地过程模式研究中必不可少的一个参量,在改善区域及全球气候模式预报、预测区域干湿情况、监测环境灾害研究中意义重大。
[0003]
土壤含水量的测定方法主要包括接触式的站点监测和非接触式的遥感观测数据反演。站点监测不受大气、植被影响,数据精度高;但是站点个数不多,无法形成连续且大范围的空间数据集,同时也很难表现土壤、地形、植被覆盖上的空间变异性。遥感监测极大地克服了这种缺陷,其观测覆盖范围大,持续时间长,能够实时、动态地监测地表变化,数据的面状特征能够更好的刻画土壤含水量的空间分布,捕捉其空间异质性信息,是监测大区域土壤水分时空分布和变化的主要方法;但遥感数据难以满足植被覆盖区(无法穿透植被冠层)的土壤含水量反演,并且深受云层覆盖及传感器探测深度的影响,存在数据缺失的问题。常用的土壤含水量插值方法主要是地统计空间插值法和机器学习算法,包括:反距离权重法(idw)、普通克里格插值法(kriging)和回归克里格法(rk)、径向基神经网络(rbf)、人工神经网络(ann)、随机森林(rf)等。
[0004]
地统计空间插值法仅从空间距离上对土壤含水量进行插值,不考虑其他因素对土壤含水量的综合影响,精度不高,且在数据量少、缺失程度大时精度会大打折扣;机器学习算法常用来模拟及处理影响因素多、关系复杂的系统,可从气象、植被、土壤、地形等方面模拟插值土壤含水量,精度较高,是目前土壤含水量插值的常用方法,但是它不能很好地同时反映土壤含水量的空间分布特征和时间变化趋势。
技术实现要素:
[0005]
发明目的:针对以上问题,本发明提出一种基于深度学习的时空双向土壤含水量插值方法,综合考虑前期土壤含水量的影响和各网格点之间土壤含水量的空间联系,显著提高插值的准确性。
[0006]
技术方案:本发明所采用的技术方案是一种基于深度学习的时空双向土壤含水量插值方法,包括以下步骤:
[0007]
步骤一:收集气象要素、植被参数、土壤信息、地形地貌条件和遥感土壤含水量esa cci数据,并进行归一化处理,将数据集按照比例分成训练集和验证集。
[0008]
其中,所述的气象要素是指降水、气温、蒸散发、风速、日照、空气湿度、大气压,所述降水包括当时降水和前期降水;植被参数主要为归一化植被指数ndvi、叶面积指数lai和
植被类型;土壤信息主要有孔隙度、田间持水量、土壤饱和含水量和凋萎含水量;地形地貌包括高程、坡度、坡向。
[0009]
所述的归一化处理是为了消除指标间的量纲影响,同时提升求解收敛速度,提高模型训练效率,其计算公式为:
[0010][0011]
其中,x
i
、o
i
分别为原始参数值与归一化后参数值;maxx
i
是该参数类别最大值;minx
i
是该参数类别最小值。
[0012]
优选的,将数据集按照7∶3的比例随机拆分成训练集和验证集。
[0013]
步骤二:分别构建长短期记忆模型和全卷积神经网络模型。
[0014]
其中,所述的长短期记忆神经网络模型由输入层、隐含层、输出层构成,其每个神经元有3个门结构来模拟神经细胞随时间变化的记忆过程:第一阶段是遗忘门,决定哪些信息需要从细胞状态中被遗忘;第二阶段是输入门,确定哪些新信息能够被存放到细胞状态中;第三阶段是输出门,决定信息的输出。
[0015]
所述的全卷积神经网络模型采用fcn-16s的结构,反卷积步长为16,上采样采用反池化中的最大池化;所述的全卷积神经网络模型将末尾的全连接层全部转化成1
×
1卷积层,并通过反卷积、上采样和跳级结构输出与原始输入同尺寸的输出,保留原始输入的空间信息。
[0016]
步骤三:将归一化后的气象要素、植被参数、遥感土壤含水量数据逐时间序列输入长短期记忆模型中,运行并得到逐时间的空间各网格点的土壤含水量。
[0017]
步骤四:将归一化后的气象要素、植被参数、土壤信息、地形地貌条件、遥感土壤含水量数据逐空间网格排列的顺序输入到全卷积神经网络模型中,运行并得到逐空间网格点长时间序列土壤含水量。
[0018]
步骤五:将两种模型模拟得到的土壤含水量数据集分别与原遥感土壤含水量及站点土壤含水量进行验证比较,评估两种算法的精度。
[0019]
其中,所述的计算两种模型算法的模拟精度,采用相关系数和均方根误差进行计算,所述相关系数cc的计算公式为:
[0020][0021]
式中,w
sim
(i)为第i个月的模拟土壤含水量含量;w
obs
(i)为第i个月的实测土壤含水量含量;为实测土壤含水量含量的平均值;为模拟土壤含水量含量的平均值;n为数据个数;
[0022]
所述均方根误差rmse的计算公式为:
[0023]
[0024]
式中,w
sim
(i)为第i个月的模拟土壤含水量含量;w
obs
(i)为第i个月的实测土壤含水量含量;n为数据个数。
[0025]
步骤六:通过基于贝叶斯网络的权重自学习法获取两种模型插值结果的权重。
[0026]
所述的权重自学习法是一种基于贝叶斯网络的的算法,通过反向误差传播和梯度下降法不断逼近权重值,其具体步骤为:(1)主观赋权,作为初始权值;(2)构建贝叶斯网络,设置目标误差值;(3)通过反向传播法和梯度下降法不断修正权重,直至误差小于目标值;(4)输出权重值。
[0027]
步骤七:根据相关系数和均方根误差修正权重,并进行时空插值结果的融合。
[0028]
根据模型精度评估结果(相关系数和均方根误差),对贝叶斯网络权重自学习法计算的权重进行修正,其目的是校正模拟精度低但权重高的插值结果,具体步骤为:(1)选取模拟结果较差(相关系数cc小于其25%分位数或rmse大于75%分位数)且权重大于或等于设定阈值的网格点;(2)针对上步筛选出的网格,比较插值结果权重w是否与模拟精度成正相关,则无需修正该网格权重系数,反之若不一致,则进入下一步;(3)对于需要修正权重系数的网格m,查找与网格m模拟精度相似的网格j,满足|cc
tm-cc
tj
|≤δ1且|cc
sm-cc
sj
|≤δ1,其中δ1为针对相关系数的设定阈值,或者|rmse
tm-rmse
tj
|≤δ2且|rmse
sm-rmse
sj
|≤δ2,其中δ2为针对均方根误差的设定阈值,则令w
tm
=w
tj
,w
sm
=w
sj
,若满足条件的网格j数量不唯一,则令w
tm
、w
sm
分别等于各网格时、空权重系数的均值。
[0029]
所述的对站点土壤含水量进行时空插值结果的融合,是指将土壤含水量的时间和空间插值结果进行融合,土壤含水量w的计算公式为:w=0.5
×
(α
t
×
y
t
+α
s
×
y
s
)+0.5
×
(β
t
×
y
t
+β
s
×
y
s
);其中,y
t
为长短期记忆神经网络模型得到的基于时间的插值结果,ys为全卷积神经网络模型得到的基于空间的插值结果,α
t
和α
s
为每一个网格点不同时间点的两种插值结果的权重,β
t
和β
s
为同一时间点时不同网格点的两种插值结果的权重。
[0030]
有益效果:与现有技术相比,本发明从时空维度综合分析气象、植被、土壤、地形因素对土壤含水量的影响,考虑前期土壤含水量对当下的影响,同时考虑各网格点之间土壤含水量的空间联系,使土壤含水量的模型模拟结果更精确。本发明采用深度学习中常用的长短期记忆神经网络和全卷积神经网络,有效提取各影响要素的特征,深度分析其与土壤含水量之间的内在联系,达到了较好的模拟结果。基于贝叶斯网络的权重自学习法能够通过自学习获取两种算法的权重,为插值结果的时空融合提供了有效途径。本发明显著提高了土壤含水量的插值精度,对于有缺失的土壤含水量资料的插值填补具有重要意义。
附图说明
[0031]
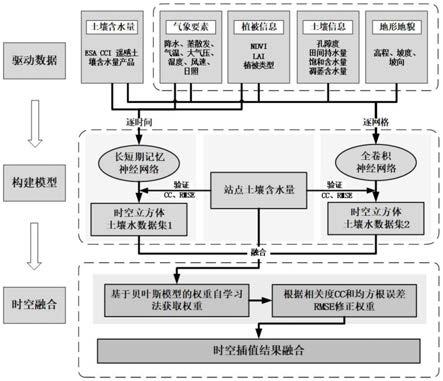
图1是本发明所述的基于深度学习的时空双向土壤含水量插值方法的流程图。
具体实施方式
[0032]
下面结合附图和实施例对本发明的技术方案作进一步的说明。
[0033]
本发明所述的基于深度学习的时空双向土壤含水量插值方法,其流程图如图1所示。包括以下步骤:
[0034]
步骤一:收集气象要素、植被参数、土壤信息、地形地貌条件和遥感土壤含水量esa cci数据,并进行归一化处理,将数据集拆分成训练集和验证集。
[0035]
气象要素主要指降水(包括当时降水和前期降水)、气温、蒸散发、风速、日照、空气湿度、大气压;植被参数主要为归一化植被指数ndvi、叶面积指数lai和植被类型;土壤信息主要有孔隙度、田间持水量、土壤饱和含水量和凋萎含水量;地形地貌包括高程、坡度、坡向。
[0036]
将数据集按照7∶3的比例随机拆分成训练集和验证集,并保证训练集中数据分布的有代表性和一致性。
[0037]
所述步骤一中的归一化的公式为:
[0038][0039]
其中,x
i
、o
i
分别为原始参数值与归一化后参数值;maxx
i
是该参数类别最大值;minx
i
是该参数类别最小值。
[0040]
步骤二:分别构建长短期记忆神经网络模型lsmt和全卷积神经网络模型fcnn;
[0041]
长短期记忆神经网络模型由输入层、隐含层、输出层构成,与传统神经网络不同的是其每个神经元有3个门结构来模拟神经细胞随时间变化的记忆过程,即元胞状态:第一阶段是遗忘门,决定哪些信息需要从细胞状态中被遗忘;下一阶段是输入门,确定哪些新信息能够被存放到细胞状态中;最后一个阶段是输出门,决定信息的输出。
[0042]
遗忘门是以上一层的输出和本层要输入的序列数据作为输入,通过一个激活函数sigmoid,得到输出为f
t
。f
t
的输出取值在[0,1]区间,表示上一层细胞状态被遗忘的概率,1是“完全保留”,0是“完全舍弃”。输入门包含两个部分,第一部分使用sigmoid激活函数,输出为i
t
,第二部分使用tanh激活函数,输出为,第二部分使用tanh激活函数,输出为为输入门的两个输出乘法运算,表示有多少新信息被保留。细胞状态的信息更新为c
t
。输出门用来控制该层的细胞状态有多少被过滤。首先使用sigmoid激活函数得到一个[0,1]区间取值的o
t
,接着将细胞状态c
t
通过tanh激活函数处理后与o
t
相乘,即是本层的输出h
t
。
[0043]
其数学表达式为:
[0044]
f
t
=σ(w
f
×
[h
t-1
,x
t
]+b
f
)
[0045]
i
t
=σ(w
i
×
[h
t-1
,x
t
]+b
i
)
[0046][0047][0048]
o
t
=σ(w
o
×
[h
t-1
,x
t
]+b
o
)
[0049]
h
t
=o
t
×
tanh(c
t
)
[0050]
其中,h
t-1
为上一层的输出,x
t
为这一层的输入,w、b为权重和偏置。
[0051]
全卷积神经网络模型与经典的卷积神经网络采用全连接层输出固定长度的特征向量不同,fcnn将末尾的全连接层全部转化成1
×
1卷积层,并通过反卷积、上采样和跳级结构输出与原始输入同尺寸的输出,保留原始输入的空间信息。
[0052]
所述全卷积神经网络采用fcn-16s的结构,反卷积步长为16。上采样采用反池化中的最大池化。
[0053]
步骤三:将归一化后的气象要素、植被参数、esa cci数据逐时间序列输入lsmt模型中,运行并得到逐时间的空间各网格点的土壤含水量;
[0054]
步骤四:将归一化后的气象要素、植被参数、土壤信息、地形地貌条件、esa cci数据逐空间网格排列的顺序输入到fcnn模型中,运行并得到逐空间网格点长时间序列土壤含水量;
[0055]
步骤五:将两种模型模拟得到的土壤含水量数据集分别与原遥感土壤含水量及各站点的土壤含水量进行验证比较,评估两种算法的精度;
[0056]
所述步骤五中模型模拟精度通过相关系数cc和均方根误差rmse进行验证。
[0057]
相关系数cc用于反映模拟结果与实测结果之间相关关系的密切程度,其值越接近于1,则说明模拟结果与实测结果相关程度越高,模拟精度越高,其计算公式为:
[0058][0059]
式中,w
sim
(i)为第i个月的模拟土壤含水量;w
obs
(i)为第i个月的实测土壤含水量;为实测土壤含水量的平均值;为模拟土壤含水量的平均值;n为数据个数。
[0060]
均方根误差rmse用于反映模拟结果与实测结果之间的离散程度,其值越小,说明模拟结果与实测结果离散程度越小,模拟精度越高,其计算公式为:
[0061][0062]
式中,w
sim
(i)为第i个月的模拟土壤含水量;w
obs
(i)为第i个月的实测土壤含水量;n为数据个数。
[0063]
步骤六:通过基于贝叶斯网络的权重自学习法获取两种模型插值结果的权重。
[0064]
权重自学习法是一种基于贝叶斯网络的的算法,通过反向误差传播和梯度下降法不断逼近权重值,其具体步骤为:(1)主观赋权,作为初始权值;(2)构建贝叶斯网络,设置目标误差值;(3)通过反向传播法和梯度下降法不断修正权重,直至误差小于目标值;(4)输出权重值。
[0065]
步骤七:根据相关系数和均方根误差修正权重,并进行时空插值结果的融合。
[0066]
根据模型精度评估结果(相关系数和均方根误差),对贝叶斯网络权重自学习法计算的权重进行修正,其目的是校正模拟精度低但权重高的插值结果,具体步骤为:(1)选取模拟结果较差(相关系数cc小于其25%分位数或均方根误差rmse大于75%分位数)且权重大于等于0.6的网格点;(2)针对上步筛选出的网格,比较插值结果权重w是否与模拟精度成正相关,例如时间模拟精度高于空间模拟精度且时间模拟结果权重较大(cc
t
≥cc
s
且w
t
≥w
s
),则无需修正该网格权重系数,反之若不一致,则认为该网格权重系数计算结果不合理,需要修正;(3)对于不合理的权重系数,查找满足条件的网格进行移植,例如某个权重不合理网格m,其cc
tm
<cc
sm
但w
tm
≥w
sm
,需要修正权重系数,则在所有网格中遍历查找网格j,满足|cc
tm-cc
tj
|≤0.1且|cc
sm-cc
sj
|≤0.1,令w
tm
=w
tj
,w
sm
=w
sj
,值得注意,若j数量不唯一,则令w
ti
等于其权重系数均值。对均方根误差rmse来说,遍历网格的阈值设为0.01为佳,即满足|rmse
tm-rmse
tj
|≤0.01且|rmse
sm-rmse
sj
|≤0.01,则移植相应的权重系数。
[0067]
时空插值结果的融合即同时考虑时间和空间因素,利用基于贝叶斯网络的权重自学习法,以站点土壤含水量为验证,将两种插值结果分别按照时间顺序和空间顺序计算得到每一个时间点每一个空间网格点的权重w,修正后得到每一个网格点不同时间点的时间和空间插值结果的权重α
t
和α
s
,同一时间点时不同网格点的权重β
t
和β
s
。则不同的网格不同时间节点的土壤含水量w=0.5
×
(α
t
×
y
t
+α
s
×
y
s
)+0.5
×
(β
t
×
y
t
+β
s
×
y
s
)。其中,y
t
为长短期记忆神经网络lstm得到的基于时间的插值结果,y
s
为全卷积神经网络fcnn得到的基于空间的插值结果。
相关技术
网友询问留言
已有0条留言
- 还没有人留言评论。精彩留言会获得点赞!
1