一种基于人工智能分词技术的警情数据治理方法与流程
[0001]
本发明涉及数据治理方法技术领域,尤其涉及一种基于人工智能分词技术的警情数据治理方法。
背景技术:
[0002]
随着城市和经济的发展,接处警工作量日益繁忙,多年接处警工作,产生大量的警情数据,警情作为公安机关的第一手资源,有着全面、丰富的信息资源,不仅能多维度的从宏观上反映社会治安形势,从微观上更是能具体到某一条警情或者某一类警情,针对警情信息的研判和挖掘,可以帮助公安机会分析社会治安形势、发现治安工作焦点、科学调整警力部署、实施定向精确打击、评估公安工作绩效,使公安机关各个管理部门的有效基于警情信息分享的协同整治治安,从而达到辅助决策预防打击的最终目标。然后由于诸多原因,警情数据质量良莠不齐,无法直接进行数据挖掘,进而发现历史警情的规律与价值,从而对当前工作进行有效改进提升。对于庞大的历史警情数据,需要提供基于人工智能的信息化系统,对数据进行治理和数据质量核查。
技术实现要素:
[0003]
为解决背景技术中存在的技术问题,本发明提出一种基于人工智能分词技术的警情数据治理方法。
[0004]
本发明提出的一种基于人工智能分词技术的警情数据治理方法,包括:
[0005]
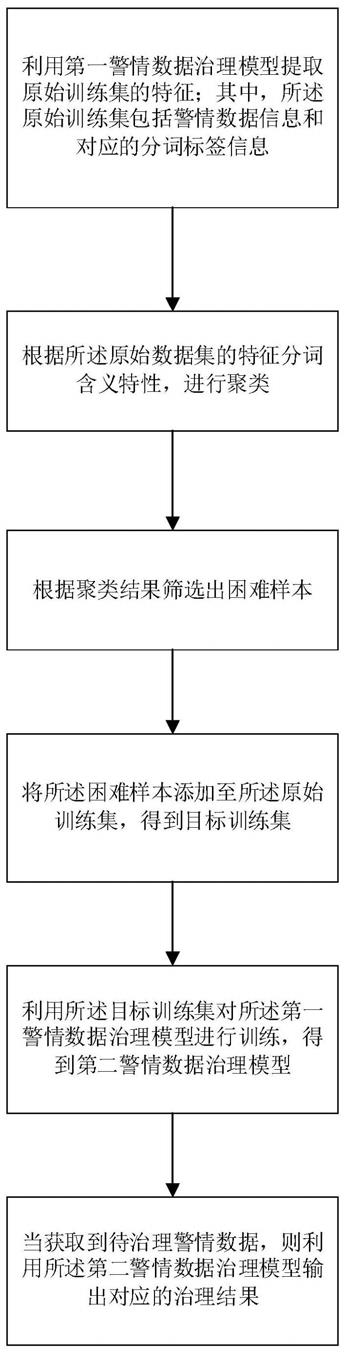
利用第一警情数据治理模型提取原始训练集的特征;其中,所述原始训练集包括警情数据信息和对应的分词标签信息;
[0006]
根据所述原始数据集的特征分词含义特性,进行聚类;
[0007]
根据聚类结果筛选出困难样本;
[0008]
将所述困难样本添加至所述原始训练集,得到目标训练集;
[0009]
利用所述目标训练集对所述第一警情数据治理模型进行训练,得到第二警情数据治理模型;
[0010]
当获取到待治理警情数据,则利用所述第二警情数据治理模型输出对应的治理结果。
[0011]
可选的,所述利用第一警情数据治理模型提取原始训练集的特征之前,还包括:
[0012]
利用同一预设训练集分别对不同的初始模型进行训练,得到多个训练后模型;不同的所述初始模型基于不同的警情数据分词算法;
[0013]
基于预设测评指标对全部所述训练后模型进行测评,确定出警情数据治理精确度最高的训练后模型,得到所述第一警情数据治理模型。
[0014]
可选的,所述根据所述原始数据集的特征分词含义特性,进行聚类,包括:
[0015]
根据所述原始数据集的特征分词含义特性,利用kmeans算法进行聚类。
[0016]
可选的,所述根据聚类结果筛选出困难样本,包括:
[0017]
筛选出聚类结果与所述分词标签信息不同的样本,得到第一样本。
[0018]
可选的,所述根据聚类结果筛选出困难样本,包括:
[0019]
基于bvsb准则筛选出第二样本。
[0020]
可选的,所述基于bvsb准则筛选出第二样本,包括:
[0021]
计算任一样本与各聚类中心的第一差异度;
[0022]
将所述第一差异度转换为对应的概率值;
[0023]
从任一样本的全部所述概率值中确定出最大概率值和次大概率值;
[0024]
判断当前样本对应的所述最大概率值和所述次大概率值的差值是否小于预设阈值;
[0025]
若当前样本对应的所述最大概率值和所述次大概率值的差值小于所述预设阈值,则判定当前样本为第二样本。
[0026]
可选的,所述根据聚类结果筛选出困难样本,包括:
[0027]
计算同一聚类中每个样本与当前聚类中心的第二差异度;
[0028]
从所述第二差异度中筛选出最大差异度和最小差异度;
[0029]
利用所述最大差异度和所述最小差异度,确定出差异度阈值;
[0030]
判断任一所述第二差异度是否大于所述差异度阈值;
[0031]
若所述第二差异度大于所述差异度阈值,则将对应的样本确定为第二样本。
[0032]
本发明中,所提出的基于人工智能分词技术的警情数据治理方法,先利用第一警情数据治理模型提取原始训练集的特征;其中,所述原始训练集包括警情数据信息和对应的分词标签信息,然后根据所述原始数据集的特征分词含义特性,进行聚类,之后根据聚类结果筛选出困难样本,并将所述困难样本添加至所述原始训练集,得到目标训练集,然后利用所述目标训练集对所述第一警情数据治理模型进行训练,得到第二警情数据治理模型,当获取到待治理警情数据,则利用所述第二警情数据治理模型输出对应的治理结果。这样,挖掘出困难样本,通过挖掘出的困难样本改变原始数据集中的样本分布,能够增加对困难样本的关注度,从而提升警情数据治理的准确度。
附图说明
[0033]
图1为本发明提出的一种基于人工智能分词技术的警情数据治理方法的流程框图。
具体实施方式
[0034]
如图1所示,图1为本发明提出的一种基于人工智能分词技术的警情数据治理方法的结构示意图。
[0035]
参照图1,本发明提出的一种基于人工智能分词技术的警情数据治理方法,包括:
[0036]
利用第一警情数据治理模型提取原始训练集的特征;其中,原始训练集包括警情数据信息和对应的分词标签信息;
[0037]
根据原始数据集的特征分词含义特性,进行聚类;
[0038]
根据聚类结果筛选出困难样本;
[0039]
将困难样本添加至原始训练集,得到目标训练集;
[0040]
利用目标训练集对第一警情数据治理模型进行训练,得到第二警情数据治理模型;
[0041]
当获取到待治理警情数据,则利用第二警情数据治理模型输出对应的治理结果。
[0042]
可选的,利用第一警情数据治理模型提取原始训练集的特征之前,还包括:
[0043]
利用同一预设训练集分别对不同的初始模型进行训练,得到多个训练后模型;不同的初始模型基于不同的警情数据分词算法;
[0044]
基于预设测评指标对全部训练后模型进行测评,确定出警情数据治理精确度最高的训练后模型,得到第一警情数据治理模型。
[0045]
可选的,根据原始数据集的特征分词含义特性,进行聚类,包括:
[0046]
根据原始数据集的特征分词含义特性,利用kmeans算法进行聚类。
[0047]
可选的,根据聚类结果筛选出困难样本,包括:
[0048]
筛选出聚类结果与分词标签信息不同的样本,得到第一样本。
[0049]
可选的,根据聚类结果筛选出困难样本,包括:
[0050]
基于bvsb准则筛选出第二样本。
[0051]
可选的,基于bvsb准则筛选出第二样本,包括:
[0052]
计算任一样本与各聚类中心的第一差异度;
[0053]
将第一差异度转换为对应的概率值;
[0054]
从任一样本的全部概率值中确定出最大概率值和次大概率值;
[0055]
判断当前样本对应的最大概率值和次大概率值的差值是否小于预设阈值;
[0056]
若当前样本对应的最大概率值和次大概率值的差值小于预设阈值,则判定当前样本为第二样本。
[0057]
可选的,根据聚类结果筛选出困难样本,包括:
[0058]
计算同一聚类中每个样本与当前聚类中心的第二差异度;
[0059]
从第二差异度中筛选出最大差异度和最小差异度;
[0060]
利用最大差异度和最小差异度,确定出差异度阈值;
[0061]
判断任一第二差异度是否大于差异度阈值;
[0062]
若第二差异度大于差异度阈值,则将对应的样本确定为第二样本。
[0063]
在本实施例中,所提出的基于人工智能分词技术的警情数据治理方法,先利用第一警情数据治理模型提取原始训练集的特征;其中,所述原始训练集包括警情数据信息和对应的分词标签信息,然后根据所述原始数据集的特征分词含义特性,进行聚类,之后根据聚类结果筛选出困难样本,并将所述困难样本添加至所述原始训练集,得到目标训练集,然后利用所述目标训练集对所述第一警情数据治理模型进行训练,得到第二警情数据治理模型,当获取到待治理警情数据,则利用所述第二警情数据治理模型输出对应的治理结果。这样,挖掘出困难样本,通过挖掘出的困难样本改变原始数据集中的样本分布,能够增加对困难样本的关注度,从而提升警情数据治理的准确度。
[0064]
以上所述,仅为本发明较佳的具体实施方式,但本发明的保护范围并不局限于此,任何熟悉本技术领域的技术人员在本发明揭露的技术范围内,根据本发明的技术方案及其发明构思加以等同替换或改变,都应涵盖在本发明的保护范围之内。
相关技术
网友询问留言
已有0条留言
- 还没有人留言评论。精彩留言会获得点赞!
1