一种基于深度学习的端到端散斑投影三维测量方法与流程
[0001]
本发明属于光学测量技术领域,具体为一种基于深度学习的端到端散斑投影三维测量方法。
背景技术:
[0002]
近几十年,快速三维形貌测量技术被广泛的应用于各个领域,如智能监控,工业质量控制和三维人脸识别等。在众多三维形貌测量方法中,基于结构光和三角测量原理的散斑投影轮廓术是最实用的技术之一,由于它具有无接触,全场,快速和高效等优点。高度适合动态3d采集的散斑投影轮廓术(spp),可以通过投影单一散斑图案来建立一对散斑立体图像之间的全局对应关系。但是spp存在传统立体匹配算法的低匹配精度的问题。
技术实现要素:
[0003]
本发明的目的在于提出了一种基于深度学习的端到端散斑投影三维测量方法。
[0004]
实现本发明目的的技术解决方案为:一种基于深度学习的端到端散斑投影三维测量方法,包括如下步骤:
[0005]
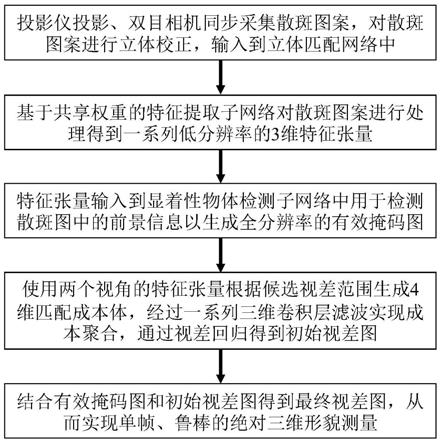
步骤一:投影仪投影、双目相机同步采集散斑图案,对散斑图案进行立体校正;
[0006]
步骤二:基于共享权重的特征提取子网络对散斑图案进行处理得到设定尺寸的低分辨率的3维特征张量;
[0007]
步骤三:将特征张量输入到显着性物体检测子网络中检测散斑图中的前景信息,生成全分辨率的有效掩膜图;
[0008]
步骤四:根据两个视角的特征张量以及候选视差范围生成4维匹配成本体,将4维匹配成本体输入三维卷积层滤波实现成本聚合,通过视差回归得到初始视差图;
[0009]
步骤五:根据有效掩膜图和初始视差图得到最终视差图。
[0010]
优选地,步骤二基于共享权重的特征提取子网络对散斑图案进行处理得到设定尺寸的低分辨率的3维特征张量的具体过程为:尺寸大小为h
×
w,散斑图案经过3个具有相同输出通道数的卷积层得到尺寸为32
×
h
×
w的张量;
[0011]
经过1个具有步长为2的卷积层得到尺寸为32
×
h/2
×
w/2的张量;连续经过3个残差块得到尺寸为32
×
h/2
×
w/2的张量;
[0012]
经过16个残差块得到尺寸为64
×
h/2
×
w/2的张量;
[0013]
经过6个残差块得到尺寸为128
×
h/2
×
w/2的张量;
[0014]
尺寸为128
×
h/2
×
w/2的张量然后分别经过大小为(5,5)、(10,10)、(20,20)、(40,40)的平均池化层与卷积层进行不同尺度的降采样,并使用双线性插值得到原分辨率的张量;
[0015]
并将原分辨率的张量与尺寸为64
×
h/2
×
w/2的张量、尺寸为128
×
h/2
×
w/2的张量在特征通道上进行拼接,得到尺寸为320
×
h/2
×
w/2的张量;
[0016]
经过两个卷积层得到尺寸为32
×
h/2
×
w/2的张量。
[0017]
优选地,步骤三将特征张量输入到显着性物体检测子网络中检测散斑图中的前景信息,生成全分辨率的有效掩膜图的具体过程为:尺寸为32
×
h/2
×
w/2的张量经过3个残差块得到尺寸为64
×
h/2
×
w/2的张量;经过一个反卷积层得到尺寸为32
×
h
×
w的张量;经过3个残差块得到尺寸为32
×
h
×
w的张量;通过一个不含激活操作的卷积层得到尺寸为1
×
h
×
w的张量;经过一个sigmoid层得到最终全分辨率的有效掩膜图。
[0018]
优选地,步骤四中使用两个视角的特征张量根据候选视差范围生成的4维匹配成本体具体为:
[0019]
cost(1:32,d
i-d
min
+1,1:h,1:w-d
i
)=feature
left
(1:32,1:h,1:w-d
i
)
[0020]
cost(33:64,d
i-d
min
+1,1:h,1:w-d
i
)=feature
right
(1:32,1:h,d
i
:w)
[0021]
其中,feature
left
和feature
right
为两个视角的特征张量,32
×
h/2
×
w/2为两个视角的特征张量的尺寸,[d
min
,d
max
]为视差范围,d
i
为候选视差。
[0022]
优选地,通过视差回归得到初始视差图的过程为:
[0023]
匹配成本体经过softmax层,通过视差回归得到初始视差图,如下式所示:
[0024][0025]
其中,[d
min
,d
max
]为视差范围,softmax(
·
)代表softmax操作,disparity代表通过视差回归得到初始视差图,cost为经过成本滤波后的4维匹配成本体;
[0026]
使用双线性插值得到原分辨率的初始视差图。
[0027]
优选地,步骤五根据有效掩膜图和初始视差图得到的最终视差图,如下式所示:
[0028]
disparity
final
(x,y)=disparity(x,y)*mask(x,y)
[0029]
式中,disparity为初始视差图,mask为有效掩膜图。
[0030]
本发明与现有技术相比,其显著优点为:本发明仅需要投影一张散斑图案即可实现单帧、鲁棒的绝对三维形貌测量。
[0031]
下面结合附图对本发明做进一步详细的描述。
附图说明
[0032]
图1为一种基于深度学习的端到端散斑投影三维测量方法的流程示意图。
[0033]
图2为本发明的基于深度学习的立体匹配算法的基本原理图。
[0034]
图3为利用本发明获得的结果的示意图。
具体实施方式
[0035]
一种基于深度学习的端到端散斑投影三维测量方法,首先使用投影仪投影、双目相机同步采集散斑图案。对散斑图案进行立体校正,输入到立体匹配网络中。其中,基于共享权重的特征提取子网络对散斑图案进行处理得到一系列低分辨率的3维特征张量。特征张量输入到显着性物体检测子网络中用于检测散斑图中的前景信息以生成全分辨率的有效掩膜图。使用两个视角的特征张量根据候选视差范围生成4维匹配成本体,经过一系列三维卷积层滤波实现成本聚合,通过视差回归得到初始视差图。结合有效掩膜图和初始视差图得到最终视差图,从而实现单帧、鲁棒的绝对三维形貌测量。本发明仅需要投影一张散斑图案即可实现单帧、鲁棒的绝对三维形貌测量。具体步骤为:
[0036]
步骤一:首先使用投影仪投影、双目相机同步采集散斑图案。对散斑图案进行立体校正,输入到立体匹配网络中。
[0037]
步骤二:基于共享权重的特征提取子网络对散斑图案进行处理得到一系列低分辨率的3维特征张量。
[0038]
在立体匹配网络的基于共享权重的特征提取子网络中,散斑图案的尺寸大小为h
×
w。首先经过3个具有相同输出通道数的卷积层得到尺寸为32
×
h
×
w的张量,然后经过1个具有步长为2的卷积层得到尺寸为32
×
h/2
×
w/2的张量,然后连续经过3个残差块得到尺寸为32
×
h/2
×
w/2的张量,再经过16个残差块得到尺寸为64
×
h/2
×
w/2的张量,再经过6个残差块得到尺寸为128
×
h/2
×
w/2的张量。尺寸为128
×
h/2
×
w/2的张量然后分别经过大小为(5,5)、(10,10)、(20,20)、(40,40)的平均池化层与卷积层对张量进行不同尺度的降采样,然后使用双线性插值得到原分辨率的张量。并将这些原分辨率的张量与尺寸为64
×
h/2
×
w/2的张量、尺寸为128
×
h/2
×
w/2的张量在特征通道上进行拼接,得到尺寸为320
×
h/2
×
w/2的张量。最后经过两个卷积层得到尺寸为32
×
h/2
×
w/2的张量。
[0039]
步骤三:特征张量输入到显着性物体检测子网络中用于检测散斑图中的前景信息以生成全分辨率的有效掩膜图。
[0040]
具体地,尺寸为32
×
h/2
×
w/2的张量首先经过3个残差块得到尺寸为64
×
h/2
×
w/2的张量,然后经过一个反卷积层得到尺寸为32
×
h
×
w的张量,经过3个残差块得到尺寸为32
×
h
×
w的张量,通过一个不含激活操作的卷积层得到尺寸为1
×
h
×
w的张量,最后经过一个sigmoid层得到最终全分辨率的有效掩膜图mask,从而实现散斑图中的前景信息检测。
[0041]
步骤四:使用两个视角的特征张量根据候选视差范围生成4维匹配成本体,经过多个三维卷积层滤波实现成本聚合,通过视差回归得到初始视差图。
[0042]
进一步的实施例汇总,两个视角的特征张量的尺寸为32
×
h/2
×
w/2,视差范围为[d
min
,d
max
],对于每一个候选视差d
i
,对应的匹配成本体cost计算如下式所示:
[0043]
cost(1:32,d
i-d
min
+1,1:h,1:w-d
i
)=feature
left
(1:32,1:h,1:w-d
i
)
[0044]
cost(33:64,d
i-d
min
+1,1:h,1:w-d
i
)=feature
right
(1:32,1:h,d
i
:w)
[0045]
其中,feature
left
和feature
right
为两个视角的特征张量。因此,根据候选视差范围生成4维匹配成本体的尺寸为64
×
(d
max-d
min
+1)
×
h/2
×
w/2。
[0046]
然后,4维匹配成本体经过多个三维卷积层滤波实现成本聚合,从而得到尺寸为1
×
(d
max-d
min
+1)
×
h/2
×
w/2的匹配成本体。然后经过softmax层,通过视差回归得到初始视差图,如下式所示:
[0047][0048]
最后使用双线性插值得到原分辨率的初始视差图。
[0049]
步骤五:结合有效掩膜图mask和初始视差图disparity得到最终视差图,从而实现单帧、鲁棒的绝对三维形貌测量。结合有效掩膜图mask和初始视差图disparity得到最终视差图disparity
final
,如下式所示:
[0050]
disparity
final
(x,y)=disparity(x,y)*mask(x,y)
[0051]
然后基于两个相机的标定参数,将视差数据转为三维信息,最终实现单帧、鲁棒的绝对三维形貌测量。
[0052]
本发明提出的立体匹配网络包含以下几个部分:
[0053]
1、基于共享权重的特征提取子网络;
[0054]
2、显着性物体检测子网络;
[0055]
3、生成初始的4维匹配成本体;
[0056]
4、经过一系列三维卷积层滤波实现成本聚合得到成本聚合后的4维匹配成本;
[0057]
5、成本聚合后的4维匹配成本通过视差回归得到初始视差图;
[0058]
6、结合有效掩膜图和初始视差图得到最终视差图。
[0059]
实施例:
[0060]
为验证本发明的有效性,使用两台相机(型号aca640-750um,basler),一台dlp投影仪(型号lightcrafter 4500pro,ti)以及一台计算机构建了一套基于深度学习的端到端散斑投影三维测量装置。该套装置在进行物体的三维测量时的拍摄速度为25帧每秒。利用步骤一所述,使用投影仪投影、双目相机同步采集散斑图案。对散斑图案进行立体校正,输入到立体匹配网络中。图2为本发明的基于深度学习的立体匹配算法的基本原理图。利用步骤二至步骤五所述,最终实现单帧、鲁棒的绝对三维形貌测量。整个实验中,投影并拍摄1200组数据,其中800组作为训练集,200组作为验证集,200组作为测试集。值得注意的是,训练集、验证集和测试集中的数据均不重复使用。设置网络的损失函数为均方误差(mse),优化器为adam,设置网络的训练周期为500轮。图3为本发明的基于深度学习的端到端散斑投影三维测量方法的结果图。图3这个结果证明,本发明仅需要投影一张散斑图案即可实现单帧、鲁棒的绝对三维形貌测量。
相关技术
网友询问留言
已有0条留言
- 还没有人留言评论。精彩留言会获得点赞!
1