基于数据增强的英文标点符号添加方法和系统及设备与流程
本发明涉及语音识别技术领域,具体涉及一种基于数据增强的英文标点符号添加方法和系统及设备。
背景技术:
近几年来,借助机器学习,深度学习领域的迅速发展,以及大数据语料的积累,语音识别技术得到突飞猛进的发展。如今,随着语音识别技术研究的突破,通过语音识别技术,将人们的语言转化成文字识别结果作为指令加到相关产品或作为最终结果,可大大提升人机交互效率,其对计算机发展和社会生活的重要性日益凸显出来,以语音识别技术开发的产品应用领域也越来越广泛,如智能会议系统、医疗服务、银行服务等等,几乎深入到社会的每个行业和每个方面。如百度、腾讯、阿里等公司都提供了云服务,上传一段音频以及这段音频的采样率等相关信息,可返回这段音频的文字内容。
当前流行的语音识别系统在语音识别过程中,语音识别系统将语音内容转化为英文、汉字或者数字等文字。当接收的语音内容是一连串的语音或者文档级的语音时,大部分的语音识别系统会转成一连串的文字,而没有标点信息,这样的转写结果可读性很差,给人们造成阅读障碍。如果适当的给转写后的文本加上标点符号,会大大地提升文本的可懂度。
近年来越来越多的研究人员投入到面向语音转写的标点预测研究中,为了恢复或预测语音转写的标点符号,人们做了许多努力。早期的尝试提出将标点符号作为隐藏事件添加到语言模型中,并将这些知识整合到语音识别系统中。最近的趋势倾向于使用独立的标点预测模块,将其作为后处理的方式加到语音识别系统中。最近的研究中,将其作为独立模块的方法主要分为三大类:一、基于声学特征的标点预测,二、基于文本特征的标点预测,三、基于声学特征和文本特征的标点预测。
其中,基于声学特征的标点预测需要音频作为输入,音频处理比文本处理相较复杂,并且很容易受口语化的影响,标点预测的准确性会受影响。另外,基于文本和声学特征的标点预测,它的输入包含文本和音频,要求文本内容和音频内容相对齐,并且语音转写结果存在着一些误差,会造成计算复杂,这种方法运算量较大且训练数据难以获取。而基于本文的标点预测仅仅将文本数据作为数据,几乎可以考虑任何文本材料,而且非常容易获得,并且可以很自由地用于声学特征的后期融合。考虑这些事实,一个好的基于文本特征的标点预测研究算法是广泛适用的。
现有的大多数基于文本特征的英文标点预测研究技术都是在标准无误的文本数据(网上大量获取数据)上训练模型的,例如标准文本:“helloeveryone,it'sapleasuretosharemythoughtswithyoutoday.thethemeofmyspeechispunctuationprediction.”。但是在真正的英文语音识别系统中,系统识别的结果并不全是正确的转写结果,例如:“helloeveryoneapleasuretosharermythoughtswithyoutodaythethemeofmyspeechispunctuationpredictionuh”,与真实的内容存在一些差异。在语音识别系统中存在着三种错误:插入错误(例如上述转写结果例子中最后的“uh”词,属于语气词)、漏字错误(例如上述转写结果例子中的“it's”词缺失)以及替换错误(例如上述转写结果例子中的”sharer”,实际中应该是“share”)。所以在这种情况下标点预测会根据这种文本预测,也会产生差异,造成标点符号预测出错。因此,在英文中标点预测时,直接拿标准文本数据去训练一个标点符号预测模型,实际上忽略了真实环境中的带有错误的文本,导致效果不佳。
现有技术手段要想处理这种问题,首先想到的是在训练模型过程中,加入大量的真实文本带有正确的标点符号的数据。但是事实中,这种大规模的带有正确标点符号的数据获取需要人工去标注,是很费时费力的。
技术实现要素:
本发明的目的在于提供一种基于数据增强的英文标点符号添加方法和系统及设备,用于解决现有的基于文本特征的英文标点符号预测研究技术效果不佳的问题,以解决语音转写标点符号恢复问题。
为实现上述目的,本发明采用如下技术方案。
第一方面,提供一种基于数据增强的英文标点符号添加方法,包括:获取文本信息并进行预处理,得到包括单词序列和对应的标签序列的训练数据,标签序列中的标签表示单词序列中对应的单词后面应添加的标点符号;对训练数据进行数据增强处理,所述数据增强包括随机删除、随机替换、随机音似词替换和随机插入,得到增强后的数据;将增强前的原数据和增强后的数据整合到一起作为训练数据集;利用训练数据集进行模型训练,得到预测模型,该预测模型用于给输入的文本信息添加英文标点符号。
在一种可能的实现方式中,所述预处理包括数据清洗和数据标准化;所述数据清洗包括:首先对文本信息中的标点符号进行替换,将逗点、句点和问号以外的标点符号替换成逗点、句点或问号;所述数据标准化包括:将文本信息中每一个单词对应到一个标签,所述标签包括:表示逗点的标签c、表示句点的标签p、表示问号的标签q和无符号标签o。
在一种可能的实现方式中,所述随机删除包括:按预设比例随机删除训练数据中的一些单词,其中,如果拟删除的单词对应的标签为o,则单词序列中删除该单词,标签序列中删除对应的标签;如果拟删除的单词对应的标签为c、p或q,则单词序列中删除该单词,但标签序列中保留对应的标签,删除上一个单词对应的标签。
在一种可能的实现方式中,所述随机替换包括:按预设比例随机替换训练数据中的一些单词,对应的标签序列不做变化。
在一种可能的实现方式中,所述随机插入包括:按预设比例随机选择一些单词插入到训练数据中,其中,如果插入的位置在句首或句子中间,则在标签序列中对应添加标签o;如果插入的位置在句末,则将插入单词的标签换成前面一个单词的标签,而将前面一个单词的标签替换成标签o。
在一种可能的实现方式中,所述随机音似词替换包括:按预设比例随机选择一些与训练数据中单词发音相似的单词来替换训练数据中的单词,对应的标签序列不做变化。
在一种可能的实现方式中,所述按预设比例随机选择一些与训练数据中单词发音相似的单词来替换训练数据中的单词,包括:提供单词词库,将词库中所有单词转换成音素序列;通过字符串相似度算法,从词库中找出与训练数据中每个单词的发音相似度最高的若干个单词作为音似词,生成一个音似词词表;按预设比例从训练数据中随机选择一些需要被替换的单词,然后从音似词词表中随机挑选对应的音似词,来替换训练数据中需要被替换的单词。
第二方面,提供一种基于数据增强的英文标点符号添加系统,包括:获取模块,用于获取文本信息;预处理模块,用于对获取的文本信息进行预处理,得到包括单词序列和对应的标签序列的训练数据,标签序列中的标签表示单词序列中对应的单词后面应添加的标点符号;数据增强模块,用于对训练数据进行数据增强处理,所述数据增强包括随机删除、随机替换、随机音似词替换和随机插入,得到增强后的数据;将增强前的原数据和增强后的数据整合到一起作为训练数据集;模型训练模块,用于利用训练数据集进行模型训练,得到预测模型,该预测模型用于给输入的文本信息添加英文标点符号。
第三方面,提供一种计算机设备,包括处理器和存储器,所述存储器中存储有程序,所述程序包括计算机执行指令,当所述计算机设备运行时,所述处理器执行所述存储器存储的所述计算机执行指令,以使所述计算机设备执行如第一方面所述的基于数据增强的英文标点符号添加方法。
第四方面,提供一种存储一个或多个程序的计算机可读存储介质,所述一个或多个程序包括计算机执行指令,所述计算机执行指令当被计算机设备执行时,使所述计算机设备执行如第一方面所述的基于数据增强的英文标点符号添加方法。
从以上技术方案可以看出,本发明实施例具有以下优点:
首先,本发明采用数据增强技术对训练数据进行处理,来模拟真实数据,跟标注大量的真实带有标点的真实文本相比,可节约人力和减少成本。
相对现有的基于文本特征的标点预测方法相比,本发明增加了数据增强处理步骤,从而使网络模型更加的鲁棒,但是运算量并没有增加,只是在训练阶段增大了训练数据;并且,本发明由于是基于增强后的数据进行的模型训练,与现有的基于文本特征的标点预测方法相比,在语音识别系统中效果更优。
附图说明
为了更清楚地说明本发明实施例技术方案,下面将对实施例和现有技术描述中所需要使用的附图作简单地介绍,显而易见地,下面描述中的附图仅仅是本发明的一些实施例,对于本领域普通技术人员来讲,在不付出创造性劳动的前提下,还可以根据这些附图获得其它的附图。
图1是本发明实施例提供的一种基于数据增强的英文标点符号添加方法的流程示意图;
图2是本发明实施例中数据增强过程的示意图;
图3是本发明实施例中模型训练过程的示意图;
图4是本发明实施例中模型测试过程的示意图;
图5是本发明实施例中训练g2p模型的示意图;
图6是本发明实施例中计算因素相似度过程的示意图;
图7是本发明实施例提供的一种基于数据增强的英文标点符号添加系统的结构示意图;
图8是本发明实施例提供的一种计算机设备的结构示意图。
具体实施方式
为了使本技术领域的人员更好地理解本发明方案,下面将结合本发明实施例中的附图,对本发明实施例中的技术方案进行清楚、完整地描述,显然,所描述的实施例仅仅是本发明一部分的实施例,而不是全部的实施例。基于本发明中的实施例,本领域普通技术人员在没有做出创造性劳动前提下所获得的所有其他实施例,都应当属于本发明保护的范围。
本发明的说明书和权利要求书及上述附图中的术语“第一”、“第二”、“第三”等是用于区别不同的对象,而不是用于描述特定顺序。此外,术语“包括”和“具有”以及它们任何变形,意图在于覆盖不排他的包含。例如包含了一系列步骤或单元的过程、方法、系统、产品或设备没有限定于已列出的步骤或单元,而是可选地还包括没有列出的步骤或单元,或可选地还包括对于这些过程、方法、产品或设备固有的其它步骤或单元。
下面通过具体实施例,分别进行详细的说明。
本发明实施例提供一种基于数据增强的英文标点符号添加方法。该方法是基于现有的文本特征的标点预测技术进行的改进,主要解决语音转写标点恢复问题,用来在英文语音识别的基础上进行后处理,给识别的文本加上合适的标点符号。本申请主要用来解决现有技术通常采用标准无误的文本数据训练模型,导致与真实环境不一致,预测效果不好的问题。
该方法主要由三个大的部分组成,一个是训练数据增强,一个是模型训练,最后一个是模型测试。训练数据增强部分主要是获取互联网中的文本信息,例如从维基百科(wikipedia)获取文本信息,然后利用进行数据预处理,对预处理后的数据进行数据增强处理,得到后续模型训练所需要的训练数据。模型训练部分主要是通过大规模的训练数据来训练一个给输入文本添加标点符号的预测模型,以便后来使用时,输入一个文本内容,输出一个带标点符号的文本内容并反馈给语音识别系统。模型测试部分主要是当模型训练完毕时,用来接收语音识别系统输入的文本,通过预测模型得出输出文本再返回给语音识别系统。
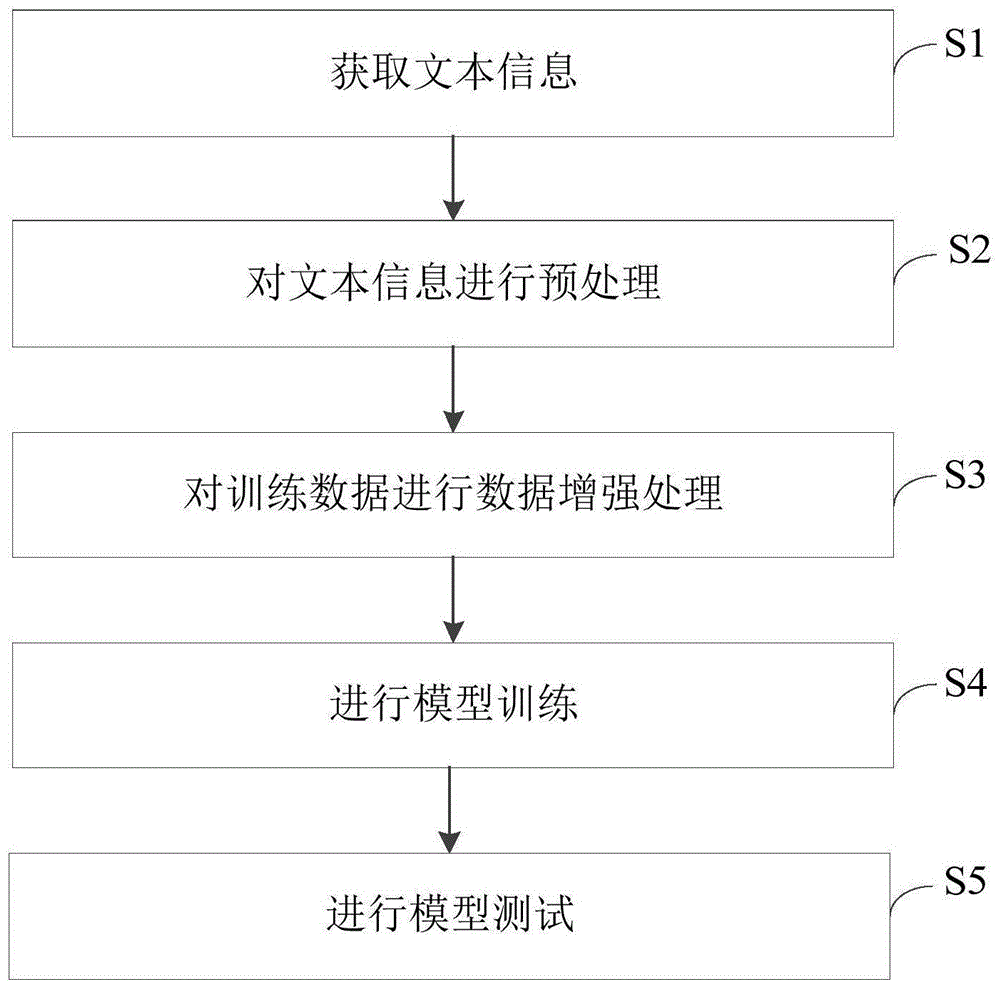
请参考图1,所述方法可包括:
s1、获取文本信息。
s2、对文本信息进行预处理。
所述预处理包括数据清洗和数据标准化,预处理后得到包括单词序列和对应的标签序列的训练数据,标签序列中的标签表示单词序列中对应的单词后面应添加的标点符号。
其中,所述数据清洗可包括:对文本信息中的标点符号进行替换,将逗点、句点和问号以外的标点符号替换成逗点、句点或问号;所述数据标准化可包括将文本信息中每一个单词对应到一个标签,所述标签包括:表示逗点的标签c、表示句点的标签p、表示问号的标签q和无符号标签o。
s3、对训练数据进行数据增强处理。
所述数据增强包括随机删除、随机替换、随机音似词替换和随机插入,得到增强后的数据;将增强前的原数据和增强后的数据整合到一起作为训练数据集。
s4、进行模型训练。
利用训练数据集进行模型训练,得到预测模型,该预测模型用于给输入的文本信息添加英文标点符号。
s5、进行模型测试。
接收语音识别系统输入的文本信息,通过所述预测模型输出添加了英文标点符号的文本信息给所述语音识别系统。
下面,详细说明上述各个步骤。
(一)训练数据增强部分。
1.1获取文本信息。
a)互联网上已有大量的文本信息。根据任务的需求,对于指定的英文范围的新闻网页(新闻文章一般具有标准的标点符号,称为目标网页),首先利用网络爬虫抓取原始的带大篇幅正文的网页信息,可以是利用现有技术手段实现。
b)针对网页中含有的各种信息,首先将网页中文本部分本别提取出来。网页中的文本分为两类,一种是各种标题,按钮等无标点符号文本。另一种是带有标点符号的大篇幅的正文。
c)正文提取过程如下(可利用已有技术):
c.1)读入网页的html文档(dh1),利用已有工具,例如微软的xmlparser或其他工具把html文档转换为树形结构(dtr1);
c.2)如果是常见网站,利用事先定义的模板(tpl),把树形结构的html文档(dtr1)中和tpl中正文对应部分提取出来,即为正文,存入txt文件中。
从而得到所需要的文本信息(或称为文本数据)。
1.2文本信息预处理
a)首先对文本信息进行数据清洗。
a.1)爬取的文本的各行中存在着大量的特殊字符,我们需要按照给定的词库进行数据清洗;
a.2)将文本中无标点符号的行和末尾没有标点符号的行删除;
a.3)按照指定的预留的标点符号进行替换(即只保留想预测的标点)。
本实施例中,只保留英文中的逗点“,”、句点“.”和问号“?”,而将逗点、句点和问号以外的标点符号均替换成逗点、句点或问号,因为这三个标点足以使我们去理解文本内容。可选的,可以将“:;-”替换成“,”,将“...!”替换成“.”,另外其他除了逗点、句点和问号全部删除。
清洗完的文本数据,可以按行数比例3:1:1切分成多个集合,例如训练数据集、验证数据集以及测试数据集。
b)其次对文本信息进行数据标准化。
在基于文本的标点预测研究中,大多数方法使用序列标签预测方法进行数据标准化。本文中,数据标准化同样采用序列标签预测技术,将文本信息中每一个单词对应到一个标签,该标签表示对应的单词后面应添加的标点符号。
需要注意,这里是将三个集合中的训练数据、验证数据以及测试数据,分别按照序列标签的格式进行数据标准化,将其中的每个单词均对应到一个标签,从而得到单词序列以及对应的标签序列。预处理后得到的训练数据就包括单词序列和对应的标签序列。
本申请只预测三种标点:逗点、句点和问号,对应的标签分别为:c、p、q;再加上无符号标签o,一共使用四种标签。标准化时,将文本信息中每一个单词对应到四种标签中的一个。
举例说明:原文为“hello,iwanttotellyousomething.”。转成序列标签时,它的单词序列为“helloiwanttotellyousomething”,则它的标签序列为“cooooop”。词“hello”对应的”c”表示hello后面加逗点”,”。同样如此“something”对应的“p”表示something后面加句点“.”。标签“o”表示此单词后面什么也不加。
1.3数据增强
本文中,数据增强包括随机删除、随机替换、随机音似词替换和随机插入。
在真实的英文语音识别场景中,通常存在着三种转写错误:漏字错误、替换错误和插入错误。由于用标准数据集训练的模型对这种场景时,标点预测的结果并不理想,所以我们用数据增强的方法去模拟真实场景的数据,达到训练的模型更加鲁棒的目的。
c.1)随机删除,即按预设的一定比例随机删除训练数据中的一些单词。由于例如:“helloeveryoneit'sapleasuretosharemythoughtswithyoutoday”,它的标签是:“ocooooooooop”。我们对其随机删除,会存在两种情况,若拟删除的单词,它的标签“o”,则单词序列直接删除此单词,标签序列删除对应的标签,如上例中删除的是“hello”,则词序列为:“everyoneit'sapleasuretosharemythoughtswithyoutoday”,标签序列为“cooooooooop”,“hello”对应的标签同时也被删除。若拟删除的单词它的标签是对应的标点符号标签“c”、“p”或者“q”,则单词序列删除此单词,而标签序列保留此词的标签,删除上一个单词的标签。如上述例子中,若删除的是“everyone”,则它的词序列为:“helloit'sapleasuretosharemythoughtswithyoutoday”,标签序列为“cooooooooop”,“everyone”对应得标签“c”保留得下来。这样做得原因是随机删除某个单词时它尾部得标点符号应该保留。
c.2)随机替换,即按预设的一定比例随机替换训练数据中的一些单词。例如:“helloeveryoneit'sapleasuretosharemythoughtswithyoutoday”,它的标签是:“ocooooooooop”。我们首先从预先准备好的词库(整理好的英文单词词库)中随机挑选一个单词,替换掉句子中随机选中的单词,和随机删除不一样的是,随机替换操作中,标签序列不做变化。
c.3)随机音似词替换,即按预设的一定比例随机选择一些与训练数据中单词发音相似的单词来替换训练数据中的单词。
由于在英文中有人归纳了一些同音词:如“to”和“too”发音一样。但是音似词是不仅指发音相同,更指发音相似的单词,例如“stew”和“too”发音相似。在语音识别系统中,这种错误大量存在,所以我们想到用音似词替换。要实现音似词替换,就需要音似词词表,本文采用词到音素的转换方法,音素是单词的发音的最小组成单位。本文将预先提供的单词词库中所有单词转换成音素序列。
可选的,可采用g2p(grapheme-to-phoneme,字音转换,现有技术)工具将词库中所有单词转换成音素序列。g2p工具是利用序列到序列的模型,可以训练一个由单词到音素的模型,输入一个单词可以获取几个发音音素序列。
首先,可训练一个g2p工具,如图5所示,训练的词典可选取cmu词典(卡内基梅隆发音词典)。
训练完g2p模型,可输入一个单词进入到g2p模型,就可以得到多个候选音素序列p={p1,p2,...,pk},pk是音素序列。可选择最优的两个发音序p={p1,p2}。有了音素序列,我们就可以比较各个单词之间在音素序列上的相似度,可利用字符串相似度算法如editdistance(编辑距离算法,由俄国科学家发明,又称levenshtein距离)计算相似度,公式为:s(s1,s2),s1,s2分别是两个序列。用此算法求两个单词之间的音素相似度,s1、s2越相似则s(s1,s2)越大。如单词w1的两个音素序列为:pw1={pw1,1,pw1,2},单词w2的两个音素序列为:pw2={pw2,1,pw2,2}。两两比较音素序列的相似度得分,最终我们取得最高分作为两个单词之间的得分score=max(s(pw1,1,pw2,1),s(pw1,1,pw2,2),s(pw1,2,pw2,1),s(pw1,2,pw2,2)),如图6所示。
本实施例中,通过将词库中所有的单词用g2p工具转换成音素序列,再通过字符串相似度算法找到每个单词的最相似的若干个例如top3的单词,做一个音似词词表,该词表中一个单词对应其三个音似词。在做随机音似词替换时,可按照一定的预设比例从训练数据中挑选被替换的词,然后从音似词词表中再随机挑选一个音似词作替换。替换的规则类似于随机替换,即,对应的标签序列不做变化。
c.4)随机插入,即按预设的一定比例从词库中随机选择一些单词插入到训练数据的句子中。这存在两种情况:一、插入的位置在句首和句子,则在相应的标签序列添加“o”标签;二、插入的位置在句末,则需要将前一个单词的标点标签替换成“o”,将插入词的标签换成前面一个词的标点标签。
上述四种增强方法中预设比例可介于5%到10%之间。
1.4训练数据整合
在上述的数据增强操作后,可得到最多四份增强后的数据,再加上一份替换前的原数据,一共五份数据。可将五份数据全部整合到一起组成一个大的训练数据集,用于下一阶段模型训练使用。
(二)模型训练阶段
2.1输入特征表示
单词序列是纯文本形式,要转换成电脑可计算的数值,需要将文本数据进行编码,再输入到模型中。本文选择使用roberta的特征表示方法,将输入的文本转换成三个编码向量相结合的形式:词编码、位置编码、句子编码。
词编码:将词转换成词向量特征。
位置编码:用来表示词与词之间的顺序信息。
句子编码:表示当前词输入哪个句子,若输入有多个句子,可以用以区分。
roberta(arobustlyoptimizedbertpretrainingapproach)是一种现有技术,其成功在11项nlp任务中取得不错的结果,赢得自然语言处理学界的一片赞誉之声,可将其应用于本发明的任务中。
2.2特征提取
在输入特征表示完成之后,可以获取到这个输入的特征向量,然后将这个特征向量输入到预训练语言模型,例如roberta的transformer(roberta中使用,最大有24个,现有技术)层,经过transformer层后,可以得到一个鲁棒的特征向量用于后面的分类。
2.3分类器
本文选择crf(条件随机场,现有技术),作为分类器。连续的词之间具有一定的联系,所以选择crf对整个序列预测打分,通过模型训练优化,crf会选择一个最优的标签序列结果。训练时与真实标签序列进行比较,从而优化整个模型。最后得到一个用于给输入的文本信息添加英文标点符号的预测模型。
总的来说,训练阶段我们选择roberta作为特征提取工具,选择crf作分类器,用于微调roberta模型实现标点预测算法。可选的,可以将roberta模型替换成其他特征提取网络;可以将crf替换成其他的分类器。
(三)模型测试阶段
测试阶段,跟模型训练阶段大部分都一样,输入是一段来自语音识别系统的无符号文本。数据流经过特征表示层、transformer层到crf分类器得到标签序列。与模型训练阶段不同的是,在测试阶段,模型不参与训练,固定模型中所有参数,并且在得到标签序列后,需要将标签转化为标点符号加入到词序列中得到最终的带有标点符号的结果,再返回给语音识别系统中。
以上,对比本发明实施例公开了的基于数据增强的英文标点符号添加方法,进行了详细说明。
最后,申请人在公开的英文标点数据集iwslt上做了实验,iwslt数据集提供了在语音识别系统后的转写结果,且对其标注了标点符号。数据集中含有三个标点符号:逗点,句点和问号。度量他们的标准是准确率(p值),召回率(r值)和f值。模型在数据增强前和增强后在iwslt数据集上的的p、r、f值的结果对比如表1所示。
表1
从上面表中可以看出,数据增强之后,每个标点符号的f值都有提升,说明了本文的增强方法是有效的,并且数据增强后的模型比没有数据增强的模型在整体f值度量上高了4.46个点。
如上,本实施例方法通过对文本信息进行数据增强处理,来提升训练得到的模型的预测效果。关键在于:
1.在英文标点预测任务中提出了4种数据增强的方法,即随机删除、随机替换、随机音似词替换和随机插入;
2.在随机音似词替换时,采用的并不是简单的同音词,而是发音相似的词,利用g2p工具将词库中的所有词转换成音素序列,并用字符串相似度算法(编辑距离算法)为每个词求出它最相似的三个词并制作成一个新的词典:一个词对应它发音最相似的三个词。在音似词替换时,我们再随机从这三个发音最相似词中挑选一个替换被替换的词。
从以上技术方案可以看出,本发明实施例具有以下优点:
首先,本发明采用数据增强技术对训练数据进行处理,来模拟真实数据,跟标注大量的真实带有标点的真实文本相比,可节约人力和减少成本。
相对现有的基于文本特征的标点预测方法相比,本发明增加了数据增强处理步骤,从而使网络模型更加的鲁棒,但是运算量并没有增加,只是在训练阶段增大了训练数据;并且,本发明由于是基于增强后的数据进行的模型训练,与现有的基于文本特征的标点预测方法相比,在语音识别系统中效果更优。
请参考图7,本发明实施例还提供一种基于数据增强的英文标点符号添加系统,可包括:
获取模块71,用于获取文本信息;
预处理模块72,用于对获取的文本信息进行预处理,得到包括单词序列和对应的标签序列的训练数据,标签序列中的标签表示单词序列中对应的单词后面应添加的标点符号;
数据增强模块73,用于对训练数据进行数据增强处理,所述数据增强包括随机删除、随机替换、随机音似词替换和随机插入,得到增强后的数据;将增强前的原数据和增强后的数据整合到一起作为训练数据集;
模型训练模块74,用于利用训练数据集进行模型训练,得到预测模型,该预测模型用于给输入的文本信息添加英文标点符号;
以及,模型测试模块75,用于接收语音识别系统输入的文本信息,利用所述预测模型输出添加了英文标点符号的文本信息给所述语音识别系统。
请参考图8,本发明实施例还提供一种计算机设备80,包括处理器81和存储器82,所述存储器82中存储有程序,所述程序包括计算机执行指令,当所述计算机设备80运行时,所述处理器81执行所述存储器82存储的所述计算机执行指令,以使所述计算机设备80执行如上文所述的基于数据增强的英文标点符号添加方法。
本发明实施例还提供一种存储一个或多个程序的计算机可读存储介质,所述一个或多个程序包括计算机执行指令,所述计算机执行指令当被计算机设备执行时,使所述计算机设备执行如上文所述的基于数据增强的英文标点符号添加方法。
综上,对本发明实施例公开了的一种基于数据增强的英文标点符号添加方法和系统及设备进行了详细说明。
在上述实施例中,对各个实施例的描述都各有侧重,某个实施例中没有详细描述的部分,可以参见其它实施例的相关描述。
上述实施例仅用以说明本发明的技术方案,而非对其限制;本领域的普通技术人员应当理解:其依然可以对上述各实施例所记载的技术方案进行修改,或者对其中部分技术特征进行等同替换;而这些修改或者替换,并不使相应技术方案的本质脱离本发明各实施例技术方案的精神和范围。
- 还没有人留言评论。精彩留言会获得点赞!