信息推荐方法及装置和构建邻域知识图谱的方法及装置与流程
1.本技术涉及但不限于互联网技术,尤指一种信息推荐方法及装置和构建邻域知识图谱的方法及装置。
背景技术:
2.在用户的购物决策过程中,搜索技术与推荐技术可以帮助用户更加快速地找到想要的商品。但是,在很多时候,用户并不是很清楚什么样的商品可以解决问题,或者用户需要了解很多的商品细节后才能进行决策。
3.用户的购物流程大致包括:需求识别、信息搜索、候选评估、购买决策和售后行为。相关技术中,大多数电商平台主要采用搜索和推荐的方式来帮助用户实现购物,这个过程中,用户需要先从站外(如搜索引擎)搜索解决方案,然后再到电商平台上搜索想要的商品。为了方便用户在电商平台上直接输入自己的问题,电商平台也开始构建用户侧的概念,以此来支持按照用户场景进行搜索。比如:当用户搜索“户外烧烤”时,可以给出户外烧烤的相关商品。搜索引擎可以支持按照场景来理解用户需求,但是难以支持从用户问题出发,来推导用户需求。搜索引擎不能支持针对商品详情的问题给出精细化的答案。搜索引擎可以对商品打上导购的标签,但是缺乏解释性的推荐理由。
4.搜索技术和推荐技术本身仅限于用户购物流程中的信息搜索,难以对用户的整个购物流程进行有效的支持。而且,搜索技术和推荐技术主要针对用户需求明确的场景,并且集中在信息搜索的阶段。因此,相关技术中通过搜索技术和推荐技术获取信息以实现用户购物的方式,对用户需求的甄别、候选商品的评估、影响用户购物决策制定等阶段的支持是不足的,比如,不能帮助和引导用户进行需求甄别,不能支持用户对候选商品进行评估和选择,不能结合用户问题给出商品的推荐理由以更好地促进成交转换等。
技术实现要素:
5.本技术提供一种信息推荐方法及装置和构建邻域知识图谱的方法及装置,能够实现对信息的有效推荐。
6.本发明实施例提供了一种信息推荐方法,包括:
7.根据用户需求和领域知识图谱,确定用户诉求;其中,邻域知识图谱包括:用户问题、用户诉求、候选知识信息,以及三者之间的关系;
8.根据确定的用户诉求和领域知识图谱确定推荐的信息。
9.在一种示例性实例中,所述确定用户诉求之前,还包括:构建所述领域知识图谱。
10.在一种示例性实例中,所述确定用户诉求,包括:
11.根据所述用户需求和所述领域知识图谱中的用户问题和用户诉求的关系,确定所述用户诉求;
12.所述确定推荐的信息包括:
13.根据所述确定出的用户诉求和所述领域知识图谱中的用户诉求和候选知识信息
的关系,确定所述推荐的信息。
14.在一种示例性实例中,所述候选知识信息包括:商品知识信息。
15.在一种示例性实例中,所述构建领域知识图谱,包括:
16.从非结构化文本样本中抽取实体,并为抽取出的实体标记类别;
17.建立实体和实体之间的关系;
18.其中,抽取实体包括:用户问题挖掘、用户诉求挖掘、候选知识信息挖掘。
19.在一种示例性实例中,所述用户诉求挖掘包括:
20.根据所在领域的信息内容,利用启发式规则和短语挖掘算法获取候选的用户诉求短语;
21.利用分类器判断候选的用户诉求短语是否是用户诉求;
22.对判断出的用户诉求进行众包质检,回收通过众包质检的用户诉求以构建用户诉求词典库。
23.在一种示例性实例中,所述启发式规则为无监督的算法。
24.在一种示例性实例中,所述候选知识信息挖掘包括:类目-属性-属性值cpv挖掘、商品-属性-值ipv挖掘。
25.在一种示例性实例中,还包括:
26.对所述商品的重点属性进行属性值补全。
27.本技术实施例还提供一种计算机可读存储介质,存储有计算机可执行指令,所述计算机可执行指令用于执行上述任一项所述的信息推荐方法。
28.本技术实施例还提供一种实现信息推荐的装置,包括存储器和处理器,其中,存储器中存储有以下可被处理器执行的指令:用于执行上述任一项所述的信息推荐方法的步骤。
29.本技术实施例又提供一种构建邻域知识图谱的方法,包括:
30.从非结构化文本样本中抽取实体,并为抽取出的实体标记类别;
31.建立实体和实体之间的关系;
32.其中,抽取实体包括:用户问题挖掘、用户诉求挖掘、候选知识信息挖掘。
33.在一种示例性实例中,所述用户诉求挖掘包括:
34.根据所在领域的信息内容,利用启发式规则和短语挖掘算法获取候选的用户诉求短语;
35.利用分类器判断候选的用户诉求短语是否是用户诉求;
36.对判断出的用户诉求进行众包质检,回收通过众包质检的用户诉求以构建用户诉求词典库。
37.在一种示例性实例中,所述启发式规则为无监督的算法。
38.在一种示例性实例中,所述候选知识信息挖掘包括:类目-属性-属性值cpv挖掘、商品-属性-值ipv挖掘。
39.在一种示例性实例中,还包括:
40.对所述商品的重点属性进行属性值补全。
41.本技术实施例再提供一种计算机可读存储介质,存储有计算机可执行指令,所述计算机可执行指令用于执行上述任一项所述的构建邻域知识图谱的方法。
42.本技术实施例还提供一种实现邻域知识图谱构建的装置,包括存储器和处理器,其中,存储器中存储有以下可被处理器执行的指令:用于执行上述任一项所述的构建邻域知识图谱的方法的步骤。
43.本技术实施例提供的信息推荐方法,通过包括用户问题、用户诉求、候选知识信息,以及三者之间的关系的邻域知识图谱,实现了信息的有效推荐。通过本技术实施例构建邻域知识图谱的方法,根据用户问题实现了推理出用户诉求、回答商品详情问题、给出解释性推荐理由,为信息推荐提供了丰富的知识图谱,为信息的有效推荐提供了有力保障。
44.本发明的其它特征和优点将在随后的说明书中阐述,并且,部分地从说明书中变得显而易见,或者通过实施本发明而了解。本发明的目的和其他优点可通过在说明书、权利要求书以及附图中所特别指出的结构来实现和获得。
附图说明
45.附图用来提供对本技术技术方案的进一步理解,并且构成说明书的一部分,与本技术的实施例一起用于解释本技术的技术方案,并不构成对本技术技术方案的限制。
46.图1为本技术实施例中信息推荐方法的流程示意图;
47.图2为本技术实施例中构建邻域知识图谱的方法的流程示意图;
48.图3为本技术实施例中节点挖掘和关系抽取的实现示意图;
49.图4为本技术短语挖掘的实施例的实现示意图;
50.图5为本技术实施例中实体识别模型的实现示意图;
51.图6为本技术实施例中用户问题、用户诉求和商品属性之间关系构建的实施例的示意图;
52.图7为本技术知识信息挖掘的第一实施例的示意图;
53.图8为本技术实施例中关系抽取的一种实现示意图;
54.图9为本技术实施例中信息推荐的一种示例示意图;
55.图10为本技术知识信息挖掘的第二实施例的示意图。
具体实施方式
56.为使本技术的目的、技术方案和优点更加清楚明白,下文中将结合附图对本技术的实施例进行详细说明。需要说明的是,在不冲突的情况下,本技术中的实施例及实施例中的特征可以相互任意组合。
57.在本技术一个典型的配置中,计算设备包括一个或多个处理器(cpu)、输入/输出接口、网络接口和内存。
58.内存可能包括计算机可读介质中的非永久性存储器,随机存取存储器(ram)和/或非易失性内存等形式,如只读存储器(rom)或闪存(flash ram)。内存是计算机可读介质的示例。
59.计算机可读介质包括永久性和非永久性、可移动和非可移动媒体可以由任何方法或技术来实现信息存储。信息可以是计算机可读指令、数据结构、程序的模块或其他数据。计算机的存储介质的例子包括,但不限于相变内存(pram)、静态随机存取存储器(sram)、动态随机存取存储器(dram)、其他类型的随机存取存储器(ram)、只读存储器(rom)、电可擦除
可编程只读存储器(eeprom)、快闪记忆体或其他内存技术、只读光盘只读存储器(cd-rom)、数字多功能光盘(dvd)或其他光学存储、磁盒式磁带,磁带磁盘存储或其他磁性存储设备或任何其他非传输介质,可用于存储可以被计算设备访问的信息。按照本文中的界定,计算机可读介质不包括非暂存电脑可读媒体(transitory media),如调制的数据信号和载波。
60.在附图的流程图示出的步骤可以在诸如一组计算机可执行指令的计算机系统中执行。并且,虽然在流程图中示出了逻辑顺序,但是在某些情况下,可以以不同于此处的顺序执行所示出或描述的步骤。
61.对话机器人能够帮助提供用户购物的售前服务。针对售前场景的对话机器人,一般采用经常问到的问题(faq,frequently asked question)的问答方式,难以真实的理解用户提出的问题,更不能推理用户需求、给出解释性的推荐理由。
62.本技术发明人发现,面临这些挑战,引导式对话是一种比较自然的服务方式。如果能结合引导式对话方式和领域知识图谱,通过对用户问题(如“皮肤干”)的理解、推导出用户需求(如“保湿”)、回答用户的商品问题(如“商品适合孕妇使用吗”)、最终提供解释性推荐理由(如“该面膜含有玻尿酸,具有保湿的功能,比较适合您皮肤干的问题”),那么,可以更好地支持消费者购物行为决策,更让人信服,从而实现对信息的有效推荐。
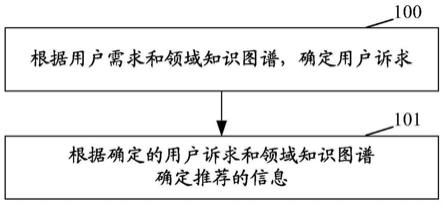
63.图1为本技术实施例中信息推荐方法的流程示意图,如图1所示,包括:
64.步骤100:根据用户需求和领域知识图谱,确定用户诉求;其中,邻域知识图谱包括:用户问题、用户诉求、候选知识信息,以及三者之间的关系。
65.在一种示例性示例中,本步骤可以包括:
66.根据用户需求和领域知识图谱中的用户问题和用户诉求的关系,确定用户诉求。
67.在一种示例性示例中,步骤100之前还包括:构建领域知识图谱。具体实现如图2所示。
68.领域知识图谱包括:表示用户需求的用户提出的问题(下文称为用户问题)、用户诉求(poi)、候选知识信息如商品知识信息,以及这三者之间的关系。这样,可以支持对用户需求的理解、对用户问题的回答、以及对推荐理由的生成等。用户问题描述了用户处于某个有问题的状态,比如:长痘痘;poi描述了用户对于解决其问题的具体诉求,比如:清痘抑痘。
69.领域知识,指的是某个领域或者行业中可复用、可共享的知识信息。比如:皮肤干需要保湿,玻尿酸可以保湿等信息就是知识信息。知识图谱,是一种由节点和边组成的数据结构。其中,每个节点表示现实世界中存在的实体,每条边则表示实体与实体之间的关系,也就是说,知识图谱是对现实世界中事物及其关系的建模,以将不同种类信息连接在一起的关系网络。
70.poi是指,用户希望从所需求的信息如欲购商品中获得的某种特性,比如:保湿、显瘦等。推荐理由,是向用户推荐信息如推荐某个商品时,给出的解释性理由,比如:这款面膜含有玻尿酸,具有保湿的效果,可以缓解皮肤干的问题。
71.候选知识信息,可以通过其属性值来体现,比如以推荐信息为商品为例,商品的属性为成分,其属性值为玻尿酸。
72.步骤101:根据确定的用户诉求和领域知识图谱确定推荐的信息。
73.在一种示例性实例中,本步骤可以包括:
74.根据确定出的用户诉求和领域知识图谱中的用户诉求和候选知识信息的关系,确
定推荐的信息。
75.本技术通过包括用户问题、用户诉求、候选知识信息,以及三者之间的关系的邻域知识图谱,实现了信息的有效推荐。
76.本技术还提供一种计算机可读存储介质,存储有计算机可执行指令,所述计算机可执行指令用于执行上述任一项的信息推荐方法。
77.本技术再提供一种实现信息推荐的设备,包括存储器和处理器,其中,存储器中存储有以下可被处理器执行的指令:用于执行上述任一项所述的信息推荐方法的步骤。
78.在一种示例性实例中,如图2所示,本技术实施例还提供一种构建邻域知识图谱的方法,可以包括节点挖掘、关系抽取两个阶段:
79.步骤200:从非结构化文本样本中抽取实体,并为抽取出的实体标记类别。
80.在一种示例性实例中,如图3所示,本步骤实现了节点挖掘,可以包括:短语挖掘、实体归类以及实体识别。其中,短语挖掘可以是基于远程监督的算法(即不需要人工标准,可以达到高准确率);实体归类和实体识别需要一定的标注量,更优地,可以借助外部知识来降低标注量和提升效果。
81.在一种示例性实例中,短语挖掘支持从百万级别的句子语料中挖掘有意义的短语。算法主要采用远程监督的方式对从句子语料中提取的n元语法(n-gram)候选进行标注,可以采用如融合浅层(wide)特征和深层(deep)语义特征构建初始的随机森林(rf)分类器来获取初始的短语集合;得到初始的短语集合之后,再基于期望最大化(em,expectation maximization)框架和维特比(viterbi)解码算法对句子进行短语粒度的切分,重新统计wide特征和rf分类;最后可以选择使用基于transformers的双向编码器表征(bert,bidirectional encoder representations from transformers)的掩码语言模型(mlm,masked language model)进行剪枝。本技术实施例中的算法的主要特点包括:不需要人工标注、跨多个行业通用、挖掘的短语准确率高(》85%+)。
82.图4为本技术短语挖掘的实施例的实现示意图,如图4所示,大致包括:
83.第1步,构建种子短语,可以通过启发式规则从大规模语料中自动提取种子短语,比如:通过句点断开并且符合一定长度和词性限制的字符序列,提取为种子短语;也可以复用某个领域已有的短语词典或者由用户提供种子短语。
84.第2步,进行短语初挖,包括:从大规模语料中自动构建出所有可能的频繁n-gram短语候选,比如:截取长度为3~8个字符、频率大于或等于3的字符序列作为n-gram短语候选;采用构建出的种子短语对n-gram短语候选进行初标,获得少量正例;基于语料中计算n-gram短语候选的统计特征(如:频率、词频-逆向文件频率(tf-idf)、点间互信息(pointwise mutual information)、信息含量(information content)、左右熵(left-right entropy)和语义特征(如:字符嵌入向量、n-gram内部字符之间的最大语义相似度和最小语义相似度),来训练随机森林分类器,以对n-gram短语候选进行分类得到初步的短语。
85.第3步,对得到的短语进行精炼处理,包括:根据对n-gram短语候选进行分类得到的短语,采用em框架和维特比算法对语料中的所有句子重新切割,得到处理后得到的短语;重新计算处理后得到的短语的特征如wide特征和deep特征;根据重新计算得到的特征,重新训练随机森林分类器进行预测。可以看出,第3步到第2步构成循环,但是实际中只迭代一次,性价比最高。本技术实施例中,对语料库的句子进行了有效的切割,这样,仅仅对切割以
后得到的有效字符序列统计频率以及计算相应的特征,消除了在统计频率时,存在的某些不是短语的字符序列也被统计了相应的频率的问题,提升了短语挖掘的有效性。这里,由于有的n-gram短语可能并不是合法的短语,在句子切分时会被移除,对n-gram短语候选进行分类得到的短语集合,通常会大于或等于,采用em框架和维特比算法对句子切分得到的短语集合。
86.可选地,还可以进一步对得到的短语进行修剪,比如:可以使用mlm语言模型进行过滤来实现修剪过程。
87.在一种示例性实例中,短语挖掘可以包括:用户问题(problem)挖掘、poi挖掘、候选知识信息挖掘。
88.在一种示例性示例中,poi挖掘用于抽取潜在的用户诉求。以服饰、美妆和餐具行业的典型poi为例,“亲肤”、“清痘抑痘”、“安全无毒”等属于poi。
89.举个例子来看,对于一个给定行业,poi挖掘的实现可以包括:
90.首先,根据该行业的信息内容如商品圈选出电商内容(如文章等),利用启发式规则和短语挖掘算法获取候选的poi短语;在一种示例性实例中,启发式规则可以是无监督的算法;
91.然后,构建分类器来判断一个短语是否是poi;
92.最后,对判断出的用户诉求进行众包质检,回收通过众包质检的poi,以构建poi词典库。
93.在一种示例性实例中,用户问题挖掘用于完成对用户的问题的挖掘,具体实现与poi挖掘类似,不同之处在于,挖掘的数据源为售前的对话日志,分类器用来判断一个短语是否是用户问题。
94.在一种示例性实例中,候选知识信息挖掘可以包括:类目-属性-属性值(cpv,catrgory-property-value)挖掘、商品-属性-值(ipv,item-property
–
value)挖掘。其中,cpv即是某个类目下属性具有的属性值,是类目层面的概念。以电商平台上的商品为例,一般可以通过多级类目组织,商品最终挂载在叶子类目之下。叶子类目预先定义有一组属性,并且每个枚举型的属性预先定义有属性值。一般而言,cpv需要经过专家的预先审核,商品的属性值需要在cpv的范围之内。ipv即是某个商品对应的属性的属性值是什么值,是商品实例层面的概念,对于叶子类目下的某个商品,将继承该类目下的属性,并且实例化相应的属性值。-95.在一种示例性实例中,cpv挖掘或ipv挖掘可以包括:
96.以商品集合为中心,从售前对话中挖掘类目下属性具有的属性值或商品对应的属性的属性值。
97.举个例子来看,假设售前对话中有这样的信息:用户针对某款商品提出问题即用户问题为:“适合孕妇吗?”,客服回答:“亲,适合”,那么,针对属性“适合人群”可以提炼出属性值为“孕妇”。具体来讲,首先,从历史售前对话日志中收集问题-答案(qa)对,对问题(q)进行分类,以去掉与业务场景无关的问答对;然后,采用序列标注的方式从qa对中识别出属性和属性值。
98.进一步地,对挖掘出的属性和属性值,需要进行极性判断,以剔除相反的答案。比如:如果上述问题客服回答:“孕妇不能用”,那么,抽取出的属性和对应的属性值:[“适合人
群:孕妇”]是错误的。因此,cpv挖掘或ipv挖掘,还包括:根据同义词对抽取出的属性值进行归一化。并且,确保挖掘得到的属性值在既定cpv词表中,也就是说,在挖掘的过程中,保持类目层级的cpv不变,并且根据cpv来过滤挖掘出的属性值,换句话说,cpv的值当做一个词典,只有挖掘得到的商品属性值在这个词典中,才认为挖掘得到的属性值是合法的。
[0099]
本技术实施例中,cpv数据来自于业务平台的商品图谱,是标准化以后的类目-属性-值(category
–
property
–
value)三元组数据,其中,类目一般指叶子类目,比如:对于“t恤”这个叶子类目来说,一般的属性包含尺寸、颜色、面料、款式、风格等;每个属性有对应的属性值,比如:属性-颜色对应有属性值-白色、蓝色、红色等,再如:属性-面料对应有属性值-纯棉、涤纶、氨纶等。
[0100]
针对实际应用,可以通过补充商品缺失的属性值来完善cpv体系,比如:假设对于某个商家的某款t恤,其属性-面料的属性值是空缺的,那么,可以通过从对话日志或者详情页的产品说明书中挖掘并补充这个属性值。如果挖掘出来的属性值不在已有的属性值列表中。假设挖掘到的属性值是尼龙,但是在原来的属性值列表中只有“纯棉、涤纶、氨纶”,那么,属性值-尼龙会被过滤掉,不会被补充。
[0101]
cpv是商品知识图谱经过外包校验过的商品组织体系,定义了商品的基本属性和枚举值。本技术实施例中,不会扩展cpv体系,只会根据cpv来补充商品的属性值即ipv(item-property-value)。需要注意的是:cpv属于模式层,而ipv属于实例层。举个例子来看,t恤是模式层的概念,某个商家出售的一件具体的t恤是一个实例(假设编号0001)。t恤的面料取值是固定的,但是商家在发布一件t恤时,可能忘记填写面料这一栏了,通过本技术可以为其进行挖掘补充。
[0102]
在一种示例性实例中,为了保证本技术信息推荐方法更加广泛的适用于商品,还包括:对商品的重点属性进行属性值补全。
[0103]
在一种示例性实例中,重点属性值补全可以采用实体识别的方式来实现。
[0104]
比如:当用户针对某款商品提问“适合孕妇吗?”,客服小二回答“亲亲,适合”时,会从问题中采用实体识别的方式标识出“孕妇”,并且打上一个标签“适合人群”,对回答做一个极性判断即正向还是负向,极性判断可以采用基于规则和二分类模型来实现,这里不再赘述。需要说明的时,本技术实施例中的极性判断是非常有必要的,如果小二的回复是“不合适”时,通过极性判断后会将抽取的“适合人群:孕妇”过滤掉,保证了后续推荐的准确性。
[0105]
在一种示例性实例中,实体识别主要针对输入的句子,识别出句子中包含特殊含义的chunk如特殊词汇或专有名词。算法可以是基于领域词典(包括商品的属性名称和属性值)以远程监督方式(这样可以降低标注量)产生弱监督训练数据集的方式,再结合部分人工标注的数据集,训练序列标注模型。特别地,为了进一步提高实体识别模型的效果,可以引入外部词汇(lexicon)和词典(dict)知识(这样可以提升准确率)来训练。在一种实施例中,可以采用如bert-bilstm-crf实体识别模型的框架。
[0106]
在一种示例性实例中,实体识别模型可以采用向量化-编码-解码(embeder-encoder-decoder)框架。其中,向量化可以采用如bert模型,编码部分可以采用如双向长短记忆网络(bilstm),解码部分可以采用如crf。本技术实施例中的实体识别模型利用领域词典以远程监督方式产生训练数据集的,并且引入了外部知识,在输入编码层之前,一方面,通过bert模型获取字符的特征,另一方面,通过外部的词汇或者词典引入了边界信息特征,
二者拼接之后输入编码层。这样,不仅降低了标注量,而且提升了准确率。这里,词汇和词典的差别在于:词汇就是一个列表的词语,而词典不仅仅是一组词语且每个词语有对应的类别。比如:“涤纶”是一个词汇,类别是“面料”。在本技术实施例中,属性值可以看成词汇,属性-属性值的配对可以看成词典。
[0107]
在一种示例性实例中,以远程监督方式产生训练数据的方法可以包括:
[0108]
对于语料中的每一句话,先进行句子切分,再和属性-属性值词典匹配。如果一句话中的某个词和属性值匹配,那么,对该词标记上属性值对应性的属性,作为类别。
[0109]
以外部知识是词汇如外部词汇集合l为例,在一种示例性实例中,首先,利用外部词汇集合对句子进行切分(segmentation),即将该外部词汇集合l加入分词器,并对候选句子进行切分。以对句子“孕妇能用吗”进行处理为例,该句子可被分成“孕妇能用吗”三个词(soft-word)。接着,如图5所示,采用bmes对字符进行边界标记。对于“孕”这个字,是“孕妇”这个soft-word的第一个字,因此,会被打上“b”的标记。对于“妇”这个字符,是“孕妇”这个词的结尾,会被打上“e”的标记。对于边界标签随机初始化向量特征,可以分别对标签b(开始,begin),标签m(中间,middle),标签e(结尾,end),标签s(单个,single)这4个标签随机初始化4个指定长度(比如50维)的向量。对于每一个字符,拼接该字符通过bert后得到的语义向量zi和soft-words得到边界信息特征ei,从而获得该字符最终的向量表示。
[0110]
对于外部知识是词典,相比较外部知识是词汇,会有如下变化:对于边界标签随机初始化向量特征:对于“孕”这个字,是“孕妇”这个soft-word的第一个字,并且“孕妇”的类别为“适合人群”,因此,会被打上“b-适合人群”的标记。对于“妇”这个字符,是“孕妇”这个词的结尾,会被打上“e-适合人群”的标记。同样的,对于“b-适合人群”和“e-适合人群”随机初始化两个指定维度的向量,以进行后续拼接。引入词典会比引入词汇具有更高的准确率。
[0111]
步骤201:建立实体和实体之间的关系。
[0112]
如图3所示,关系抽取可以包括:建立实体和实体之间的关系,比如可以采用关系分类和知识图谱补全等技术来实现。
[0113]
在一种示例性实例中,在本技术实施例中通过poi挖掘、用户problem挖掘、cpv挖掘和ipv挖掘构建邻域知识图谱的过程中,还包括:质量检测,比如:众包质检。
[0114]
通过本技术实施例构建的邻域知识图谱,根据用户问题实现了推理出用户诉求、回答商品详情问题、给出解释性推荐理由。
[0115]
本技术构建邻域知识图谱的方法的实施例中,如图4所示,以用户在某种场景下需要购买相应商品场景为例,从基本的人、货、场出发,引入用户问题和用户诉求两个概念。用户问题描述了用户处于某个有问题的状态,如“长痘痘”,poi描述了用户对于解决其问题的具体诉求,如“清痘抑痘”。如图6所示,本技术实施例中采用需求(need)和理由(cause)两种关系,其中,need关系用于关联用户问题和用户诉求,cause关系用于关联用户诉求和商品的ipv属性值。poi的知识信息主要用于支持推理用户需求和提供解释性推荐理由。poi关系的挖掘中,以cause关系的挖掘为例,首先,会从电商内容收集文本句子,通过词典匹配和序列标注的方式从句子中识别出cpv和/或poi;然后,保留同时包含cpv和poi的句子,采用关系分类的模型进行链接预测。类似地,need关系也可以通过类似的方式来建立。
[0116]
如图6所示,用户(人)
–
商品(货)
–
场景是电商领域的经典概念,其中场景的概念不仅是指购物场所(如商店、商场、商超等),也包括各种不同的消费场景(如:教师节、户外烧
烤等),通常会说用户在某个场景下需要购买相关的商品。ipv是指的商品
–
商品属性
–
商品属性值构成的三元组,比如:t恤
–
颜色
–
红色。用户问题描述了用户处于的某种状态(如长痘痘),poi是针对用户问题的某种解决方案(如清痘抑痘)。为了能够推理用户的需求,本技术实施例建立了用户问题和poi之间的连接,如长痘痘需要清痘抑痘这样的need;为了解释某件商品为什么适合用户的需求,建立了商品自身特性和poi之间的关联,如红霉药醇可以清痘抑痘的cause。
[0117]
图7为本技术知识信息挖掘的第一实施例的示意图,如图7所示,假设给定句子即图7中的原始文本:“食品级硅胶材质不含bpa,可以高温消毒,是真正令妈妈放心的安全餐具”,首先,进行实体识别,识别出“食品级硅胶”是一种材质;“高温消毒”,“令人放心”,“安全”等是poi。然后,进行关系抽取以建立材质“食品级硅胶”和每一个poi之间的cause关系,如图7中的知识图谱(kg)三元组所示,从而完成cpv级别即类目级别的cpv挖掘:宝宝餐具-材质-食品级硅胶;ipv级别即商品实例级别的ipv挖掘:餐具#1-材质-食品级硅胶,餐具#2-材质-食品级硅胶。以及材质“食品级硅胶”的推荐理由:高温消毒、令人放心、安全。
[0118]
本技术知识信息挖掘实施例,包括众包环节在内,通过周期性运行,ipv挖掘会越来越丰富、poi及poi三元组也会越来越完善,为信息推荐提供了丰富的知识图谱,为信息的有效推荐提供了有力保障。
[0119]
导购主要是根据用户提出的问题,推理出用户的需求,并且借助搜索引擎搜索出合适的商品推荐给用户。如果用户对某个商品的细节需要进一步了解,还可以基于kbqa的商品属性问答,来解答商品详情相关的问题。进一步地,在推荐某一个商品之后,针对用户的问题或者偏好,还可以生成一句解释性的推荐理由,以辅助提升成交转换。应用过程如表1所示。
[0120]
消费者购物决策流程方法知识图谱应用识别用户需求推理用户需求导购信息搜索调用搜索引擎接口导购评估候选商品商品详情问题商品属性问答购买决策提供解释性推荐理由推荐理由生成购后行为
--
[0121]
表1
[0122]
关系抽取主要用于上文中的poi关系型知识构建。图8为本技术实施例中关系抽取的一种实现示意图,如图8所示,关系抽取是针对输入的句子,预测句子中两个实体之间的关系类型。可以采用如bert框架,以远程监督的方式(这样可以降低标注量)生成初始的种子实体对和相应的训练数据,比如:商品属性pv值和poi是否同时在某网络文章的句子中出现,并且引入了实体边界信息(比如实体两侧加入特殊分界符号$和#)和实体所在的三元组知识等外部知识(引入外部知识如实体知识、边界信息、实体三元组知识等,可以提升的效果)。
[0123]
如图8所示实施例,在“氨纶面料,使衣服很有弹力”这个句子中,识别出了两个概念“氨纶面料”和“有弹力”,并分别在这两个概念的前后加入特殊符号如$和#,标志着概念的开始和结束,如图8中的“$氨纶面料$,使衣服很#有弹力#”。同时,对于“氨纶面料”这个概念,从外部知识库,比如中国通用百科知识图谱(cn-dbpedia)等,查到对应的三元组知识包
括:氨纶面料-特点-弹性高,利用软索引(soft-index)技术将这个三元组知识引入到句子中。这里,软索引指的是相对位置,如图8中加粗斜体索引标签所示。假如,额外引入的短句“特点弹性高”的软索引是从6到10,引入之后原句子的序号“$,使衣服#有弹力#”的索引仍然是从6到15保持不变。另外,需要注意的是注意力机制,在上述句子中,融入的额外短语“特点弹性高”除了对“氨纶面料”可见之外,对原句子中的其他字符都是不可见的。在关系抽取中引入边界信息和外部三元组知识都是有效的。图8所示的实施例中,采用bert模型作为骨干网络,在输入层,沿用了字符标记(token)向量,位置(position)向量,和段(segment)向量。其中,position向量就是改进后的软索引。在模型的输出层,将’[cls]’的向量、两个概念的向量(概念的向量是其包含token字符的平均)进行拼接,最终经过一个全连接(fully connection)层和归一化指数函数如softmax函数后,得到最终的分类结果。序bert模型作为骨干网络可以参见相关资料,这里不再赘述。
[0124]
图9为本技术实施例中信息推荐的一种示例示意图,如图9所示,整个处理过程包括模式层和实例层两层结构,其中,模式层中的概念包括:用户(user)、用户诉求(poi)和商品(item),用户层面主要包括用户的问题,如图9中的长痘痘,商品层面主要指特定类目下商品的属性和属性值,如图9中的成分(ingredient)是属性,红霉药醇是属性值。用户诉求是链接用户层面和商品层面的桥梁,一方面用户诉求关联用户问题,如图9中的用户诉求即清痘抑痘是解决用户问题即长痘痘的方案,另一方面用户诉求链接商品属性值,如图9中的面膜的成分红霉药醇具有清痘抑痘的功效。
[0125]
从知识图谱的角度来看,知识图谱包括三类概念:用户侧,商品层,以及诉求。其中,用户侧主要描述用户的问题(如长痘痘);商品层主要描述商品的属性(如成分是红霉药醇);poi层是用户和商品之间的桥梁:一方面用户的问题导致某种诉求(比如:长痘痘需要清痘抑痘),这个关联通过图6中所示的need关系来表示,另一方面商品的某种属性能满足用户的诉求(比如:商品因为成分含有红霉药醇,所以可以清痘抑痘),这个关联通过图6中所示的cause关系来表示。
[0126]
需要说明的是,本技术实施例中,商品主要通过cpv体系组织,叶子类目预先定义好属性,叶子类目下对应的商品会继承叶子类目预定义的属性和属性值。在实际应用中,商品和用户属于实体层,数量巨大,至少是亿级别;而用户问题(某个问题导致什么样的诉求)、poi知识、商品知识(如某种成分的功效)属于类型层面,数量级在百万级别。为了方便,如图9所示,在一种示例性实例中,在知识图谱中可以进一步添加偏好(preference)和特征(feature)两条边,比如:如果用户#1的问题是“长痘痘”,需要“清痘抑痘”,那么,在该用户和清痘抑痘之间连一条preference的边。同样的,如果商品#1具有某个成分如红霉药醇,而红霉药醇这种成分能够清痘抑痘,那么,在商品#1和清痘抑痘之间连接一条feature的边。
[0127]
在实际应用中,针对用户说的话,会基于规则或模型解析出用户是否提到了某种问题,然后再基于本技术实施例中的知识图谱推理出用户诉求,并通过商品和用户诉求之间的满足关系倒查出相应的商品,最后推荐查出的商品。
[0128]
本技术实施例中的邻域知识图谱可以应用于导购、商品属性问答、推荐理由生成等实际应用场景,实现了支持消费者购物决策流程中的需求识别、信息搜索、候选商品评估、辅助购买决策等阶段。
[0129]
对于理解用户问题,推理用户需求的应用场景,本技术实施例中构建的领域知识
图谱建模了用户问题和用户诉求之间的关系,也就是说,建立了什么样的问题会导致什么样的诉求的关系。比如:对于用户提出的“皮肤干”的问题,根据建立的用户问题与用户诉求之间的关系,可以得出:用户诉求为需要“保湿”;再如:对于用户提出的“长痘痘”的问题,根据建立的用户问题与用户诉求之间的关系,可以得出:用户诉求为需要“清痘抑痘”。在一种示例性实例中,针对用户提出的问题,可以使用字典匹配的方式来识别用户问题,查询构建的邻域知识图谱推导出相应的用户诉求。
[0130]
对于回答商品详情问题的应用场景,本技术实施例构建的邻域知识图谱中包括商品知识信息,以及商品知识信息与诉求之间的关系,那么,针对商品属性相关的问题,可以采用序列标注的方式识别出属性,并获取相应的属性值来回答商品详情的问题。
[0131]
对于解释性推荐理由的应用场景,本技术实施例构建的邻域知识图谱中建立有商品属性与用户诉求之间的关联。比如:商品“面膜”的成分(属性)含有玻尿酸,而玻尿酸可以保湿(用户诉求),根据这个关系可以得出含有玻尿酸成分的面膜可以满足保湿这样的用户诉求,也就是说,含有玻尿酸成分的面膜是可以推荐出提出“皮肤干”这样的问题的用户的,而且,可以结合商品本身的属性在推荐商品时,想用户解释为什么会推荐这样的商品,使得商品的推荐更具有信服力。
[0132]
图10为本技术知识信息挖掘的第二实施例的示意图,如图10所示,整体分为上下两个部分即节点挖掘(node mining)和关系挖掘(link prediction)。节点挖掘包括(a)poi挖掘、(b)用户问题挖掘、(c)商品属性值挖掘即cpv&ipv挖掘三部分。关系挖掘主要分为need和cause两类关系的挖掘,即(d)poi关系知识挖掘。在本实施例的知识信息挖掘过程中,如图10所示,众包被引入来保证知识图谱的质量。知识信息挖掘的实现过程是系统化的,包括众包任务都是可以通过平台自动发布和回收并最终入库的。
[0133]
如图10中的(a)poi挖掘所示,poi是按照不同行业分别进行挖掘的。对于给定的一个行业,首先,获取该行业的所有商品及其对应的信息如网络文章、商品详情页等内容;然后,通过启发式规则和短语挖掘算法从这些内容中挖掘出候选短语,并通过人工标注很小一部分作为训练数据,比如:给定的一些候选短语,标注出这些候选短语是不是poi,数量大概可以在2~3k;接着,基于标注的数据训练基于bert的分类模型;最后,利用训练得到的分类模型对余下的大量候选短语进行预测。这些通过分类模型预测出的候选poi具有高的准确性。是为了100%保证准确性,可以对预测出的候选poi进行众包审核后入库。
[0134]
如图10中的(b)用户问题挖掘所示,用户问题的挖掘也是按照不同行业分别进行的,与(a)poi挖掘不同的是,挖掘的数据源更换为对话日志和用户评论即可,其他具体实现与poi挖掘流程类似,这里不再赘述。
[0135]
如图10中的(c)cpv&ipv挖掘所示,首先,可以从商品图谱中获取cpv体系,并以此为依据对商品的重要属性值进行补全。在一种实施例中,比如:可以从售前对话日志中获取“问题-答案”对,基于场景方式对问题进行分类,判断是否和商品相关。在本实施例中,会从和商品相关的问答对中抽取商品的属性值并进行极性判断,这里,极性判断是非常有必要的,比如对于“孕妇可以用吗”,如果客服的回复是“可以”,那么,适用人群可以是孕妇;如果客服的回复是“不可以”,那么,孕妇是不适用,此时需要过滤掉该抽取出的商品的属性值。然后,基于同义词对抽取出的属性值进行归一化处理,最终利用cpv过滤掉不在既定词表中的属性值。
[0136]
如图10中的(d)poi关系知识挖掘所示,poi关系知识的抽取是整个图谱能够连起来的关键,poi不仅连接了用户问题和用户诉求,还连接了用户诉求和商品属性。poi关系知识挖掘的核心思想就寻找到文本证据(text evidence),以表明某个用户问题和poi之间、某个poi和某个商品属性之间存在的如图6所示的need关系和cause关系。如图10所示,以表明cause关系为例,可以从网络文章中获取大量的文本,并从文本中识别出poi和ipv属性值。本实施例中,以保留那些同时包含了poi和ipv属性值的句子为例,通过人工标注出一小部分句子,以判断某个句子是否能表明cause关系,也就是说其包含的ipv属性值和poi之间是否存在cause关系。以图7中的“食品级硅胶不含bpa,可以高温消毒,是真正让妈妈放心的安全餐具”为例,假设识别出的ipv属性值是“食品级硅胶”,poi是“安全”,可以通过人工标注来判断这个句子是否表明“食品级硅胶”和“安全”之间存在cause关系,这个例子是成立的,也就是说,从该句子中识别出的ipv属性值即“食品级硅胶”与poi即“安全”之间存在cause关系。就这样,在具有一定的训练数据之后,可以通过这些训练数据训练出一个关系分类模型,这样,就可以对网络文本中的大量候选句子进行预测,以获取更多的ipv-cause-poi关系型三元组知识信息。need关系的确定也可以采用与cause关系类似的方法挖掘获得,这里不再赘述。
[0137]
需要说明的是,这样的poi关系型知识是类型层面的,亦即并非关联到特定的个人或者某个商品。在实际应用中,可以根据具体的人是否有某个问题,或者具体的商品是否有某个成分来进行推导。
[0138]
本技术还提供一种计算机可读存储介质,存储有计算机可执行指令,所述计算机可执行指令用于执行上述任一项的构建邻域知识图谱的方法。
[0139]
本技术再提供一种实现邻域知识图谱构建的设备,包括存储器和处理器,其中,存储器中存储有以下可被处理器执行的指令:用于执行上述任一项所述的构建邻域知识图谱的方法的步骤。
[0140]
虽然本技术所揭露的实施方式如上,但所述的内容仅为便于理解本技术而采用的实施方式,并非用以限定本技术。任何本技术所属领域内的技术人员,在不脱离本技术所揭露的精神和范围的前提下,可以在实施的形式及细节上进行任何的修改与变化,但本技术的专利保护范围,仍须以所附的权利要求书所界定的范围为准。
相关技术
网友询问留言
已有0条留言
- 还没有人留言评论。精彩留言会获得点赞!
1