一种利用键值匹配模型提高黑名单准确率的方法及系统与流程
本发明涉及通信安全以及数据挖掘技术领域,尤其涉及一种利用键值匹配模型提高黑名单准确率的方法及系统。
背景技术:
随着通信行业的成熟和发展,移动通信资费逐渐降低,群众和企业从中切实受益,但低成本的通信费用也为恶意营销类骚扰电话提供了滋生的土壤。一些不法分子出于恶意报复、勒索等目的,利用移动通信进行骚扰等违法犯罪活动。另外市场形成饱和格局,企业之间为实现产品销售的竞争激化,也使得未经过用户允许的营销类骚扰电话的传播。ai发展衍生出了电销机器人,减低了营销成本,更加剧了这一产业的发展。商业营销类电话、恶意骚扰等电话泛滥,给移动用户带来了巨大的经济损失和生活困扰,同时蚕食着电信营运商的宝贵网络资源。
随着云计算、大数据的不断发展,海量数据计算能力不断增强,核心算法不断突破,应用邻域不断扩展,已成为技术创新的重要技术,在骚扰电话治理工作中发挥的作用也越发明显,识别准确度更高、覆盖完整性更全、监控实时性更快,在骚扰电话治理工作中已经成为重要生产力,高效识别骚扰电话可有效减少骚扰电话蔓延带来的负面影响。
如公开号为cn109995924a的专利公开了一种欺诈电话识别方法、装置、设备及介质,包括如下步骤:获取用户的基础通话数据;将所述基础通话数据进行统计及计算,生成与用户通话的各电话号码及其数据特征;从所述与用户通话的各电话号码中选出多个已知的黑名单号码及多个已知的非黑名单号码;建立二分类训练模型,将所述多个已知的黑名单号码的数据特征与所述多个已知的非黑名单号码的数据特征输入所述二分类训练模型内,训练所述二分类训练模型,以得到经过训练的二分类训练模型;及将新号码的数据特征输入所述经过训练的二分类训练模型内,以识别该新号码是否是欺诈电话。虽然上述专利可以识别欺诈电话,但是其只是根据数据特征对诈骗号码进行一次识别,依然存在误判现象以及识别准确率不高的问题。
技术实现要素:
本发明的目的是针对现有技术的缺陷,提供了一种利用键值匹配模型提高黑名单准确率的方法及系统,通过查询键的匹配和计算类别的概率,输出号码对应的最大可能的类标,从而能够在不降低覆盖率的同时,通过二次筛选机制(键值匹配)提高黑名单识别准确率。
为了实现以上目的,本发明采用以下技术方案:
一种利用键值匹配模型提高黑名单准确率的方法,包括步骤:
s1.采集类别标签中的每个号码数据对应的24小时内的通话记录;
s2.根据采集到的通话记录计算每个号码的查询键,并将计算得到的查询键与号码对应的类别标签进行组合,生成号码的数据集;
s3.统计所有号码的数据集,并筛选统计的数据集中同一查询键所对应的类别标签,得到查询键对应的类别标签统计模型;
s4.将测试号码进行步骤s2的处理,得到测试号码的查询键,并将所述查询键输入至得到的统计模型中,统计模型输出与测试号码的查询键相同的查询键所对应的类别标签;
s5.将输出的查询键的类别标签相加,得到输出的查询键的键值对;根据得到的键值对计算查询键所对应的类别标签,得到最终结果。
进一步的,所述步骤s1中的类别标签的号码包括黑名单号码、白名单号码、未定义号码、正常号码。
进一步的,所述步骤s2包括:
s21.统计当前号码24小时内通话记录的次数;
s22.判断统计的当前号码24小时中每个时间点的通话次数是否大于第一预设阈值,若是,则将大于第一预设阈值所对应的时间点的数值转换为1;若否,则将小于等于第一预设阈值所对应的时间点的数值转换为0,并记录当前号码转换后的数据特征;
s23.获取记录的当前号码的数据特征中为1的时间点,并将获取的为1的时间点对应的数值转换为字符,将转换后的字符进行拼接,得到当前号码的查询键;
s24.将得到的当前号码的查询键与当前号码对应的类别标签进行组合,生成当前号码的数据集。
进一步的,所述步骤s5中根据得到的键值对计算查询键所对应的类别标签具体为:
计算键值对中每个数值的结果,并将计算得到的每个数值的结果与第二预设阈值进行比较,得到大于第二预设阈值的数值,并根据得到的大于第二预设阈值的数值得到数值对应的类别标签。
进一步的,所述计算键值对中每个数值的结果,表示为:
其中,y表示计算后得到各标签的概率值;yi表示键值对中第i个数值;y表示所有标签个数累加后的yi的集合。
相应的,还提供一种利用键值匹配模型提高黑名单准确率的系统,包括:
采集模块,用于采集类别标签中的每个号码数据对应的24小时内的通话记录;
第一计算模块,用于根据采集到的通话记录计算每个号码的查询键,并将计算得到的查询键与号码对应的类别标签进行组合,生成号码的数据集;
统计模块,用于统计所有号码的数据集,并筛选统计的数据集中同一查询键所对应的类别标签,得到查询键对应的类别标签统计模型;
第二计算模块,用于将测试号码通过第一计算模块中处理方式处理,得到测试号码的查询键,并将所述查询键输入至得到的统计模型中,统计模型输出与测试号码的查询键相同的查询键所对应的类别标签;
识别模块,用于将输出的查询键的类别标签相加,得到输出的查询键的键值对;根据得到的键值对计算查询键所对应的类别标签,得到最终结果。
进一步的,所述采集模块中的类别标签的号码包括黑名单号码、白名单号码、未定义号码、正常号码。
进一步的,所述第一计算模块包括:
统计模块,用于统计当前号码24小时内通话记录的次数;
判断模块,用于判断统计的当前号码24小时中每个时间点的通话次数是否大于第一预设阈值,若是,则将大于第一预设阈值所对应的时间点的数值转换为1;若否,则将小于等于第一预设阈值所对应的时间点的数值转换为0,并记录当前号码转换后的数据特征;
获取模块,用于获取记录的当前号码的数据特征中为1的时间点,并将获取的为1的时间点对应的数值转换为字符,将转换后的字符进行拼接,得到当前号码的查询键;
生成模块,用于将得到的当前号码的查询键与当前号码对应的类别标签进行组合,生成当前号码的数据集。
进一步的,所述识别模块中根据得到的键值对计算查询键所对应的类别标签具体为:
计算键值对中每个数值的结果,并将计算得到的每个数值的结果与第二预设阈值进行比较,得到大于第二预设阈值的数值,并根据得到的大于第二预设阈值的数值得到数值对应的类别标签。
进一步的,所述计算键值对中每个数值的结果,表示为:
其中,y表示计算后得到各标签的概率值;yi表示键值对中第i个数值;y表示所有标签个数累加后的yi的集合。
与现有技术相比,本发明利用大数据技术实现对号码的精准分类,通过对号码24小时内的通话记录的统计与转化,得到黑名单号码与非黑名单号码(未定义号码、白名单号码、正常号码等)对应的查询键和类标,通过查询键的匹配和计算类别的概率,输出号码对应的最大可能的类标,从而能够在不降低覆盖率的同时,通过二次筛选机制(键值匹配)提高黑名单识别准确率。
附图说明
图1是实施例一提供的一种利用键值匹配模型提高黑名单准确率的方法流程图;
图2是实施例一提供的数据集构建流程示意图;
图3是实施例一提供构建统计模块流程图示意图;
图4是实施例一提供识别号码流程示意图;
图5是实施例二提供的一种利用键值匹配模型提高黑名单准确率的系统结构图。
具体实施方式
以下通过特定的具体实例说明本发明的实施方式,本领域技术人员可由本说明书所揭露的内容轻易地了解本发明的其他优点与功效。本发明还可以通过另外不同的具体实施方式加以实施或应用,本说明书中的各项细节也可以基于不同观点与应用,在没有背离本发明的精神下进行各种修饰或改变。需说明的是,在不冲突的情况下,以下实施例及实施例中的特征可以相互组合。
本发明的目的是针对现有技术的缺陷,提供了一种利用键值匹配模型提高黑名单准确率的方法及系统。
实施例一
本实施例提供一种利用键值匹配模型提高黑名单准确率的方法,如图1所示,包括步骤:
s11.采集类别标签中的每个号码数据对应的24小时内的通话记录;
s12.根据采集到的通话记录计算每个号码的查询键,并将计算得到的查询键与号码对应的类别标签进行组合,生成号码的数据集;
s13.统计所有号码的数据集,并筛选统计的数据集中同一查询键所对应的类别标签,得到查询键对应的类别标签统计模型;
s14.将测试号码进行步骤s12的处理,得到测试号码的查询键,并将所述查询键输入至得到的统计模型中,统计模型输出与测试号码的查询键相同的查询键所对应的类别标签;
s15.将输出的查询键的类别标签相加,得到输出的查询键的键值对;根据得到的键值对计算查询键所对应的类别标签,得到最终结果。
需要说明的是,现有技术中识别黑名单是使用分类算法进行识别的,其通过分类算法对号码通话行为进行分析后,输出一批黑名单号码,但是通过分类算法输出的黑名单中的号码可能存在一些误判现象,因此,本实施例提出了一种利用键值匹配模型提高黑名单准确率的方法来对通过分类算法输出的黑名单中的号码进行识别处理,进而进一步提高黑名单的准确率。
在步骤s11中,采集类别标签中的每个号码数据对应的24小时内的通话记录。
类别标签的号码包括黑名单号码、白名单号码、未定义号码、正常号码。
获取已经分类好的每个名单中的号码,如通过获取12321等其他运营商官方平台已经确认的黑名单、白名单、未定义号码和正常号码中的号码数据。
在本实施例中,将黑名单号码用[0100]表示,白名单号码用[0010]表示、未定义号码用[1000]表示,正常号码用[0001]表示。那么[0100]、[0010]、[1000]、[0001]则为号码对应的类别标签。
根据获取的各个类别的号码数据,采集每个号码一天(24小时)内的通话记录。
在步骤s12中,根据采集到的通话记录计算每个号码的查询键,并将计算得到的查询键与号码对应的类别标签进行组合,生成号码的数据集。
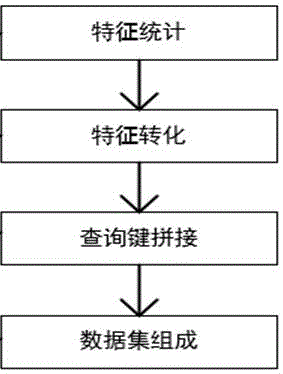
如图2所示,步骤s12具体包括:
s121.特征统计:统计当前号码24小时内通话记录的次数;
对步骤s11中采集的每个号码24小时内的通话记录进行特征统计,如:黑名单中的电话号码为135xxxxxxxx,该号码24小时中每个小时拨出的次数记录如下[0000012806129300000000000],其中[]内共有24个数值,每个数值依次是上述号码从0点-23点每小时对应的通话次数。
s122.特征转换:判断统计的当前号码24小时中每个时间点的通话次数是否大于第一预设阈值,若是,则将大于第一预设阈值所对应的时间点的数值转换为1;若否,则将小于等于第一预设阈值所对应的时间点的数值转换为0,并记录当前号码转换后的数据特征;
当步骤s121中对每个号码进行特征统计处理后,判断每个号码在每个时间的通话次数是否大于第一预设阈值。其中,第一预设阈值的数值可根据对黑名单和非黑名单的每天通话行为进行统计得到的,本实施例将第一预设阈值设为4进行说明。
举例说明:如步骤s121中得到的号码135xxxxxxxx的特征数据为[0000012806129300000000000],根据特征数据得到在5点、6点、8点、11点时对应的数值分别为12、8、6、9,且12、8、6、9均大于第一预设阈值4,则表示在5点、6点、8点、11点是上述号码拨出的次数大于4,将该点对应的数值用1表示,其余时间点对应的数值用0表示,得到上述号码的数据特征,即[000001280612930000000000]转化后的数据特征为[00000110100100000000000]。
s123.查询键拼接:获取记录的当前号码的数据特征中为1的时间点,并将获取的为1的时间点对应的数值转换为字符,将转换后的字符进行拼接,得到当前号码的查询键;
将步骤s122中转换后的数据特征简化为字符串,把将简化后的字符串作为查询键。
举例说明:数据特征为[00000110100100000000000],取所有不为0(即为1)的特征数据中的特征值所对应的时间点,即上述数据特征中为1的特征值所对应的时间点分别为5点、6点、8点、11点,则将该时间点用字符表示。
字符表示的方法为:如0点用00表示,5点用05表示,15点用15表示。
5点、6点、8点、11点转换后的字符分别为05、06、08、11,接着将转换后的字符进行拼接,则拼接后的形式为‘05060811’,将进行拼接后的05060811作为电话135xxxxxxxx的查询键。
将所有的电话号码按照上述方式进行处理,得到每个号码的查询键。
s124.数据集组成:将得到的当前号码的查询键与当前号码对应的类别标签进行组合,生成当前号码的数据集。
将步骤s123中得到的每个号码的查询键与每个号码所对应的one-hot形式的类别标签(即黑名单、白名单、未定义、正常)进行组合,生成每个号码的数据集。其中one-hot表示类别标签。
举例说明:在步骤s121中,已知电话号码135xxxxxxxx为黑名单中的号码,则该号码对应的类别标签为[0100],则将该号码的类别标签与步骤s123得到的查询键进行组合,组合后的样本形式为{‘05060811’,[0100]}。
在步骤s13中,统计所有号码的数据集,并筛选统计的数据集中同一查询键所对应的类别标签,得到查询键对应的类别标签统计模型。
将所有号码均按照步骤s121-s124处理,得到所有号码的数据集,并在所有号码的数据集中筛选相同的查询键,得到查询键对应的类别标签统计模型。
以查询键‘05060811’为例具体说明:
‘05060811’在所有数据集中对应的类别标签可能包括[0100]、[0010]、[1000]、[0001]这四种,假设共有22个查询键为‘05060811’的号码,查询键为‘05060811’所对应的类别标签为[1000]的号码为1个,‘05060811’所对应的类别标签为[0100]的号码为16个,‘05060811’所对应的类别标签为[0010]的号码为2个,‘05060811’所对应的类别标签为[0001]的号码为3个,则将查询键‘05060811’所对应的类别标签进行统计。
所有的查询键均依据上述方式进行统计,则得到所有查询键所对应的类别标签的统计模型。
在步骤s14中,将测试号码进行步骤s12的处理,得到测试号码的查询键,并将所述查询键输入至得到的统计模型中,统计模型输出与测试号码的查询键相同的查询键所对应的类别标签。
具体为:
取一个测试的号码,将该测试的号码经过步骤s121-s123的方法进行处理,得到该号码对应的查询键,将该号码对应的查询键输入生成的统计模型中进行处理,统计模型输出该查询键对应的所有类别标签,如[0100]、[0010]、[1000]、[0001]。
在步骤s15之前还包括通过步骤1、获取当前的测试号码;2、对当前的测试号码进行特征工程,处理异常值,挖掘出数据中更多更重要的特征;3、采用多种算法ensemble对特征进行处理;4、得到当前测试号码所述的类别。
需要说明的是,步骤1-4均可通过现有技术实现,本实施例不在赘述。
在步骤s15中,将输出的查询键的类别标签相加,得到输出的查询键的键值对;根据得到的键值对计算查询键所对应的类别标签,得到最终结果。
具体为,测试号码的查询键在统计模型中可能对应多个类别标签,则将该查询键对应的类别标签相加,得到一个键值对。
需要说明的是,测试号码对应的类别标签通过步骤1-4可计算得到,下述步骤是为了进一步提高号码的准确率,进行二次筛选。
以查询键‘05060811’为例具体说明:
‘05060811’在统计模型中对应的类别标签可能包括[0100]、[0010]、[1000]、[0001]这四种,假设将测试号码的查询键输入后,共有22个号码对应的查询键为‘05060811’,其中查询键为‘05060811’所对应的类别标签为[1000]的号码为1个,‘05060811’所对应的类别标签为[0100]的号码为16个,‘05060811’所对应的类别标签为[0010]的号码为2个,‘05060811’所对应的类别标签为[0001]的号码为3个;将‘05060811’对应的所有类别标签相加,得到‘05060811’的键值对为[1,16,2,3]。
根据上述键值对可以看出,在22个号码中,有1个是未定义的号码,16个是黑名单的号码,2个是白名单的号码,3个是正常号码。
接着根据得到的键值对中得到每个查询键的键值对,再计算键值对中每个数值的结果,并将计算得到的每个数值的结果与第二预设阈值进行比较,得到大于第二预设阈值的数值,并根据得到的大于第二预设阈值的数值得到数值对应的类别标签。
其中,计算键值对中每个数值的结果,表示为:
其中,y表示计算后得到各标签的概率值;yi表示键值对中第i个数值;y表示所有标签个数累加后的yi的集合。
具体为:当查询键匹配得到的值y=[y0y1y2y3],则计算每个树脂的结果为的公式为:
其中,ya、yb、yc、yd分别表示数值y0、y1、y2、y3的结果。
以键值对为[1,16,2,3]为例具体说明:
计算键值对中每个数值的结果,也就是计算键值对中1的结果、16的结果、2的结果、3的结果。
上述结果则为键值对中每个数值的计算结果,接着将得到的计算结果与第二预设阈值比较,本实施例将第二预设阈值设为0.99,则上述结果中大于0.99的为第二类,也就是键值对中数值为16多对应的结果,则根据上述方案可得到键值对为[1,16,2,3]所对应的查询键‘05060811’中的号码为黑名单的号码,及查询键为‘05060811’对应的号码黑名单的号码,也就是该测试号码为黑名单的号码。
需要说明的是,若上述中第一类的结果大于0.99,其余均小于0.99,则认为相应的查询键对应的号码为未定义的号码;若第三类的结果大于0.99,其余均小于0.99,则认为相应的查询键对应的号码为白名单的号码;若第四类的结果大于0.99,其余结果均小于0.99,则认为相应的查询键对应的号码为正常号码。
综上所示,本实施例提供的一种利用键值匹配模型提高黑名单准确率的方法分为两步,第一步为建立统计模型,第二步为识别号码。
建立统计模型:
如图3所示,根据自定义的未定义号码、黑名单号码、白名单号码、正常号码四种类型的号码,统计其在原始话单中的每天24小时内的通话记录,得到号码在一天24小时中每个小时的通话次数,将通话次数大于设定阈值的值设为1,小于阈值的设为0,转化后所有小时对应的特征值为0或1,将所有特征值不为0对应的时间点字符拼接,形成一个字符查询键,用以上方法统计所有已知类型号码的通话行为形成的查询键,对查询键进行循环,将一个查询键对应的所有类标相加,作为统计好的模型。
识别号码:
如图4所示,对第一级分类模型输出的黑名单中,进行上述同样的小时通话次数统计并与阈值比较转化为0或1,将特征值不为0对应的小时转化为字符进行拼接得到查询键,与统计好的模型里的查询键进行匹配,当通过查询键匹配得到类型的概率大于0.9时,输出复筛的黑名单。
需要说明的是,第一级分类模型输出的黑名单指的是通过现有技术的方法输出的黑名单。
本实施例基于分类模型输出的黑名单在通过兼职匹配进行处理,能够在不降低覆盖率的同时,通过二次筛选机制(键值匹配)提高黑名单识别准确率。
本实施例利用大数据技术实现对号码的精准分类,通过对号码24小时内的通话记录的统计与转化,得到黑名单号码与非黑名单号码(未定义号码、白名单号码、正常号码等)对应的查询键和类标,通过查询键的匹配和计算类别的概率,输出号码对应的最大可能的类标,从而能够在不降低覆盖率的同时,通过二次筛选机制(键值匹配)提高黑名单识别准确率。
实施例二
本实施例提供一种利用键值匹配模型提高黑名单准确率的系统,如图5所示,包括:
采集模块11,用于采集类别标签中的每个号码数据对应的24小时内的通话记录;
第一计算模块12,用于根据采集到的通话记录计算每个号码的查询键,并将计算得到的查询键与号码对应的类别标签进行组合,生成号码的数据集;
统计模块13,用于统计所有号码的数据集,并筛选统计的数据集中同一查询键所对应的类别标签,得到查询键对应的类别标签统计模型;
第二计算模块14,用于将测试号码通过第一计算模块中处理方式处理,得到测试号码的查询键,并将所述查询键输入至得到的统计模型中,统计模型输出与测试号码的查询键相同的查询键所对应的类别标签;
识别模块15,用于将输出的查询键的类别标签相加,得到输出的查询键的键值对;根据得到的键值对计算查询键所对应的类别标签,得到最终结果。
进一步的,所述采集模块中的类别标签的号码包括黑名单号码、白名单号码、未定义号码、正常号码。
进一步的,所述第一计算模块包括:
统计模块,用于统计当前号码24小时内通话记录的次数;
判断模块,用于判断统计的当前号码24小时中每个时间点的通话次数是否大于第一预设阈值,若是,则将大于第一预设阈值所对应的时间点的数值转换为1;若否,则将小于等于第一预设阈值所对应的时间点的数值转换为0,并记录当前号码转换后的数据特征;
获取模块,用于获取记录的当前号码的数据特征中为1的时间点,并将获取的为1的时间点对应的数值转换为字符,将转换后的字符进行拼接,得到当前号码的查询键;
生成模块,用于将得到的当前号码的查询键与当前号码对应的类别标签进行组合,生成当前号码的数据集。
进一步的,所述识别模块中根据得到的键值对计算查询键所对应的类别标签具体为:
计算键值对中每个数值的结果,并将计算得到的每个数值的结果与第二预设阈值进行比较,得到大于第二预设阈值的数值,并根据得到的大于第二预设阈值的数值得到数值对应的类别标签。
进一步的,所述计算键值对中每个数值的结果,表示为:
其中,y表示计算后得到各标签的概率值;yi表示键值对中第i个数值;y表示所有标签个数累加后的yi的集合。
需要说明的是,本实施例提供的一种利用键值匹配模型提高黑名单准确率的系统与实施例一类似,在此不多做赘述。
与现有技术相比,本发明利用大数据技术实现对号码的精准分类,通过对号码24小时内的通话记录的统计与转化,得到黑名单号码与非黑名单号码(未定义号码、白名单号码、正常号码等)对应的查询键和类标,通过查询键的匹配和计算类别的概率,输出号码对应的最大可能的类标,从而能够在不降低覆盖率的同时,通过二次筛选机制(键值匹配)提高黑名单识别准确率。
实施例三
本实施例提供的一种利用键值匹配模型提高黑名单准确率的方法与实施例一的不同之处在于:
本实施例以8000个手机号码通话记录作为实验样本进行说明。
在8000个手机号码通话记录中,正样本数为3000,负样本数5000。
8000个实验样本相当于测试数据集,因为是已知了样本标签;其中正样本表示黑名单,负样本表示非黑名单。
本实施例将只用现有技术中的分类模型和实用加入本实施例的键值匹配模型后进行黑名单识别的结果进行比较。
采用现有技术中的分类模型输出的结果:输出正样本6540,负样本1460;其中tp:2870、fp:3670、fn:130、tn:1330,如下表1所示:
表1
tp为truepositive,表示真正例,将正类正确预测为正类数;
fp为falsepositive,表示假正例,将负类错误预测为正类数;
fn为falsenegative,表示假负例,将正类错误预测为负类数;
tn为truenegative,表示真负例,将负类正确预测为负类数。
根据上述数据计算样本中有多少正例被预测正确,即召回率recall:
recall=tp/tp+fn=2870/(2870+130)=95.67%
根据上述数据计算分类正确的样本占总样本的比例,即精度accuracy;
accuracy=tp+tn/tp+tn+fp+fn=(2870+1330)/8000=52.5%
由此可知,采用现有技术的分类模型得到的正样本的recall为95.67%,accuracy为52.5%。
采用加入键值匹配模型(具体如实施例一的方案)输出的结果:输出正样本2871,负样本5129;其中tp:2730、fp:141、fn:270、tn:4859,如下表2所示:
表2
根据上述数据计算样本中有多少正例被预测正确,即召回率recall:
recall=tp/tp+fn=2730/(2730+270)=91%
根据上述数据计算分类正确的样本占总样本的比例,即精度accuracy;
accuracy=tp+tn/tp+tn+fp+fn=(2730+4859)/8000=94.9%
由此可知,采用现有技术的分类模型得到的正样本的recall为91%,accuracy为94.9%。
本实施例通过加入键值匹配模型后,从而能够在不降低覆盖率的同时,通过二次筛选机制(键值匹配)提高黑名单识别准确率。
注意,上述仅为本发明的较佳实施例及所运用技术原理。本领域技术人员会理解,本发明不限于这里所述的特定实施例,对本领域技术人员来说能够进行各种明显的变化、重新调整和替代而不会脱离本发明的保护范围。因此,虽然通过以上实施例对本发明进行了较为详细的说明,但是本发明不仅仅限于以上实施例,在不脱离本发明构思的情况下,还可以包括更多其他等效实施例,而本发明的范围由所附的权利要求范围决定。
- 还没有人留言评论。精彩留言会获得点赞!