数据处理方法、装置以及电子设备与流程
本申请涉及计算机技术领域,更具体地,涉及一种数据处理方法、装置以及电子设备。
背景技术:
深度学习的飞速发展伴随着移动端神经网络计算引擎的快速迭代,深度学习的算法一般都是具有大计算量的特点,尤其是矩阵乘法这类超大计算量的算子往往占据着深度学习算法算力需求的一大半。但是,在相关的矩阵乘法实施方式中,还存在矩阵乘法的运算效率有待提升的问题。
技术实现要素:
鉴于上述问题,本申请提出了一种数据处理方法、装置以及电子设备,以改善上述问题。
第一方面,本申请提供了一种数据处理方法,应用于电子设备,所述方法包括:获取进行矩阵乘法的待计算矩阵;将所述待计算矩阵所在内存块进行分块,得到多个子分块,所述子分块的尺寸小于所述内存块的尺寸;获取矩阵对应的内存排布方式;基于所述内存排布方式,将所述待计算矩阵的元素对应于所述多个子分块进行重新排列,得到重新排序后的待计算矩阵,其中,进行所述分块后,基于所述内存排布方式,从内存中读取所述重新排序后的待计算矩阵的元素时进行元素读取的次数,小于读取重新排序前的所述待计算矩阵的元素时进行元素读取的次数;
基于所述重新排序后的待计算矩阵执行所述矩阵乘法。
第二方面,本申请提供了一种数据处理装置,运行于电子设备,所述装置包括:矩阵获取单元,用于获取进行矩阵乘法的待计算矩阵;内存分块单元,用于将所述待计算矩阵所在内存块进行分块,得到多个子分块,所述子分块的尺寸小于所述内存块的尺寸;排布方式获取单元,用于获取矩阵对应的内存排布方式;内存重排单元,用于基于所述内存排布方式,将所述待计算矩阵的元素对应于所述多个子分块进行重新排列,得到重新排序后的待计算矩阵,其中,进行所述分块后,基于所述内存排布方式,从内存中读取所述重新排序后的待计算矩阵的元素时进行元素读取的次数,小于读取重新排序前的所述待计算矩阵的元素时进行元素读取的次数;数据处理单元,用于基于所述重新排序后的待计算矩阵执行所述矩阵乘法。
第三方面,本申请提供了一种电子设备,所述电子设备至少包括处理器、以及存储器;一个或多个程序被存储在所述存储器中并被配置为由所述处理器执行以实现上述方法。
第四方面,本申请提供了一种计算机可读存储介质,所述计算机可读存储介质中存储有程序代码,其中,在所述程序代码被处理器运行时执行上述的方法。
本申请提供的一种数据处理方法、装置以及电子设备,会在接收到矩阵乘法计算指令时,获取进行矩阵乘法的待计算矩阵,并对该计算矩阵所在的内存块进行分块,以得到多个子分块。并且,在获取到矩阵对应的内存排布方式以后,先基于所述内存排布方式,将所述待计算矩阵的元素对应于所述多个子分块进行重新排列,得到重新排序后的待计算矩阵,然后再基于所述重新排序后的待计算矩阵执行所述矩阵乘法。从而通过对待计算矩阵的元素在内存中的存储序列进行重新排列的方式,使得在对待矩阵原本的内存块进行分块以后,可以减少在进行分块后,在读取待计算矩阵的元素时,减少因为矩阵对应的内存排布方式所造成的较多的跨子分块进行元素读取的次数,进而可以减小从内存中读取所述待计算矩阵的元素时进行元素读取的次数,以提升矩阵乘法的运算效率。
附图说明
为了更清楚地说明本申请实施例中的技术方案,下面将对实施例描述中所需要使用的附图作简单地介绍,显而易见地,下面描述中的附图仅仅是本申请的一些实施例,对于本领域技术人员来讲,在不付出创造性劳动的前提下,还可以根据这些附图获得其他的附图。
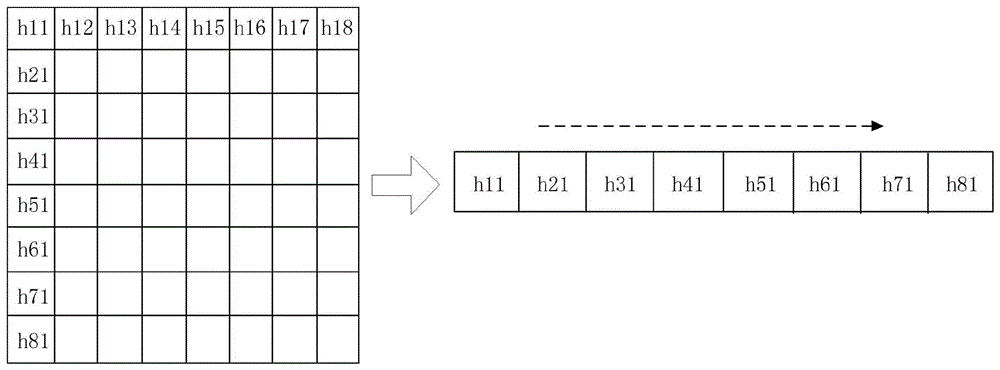
图1示出了本申请实施例中基于列主序进行矩阵的元素进行存储的示意图;
图2示出了本申请实施例中基于行主序进行矩阵的元素进行存储的示意图;
图3示出了本申请实施例中处理器、缓存以及内存的关系示意图;
图4示出了本申请实施例中对内存块进行分块的示意图;
图5示出了本申请实施例提出的一种数据处理方法的流程图;
图6示出了本申请实施例中一种对内存块进行分块得到两个子内存块的示意图;
图7示出了本申请实施例中一种对矩阵的元素进行重新排列后的示意图;
图8示出了本申请实施例中另一种对内存块进行分块得到两个子内存块的示意图;
图9示出了本申请实施例中另一种对矩阵的元素进行重新排列后的示意图;
图10示出了本申请另一实施例提出的一种数据处理方法的流程图;
图11示出了本申请再一实施例提出的一种数据处理方法的流程图;
图12示出了本申请实施例中矩阵乘法的示意图;
图13示出了本申请实施例中多层循环嵌套的示意图;
图14示出了本申请实施例提出的另一种数据处理装置的结构框图;
图15示出了本申请实施例提出的再一种数据处理装置的结构框图;
图16示出了本申请的用于执行根据本申请实施例的数据处理方法的另一种电子设备的结构框图;
图17是本申请实施例的用于保存或者携带实现根据本申请实施例的数据处理方法的程序代码的存储单元。
具体实施方式
下面将结合本申请实施例中的附图,对本申请实施例中的技术方案进行清楚、完整地描述,显然,所描述的实施例仅仅是本申请一部分实施例,而不是全部的实施例。基于本申请中的实施例,本领域普通技术人员在没有作出创造性劳动前提下所获得的所有其他实施例,都属于本申请保护的范围。
人工智能(artificialintelligence,ai)是利用数字计算机或者数字计算机控制的机器模拟、延伸和扩展人的智能,感知环境、获取知识并使用知识获得最佳结果的理论、方法、技术及应用系统。换句话说,人工智能是计算机科学的一个综合技术,它企图了解智能的实质,并生产出一种新的能以人类智能相似的方式做出反应的智能机器。人工智能也就是研究各种智能机器的设计原理与实现方法,使机器具有感知、推理与决策的功能。
人工智能技术是一门综合学科,涉及领域广泛,既有硬件层面的技术也有软件层面的技术。人工智能基础技术一般包括如传感器、专用人工智能芯片、云计算、分布式存储、大数据处理技术、操作/交互系统、机电一体化等技术。人工智能软件技术主要包括计算机视觉技术、语音处理技术、自然语言处理技术以及机器学习/深度学习等几大方向。
深度学习是人工智能技术中一项重要的技术,深度学习的飞速发展伴随着移动端神经网络计算引擎的快速迭代,深度学习的算法一般都是具有大计算量的特点,尤其是矩阵乘法这类超大计算量的算子往往占据着深度学习算法算力需求的一大半。但是,发明人在对相关的矩阵乘法的研究中发现,在相关的矩阵乘法实施方式中,还存在矩阵乘法的运算效率有待提升的问题。
具体的,矩阵通常会包括有多个元素,而在不同的电子设备中矩阵在内存中进行排布的方式可能是不同的。可选的,矩阵对应的内存排布方式可以有列主序排布以及行主序排布这两种方式。其中,列主序排布可以理解为,矩阵中的元素以列方向存储在内存中。示例性的,如图1所示,图1左侧示出了一8×8的矩阵,在矩阵中的第一行元素包括有h11、h12、h13、h14、h15、h16、h17以及h18,第一列的元素包括有h11、h21、h31、h41、h51、h61、h71以及h81(其他位置元素未在图中示出)。若在按照列主序排布的情况下,则会按照列为顺序对矩阵元素进行存储,即首先对h11所在的第一列元素进行存储(如图1右侧虚线箭头所示的方向),然后再对h12所在第二列元素进行存储,以此类推直到对最后一列的元素进行存储。
对应的,行主序排布可以理解为,矩阵中的元素以行方向存储在内存中。示例性的,如图2所示,若在按照行主序排布的情况下,则会按照行为顺序对矩阵元素进行存储,即首先对h11所在的第一行元素进行存储(如图2右侧虚线箭头所示的方向),然后再对h12所在第二行元素进行存储,以此类推对最后一行的元素进行存储。
在对于矩阵乘法的运算过程中,可以进一步的对矩阵所在的内存块进行分块,以便得到更小的子分块,而对于相比原来的内存块尺寸更小的子分块可以通过向量化来实现矩阵乘法运算,有提升运算效率,例如,可以通过neon技术来实现向量化的矩阵乘法运算。但是,在进行分块之后,会造成从内存中进行矩阵元素读取时,会有较多的不连续读取次数。其中,该不连续可以理解为矩阵元素对应的内存地址不连续,进而造成在读取一列(一行)元素时会多次从内存中进行元素的读取。
需要说明的是,矩阵乘法运算是由处理器执行的,而对于从内存中读取的矩阵元素会先存储到处理器对应的缓存中。其中,缓存可以通过其较快的数据访问速度解决处理器和内存(dram)直接速度不匹配的问题。示例性的,如图3所示,缓存通常位于处理器和内存之间。当缓存从内存中获取数据时以一个cacheline来读取的(示例性的,cacheline可以是64byte),下面以列主序排布方式为例对从内存中读取数据到缓存中的不连续读取问题进行说明。
如图1所示,在列主序排布的情况下,会先读取第一列数据,在图1左侧的矩阵全部存储在同一个内存块的情况下,在读取第一列数据时,是可以连续的读取到第一列数据中的h11、h21、h31、h41、h51、h61、h71以及h81,因为在读取的过程中都是在同一个内存块(memoryblock)上进行的数据读取,而h11、h21、h31、h41、h51、h61、h71以及h81各自对应的内存地址也是连续的,并没有出现跨内存块的情况。在一些情况下,若对矩阵原本的内存块进行分块以便可以适应向量化乘法运算的情况下,则会出现无法连续的进行元素读取的情况。例如,如图4所示,若在进行分块后,虚线框以内的元素和虚线框以外的元素分别在两个内存块上,那么就会造成按照列主序(图4左侧箭头所示方向)读取第一列元素时,只能先读取到h11、h21、h31以及h41,而与h41所对应的内存地址连续的为元素h12,,那么就会造成若又需要读取到这一列的元素中还未读取到的元素(即h51、h61、h71以及h81),则又需要再次访问内存从另一个内存块中读取到该h51、h61、h71以及h81,进而就会造成更多次的跨内存块的数据读取。在行主序排布下也会有类似的问题,此处就不再赘述。
因此,发明人在研究中发现上述问题后,提出了本申请中可以改善上述问题的数据处理方法、装置以及电子设备。该数据处理方法会在接收到矩阵乘法计算指令时,获取进行矩阵乘法的待计算矩阵,并对该计算矩阵所在的内存块进行分块,以得到多个子分块。并且,在获取到矩阵对应的内存排布方式以后,先基于所述内存排布方式,将所述待计算矩阵的元素对应于所述多个子分块进行重新排列,得到重新排序后的待计算矩阵,然后再基于所述重新排序后的待计算矩阵执行所述矩阵乘法。从而通过对待计算矩阵的元素在内存中的存储序列进行重新排列的方式,使得在对待矩阵原本的内存块进行分块以后,可以减少在进行分块后,在读取待计算矩阵的元素时,减少因为矩阵对应的内存排布方式所造成的较多的跨子分块进行元素读取的次数,进而可以减小从内存中读取所述待计算矩阵的元素时进行元素读取的次数,以提升矩阵乘法的运算效率。
下面将结合附图具体描述本申请的各实施例。
请参阅图5,本申请实施例提供的一种数据处理方法,应用于电子设备,所述方法包括:
s110:获取进行矩阵乘法的待计算矩阵。
作为一种方式,可以响应于矩阵乘法执行指令以获取进行矩阵乘法的待计算矩阵。其中,该矩阵乘法执行指令可以在多种场景下进行触发。示例性的,在神经网络模型的运行过程中,会涉及较多的矩阵乘法运算,那么在这种方式下,可以在神经网络模型的运行过程中触发矩阵乘法执行指令。
s120:将所述待计算矩阵所在内存块进行分块,得到多个子分块,所述子分块的尺寸小于所述内存块的尺寸。
需要说明的是,电子设备的内存可以是有多个内存块组成的,其中的内存块可以理解为内存进行数据存储的一个单位,并且在一个内存块内内存地址是连续的。在一些处理器中,可以通过向量化运算的方式来进行矩阵乘法运算,但是,该支持向量化运算的处理器中的寄存器的存储空间比较有限,为了能够支持该向量化运算则可以将需要进行向量化运算的数据所在的内存块进一步的分块,以得到尺寸更小的子分块。其中,该子分块实质上还是可以理解为一个内存块(memoryblock)。例如,若待计算矩阵的元素原本所在的内存块的尺寸为64×64,则可以将该尺寸为64×64的内存块划分为尺寸为4×8的内存块,或者尺寸为8×8的内存块。
再者,可以理解的是,在进行矩阵乘法的运算时,参与矩阵乘法运算的待计算矩阵至少为两个,然后经过乘法运算以后由可以得到一个新的矩阵。可选的,对于参与矩阵乘法运算的待计算矩阵以及运算以后得到的新的矩阵原本所在的内存块均可以安装不同的分块方式进行划分。示例性的,待计算矩阵包括矩阵a和矩阵b,计算得到的新的矩阵为矩阵c,那么运算式为c=a×b。在原本组成矩阵a、矩阵b以及矩阵c的内存块均为64×64的情况下,可以将矩阵a所在的内存块划分为4×8的子内存块,可以将矩阵b所在的内存块划分为8×8的子内存块,可以将矩阵c所在的内存块划分为4×8的子内存块。
s130:获取矩阵对应的内存排布方式。
其中,矩阵对应的内存排布方式表征了矩阵中的元素是按照何种方式存储在内存中的。例如,若在按照列主序排布的情况下,则会按照列为顺序对矩阵元素进行存储,若在按照行主序排布的情况下,则会按照行为顺序对矩阵元素进行存储。而在不同的电子设备中,矩阵所对应的内存排布方式可能会有不同。作为一种方式,电子设备可以将矩阵对应的内存排布方式进行存储。例如,存储在指定的系统文件中,在这种方式下,电子设备可以通过查询在指定的系统文件来获取到矩阵对应的内存排布方式。
s140:基于所述内存排布方式,将所述待计算矩阵的元素对应于所述多个子分块进行重新排列,得到重新排序后的待计算矩阵,其中,进行所述分块后,基于所述内存排布方式,从内存中读取所述重新排序后的待计算矩阵的元素时进行元素读取的次数,小于读取重新排序前的所述待计算矩阵的元素时进行元素读取的次数。
需要说明的是,在将待计算矩阵原本所在的内存块进行分块以后,按照前述的介绍,矩阵的某一列或者某一行元素各自对应的内存地址并不连续,进而就会造成无法连续的读取待计算矩阵原本的某一列或者某一行元素。那么通过对待计算矩阵的元素进行重新排列后,则可以使得待计算矩阵中的元素对应于多个子分块进行排布时可以对应有连续的内存地址,从而使得电子设备在从内存中读取所述重新排序后的待计算矩阵的元素时不会因为进行了分块而有更多的跨子内存块读取次数。其中,在本实施例中,待计算矩阵的元素对应于所述多个子分块进行重新排列可以理解为,将该多个子分块内的元素的内存地址进行重新配置。
例如,如图6所示,以列主序为例,在图6左侧图像所示的分块前的状态下,第一列元素h11、h21、h31、h41、h51、h61、h71以及h81是均在同一个内存块10中的,也就意味着,h11、h21、h31、h41、h51、h61、h71以及h81各自对应的内存地址是连续的,进而电子设备可以沿着左侧箭头所示的方向连续的从内存中连续的读取到h11、h21、h31、h41、h51、h61、h71以及h81,而在读取的过程中也不会存在跨内存块的读取的问题。
而图6中右侧示处了分块后的状态,在分块后的状态后,若并未对矩阵元素在内存中的存储序列进行重排,对于原本内存地址连续的h11、h21、h31、h41、h51、h61、h71以及h81,则会出现内存地址不连续的问题。例如,以列主序为例,按照子分块11中数据的内存地址排列情况,h41的内存地址与h12的内存地址是连续的,那么在读取h41后则不会连续的读取到h51。
并且,电子设备在从内存读取数据时,会按照内存块依次进行读取,那么在读取原本的第一列元素时,h11、h21、h31、h41因为均在子内存块11中,那么可以连续的读取到h11、h21、h31、h41,但是在需要读取后续的h51、h61、h71以及h81时,因为h51、h61、h71以及h81时在另外的子内存块12中,那么电子设备需要再次从内存中执行一次内存读取操作,以便从子内存块12中读取到h51、h61、h71以及h81,进而就出现了为了读取原本内存地址连续的元素会出现无法连续读取的问题。
而在基于所述内存排布方式,将所述待计算矩阵的元素对应于所述多个子分块进行重新排列后,则会使得分块之后,在子内存块中依然可以连续读取到矩阵中的一列或者一行元素。例如,如图7所示,对于原本矩阵的第一列元素h11、h21、h31、h41、h51、h61、h71以及h81,经过重排后则可以将h51、h61、h71以及h81重排到h11、h21、h31、h41所在子内存块的第二列中,从而使得在基于列主序进行元素排布(也可以理解为逐列进行元素的读取)的情况下,在读取完第一列元素h11、h21、h31、h41之后,进而又会从第二列的第一个元素开始进行读取,即从h51开始进行元素读取,从而可以连续的读取出h11、h21、h31、h41、h51、h61、h71以及h81,进而使得在分块之后,依然可以连续的进行元素读取。
类似的,如图8所示,在基于行主序的方式中,进行分块后可以有子分块14和子分块15。在行主序的方式中,电子设备会逐行进行元素的读取。例如,在图8左侧图像所示的矩阵中会先读取第一行的元素,以读取到h11、h12、h13、h14、h15、h16、h17以及h18,然后再对h21所在的第二行元素进行读取,以此类推直到读取最后一行元素。也就是说,元素h18和元素h21的内存地址是连续的。而在进行图8右侧图像所示的分块后的状态时,在读取完元素h14后,因为元素h14的内存地址和元素h21的内存地址是连续的,那么电子设备在读取元素h14后下一个读取的元素为h21,而不是h15,从而使得在读取原本一行的元素时,需要跨子内存块14和子内存块15进行元素读取,进而就会造成无法连续的进行元素读取,进而增加了从内存中进行元素读取的次数。
如图9所示,在基于行主序的排布方式进行内存重排后,在子内存块16中读取完第一行元素h11、h12、h13以及h14后,会从第二行的第一个元素继续进行读取,进而会在h14后读取到h15、h16、h17以及h18,进而使得又可以连续的对原本的第一行元素进行连续读取。
s150:基于所述重新排序后的待计算矩阵执行所述矩阵乘法。
在完成对待计算矩阵的元素进行重新排列后,则会基于重新排布后的元素来进行元素读取,进而基于读取出的元素执行矩阵乘法。
本申请提供的一种数据处理方法,会在接收到矩阵乘法计算指令时,获取进行矩阵乘法的待计算矩阵,并对该计算矩阵所在的内存块进行分块,以得到多个子分块。并且,在获取到矩阵对应的内存排布方式以后,先基于所述内存排布方式,将所述待计算矩阵的元素对应于所述多个子分块进行重新排列,得到重新排序后的待计算矩阵,然后再基于所述重新排序后的待计算矩阵执行所述矩阵乘法。从而通过对待计算矩阵的元素在内存中的存储序列进行重新排列的方式,使得在对待矩阵原本的内存块进行分块以后,可以减少在进行分块后,在读取待计算矩阵的元素时,减少因为矩阵对应的内存排布方式所造成的较多的跨子分块进行元素读取的次数,进而可以减小从内存中读取所述待计算矩阵的元素时进行元素读取的次数,以提升矩阵乘法的运算效率。
请参阅图10,本申请实施例提供的一种数据处理方法,应用于电子设备,所述方法包括:
s210:获取进行矩阵乘法的待计算矩阵。
s220:将所述待计算矩阵所在内存块进行分块,得到多个子分块,所述子分块的尺寸小于所述内存块的尺寸。
s230:获取矩阵对应的内存排布方式。
在内存中为所述待计算矩阵分配与所述多个子分块的尺寸相同的多个新的子内存块。
s240:基于所述内存排布方式,在所述多个新的子内存块中对所述待计算矩阵的元素的存储序列进行重新排列,得到重新排序后的待计算矩阵;其中,进行所述分块后,基于所述内存排布方式,从内存中读取所述重新排序后的待计算矩阵的元素时进行元素读取的次数,小于读取重新排序前的所述待计算矩阵的元素时进行元素读取的次数。
在本实施例中,作为一种元素的存储序列进行重新排列的方式,可以对应于分块所得到的子内存块新建新的子内存块,然后将待矩阵元素在多个新的子内存块中按照矩阵对应的内存排布方式进行重新排列,以便可以在每个子内存块类连续的对待计算矩阵的元素进行读取。示例性的,若待计算矩阵的元素原本所在的内存块的尺寸为64×64,则可以将该尺寸为64×64的内存块划分为尺寸为4×8的子内存块,那么建立的新的子内存块的尺寸也可以为4×8。
需要说明的是,在通过建立新的子内存块来进行元素重新排列的情况下,在完成元素重新排列后,在执行矩阵乘法时则会从该多个新的子内存块中读取元素执行乘法运算。
作为一种方式,若所述内存排布方式为列主序排布,基于列主序排布的方式将所述待计算矩阵的元素对应于所述多个子分块进行重新排列,得到重新排序后的待计算矩阵。
作为一种方式,若所述内存排布方式为行主序排布,基于所述行主序排布的方式将所述待计算矩阵的元素对应于所述多个子分块进行重新排列,得到重新排序后的待计算矩阵。
s250:从所述多个新的内存块中读取所述重新排序后的待计算矩阵的元素,以执行所述矩阵乘法。
本申请提供的一种数据处理方法,从而通过对待计算矩阵的元素在内存中的存储序列进行重新排列的方式,使得在对待矩阵原本的内存块进行分块以后,可以减少在进行分块后,在读取待计算矩阵的元素时,减少因为矩阵对应的内存排布方式所造成的较多的跨子分块进行元素读取的次数,进而可以减小从内存中读取所述待计算矩阵的元素时进行元素读取的次数,以提升矩阵乘法的运算效率。并且,在本实施例中,在进行矩阵元素的重新排列时,会分配与所述多个子分块的尺寸相同的多个新的子内存块,进而使得可以在该多个新的子内存块内对待计算矩阵的元素进行重新排列,以便后续在进行待计算矩阵元素的读取时,可以直接从该多个新的子内存块进行读取,避免数据读取错误。
请参阅图11,本申请实施例提供的一种数据处理方法,应用于电子设备,所述方法包括:
s310:获取进行矩阵乘法的待计算矩阵。
s320:将所述待计算矩阵所在内存块进行分块,得到多个子分块,所述子分块的尺寸小于所述内存块的尺寸。
s330:获取矩阵对应的内存排布方式。
s340:基于所述内存排布方式,将所述待计算矩阵的元素对应于所述多个子分块进行重新排列,得到重新排序后的待计算矩阵,其中,进行所述分块后,基于所述内存排布方式,从内存中读取所述重新排序后的待计算矩阵的元素时进行元素读取的次数,小于读取重新排序前的所述待计算矩阵的元素时进行元素读取的次数。
s350:基于所述重新排序后的待计算矩阵生成多层循环嵌套计算式,其中,每层所述循环嵌套计算式的循环次数基于所述重新排序后的待计算矩阵的尺寸得到。
如图12所示,待计算矩阵包括矩阵a和矩阵b,其中矩阵a的尺寸为m×k,矩阵b的尺寸为k×n。那么在执行矩阵a和矩阵b的乘法运算的过程中,会有三层的循环嵌套,并且该三层循环的次数分别为m、k以及n。那么基于所述重新排序后的待计算矩阵生成多层循环嵌套计算式可以为三层依次嵌套的for循环函数。该所构建的三层依次嵌套的for循环函数可以如下:
可选的,在本实施例中,对于所建立的多层循环嵌套计算式的循环顺序也可以进行改变。例如,在前述所示的循环顺序中,会先执行最内层的k循环,然后再执行中间层的n循环,然后执行最外层的m的循环。作为另外一种方式,可以将该三层循环的顺序进行改变。例如,在执行s340之前的内存块的尺寸为64×64的情况下,则可以将三层循环的顺序改为下列方式:
在上述方式中,会先执行最内层的n循环,然后执行中间的k循环,再执行最外面一层的m循环。如图13所示,其中的数字1标识的是最内层的n循环,数字2标识的是中间层的k循环,数字3标识的是最外层的m循环。其中,数字1所标识的最内存循环可以理解为沿1所对应箭头方向的跨子分块的循环,在子分块的尺寸为4×8的情况下,即会先访问左上部分的尺寸为4×8的第一个子分块17,然后访问左下部分的尺寸为4×8的子分块18,而在访问每一个子分块时又会按照逐列的方式进行循环,即逐列的进行元素读取,而数字3所标识的循环可以理解为在访问左下部分的尺寸为4×8的子分块后,会接着访问右上部的尺寸为4×8的子分块19。
s360:基于所述多层循环嵌套计算式执行所述矩阵乘法。
需要说明的是,在本申请实施例中,为了提升矩阵算法的执行效率,可以建立多个线程来并行化执行多层的循环。可选的,可以基于openmp方式建立多个线程,进而基于所述多个线程并行执行所述多层循环嵌套计算式,以执行所述矩阵乘法。
在一种方式中,所述基于openmp方式建立多个线程,包括:基于openmp方式触发建立多个线程,并基于schedule方式将所述多个线程的调度方式配置为动态调度,其中每个线程分别由所述电子设备的不同核运行。
需要说明的是,在基于openmp方式触发建立多个线程后,可以由多个核分别来承载一个线程。例如,在处理器包括有大核和小核的情况下,可以触发该大核和小核均参与到矩阵乘法的运算过程中,对应的会使得大核和小核分别承载不同的线程。在这种方式下,若基于schedule方式将所述多个线程的调度方式配置为动态调度,则分配到大核和小核上的处理任务会动态进行分配,使得处于完成当前处理任务的线程会再次分配新的处理任务,进而使得处理能力更强的大核可以分配更多的处理任务,以便减轻小核所需处理的任务的数量。
作为一种方式,基于schedule方式将所述多个线程的调度方式配置为动态调度的代码可以配置在前述的多层循环嵌套计算式之前,进而减少前述基于openmp方式建立多个线程重复进行建立和销毁的次数。需要说明的是,在多层循环嵌套计算式中,每执行基于schedule方式将所述多个线程的调度方式配置为动态调度的代码之前的for循环代码时,每次执行完成一次循环时都需要对线程进行销毁。如下列三层for循环所示:
其中,“#pragmaompparallelforschedule(dynamic)”为基于schedule方式将所述多个线程的调度方式配置为动态调度的代码。那么其中的对于“#pragmaompparallelforschedule(dynamic)”之前的n循环和m循环则在执行过程中需要每次从内存中读取元素需要新建线程,而在完成计算后由回销毁线程,进而使得在n循环和m循环的过程中需要多次重复新建和销毁线程。需要说明的是,在本实施例中n循环可以理解为循环次数为n的for循环,类似的,m循环可以理解为循环次数为m的for循环。
而将基于schedule方式将所述多个线程的调度方式配置为动态调度的代码可以配置在前述的多层循环嵌套计算式之前之后,则使得在多层循环嵌套计算式的计算过程中,在每次执行完循环计算后都不必进行线程的销毁,以便可以缩短线程的建立和销毁所消耗的时间,以进一步的提升矩阵乘法的运算效率。示例性的,若将“#pragmaompparallelforschedule(dynamic)”如下述方式配置待多层for循环之前,那么则对于在“#pragmaompparallelforschedule(dynamic)”之后的m循环、n循环以及k循环在执行过程中不会在每次循环执行完成后销毁线程。
本申请提供的一种数据处理方法,从而通过对待计算矩阵的元素在内存中的存储序列进行重新排列的方式,使得在对待矩阵原本的内存块进行分块以后,可以减少在进行分块后,在读取待计算矩阵的元素时,减少因为矩阵对应的内存排布方式所造成的较多的跨子分块进行元素读取的次数,进而可以减小从内存中读取所述待计算矩阵的元素时进行元素读取的次数,以提升矩阵乘法的运算效率。并且,在本实施例中,会基于所述重新排序后的待计算矩阵生成多层循环嵌套计算式,而且该多层循环嵌套计算式可以由基于openmp方式触发建立多个线程来执行,从而提升了矩阵乘法的运算效率。
请参阅图14,本申请实施例提供的一种数据处理装置400,运行于电子设备,所述装置400包括:
矩阵获取单元410,用于获取进行矩阵乘法的待计算矩阵。
内存分块单元420,用于将所述待计算矩阵所在内存块进行分块,得到多个子分块,所述子分块的尺寸小于所述内存块的尺寸。
排布方式获取单元430,用于获取矩阵对应的内存排布方式。
内存重排单元440,用于基于所述内存排布方式,将所述待计算矩阵的元素对应于所述多个子分块进行重新排列,得到重新排序后的待计算矩阵,其中,进行所述分块后,基于所述内存排布方式,从内存中读取所述重新排序后的待计算矩阵的元素时进行元素读取的次数,小于读取重新排序前的所述待计算矩阵的元素时进行元素读取的次数。
作为一种方式,若所述内存排布方式为列主序排布,内存重排单元440,具体用于基于列主序排布的方式将所述待计算矩阵的元素对应于所述多个子分块进行重新排列,得到重新排序后的待计算矩阵。
作为一种方式,若所述内存排布方式为行主序排布,若所述内存排布方式为行主序排布,基于所述行主序排布的方式将所述待计算矩阵的元素对应于所述多个子分块进行重新排列,得到重新排序后的待计算矩阵。
数据处理单元450,用于基于所述重新排序后的待计算矩阵执行所述矩阵乘法。
作为一种方式,内存重排单元440,具体用于在内存中为所述待计算矩阵分配与所述多个子分块的尺寸相同的多个新的子内存块;基于所述内存排布方式,在所述多个新的子内存块中对所述待计算矩阵的元素的存储序列进行重新排列,得到重新排序后的待计算矩阵。在这种方式下,数据处理单元450,具体用于从所述多个新的内存块中读取所述重新排序后的待计算矩阵的元素,以执行所述矩阵乘法。
作为一种方式,数据处理单元450,具体用于基于所述重新排序后的待计算矩阵生成多层循环嵌套计算式,其中,每层所述循环嵌套计算式的循环次数基于所述重新排序后的待计算矩阵的尺寸得到;基于所述多层循环嵌套计算式执行所述矩阵乘法。
可选的,如图15所示,所述装置400还包括:线程管理单元460,用于基于openmp方式建立多个线程。数据处理单元450,具体用于基于所述多个线程并行执行所述多层循环嵌套计算式,以执行所述矩阵乘法。其中,线程管理单元460,具体用于基于openmp方式触发建立多个线程,并基于schedule方式将所述多个线程的调度方式配置为动态调度,其中每个线程分别由所述电子设备的不同核运行。
本申请提供的一种数据处理装置,会在接收到矩阵乘法计算指令时,获取进行矩阵乘法的待计算矩阵,并对该计算矩阵所在的内存块进行分块,以得到多个子分块。并且,在获取到矩阵对应的内存排布方式以后,先基于所述内存排布方式,将所述待计算矩阵的元素对应于所述多个子分块进行重新排列,得到重新排序后的待计算矩阵,然后再基于所述重新排序后的待计算矩阵执行所述矩阵乘法。从而通过对待计算矩阵的元素在内存中的存储序列进行重新排列的方式,使得在对待矩阵原本的内存块进行分块以后,可以减少在进行分块后,在读取待计算矩阵的元素时,减少因为矩阵对应的内存排布方式所造成的较多的跨子分块进行元素读取的次数,进而可以减小从内存中读取所述待计算矩阵的元素时进行元素读取的次数,以提升矩阵乘法的运算效率。
需要说明的是,本申请中装置实施例与前述方法实施例是相互对应的,装置实施例中具体的原理可以参见前述方法实施例中的内容,此处不再赘述。
下面将结合图16对本申请提供的一种电子设备进行说明。
请参阅图16,基于上述的图片处理方法、装置,本申请实施例还提供的另一种可以执行前述图片处理方法的电子设备100。电子设备100包括相互耦合的一个或多个(图中仅示出一个)处理器102、存储器104以及网络模块106。其中,该存储器104中存储有可以执行前述实施例中内容的程序,而处理器102可以执行该存储器104中存储的程序。
其中,处理器102可以包括一个或者多个处理核。处理器102利用各种接口和线路连接整个电子设备100内的各个部分,通过运行或执行存储在存储器104内的指令、程序、代码集或指令集,以及调用存储在存储器104内的数据,执行电子设备100的各种功能和处理数据。可选地,处理器102可以采用数字信号处理(digitalsignalprocessing,dsp)、现场可编程门阵列(field-programmablegatearray,fpga)、可编程逻辑阵列(programmablelogicarray,pla)中的至少一种硬件形式来实现。处理器102可集成中央处理器(centralprocessingunit,cpu)、图像处理器(graphicsprocessingunit,gpu)和调制解调器等中的一种或几种的组合。其中,cpu主要处理操作系统、用户界面和应用程序等;gpu用于负责显示内容的渲染和绘制;调制解调器用于处理无线通信。可以理解的是,上述调制解调器也可以不集成到处理器102中,单独通过一块通信芯片进行实现。
存储器104可以包括随机存储器(randomaccessmemory,ram),也可以包括只读存储器(read-onlymemory)。存储器104可用于存储指令、程序、代码、代码集或指令集。存储器104可包括存储程序区和存储数据区,其中,存储程序区可存储用于实现操作系统的指令、用于实现至少一个功能的指令(比如触控功能、声音播放功能、图像播放功能等)、用于实现下述各个方法实施例的指令等。存储数据区还可以存储终端100在使用中所创建的数据(比如电话本、音视频数据、聊天记录数据)等。
所述网络模块106用于接收以及发送电磁波,实现电磁波与电信号的相互转换,从而与通讯网络或者其他设备进行通讯,例如和音频播放设备进行通讯。所述网络模块106可包括各种现有的用于执行这些功能的电路元件,例如,天线、射频收发器、数字信号处理器、加密/解密芯片、用户身份模块(sim)卡、存储器等等。所述网络模块106可与各种网络如互联网、企业内部网、无线网络进行通讯或者通过无线网络与其他设备进行通讯。上述的无线网络可包括蜂窝式电话网、无线局域网或者城域网。例如,网络模块106可以与基站进行信息交互。
请参考图17,其示出了本申请实施例提供的一种计算机可读存储介质的结构框图。该计算机可读介质1100中存储有程序代码,所述程序代码可被处理器调用执行上述方法实施例中所描述的方法。
计算机可读存储介质1100可以是诸如闪存、eeprom(电可擦除可编程只读存储器)、eprom、硬盘或者rom之类的电子存储器。可选地,计算机可读存储介质1100包括非易失性计算机可读介质(non-transitorycomputer-readablestoragemedium)。计算机可读存储介质1100具有执行上述方法中的任何方法步骤的程序代码1110的存储空间。这些程序代码可以从一个或者多个计算机程序产品中读出或者写入到这一个或者多个计算机程序产品中。程序代码810可以例如以适当形式进行压缩。
本申请提供的一种数据处理方法、装置以及电子设备,会在接收到矩阵乘法计算指令时,获取进行矩阵乘法的待计算矩阵,并对该计算矩阵所在的内存块进行分块,以得到多个子分块。并且,在获取到矩阵对应的内存排布方式以后,先基于所述内存排布方式,将所述待计算矩阵的元素对应于所述多个子分块进行重新排列,得到重新排序后的待计算矩阵,然后再基于所述重新排序后的待计算矩阵执行所述矩阵乘法。从而通过对待计算矩阵的元素在内存中的存储序列进行重新排列的方式,使得在对待矩阵原本的内存块进行分块以后,可以减少在进行分块后,在读取待计算矩阵的元素时,减少因为矩阵对应的内存排布方式所造成的较多的跨子分块进行元素读取的次数,进而可以减小从内存中读取所述待计算矩阵的元素时进行元素读取的次数,以提升矩阵乘法的运算效率。
并且,在本实施例中对待矩阵元素所在的内存块进行分块的一个目的在于使得可以通过向量化运算的方式来进行矩阵乘法运算,进而再这种情况下,在进行分块之后再通过本实施例数据处理方法中的内存重新排列的方式可以使得在基于向量化运算的方式提升矩阵乘法的运算效率时,进一步的通过内存重新排列的方式再次提升了矩阵乘法的运算效率。
最后应说明的是:以上实施例仅用以说明本申请的技术方案,而非对其限制;尽管参照前述实施例对本申请进行了详细的说明,本领域的普通技术人员当理解:其依然可以对前述各实施例所记载的技术方案进行修改,或者对其中部分技术特征进行等同替换;而这些修改或者替换,并不驱使相应技术方案的本质脱离本申请各实施例技术方案的精神和范围。
- 还没有人留言评论。精彩留言会获得点赞!