一种基于二维空间编码的图像描述方法与流程
本发明涉及图像描述技术领域,特别涉及一种基于二维空间编码的图像描述方法。
背景技术:
随着人工智能的不断发展,计算机视觉成为人工智能领域最重要的研究方向之一,自从2006年hinton教授在《科学》发表对于深层神经网络的训练方法以后,迎来了深度学习的蓬勃发展,也使得基于深度学习的计算机视觉成为目前人工智能最活跃的领域。视觉技术不仅需要计算机可以代替人的眼睛来“观察”事物,还必须像人的大脑一样具有“理解”事物的能力,它的挑战是使计算机和机器人开发成具有与人类水平相当的视觉能力,从而可以帮助人处理一些复杂的技术应用。当前,基于深度学习的计算机视觉被广泛应用于各个行业,其中包括智慧医疗、公共安防、无人机与自动驾驶等领域,如农产品品质检测、作物识别与分级、质量检测、地标跟踪等都为人类生活提供了越来越多的便利。图像描述(imagecaptioning)是一个融合计算机视觉、自然语言处理和机器学习的综合研究方向,它类似于将一幅图片翻译为一段描述文字,该任务对于人类来说非常容易,但对于机器却非常具有挑战性,它不仅需要利用模型去理解图片的内容并且还需要用自然语言去表达它们之间的语义关系,所以也是当前人工智能领域跨学科的研究重点和难点。图像描述是指给定一张图像,通过相应的算法不仅要理解图上有什么物体,而且要理解物体之间的相互关系,最后要用文字将其描述出来,就类似于小学生的“看图说话”题。随着机器翻译和大数据的兴起,出现了imagecaption的研究浪潮。当前大多数的imagecaption方法基于encoder-decoder模型,其中encoder一般为卷积神经网络(cnn),利用最后全连接层或者卷积层的特征作为图像的特征,decoder一般为递归神经网络(rnn),主要用于图像描述的生成。现在,大部分国内外知名团队在对图像描述任务进行改进时都会对“encoder-decoder”这一模型进行深入研究。为了更好的得到图像的高层语义信息,对原有的卷积神经网络进行改进,加强encoder阶段图像特征的提取;也会依据机器翻译领域的启发,对原有的递归神经网络进行改进,使得decoder模型的语言表达能力更为准确和丰富。
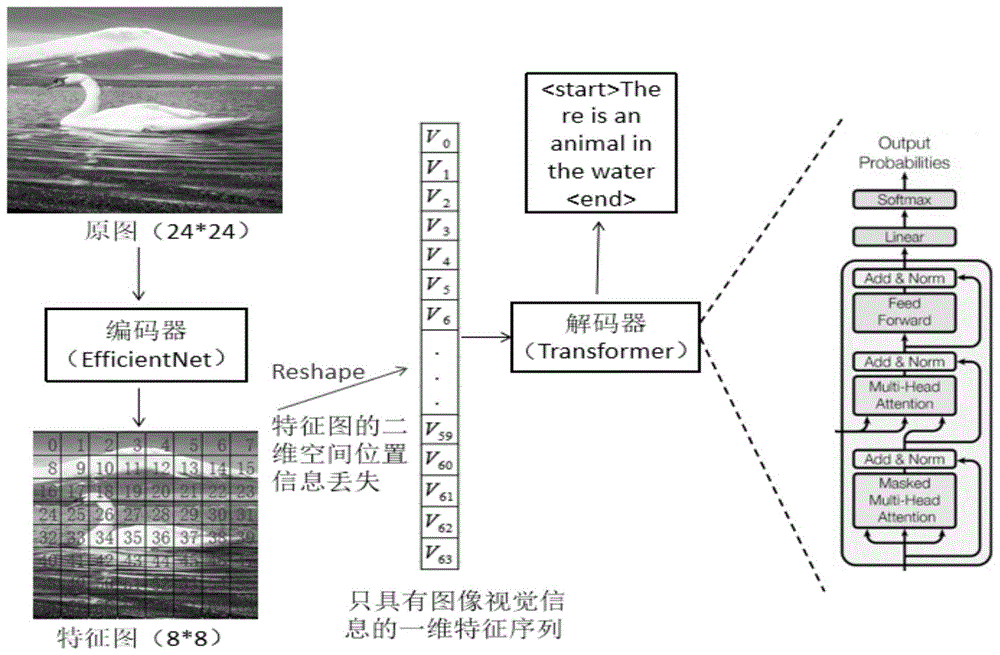
在计算机视觉领域中,输入一幅图像中的各个目标之间固有的几何位置结构有利于对视觉信息进行推理,在图像理解的相关任务上有至关重要的影响,比如对于一幅图片中的两个目标而言,如果知道两个目标之间的相对位置关系就可以进一步提高计算机对整幅图像的理解,从而提取出更丰富的图像特征。对于图像描述而言,经过编码器对图片进行特征提取的过程,图片的相对位置关系没有发生变化,所以一般的编码器工作都没有特意给图片中的每个像素添加相应的空间位置信息。图像描述本来就是一项跨领域的研究,要将二维特征图转换成解码器能够识别的一维特征序列表示,但由于特征图没有特意标注空间位置信息,在转换成一维序列之后会打乱图像中原有每个像素点的空间位置关系,使得图像本身的位置信息丢失。
技术实现要素:
本发明提供一种基于二维空间编码的图像描述方法,能够解决图像空间位置信息丢失的问题。
本发明提供了一种基于二维空间编码的图像描述方法,包括以下步骤:
s1、将一幅图像送入编码器模型中进行图像特征提取,得到相应的二维特征图;
s2、通过顺序位置编码、坐标位置编码或目标级的位置编码为二维特征图编码绝对位置信息;
s3、根据二维特征图的绝对位置信息,将二维特征图转换为解码器能够识别的一维序列。
所述步骤s2中的顺序位置编码和坐标位置编码用于图像级图像描述和attention级图像描述,目标级的位置编码用于目标级图像描述。
所述图像级图像描述和attention级图像描述采用efficientnet编码器,目标级图像描述采用fasterr-cnn编码器。
所述步骤s2中的顺序位置编码包括以下步骤:
s21、二维特征图转换为一维序列的过程中,解码器模型具有按行读取像素点信息的特征,输入的特征图大小为m*n,按行依次给二维特征图中的m*n个像素点进行编码,得到二维特征图每个像素点的行位置信息即视觉信息v0、v1、v2…v(m*n)-2、v(m*n)-1;
s22、依据编码好行位置信息的二维特征图中的像素点,每行像素都有从0到i-1共n个像素点,i=0、1、…、n-1,对第一行的n个像素点,当i=0时,就是对第一行中行位置信息为0的像素开始进行列抽取,按照i+j*n进行m次抽取,j=0、1、…、m-1,得到第1列的所有像素点;当i=1时,对第一行中行位置信息为1的像素进行列抽取,然后按照i+j*n进行m次抽取,得到第2列的所有像素点,依次类推对第一行0~i-1各像素点都按照i+j*n进行m次抽取,最终得到大小为m*n特征图的列位置信息;
s23、根据二维特征图每个像素点的行位置信息和列位置信息,获得二维特征图的绝对位置信息。
所述步骤s2中的坐标位置编码包括以下步骤:
s21、给编码器输出的(i+1)*(i+1)特征图进行0~i的行位置编码,给第一行的i+1个像素点进行从0~i的编码,第二行的i+1个像素点进行从0~i的编码,以此类推给每一行的i+1个像素点都编码0~i,获得二维特征图的行位置信息;
s22、对具有行位置编码的二维特征图进行转置操作,得到二维特征图中相应像素点的列位置信息;
s23、根据二维特征图每个像素点的行位置信息和列位置信息,获得二维特征图的绝对位置信息。
所述步骤s2中的目标级的位置编码包括以下步骤:
s21、编码器模型fasterr-cnn通过锚框去框特征图中的目标,编码器模型fasterr-cnn计算锚框是否框到了目标,以及框到的目标的类别,置信度表示框到的目标有多大概率属于这个类别;
s22、通过编码器模型fasterr-cnn提取出每个目标按照置信度排列的特征序列;
s23、根据每个目标按照置信度排列的特征序列,借助编码器模型fasterr-cnn内部中心坐标的位置信息,为每个目标对象编码出相应的绝对位置信息,获得特征图的绝对位置信息。
所述步骤s23中为每个目标对象编码出相应的绝对位置信息的具体过程包括以下步骤:
s231、首先根据目标特征图中每个目标矩形框的坐标信息计算出矩形框的面积,使用交并比函数iou计算出多个目标矩形框面积两两之间的重合度;
s232、其次根据矩形框的位置坐标计算出多个目标相应的中心点位置,将此中心点位置进行反向映射到编码器输出的特征图即卷积特征图的相应像素点上;
s233、对相应像素点进行位置编码得到多个目标的空间位置信息,从而使得编码器输出的置信度排列的一维视觉序列添加了每个目标的空间位置信息。
所述步骤s231中的交并比函数iou是一种计算目标1的矩形框面积area1和目标2的矩形框面积area2之间重合度的方法,定义为:
iou=area/(area1+area2-area)
其中,交并比函数iou值很大说明两个目标之间的重合度很高,如果交并比函数iou值很小说明两个目标之间没有重合。
与现有技术相比,本发明的有益效果在于:
本发明使二维特征图转换为一维序列后还保存着原有图像的位置信息,使得具有图像位置信息的一维序列进入解码器后能依靠单词表示法和视觉信息的综合指导,与现阶段一维序列不添加图像位置信息的方法相比较,图像描述效果好。
附图说明
图1为本发明实施例提供的未加空间位置信息且按行优先排列的一维序列特征的图像描述流程图。
图2为本发明实施例提供的顺序编码行列信息的图像描述流程图。
图3为本发明实施例提供的坐标位置编码行列信息的图像描述流程图。
图4为本发明实施例提供的未添加目标位置信息的图像描述流程图。
图5为本发明实施例提供的具有空间位置信息的目标级图像描述流程图。
图6为本发明实施例提供的计算两个矩形框area1(目标a)和area2(目标b)重合度的示意图。
图7为本发明实施例提供的一种基于二维空间编码的图像描述方法的流程图。
具体实施方式
下面结合附图1-7,对本发明的一个具体实施方式进行详细描述,但应当理解本发明的保护范围并不受具体实施方式的限制。
图像描述(imagecaption)的特征图位置编码方案:
我们采用的是图像描述领域最常用的“编码器-解码器”架构。编码器使用的是“efficientnet”模型或“fasterr-cnn”模型,解码器使用的是基本的并行语言生成模型“basedtransformer”。我们要探索给特征图中的每个像素点编码位置信息的方法,为了方便说明,我们首先来讨论一下,以往的图像描述任务将二维特征图转换(reshape)为一维序列时是如何丢失位置信息的(如图1所示)。
首先,将一幅512*512大小的图像送入编码器(efficientnet)模型中进行图像的特征提取得到相应的特征图谱,此时特征图谱的维度是[1,512,8,8],其中输入编码器模型的图像批大小为1,512指卷积层的通道数,两个8分别指图像长和宽的尺寸,图像一共有8*8=64个像素点。由于图像经过cnn编码器后本身具有空间位置不变性的特点,所以将原图转换为特征图后并没有丢失原有各个像素点的位置信息,紧接着要将二维特征图进行处理(reshape)变为解码器能够识别的一维序列,reshape生成的一维序列保持批大小和通道数不变,只是将二维图像8*8的像素点推平成64个像素点的一维序列,在此处理(reshape)过程中由于未给特征图编码绝对位置信息,导致二维特征图转化为一维序列后丢失了特征图各个像素点原有的位置信息,从而也会丢失图片的一些特征,使得解码器模型的描述质量较低。
本发明给每个特征图的像素点添加相应的位置编码信息,与一维序列添加位置信息不同的是,图像的二维位置信息需要分别编码出它的行位置(lineembedding)和列位置(columnembedding)。本发明所提出的特征图位置编码方法,恰好可以解决二维特征图转化为一维序列后丢失各个像素点位置信息的问题,使得转化后的一维序列还可以保持图像像素点原有的位置信息关系。由于图像描述分为三种类型:图像级、attention级和目标级,并且目标级的图像描述与其他两种有很大区别,它没有图像的顺序位置关系信息,只有图像目标的位置关系。因此我们提出了三种特征图位置编码的方法:顺序位置编码、坐标位置编码和目标级的位置编码:
(1)顺序位置编码:s21、二维特征图转换为一维序列的过程中,解码器模型具有按行读取像素点信息的特征,输入的特征图大小为m*n,按行依次给二维特征图中的m*n个像素点进行编码,得到二维特征图每个像素点的行位置信息即视觉信息v0、v1、v2…v(m*n)-2、v(m*n)-1;
s22、依据编码好行位置信息的二维特征图中的像素点,每行像素都有从0到i-1共n个像素点,i=0、1、…、n-1,对第一行的n个像素点,当i=0时,就是对第一行中行位置信息为0的像素开始进行列抽取,按照i+j*n进行m次抽取,j=0、1、…、m-1,得到第1列的所有像素点;当i=1时,对第一行中行位置信息为1的像素进行列抽取,然后按照i+j*n进行m次抽取,得到第2列的所有像素点,依次类推对第一行0~i-1各像素点都按照i+j*n进行m次抽取,最终得到大小为m*n特征图的列位置信息;
s23、根据二维特征图每个像素点的行位置信息和列位置信息,获得二维特征图的绝对位置信息。
为了说明此方法中的绝对位置信息如何抽取,我们设m*n为8*8,每行有8个像素点,按照i+j*8进行8次抽取,这里i取0~7,j取0~7,由于一共有8行,则依次对第一行这8(0~7)个像素点都分别进行8次抽取,当i=0时,对第一行0位置按照i+8*j,j取0~7抽取8次,第一次j=0时i+8*j=0+8*0抽取得到p0位置信息,第二次j=1时i+8*j=0+8*1抽取得到p0位置下方p8的位置信息,依次类推抽取8次,最终得到第一列位置信息p0、p8、p16、p24、p32、p40、p48、p56;再从i=1位置按照i+8*j,j取0~7抽取8次,则抽取出第二列的位置信息p1、p9、p17、p25、p33、p41、p49、p57,依次类推对第一行0~7各点都按照i+8*j抽取8次最终得到特征图的列位置信息。
这样就可以得到特征图每个像素点的行列位置信息,对带有二维空间位置信息的特征图进行reshape转换,这样可以防止图像的空间位置信息丢失。
(2)坐标位置编码:由于特征图的每个像素点都需要表示出行和列的位置信息,因此我们可以构想到用二维坐标来表示像素点的位置,令坐标的x轴表示像素点的行位置信息,y轴表示像素点的列位置信息,这样就可以给图像的各个像素点编码出相应的空间位置信息,使得二维特征图转换为一维序列后还保存着原有图像的空间位置信息。具体实现如图3所示,首先给编码器(efficientnet)输出的8*8特征图进行0~7的行位置编码,例如:给第一行的8个像素点进行从0~7的编码,记为(p0、p1、p2、p3、p4、p5、p6、p7),第二行的8个像素点进行从0~7的编码,以此类推给每一行的8个像素点都编码0~7,这样就完成了特征图的行位置编码(lineembedding)。紧接着对具有行位置编码的特征图进行转置操作就可以得到相应像素点的列位置信息(columnembedding),就如图3中转换为一维的视觉序列(v0、v1、v2…v62、v63)不仅添加了相应的行位置信也添加了列位置信息,这样已标注行列位置信息的特征图转换成一维序列以后还会保存原有图像的空间位置信息。
(3)目标级的位置编码:如上文所述,图像描述任务有三种类型:图像级、attention级和目标级。前两种位置信息编码方式适用于图像级和attention级的图像描述,不适用于目标级的图像描述任务,因为目标级的图像描述编码器使用的是目标检测的经典模型,经过这样的编码器提取出的不是整幅图像的顺序特征序列,而是图像中显著目标区域的特征序列,前两种方法用的efficientnet编码器无法提取这种目标区域特征,所以我们要给目标级的图像描述任务添加位置信息之前,必须将编码器换成fasterr-cnn模型。目标级的图像描述通过编码器fasterr-cnn提取出的是每个目标按照置信度排列的特征序列,置信度:模型先产生锚框,然后锚框去框图像中的目标,模型会计算出这个锚框是否框到了目标,以及框到的目标是属于哪个类,置信度就是表示框到的目标有多大概率属于这个类别,如图4所示:水的置信度为0.99、鸭子的置信度是0.92、雪山的置信度为0.80,因此得到7*7的特征图依次是水(c)、鸭子(b)、雪山(a),同样每个目标得到的一维视觉特征序列没有相应的空间位置信息。由于fasterr-cnn模型内部每个目标的矩形框(rectanglebox)都有四个框角的坐标信息和框的长宽信息(x、y、w、h),用来在区域生成网rpn(regionproposalnetwork)过程中获取更高精度的矩形框(如图5的目标特征图),因此我们可以借助目标级编码器模型内部的中心坐标位置信息,为每个目标对象编码出相应的绝对位置信息,使得fasterr-cnn模型输出按置信度排列的一维视觉序列添加上相应的空间位置信息。如图5所示,我们的做法是:首先根据目标特征图中每个目标矩形框的坐标信息计算出矩形框的面积,使用iou方法计算出三个目标(a、b、c)矩形框面积两两之间的重合度,iou是一种计算两个矩形框area1(目标a)和area2(目标b)重合度的方法,如图6所示,定义为:
iou=area/(area1+area2-area)
其中iou值很大说明两个目标之间的重合度很高,如果iou值很小说明两个目标之间没有重合,可以的到a目标雪山与b目标鸭子的iou很小,b目标鸭子与c目标水的iou很大,a目标雪山与c目标水的iou很小,从而得到三个目标之间的位置关系:雪山是单独存在的与鸭子和水都没有重叠关系,鸭子和水的iou值很高说明鸭子包含于水中;其次根据矩形框的位置坐标计算出三个目标相应的中心点位置,将此中心点位置进行反向映射到卷积特征图的相应像素点上,如图5中卷积特征图上三个目标的abc标记点所示,其中a点雪山的中心点位置在第11个像素点上,b点鸭子的中心点位置在第27个像素点,c点水的中心点位置在第43个像素点上,同时对相应像素点进行位置编码得到三个目标的空间位置信息,从而使得编码器输出的置信度排列的一维视觉序列添加了每个目标的空间位置信息。
本发明旨在解决图像描述算法中的图像像素点位置信息丢失的问题,提出了三种图像位置编码方法,这三种方法都是给编码器的输出特征图添加绝对位置信息。
对于图像描述任务而言,编码器和解码器的设计和选择对任务整体的描述效果至关重要,但已有的很多模型都忽略了二维特征图像转换为一维序列时丢失的位置信息,没有图像位置信息的一维序列进入解码器后只能依靠单词表示法,缺乏视觉信息的指导,因此提出了三种图像位置信息编码方法,图像级和attention级的图像描述可任意采用顺序位置编码和坐标位置编码的方法,目标级的图像描述任务采用目标位置编码方案。
顺序位置编码或坐标位置编码的图像描述方法,在整个流程中关注的是图像的整体信息,如果局部的个别区域被遮挡不会因为局部特征的消失而影响他特征的检测和匹配等特点,对图像描述的整体描述效果影响不大,虽然描述的文本语义可能不太丰富,但对图像描述出的语义完整性好。
目标位置编码的图像描述方法,在整个流程中先关注图像的整体信息,后对图像的显著目标区域进行特征提取。由于图像中各个目标信息对解码部分的描述效果影响极大,所以目标位置编码方法的图像描述任务生成的文本不但语义完整性好而且语义丰富度更高。整体描述效果较好于顺序位置编码和attention位置编码的图像描述方法。
无论是上述的哪种位置编码方法,都可以使二维特征图转换为一维序列后还保存着原有图像的位置信息,使得具有图像位置信息的一维序列进入解码器后能依靠单词表示法和视觉信息的综合指导,都比现阶段一维序列不添加图像位置信息的方法描述效果好。
以上公开的仅为本发明的几个具体实施例,但是,本发明实施例并非局限于此,任何本领域的技术人员能思之的变化都应落入本发明的保护范围。
- 还没有人留言评论。精彩留言会获得点赞!