一种基于分类错误率和一致性预测的概念漂移检测方法与流程
本发明提出了一种基于分类错误率和一致性预测的概念漂移检测方法,属于计算机机器学习和信息安全技术领域。
背景技术:
随着大数据时代的到来,机器学习算法在众多领域的应用飞速发展。其中,基于大数据技术的信息安全是近几年最活跃的研究热点之一,出现了大量代码克隆检测模型、恶意代码分类模型、漏洞预测模型、缺陷预测模型等机器学习分类模型,这些模型在构建时都获得了极高的准确率。
在信息安全领域,软件随时间不断演化,出现了不同的类别。以恶意软件为例,根据行为特点可以分为木马、蠕虫等大类,还可以进一步细分成小类,这种小类被称为家族。同一家族的恶意软件还可以演化成不同变种。恶意软件的大类变化较小,新的家族不断出现,有些家族还不断产生变种。分析表明,不同家族之间的差异较大,同一家族的不同变种之间差异较小,因此新家族的产生会引起恶意代码出现突变型概念漂移,而新变种的产生则引起渐进型概念漂移。由此可见,为了提高软件分类器的可持续性,在新软件不断出现的情况下长期保持较高的准确率,有必要及时准确地检测软件中的概念漂移,包括突变型概念漂移和渐进型概念漂移。
攻击者为了逃避检测,通过变形等混淆技术以及0day漏洞的利用,使得恶意代码在不断变异和进化,其分布随时间发生改变,产生了概念漂移现象,最终导致以前构建的分类模型无法正确地对漂移数据进行分类,引起模型退化问题。恶意代码通过加壳、变形、混淆等技术不断生成新的变种,随着时间会产生两种类型的概念漂移,突变型概念漂移和渐进型概念漂移。突变型概念漂移表现为恶意代码数据流中有较多的数据在短时间内发生变异和进化,类标签与之前的完全不同,此时若使用原先的模型对其进行预测,将无法得到较准确的结果。渐进型概念漂移是指恶意代码数据中部分数据在缓慢地进化和变异,若取进化过程中的一段时间的数据进行检测,由于变化程度较小,容易被检测机制遗漏,将无法准确识别概念漂移现象。ddm(driftdetectionmethod)是最常用的概念漂移检测方法且具有较好的检测准确率,通过观察当前模型对最新的数据集的分类性能来判断最新的数据集中是否包含概念漂移,若模型的分类性能出现大幅下降,则说明新训练集中包含概念漂移。ddm检测法可适用于任何分类算法,且其计算效率高,能检测突变型概念漂移,然而,出现渐进型概念漂移时,该算法则无法及时识别。由于渐进型概念漂移具有变化缓慢的特点,而现有分类算法往往根据属于某个类别的概率来评价其判定结果,无法准确地对被错误分类的与训练的不一致程度进行统计量化分析,因此不能及时检测出渐进型概念漂移对分类效果的影响。
因此,需要一种能及时识别模型出现退化迹象的概念漂移检测方法,为分类模型的更新提供依据,最终保持分类模型的可持续性,即在不断出现新的恶意代码变种的情况下依然保持较高的分类准确率。
技术实现要素:
本发明的目的是为了解决信息安全中软件分析领域中机器学习分类模型概念漂移检测的技术问题,创造性地提出一种分类错误率和一致性预测相结合的概念漂移检测方法,对于评估当前信息安全领域中迅速增多的基于机器学习分类算法的安全检测或测评系统在面对不断演化的恶意软件时的性能和持续性,具有重要的现实意义。
本方法,首先通过计算模型分类错误率的变化来检测突变型概念漂移,然后通过计算分类错误的样本与分类正确的样本一致性程度来检测渐进型概念漂移,从而能及时检测突变型概念漂移和渐进型概念漂移,且保持较小的计算开销。
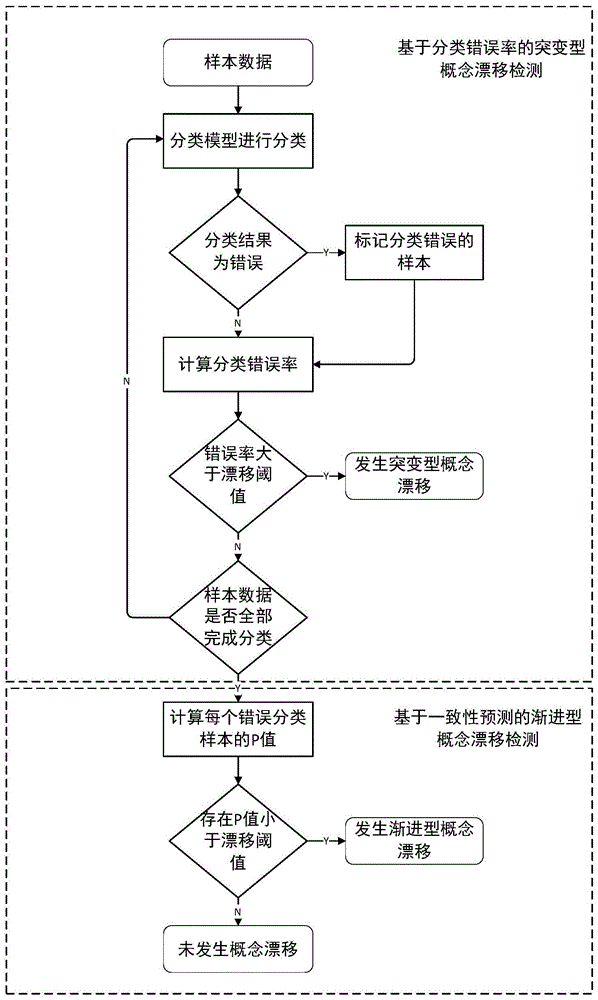
本方法的技术方案包括两个部分,即基于分类错误率的突变型概念漂移检测和基于一致性预测器的渐进型概念漂移检测。
其中,基于分类错误率的突变型概念漂移检测,是通过检测样本数据分布的改变来检测概念漂移。当概念发生变化时,数据的分布发生改变,分类模型会对发生漂移的样本产生错误的分类预测,因此,如果分类错误率增加,则表明发生了概念漂移。首先使用分类模型对样本进行分类,标记分类错误的样本,并计算分类错误率,若分类错误率大于漂移阈值,则说明发生突变型概念漂移。
若所有样本都完成分类,而分类错误率仍小于漂移阈值,则进一步使用一致性预测器算法检测渐进型概念漂移。通过计算分类错误的样本的p值,判断分类错误的样本中是否存在以前未出现的新类,若存在样本的p值小于漂移阈值,则说明数据发生渐进型概念漂移,若所有分类错误的样本的p值都大于漂移阈值,则说明数据未发生概念漂移。
有益效果
本发明方法,旨在通过识别机器学习分类模型的退化现象,进行概念漂移的检测,特别是突变型概念漂移和渐进型概念漂移的检测。本方法,通过分类错误率来检测突变型概念漂移,通过计算分类错误的样本与分类正确的样本的一致性程度来检测渐进型概念漂移,实现了在较低计算成本下对突变型概念漂移和渐进型概念漂移的检测,及时识别模型退化现象。本发明主要用于概念漂移检测,能有效作用于机器学习分类模型退化现象的早期判定,可以作为大数据环境下自动化分析和决策等各种应用领域的性能监测方法。
与现有最好技术相比,本发明的优点在于:
1.本发明能够同时检测突发型概念漂移和渐进型概念漂移,适用于检测恶意软件样本中的新家族和新变种,进而有效评估基于机器学习分类算法的安全检测或测评系统的可持续性;
2.本发明将分类错误率和一致性度量有机结合,先检测突发型概念漂移,仅在错误率低于漂移阈值的情况下,即没有突发型概念漂移时,才只对出现分类错误的样本进行一致性度量,与仅使用一致性检测器的检测方法相比,计算量大大降低。
附图说明
图1是本发明所述方法的流程图。
图2是漂移阈值计算流程图。
具体实施方式
下面结合附图和实施例对本发明方法做进一步详细说明。
一种分类错误率和一致性预测相结合的概念漂移检测方法,将分类错误率变化检测和一致性预测器相结合,能够检测因突变型概念漂移和渐进型概念漂移引起的任意机器学习分类模型的退化问题。
本发明方法,包括基于分类错误率的突变型概念漂移检测和基于一致性预测器的渐进型概念漂移检测两部分,其流程如图1所示。
步骤一:使用分类模型对样本进行分类。
将测试数据集的数据依次输入分类模型进行分类,输入的样本序列记为(xi,yi),xi是样本的多维特征,yi是样本真实类别标签,模型对xi的预测标签是yi^,通过比较yi和yi^,确定样本i的预测结果是否正确。
步骤二:基于分类错误率的突变型概念漂移检测。
标记分类错误的样本,并计算此时的分类错误率err和标准偏差s。对于样本i,分类错误率erri为该时刻分类结果中分类错误的概率,对应的标准偏差为si=sqrt(erri(1-erri)/i)。若分类错误率和标准偏差之和大于漂移阈值,则表示该模型发生概念漂移,若小于漂移阈值,则继续下一个样本的分类。若测试数据集中最后一个样本的分类错误率和标准偏差之和小于漂移阈值,则未发生突变型概念漂移,并进一步执行基于一致性预测器的检测。
其中,所述漂移阈值的计算过程如图2所示,将分类错误率err的最小值errmin和标准偏差s的最小值smin初始化为1,样本数据依次输入分类模型进行分类,并计算分类错误率erri和标准偏差si,若erri<errmin,则用erri替换errmin;若si<smin,则用si替换smin,直到样本数据全部完成分类,得到分类错误率最小值errmin和标准偏差最小值smin。将置信水平设为99%,漂移阈值为errmin+3smin。
步骤三:基于一致性预测器的渐进型概念漂移检测。
本发明使用一致性预测器的核心算法,来衡量样本与其他样本的一致性程度。所述一致性预测器算法(comformalpredictor,cp),是一种域预测分类算法,通过分析待测样本和已知类别标签的样本之间的内在联系,预测出待测样本的类别域,并使用置信度对预测的类别域进行评估。
通过基于分类错误率的检测后,测试数据集中每个样本数据都对应一种分类结果。基于一致性预测的方法将分类错误的样本作为待测数据集,分类正确的样本作为已知类别标签的样本数据集b=(z1,z2,...,zn-1),对于待测数据集中的每一个待测样本zn=(xi,yi),将所有可能的类别都赋值给类别标签yi,若有m个类别,则yi=1,2,...,m。将待测样本加入到样本数据集b中,构成m个待检验样本序列{z1,z2,...,zn-1,zn=(xn,yn)},yn=1,2,...,m,每个待检验样本序列包含n个样本。对m个待检验样本序列分别进行随机性检验。步骤如下:
第一步:通过奇异值映射函数a(b,z),得到样本数据集b中所有样本和待测样本的奇异值αi。奇异值映射函数使用机器学习算法挖掘样本之间的内在联系来计算奇异值。该检测算法使用距离来表示待测样本与数据集b中样本的一致程度,若距离越小,则待测样本与样本数据集b中样本越相似。利用knn算法的思想,定义奇异值映射函数,如式(1)所示:
其中,
第二步:通过奇异值计算待测样本的每个可能的类别标签对应的p值,p值表示在样本序列b中比待测样本奇异值大的样本数量占样本总数的比例,即
第三步:通过p值的大小识别不属于已知类别的新样本,进而判断是否发生渐进型概念漂移。对于步骤一中分类错误的样本可能存在两种情况:一种是样本被错误地分类,但真实类别属于已知类别,另一种是样本被错误地分类,但实际上不属于任何一种已知类别。若待测样本为第一种情况,则至少有一个类别标签对应的p值不接近0,即待测样本的最大p值不接近0。若待测样本为第二种情况,则每个类别标签对应的p值都接近0,即待测样本的最大p值接近0。因此,可以通过判断待测样本的m个p值中的最大值是否接近0来判断该样本是否属于已知类别。
由于接近0是一个比较模糊的概念,本方法通过设置漂移阈值,比较待测样本的p值与漂移阈值的大小来判断是否存在新类。计算所有属于已知类别的样本的p值,包括正确分类样本和错误分类样本,将所有p值的最小值作为漂移阈值。若存在待测样本的p值小于漂移阈值,则待测样本中存在不属于已知类别的新类,即数据发生了渐进型概念漂移。若所有待测样本的p值都大于漂移阈值,则数据未发生渐进型概念漂移。
- 还没有人留言评论。精彩留言会获得点赞!