一种基于邻域拓扑结构的异常金融组织层次划分系统及其工作方法与流程
本发明涉及一种异常金融组织层次划分系统及其工作方法,尤其涉及一种基于邻域拓扑结构的异常金融组织层次划分系统及其工作方法。
背景技术:
异常金融组织是金融交易行为存在异常情形的金融组织,种类繁多。常见的有传销组织、非法集资组织、洗钱组织等。其中,传销组织是典型的异常金融组织。传销是一种扰乱经济秩序的犯罪行为,本质上属于“庞氏骗局”,即利用新加入人员的钱来向先前加入人员支付利息和短期回报,以制造赚钱的假象进而骗取更多的投资。传销组织具有典型的金字塔架构,传销组织成员之间相互转账构成的交易网络也具有典型的层次性。根据传销组织交易网络准确判断传销组织成员在传销组织中的级别层次具有充分的现实意义。目前,根据传销组织转账交易分析传销组织成员级别的方法在很大程度上依赖人工判断,需要大量人力参与。而面对繁复众多的传销组织数据,传统的利用人工判断的方法无法有效满足大规模数据分析处理的需要。
目前,基于网络表示学习的方法在提取网络信息方面取得了很大进展。这类方法可以将网络中的节点映射成低维稠密向量,然后应用到后续任务。很多研究充分吸取了自然语言处理领域的算法,将word2vec模型应用到了网络表示学习领域,取得了更好的学习效果,生成的节点向量也能够更好的满足后续任务。国内有关网络表示学习的研究主要有line算法、sdne算法和tadw算法等。但line算法和sdne算法主要捕捉节点的一阶邻居和二阶邻居信息,采样范围小。而传销网络属于多层次网络,这两类方法无法全面而有效地捕捉传销交易网络中账号节点的层次信息,更倾向于将转账交易密切的账号划分为一类,无法对网络进行层次划分。tadw算法为处理社交网络设计,应用了节点的发言文本这一异质信息。tadw算法在应用到传销交易网络上时,除传销网络本身外,需额外引入其他类型数据,如交易摘要信息、通话信息、聊天记录等,因此需要更多的人工参与收集信息,前期的数据预处理任务会导致劳动力密集型工作,无法有效减少人力成本。现有方法大多无法针对传销组织交易网络特点进行针对性分析,更为有效地提取账号节点的层次信息、完成异常金融组织层次划分工作,从而减少劳动力密集型工作,提高传销组织成员级别划分的自动化程度。
技术实现要素:
针对现有技术的不足,本发明提供了一种基于邻域拓扑结构的异常金融组织层次划分系统;
本发明还提供了上述异常金融组织层次划分系统的工作方法;
本发明能够提取异常金融组织的交易流水信息,在此基础上构建异常交易网络,并使用自定义的基于邻域拓扑结构的网络表示学习方法提取账号的邻域拓扑结构特征,为每个账号生成对应的低维稠密向量,然后使用k-means算法对节点向量进行聚类处理,完成异常金融组织层次划分任务。本发明能够用于:1)基于金融交易流水的异常金融组织交易网络构建。2)基于邻域拓扑结构特征的异常金融组织层次划分。
术语解释:
1、ntf算法,属于网络表示学习方法的一种。它的关键思想包括:
1)衡量节点对的结构相似性与节点对的相对位置无关。两节点的相似程度只与它们的邻域拓扑结构有关,与两节点是否连通、在网络中的位置、标签和属性无关。
2)引入能级概念衡量邻域节点在中心节点邻域拓扑结构中的重要程度,并将其作为邻域节点的特征参与描述中心节点的邻域拓扑结构。采用能量耗散的思想,筛选出对中间节点影响较大的邻域节点,构造中心节点的影响力子网络,可以有效减少噪声数据的干扰。
3)使用邻域节点的相对特征和绝对特征来表示中心节点的结构特征,综合考虑邻居节点本身的固有属性和其相对中心节点邻域结构的重要程度,更好的反映中心节点的邻域结构特征。
4)节点邻域结构表示的层次化。从中心节点出发,采用广度优先搜索的思想按邻居节点到中心节点的距离逐层进行采样,更为合理的描述中心节点邻域结构拓扑特征。
2、ntf模型,主要包括以下四个步骤:
1)生成节点的影响力子网络。ntf模型的引入能级概念来衡量邻居节点相对于中心节点的重要程度,首先从网络中筛选出对中心节点邻域拓扑结构重要程度较大的邻居节点,连同它们的边一起构造中心节点的影响力子网络。
2)获取节点的邻域拓扑结构表示。按照给定的最大采样深度,在步骤1)求得的中心节点的影响力子网络上,从中心节点出发,采用广度优先搜索的策略,按距离逐层向外扩展取样,使用节点的能级和度来表示采样过程中扩展到的邻居节点,其中能级是相对特征,度是绝对特征。扩展采样得到的邻居节点的序列为中心节点的邻域拓扑结构表示。
3)构建二次图。二次图是在原图基础上新构建的一张无向有权图。根据步骤2)求得的节点的邻域拓扑结构表示,计算节点对的邻域拓扑结构相似度,据此计算在二次图上节点对的边的权重,具体计算方式如下文公式(ⅲ)所示。
4)生成节点的向量表示。首先在步骤3构建的二次图上进行随机游走操作,为每个节点生成对应的节点上下文序列,然后使用skip-gram算法根据节点上下文序列为每个节点生成上下文表示。
本发明的技术方案为:
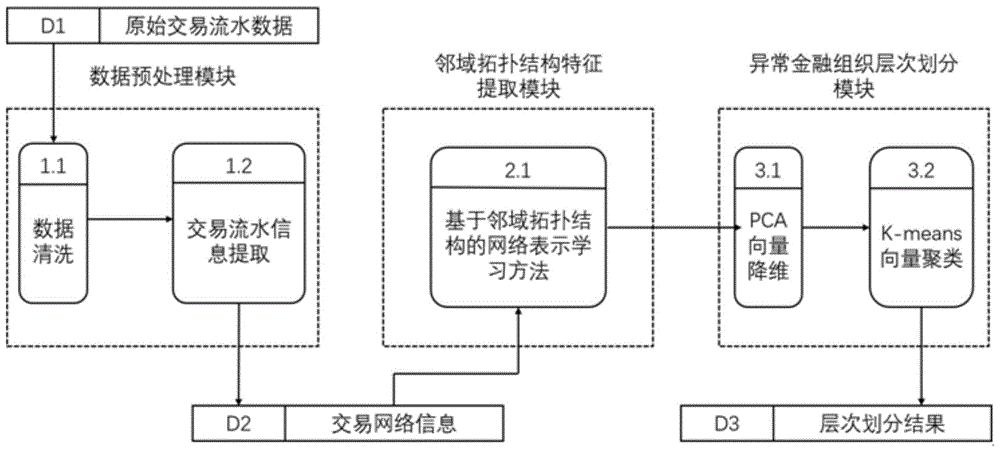
一种基于邻域拓扑结构的异常金融组织层次划分系统,包括依次连接的数据预处理模块、邻域拓扑结构特征提取模块和异常金融组织层次划分模块;
所述数据预处理模块用于:对输入的异常金融组织交易流水数据依次进行去重、去噪和去不完整数据操作,并提取异常金融组织交易流水数据中的交易账号信息和交易对手账号信息,构建异常金融组织的交易网络;所述异常金融组织交易流水数据包括交易账号、对手账号、交易金额、交易时间、摘要、交易余额、交易地点;
所述邻域拓扑结构特征提取模块用于:使用自定义的基于邻域拓扑结构的网络表示学习方法处理异常金融组织的交易网络的数据,提取交易网络账号节点的邻域拓扑结构信息,为每个账号生成对应的低维稠密向量;
所述异常金融组织层次划分模块用于:首先,使用pca方法对每个账号生成的低维稠密向量进行降维处理,然后,使用k-means算法对降维处理后的低维稠密向量进行聚类操作,获取异常金融组织层次划分结果。
上述异常金融组织层次划分系统的工作方法,运行于计算机中,包括步骤如下:
(1)所述数据预处理模块对输入的异常金融组织交易流水数据依次进行去重、去噪和去不完整数据操作,并提取异常金融组织交易流水数据中的每一条交易记录的交易账号和交易对手账号,构建异常金融组织的交易网络;
(2)所述邻域拓扑结构特征提取模块使用自定义的基于邻域拓扑结构的网络表示学习方法处理异常金融组织的交易网络的数据,提取交易网络账号节点的邻域拓扑结构信息,为每个账号生成对应的低维稠密向量;
(3)所述异常金融组织层次划分模块先使用pca方法对每个账号生成的低维稠密向量进行降维处理,然后使用k-means算法对降维处理后的低维稠密向量进行聚类操作,获取异常金融组织层次划分结果。
原始的金融交易流水数据存在数据冗余、缺失、格式不规范等缺点,首先需要进行数据清洗工作,提取有效的交易记录信息。根据本发明优选的,步骤(1)中,数据清洗,包括:
a、去不完整数据:即清洗格式不规范数据,格式不规范数据是指交易账号和交易对手账号位数与标准银行卡账号位数不一致的数据;该部分数据认定为不完整数据,对其进行清洗工作。
b、去噪:即清洗交易金额小于50元的数据;一般异常金融组织的异常交易涉及的金额较大,清洗金额较小的交易记录有利于提高层次划分的准确程度。
c、去重:即清洗冗余数据,冗余数据是指异常金融组织交易流水数据中存在的同一笔交易记录以不同方式被记录两次的情况。如account1与account2之间发生了一笔交易,该笔交易分别以“交易账号为account1,交易对手账号为account2”和“交易账号为account2、交易对手账号为account1”的两条记录,需要删去其中一条。
根据本发明优选的,步骤(1)中,提取异常金融组织交易流水数据中的交易账号信息和交易对手账号信息,构建异常金融组织的交易网络,包括:
d、统计异常金融组织交易流水数据所涉及的账号集合c={c1,c2,…,ci,…,cn},表示一共有n个账号,c表示所有账号的集合,ci表示集合中的第i个账号;
e、根据f(ci)=vi构建交易网络的点集v={v1,v2,…,vi,…vn},将每个账号ci映射为一个正整数,范围为[1,n],vi=i,i=1,2,…,n,
f、根据交易网络的点集v、账号集合c和交易流水数据,构建交易网络的边集
g、最终构建交易网络:g={v,e}。
根据本发明优选的,步骤(2)中,包括步骤如下:
在网络中,邻域结构相似的节点往往有着相似的功能,扮演着相似的角色,这反映在异常金融组织交易网络中便体现为邻域拓扑结构相似的账号节点在组织中往往处于相同的层次。本发明设计的ntf方法可以有效提取节点的邻域拓扑结构信息,从而有效完成网络层次划分任务。
给定一个图g=(v,e),v={v1,v2,…,vi,…vn},表示有n个节点的集合;
节点v相对于节点u的能级为elu(v),设定初始能量qu(u)=1,共有k*级能级,第k级能级能量范围为
最大采样深度d*表示以某节点为中心,按距离逐层向外扩展采样,所能采样得到的节点到中心节点距离的最大值;到中心节点距离超过d*的节点将不纳入采样范围;
二次图g′={v,e′,s},g′是在原始图基础上生成的无向有权的完全图,
h、通过ntf算法为每个节点生成各自的影响力子网络;后续的采样过程也将在该影响力子网络上进行。从交易网络g中取出一节点作为中心节点,ntf模型从交易网络g中筛选出对中心节点邻域结构重要程度较大的邻居节点,连同边一起构成中心节点的影响力子图即影响力子网络;是指:设中心节点为u,初始能量qu(u)=1,从点u出发,能量沿边进行传播,直到能量处于最低能级或剩余能量不足以到达下一节点为止;在能量传播过程中,能量耗散速率与节点到u的距离、节点的度、边权重等因素有关,距离u越近、节点度越大、边权重越大,该节点相对u邻域结构的重要程度也就越大,到达该节点时损失的能量越少,即该节点的重要程度也就越大。设定存在一路径p={u,v1,…,vi,vj},vj到中心节点u的距离为k,从点u出发,能量沿该路径传播,经vi到达vj时的剩余能量qu(vj)如公式(ⅰ)所示:
式(ⅰ)中,qu(vi)表示从节点u出发沿路径p到达点vi时的剩余能量,k表示vj到u的距离,wi,j代表边ei,j的权重,α是能量衰减率,l(p)表示路径p的长度,
注意,由于从u到vj的路径可能存在多条,因此存在vj同时属于
从点u出发,所能抵达的节点的集合记为v(u),边的集合记为e(u),影响力子图g(u)={v(u),e(u),n},n={elu(v)∣v∈v(u)},为所抵达节点的能级集合;
i、在影响力子网络的基础上,进行邻域拓扑结构特征的采样工作,是指:按照给定的采样深度d*,在影响力子网络中,从中心节点出发,采用广度优先搜索的策略,按距离逐层向外扩展采样,使用节点的能级和度来表示采样过程中扩展到的节点,其中节点的能级是相对特征,度是绝对特征;
定义ri(u)是到中心节点u距离为i的节点构成的集合,dei(u)表示从节点u出发,采样深度为i时所扩展到的节点的绝对特征和相对特征的有序对构成的集合,定义如公式(ⅱ)所示:
dei(u)={(d(v),elu(v))∣∣v∈ri(u)}#(ⅱ)
式(ⅱ)中,d(v)代表节点v的度,elu(v)表示节点v相对于节点u的能级。
让dei(u)中的元素进行有序排列,以节点的度为主关键字、节点能级为次关键字进行升序排列,综合节点的绝对特征和相对特征,
j、根据节点的邻域结构特征构建二次图;将在二次图上进行随机游走操作。
定义distance(u,v)表示节点u,v的邻域拓扑结构距离,该距离根据点u,v的邻域拓扑结构特征集合de(u),de(v)计算得出,计算方法如公式(ⅲ)所示:
dist(·)为计算两个序列之间距离的函数;
当且仅当节点u,v同时存在距离为k的邻居时,第k跳邻域的距离才存在,其中,wi表示第i跳邻域距离对总距离的贡献比例,计算方法如公式(ⅳ)所示:
在本模型中,采用的是dtw(dynamictimewrap)算法;在实际计算中,为了兼顾计算速度和精度,我们采用的是fastdtw算法。根据dtw算法,给出任意两元素的差值计算定义式,如公式(ⅴ)所示:
该插值综合考虑了节点的度和能级特征,a1,b1表示有序对a,b的第一个元素,即节点的度,a2,b2表示有序对的第二个元素,即节点的能级;
在此基础上,构建二次图,对于二次图中的两点u,v而言,边(u,v)的权重su,v体现了它们的邻域结构相似度su,v,计算方式如公式(ⅵ)所示:
su,v=e-distance(u,v)#(ⅵ)
注意,su,v=sv,u。最终,将两节点的邻域结构距离映射为(0,1]区间内的一个小数;
k、生成节点的向量表示,即低维稠密向量,是指:
在二次图上进行随机游走,生成节点的上下文序列,根据二次图边的权重计算出从当前节点u转移到其他节点的概率,如公式(ⅶ)所示:
z(u)是归一化因子;根据游走概率可以看出,从当前节点开始,会更倾向于转移到和当前节点结构相似的节点上去,因此节点u的上下文中包含了和u结构相似的节点;
使用skip-gram算法,为每个节点学习一个向量表示。邻域拓扑结构相近的节点的向量表示在向量空间中更为接近。
根据本发明优选的,使用skip-gram算法,为每个节点学习一个向量表示。包括步骤如下:
①为每个节点生成one-hot向量,对于
②设生成的稠密向量维度为d,随机初始化矩阵u,
③设vi表示中心节点,vi∈v,context(vi)表示vi的背景节点的集合,∣context(vi)∣=wsize,wsize表示窗口长度,skip-gram的目标函数f(skip-gram)如公式(ⅷ)所示:
若有vj∈context(vi),那么有vi∈context(vj),即vi,vj互为背景节点和中心节点,背景节点为节点的上下文序列中距离中心节点不超过wsize的节点;
④使用反向传播算法更新矩阵u,w使f(skip-gram)最大化,对于
l、构建矩阵x,
m、计算x的协方差矩阵cov,
n、计算x的特征值和特征向量:(λa-cov)x=0,λ为cov的特征值,a为单位矩阵,x为cov的特征向量;
o、设降维后维度为d′,按特征值大小将特征向量从上到下排列,取前d′行得到矩阵p,
p、设降维后的数据为y,y=px,
根据本发明优选的,步骤(3)中,使用k-means算法对降维处理后的低维稠密向量进行聚类操作,获取异常金融组织层次划分结果。vi对应的降维后的节点向量为yi,yi=yit,k-means算法的输入样本集为:s={yi∣i∈[1,n]},设置的分类类别数为classnum,迭代次数为iternum,包括步骤如下:
q、从s中随机选择classnum个节点向量作为每个类别初始的质心向量,分别是:{μ1,μ2,…,μclassnum},对应类别为{class1,class2,…,classc};
r、
s、更新每个类别的质心向量,更新公式如公式(ⅹ)所示:
t、依次执行步骤r和步骤s,执行iternum次后终止执行,输出分类结果。
本发明的有益效果为:
本发明能够利用异常金融组织的交易流水记录,构建该组织的交易网络,通过自定义的ntf算法提取网络中账号节点的邻域拓扑结构特征,并基于此为每个账号节点生成低维稠密向量。然后使用pca算法对向量进行降维处理,并使用k-means算法处理降维后的节点向量,最终得到账号节点的层次信息。本发明提出的基于邻域拓扑结构的异常金融组织层次划分算法所需信息少,只需要异常金融组织的交易记录的转账双方信息,不需要其余的额外信息项参与,在一定程度上减少了人工参与,降低了人力成本,能够取得很好的层次划分结果,实现了异常金融组织层次划分的自动化处理。本方法可以辅助相关工作人员对异常金融组织进行分析研判,提高相关人员工作效率。
附图说明
图1为本发明基于邻域拓扑结构的异常金融组织层次划分系统的结构框图;
图2为本发明影响力子网络的采样示意图;
图3为本发明异常金融组织层次划分系统的工作方法的流程示意图;
图4(a)为实施例2提出的ntf方法得到的聚类可视化结果示意图;
图4(b)为现有的boostne方法得到的聚类可视化结果示意图;
图4(c)为现有的role2vec方法得到的聚类可视化结果示意图;
图4(d)为现有的struc2vec方法得到的聚类可视化结果示意图。
具体实施方式
下面结合说明书附图和实施例对本发明作进一步限定,但不限于此。
实施例1
一种基于邻域拓扑结构的异常金融组织层次划分系统,如图1所示,包括依次连接的数据预处理模块、邻域拓扑结构特征提取模块和异常金融组织层次划分模块;
数据预处理模块用于:对输入的异常金融组织交易流水数据依次进行去重、去噪和去不完整数据操作,并提取异常金融组织交易流水数据中的交易账号信息和交易对手账号信息,构建异常金融组织的交易网络;所述异常金融组织交易流水数据包括交易账号、对手账号、交易金额、交易时间、摘要、交易余额、交易地点;
邻域拓扑结构特征提取模块用于:使用自定义的基于邻域拓扑结构的网络表示学习方法处理异常金融组织的交易网络的数据,提取交易
网络账号节点的邻域拓扑结构信息,为每个账号生成对应的低维稠密向量;
异常金融组织层次划分模块用于:首先,使用pca方法对每个账号生成的低维稠密向量进行降维处理,然后,使用k-means算法对降维处理后的低维稠密向量进行聚类操作,获取异常金融组织层次划分结果。
实施例2
实施例1所述的异常金融组织层次划分系统的工作方法,运行于计算机中,如图3所示,包括步骤如下:
(1)数据预处理模块对输入的异常金融组织交易流水数据依次进行去重、去噪和去不完整数据操作,并提取异常金融组织交易流水数据中的每一条交易记录的交易账号和交易对手账号,构建异常金融组织的交易网络;
原始的金融交易流水数据存在数据冗余、缺失、格式不规范等缺点,首先需要进行数据清洗工作,提取有效的交易记录信息。数据清洗,包括:
a、去不完整数据:即清洗格式不规范数据,格式不规范数据是指交易账号和交易对手账号位数与标准银行卡账号位数不一致的数据;该部分数据认定为不完整数据,对其进行清洗工作。
b、去噪:即清洗交易金额小于50元的数据;一般异常金融组织的异常交易涉及的金额较大,清洗金额较小的交易记录有利于提高层次划分的准确程度。
c、去重:即清洗冗余数据,冗余数据是指异常金融组织交易流水数据中存在的同一笔交易记录以不同方式被记录两次的情况。如account1与account2之间发生了一笔交易,该笔交易分别以“交易账号为account1,交易对手账号为account2”和“交易账号为account2、交易对手账号为account1”的两条记录,需要删去其中一条。
提取异常金融组织交易流水数据中的交易账号信息和交易对手账号信息,构建异常金融组织的交易网络,包括:
d、统计异常金融组织交易流水数据所涉及的账号集合c={c1,c2,…,ci,…,cn},表示一共有n个账号,c表示所有账号的集合,ci表示集合中的第i个账号;
e、根据f(ci)=vi构建交易网络的点集v={v1,v2,…,vi,…vn},将每个账号ci映射为一个正整数,范围为[1,n],vi=i,i=1,2,…,n,
f、根据交易网络的点集v、账号集合c和交易流水数据,构建交易网络的边集
g、最终构建交易网络:g={v,e}。
(2)邻域拓扑结构特征提取模块使用自定义的基于邻域拓扑结构的网络表示学习方法处理异常金融组织的交易网络的数据,提取交易网络账号节点的邻域拓扑结构信息,为每个账号生成对应的低维稠密向量;包括步骤如下:
在网络中,邻域结构相似的节点往往有着相似的功能,扮演着相似的角色,这反映在异常金融组织交易网络中便体现为邻域拓扑结构相似的账号节点在组织中往往处于相同的层次。本发明设计的ntf方法可以有效提取节点的邻域拓扑结构信息,从而有效完成网络层次划分任务。
给定一个图g=(v,e),v={v1,v2,…,vi,…vn},表示有n个节点的集合;
节点v相对于节点u的能级为elu(v),设定初始能量qu(u)=1,共有k*级能级,第k级能级能量范围为
最大采样深度d*表示以某节点为中心,按距离逐层向外扩展采样,所能采样得到的节点到中心节点距离的最大值;到中心节点距离超过d*的节点将不纳入采样范围;
二次图g′={v,e′,s},g′是在原始图基础上生成的无向有权的完全图,
h、通过ntf算法为每个节点生成各自的影响力子网络;后续的采样过程也将在该影响力子网络上进行。如图2所示,从交易网络g中取出一节点作为中心节点,ntf模型从交易网络g中筛选出对中心节点邻域结构重要程度较大的邻居节点,连同边一起构成中心节点的影响力子图即影响力子网络;是指:设中心节点为u,初始能量qu(u)=1,从点u出发,能量沿边进行传播,直到能量处于最低能级或剩余能量不足以到达下一节点为止;在能量传播过程中,能量耗散速率与节点到u的距离、节点的度、边权重等因素有关,距离u越近、节点度越大、边权重越大,该节点相对u邻域结构的重要程度也就越大,到达该节点时损失的能量越少,即该节点的重要程度也就越大。设定存在一路径p={u,v1,…,vi,vj},vj到中心节点u的距离为k,从点u出发,能量沿该路径传播,经vi到达vj时的剩余能量qu(vj)如公式(ⅰ)所示:
式(ⅰ)中,qu(vi)表示从节点u出发沿路径p到达点vi时的剩余能量,k表示vj到u的距离,wi,j代表边ei,j的权重,α是能量衰减率,l(p)表示路径p的长度,
注意,由于从u到vj的路径可能存在多条,因此存在vj同时属于
从点u出发,所能抵达的节点的集合记为v(u),边的集合记为e(u),影响力子图g(u)={v(u),e(u),n},n={elu(v)∣v∈v(u)},为所抵达节点的能级集合;
i、在影响力子网络的基础上,进行邻域拓扑结构特征的采样工作,是指:按照给定的采样深度d*,在影响力子网络中,从中心节点出发,采用广度优先搜索的策略,按距离逐层向外扩展采样,使用节点的能级和度来表示采样过程中扩展到的节点,其中节点的能级是相对特征,度是绝对特征;
定义ri(u)是到中心节点u距离为i的节点构成的集合,dei(u)表示从节点u出发,采样深度为i时所扩展到的节点的绝对特征和相对特征的有序对构成的集合,定义如公式(ⅱ)所示:
dei(u)={(d(v),elu(v))∣∣v∈ri(u)}#(ⅱ)
式(ⅱ)中,d(v)代表节点v的度,elu(v)表示节点v相对于节点u的能级。
让dei(u)中的元素进行有序排列,以节点的度为主关键字、节点能级为次关键字进行升序排列,综合节点的绝对特征和相对特征,
j、根据节点的邻域结构特征构建二次图;将在二次图上进行随机游走操作。
定义distance(u,v)表示节点u,v的邻域拓扑结构距离,该距离根据点u,v的邻域拓扑结构特征集合de(u),de(v)计算得出,计算方法如公式(ⅲ)所示:
dist(·)为计算两个序列之间距离的函数;
当且仅当节点u,v同时存在距离为k的邻居时,第k跳邻域的距离才存在,其中,wi表示第i跳邻域距离对总距离的贡献比例,计算方法如公式(ⅳ)所示:
在本模型中,采用的是dtw(dynamictimewrap)算法;在实际计算中,为了兼顾计算速度和精度,我们采用的是fastdtw算法。根据dtw算法,给出任意两元素的差值计算定义式,如公式(ⅴ)所示:
该插值综合考虑了节点的度和能级特征,a1,b1表示有序对a,b的第一个元素,即节点的度,a2,b2表示有序对的第二个元素,即节点的能级;
在此基础上,构建二次图,对于二次图中的两点u,v而言,边(u,v)的权重su,v体现了它们的邻域结构相似度su,v,计算方式如公式(ⅵ)所示:
su,v=e-distance(u,v)#(ⅵ)
注意,su,v=sv,u。最终,将两节点的邻域结构距离映射为(0,1]区间内的一个小数;
k、生成节点的向量表示,即低维稠密向量,是指:
在二次图上进行随机游走,生成节点的上下文序列,根据二次图边的权重计算出从当前节点u转移到其他节点的概率,如公式(ⅶ)所示:
z(u)是归一化因子;根据游走概率可以看出,从当前节点开始,会更倾向于转移到和当前节点结构相似的节点上去,因此节点u的上下文中包含了和u结构相似的节点;
使用skip-gram算法,为每个节点学习一个向量表示。邻域拓扑结构相近的节点的向量表示在向量空间中更为接近。
根据本发明优选的,使用skip-gram算法,为每个节点学习一个向量表示。包括步骤如下:
①为每个节点生成one-hot向量,对于
②设生成的稠密向量维度为d,随机初始化矩阵u,
③设vi表示中心节点,vi∈v,context(vi)表示vi的背景节点的集合,∣context(vi)∣=wsize,wsize表示窗口长度,skip-gram的目标函数f(skip-gram)如公式(ⅷ)所示:
若有vj∈context(vi),那么有vi∈context(vj),即vi,vj互为背景节点和中心节点,背景节点为节点的上下文序列中距离中心节点不超过wsize的节点;
④使用反向传播算法更新矩阵u,w使f(skip-gram)最大化,对于
(3)异常金融组织层次划分模块先使用pca方法对每个账号生成的低维稠密向量进行降维处理,然后使用k-means算法对降维处理后的低维稠密向量进行聚类操作,获取异常金融组织层次划分结果。
使用pca方法对每个账号生成的低维稠密向量进行降维处理,vi的低维稠密向量为veci。包括步骤如下:
l、构建矩阵x,
m、计算x的协方差矩阵cov,
n、计算x的特征值和特征向量:(λa-cov)x=0,λ为cov的特征值,a为单位矩阵,x为cov的特征向量;
o、设降维后维度为d′,按特征值大小将特征向量从上到下排列,取前d′行得到矩阵p,
p、设降维后的数据为y,y=px,
使用k-means算法对降维处理后的低维稠密向量进行聚类操作,获取异常金融组织层次划分结果。vi对应的降维后的节点向量为yi,yi=yit,k-means算法的输入样本集为:s={yi∣i∈[1,n]},设置的分类类别数为classnum,迭代次数为iternum,包括步骤如下:
q、从s中随机选择classnum个节点向量作为每个类别初始的质心向量,分别是:{μ1,μ2,…,μclassnum},对应类别为{class1,class2,…,classc};
r、
s、更新每个类别的质心向量,更新公式如公式(ⅹ)所示:
t、依次执行步骤r和步骤s,执行iternum次后终止执行,输出分类结果。
采用本实施例的方法对某用户输入某异常金融组织交易流水数据集t进行处理。
本示例采用的交易流水数据集中共有账户节点105个,共分为3类。其中,高层账户22个,特定功能账户11个,底层账户72个,共有转账记录784条。
本示例使用chi(calinskiharabazindex)、sc(silhouettecoefficient)、dbi(daviesbouldinindex)、ari(adjustedrandindex)、ami(adjustedmutualindex)和v-measure六个指标来评估本实施方法效果。前三个指标chi、sc、dbi为内部度量(internalcriteria),用来评估聚类之后得到的类簇之间的效果;后三个指标ari、ami、v-measure为外部标准(externalcriteria),用来比较聚类结果和真实分布的匹配程度。
图4(a)为本实施例提出的ntf方法得到的聚类可视化结果示意图;图4(b)为现有的boostne方法得到的聚类可视化结果示意图;现有的boostne方法参见文献lij,wul,guor,etal.multi-levelnetworkembeddingwithboostedlow-rankmatrixapproximation[c]//proceedingsofthe2019ieee/acminternationalconferenceonadvancesinsocialnetworksanalysisandmining.2019:49-56.图4(c)为现有的role2vec方法得到的聚类可视化结果示意图;现有的role2vec方法参见ahmednk,rossir,leejb,etal.learningrole-basedgraphembeddings[j].arxivpreprintarxiv:1802.02896,2018.。图4(d)为现有的struc2vec方法得到的聚类可视化结果示意图;现有的struc2vec方法参见ribeirolfr,saveresephp,figueiredodr.struc2vec:learningnoderepresentationsfromstructuralidentity[c]//proceedingsofthe23rdacmsigkddinternationalconferenceonknowledgediscoveryanddatamining.2017:385-394.。
图4(a)至图4(d)中,横、纵坐标表示算法(ntf、boostne、role2vec和struc2vec)为每个节点生成的稠密向量降维到二维向量时,在二维平面对应的坐标值。由于在使用相关指标(chi、sc、dbi、ari、ami和v-measure)对聚类结果进行评估时需对向量进行归一化处理,因此,节点的横纵坐标绝对值的大小并不影响聚类结果。
从图4(a)至图4(d)可以看出,boostne和role2vec两种方法不能很好的区分三类节点。struc2vec可以较好地区分从类别1和类别2中区分出类别3,但无法较好的区分类别1和类别2。本发明提出的ntf方法则能很好的区分三类节点,取得了更好地聚类效果。
用chi、sc和dbi三个指标来衡量ntf和三个对比方法boostne、role2vec以及struc2vec的聚类效果,结果如表1所示。
表1
使用k-means算法对四种方法生成的降维后的节点向量进行聚类操作,然后使用ari、ami、v-measure来衡量k-means算法的聚类效果,结果如表2所示。
表2
从表1和表2可以看出,与现有的boostne、role2vec、struc2vec三种方法相比,本发明提出的ntf方法在6种指标上均取得了最好的结果,这反映出ntf方法可以有效提取节点的邻域拓扑结构信息,在将同类节点聚集到一起的同时,将不同类别的节点尽可能区分开,以取得更好的聚类结果。同时,ntf方法能够更好地支持后续的节点分类任务。
- 还没有人留言评论。精彩留言会获得点赞!