一种基于自然语言的企业新闻动态监测方法与流程
本发明属于在自然语言处理领域,涉及一种基于自然语言的企业新闻动态监测方法。
背景技术:
随着互联网的普及,以及各类互联网产品的推出,世界走入了信息爆炸时代,网上新闻成为了人们获取信息的重要渠道。互联网上每天都有大量的新闻产生,对于园区管理、招商、运营等需要快速把握企业动态的领域来说,如何从海量的新闻数据中提取到关注的企业动态信息一直是工作中的痛点和难点。
一般的企业新闻动态监测方法大多直接采用企业关键字匹配的办法,直接通过搜索引擎等渠道搜索企业名称,查找相关新闻。该方法门槛较低,在处理的企业新闻动态较少时能取得较好的效果,但在园区招商、管理等对信息处理数据量大、精准度要求较高的环境中,直接搜索不能快速实现对企业动态信息维度的分类,同时企业名称关键字识别不准确,可能会识别出非企业实体的新闻,在数据量较大的情况下掺杂无效信息,降低了信息获取效率和准确性。
技术实现要素:
有鉴于此,本发明的目的在于提供一种基于自然语言的企业新闻动态监测方法。
为达到上述目的,本发明提供如下技术方案:
一种基于自然语言的企业新闻动态监测方法,该方法包括以下步骤:
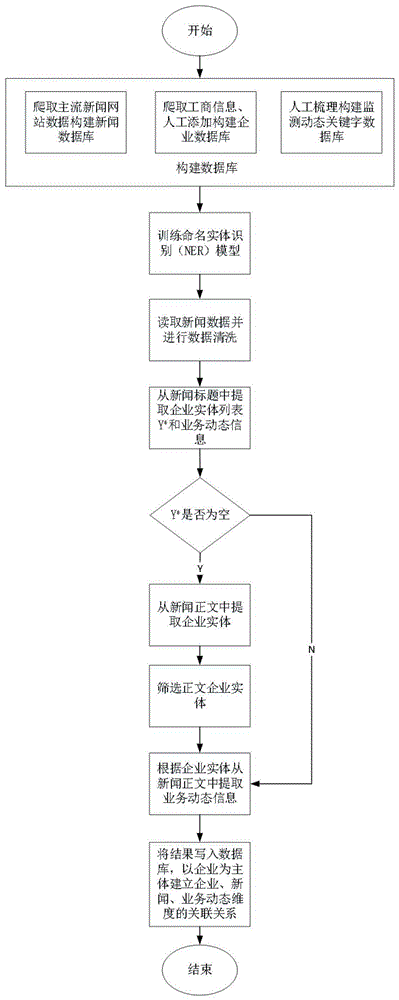
步骤1:构建数据库;爬取主流新闻网站实时数据构建新闻数据库,通过工商信息爬取和人工添加等方法构建企业数据库,通过人工梳理的方法构建业务动态关键字数据库;
步骤2:训练命名实体识别ner模型;采用成熟的线性链条件随机场(conditionalrandomfield,crf)方法和中文语料库训练命名实体识别(namedentityrecognition,ner)模型;
对新闻数据库中每一条新闻,进行步骤3-8操作:
步骤3:读取新闻数据并进行数据清洗;按照预定方法从新闻数据库中读取新闻标题、新闻源文本、新闻发布时间等维度数据,并对新闻数据清洗,去除无效字符;
步骤4:从新闻标题中提取企业实体和业务动态信息;利用命名实体识别和企业名称匹配的方法从新闻标题文本中提取企业实体,利用文本匹配的方法提取业务动态信息,若标题中可提取到实体,则跳过步骤5,否则转到步骤5;
步骤5:从新闻正文中提取企业实体;利用命名实体识别的方法从新闻正文文本中提取企业实体;
步骤6:筛选正文企业实体;根据新闻正文中出现企业实体次数的数量、排名等信息,筛除关联性不大的企业实体,保留主要企业实体作为该新闻识别结果;
步骤7:根据筛选后的企业实体从新闻正文中提取相应的业务动态信息;查找正文中出现的业务动态关键字,计算各业务动态关键字与企业实体的空间距离,按照距离大小提取业务动态信息;
步骤8:将结果写入数据库;将步骤6中获得的主要企业实体、新闻数据、步骤4和步骤7中获得的涉及业务动态维度,按照预定关联方法写入数据库进行保存,以企业为主体建立企业、新闻、业务动态维度的关联关系。
可选的,所述步骤1中,构建数据库步骤中的企业数据库信息,包括企业基本信息、投融资信息、经营信息、司法欠税信息和产品技术信息的数据维度;动态关键字数据库包括多级关键字。
可选的,所述步骤4中,若标题中提取到企业实体,则有理由认为新闻明确与该企业实体相关联,可省略从新闻正文中再查找筛选企业实体的步骤;
可选的,所述步骤4-6中,判断新闻数据是否与企业相关时,一方面通过实体识别和名称匹配的方法识别出新闻中出现的企业,另一方面通过各企业实体出现的次数、排名、位置等信息构建筛选模型,去除关联性不强的企业,保留新闻涉及的主要企业实体;
具体分为以下步骤:
s01:判断新闻标题中是否出现企业实体;由于大量新闻标题中的企业以企业简称的形式出现,且标题存在语言结构不严谨、实体识别效果不好的现象,因此新闻标题采用文本匹配和实体识别相结合的方法进行判断;对前述企业数据库中的企业名称,包括全称和简称,按文本匹配的方法在新闻标题中查找是否出现企业名称,同时利用ner模型提取标题实体后查结合企业数据库判断该实体是否属于企业,二者结合得到新闻标题中出现的企业实体列表y*;若y*不为空集,则完成企业识别,否则转到s02;
s02:判断新闻正文中是否出现企业实体;利用前述ner模型对新闻正文文本进行实体识别,识别结果进行去重后得到实体名称列表y=(y1,y2,y3...ym),对y中每一个实体yi,在前述企业数据库中查询是否存在该实体,若存在,则表明该实体属于企业;若不存在,则丢弃该实体,得到新闻正文中出现的企业实体列表y'=(y1,y2,y3...yn);
s03:筛选企业实体;根据新闻正文中出现企业实体列表y'中各实体次数的数量、排名等信息,筛除关联性不大的企业实体,具体的筛选逻辑及维度可根据模型实际运行效果进行调整,保留主要企业实体作为该新闻识别结果;
可选的,所述步骤4、步骤7中,判断新闻数据是否与业务动态维度相关时,一方面通过业务关键字匹配的方法识别到业务动态信息,另一方面,通过业务关键字与主要企业实体的空间距离对业务动态维度进行筛选,保留与企业关联性较强的业务动态维度,其中关键字与企业实体的空间距离计算方法和阈值可根据模型实际运行效果进行调整。
本发明的有益效果在于:本发明给出了一种企业新闻动态监测方法,可快速、大量、自动化的从网络获取新闻信息;对新闻信息进行实体识别和业务动态关键字匹配处理后,建立新闻、企业、动态维度三者的关联关系,实现企业的高效新闻动态监测和分类;新闻关联企业识别采用成熟的实体识别算法与企业名称匹配相结合的方法,大幅度降低了无关信息对识别结果的干扰,具有较高的稳定性和准确率。
本发明的其他优点、目标和特征在某种程度上将在随后的说明书中进行阐述,并且在某种程度上,基于对下文的考察研究对本领域技术人员而言将是显而易见的,或者可以从本发明的实践中得到教导。本发明的目标和其他优点可以通过下面的说明书来实现和获得。
附图说明
为了使本发明的目的、技术方案和优点更加清楚,下面将结合附图对本发明作优选的详细描述,其中:
图1为本发明实施例中的流程示意图。
图2为本发明实施例中步骤s01至s03的流程示意图。
具体实施方式
以下通过特定的具体实例说明本发明的实施方式,本领域技术人员可由本说明书所揭露的内容轻易地了解本发明的其他优点与功效。本发明还可以通过另外不同的具体实施方式加以实施或应用,本说明书中的各项细节也可以基于不同观点与应用,在没有背离本发明的精神下进行各种修饰或改变。需要说明的是,以下实施例中所提供的图示仅以示意方式说明本发明的基本构想,在不冲突的情况下,以下实施例及实施例中的特征可以相互组合。
其中,附图仅用于示例性说明,表示的仅是示意图,而非实物图,不能理解为对本发明的限制;为了更好地说明本发明的实施例,附图某些部件会有省略、放大或缩小,并不代表实际产品的尺寸;对本领域技术人员来说,附图中某些公知结构及其说明可能省略是可以理解的。
本发明实施例的附图中相同或相似的标号对应相同或相似的部件;在本发明的描述中,需要理解的是,若有术语“上”、“下”、“左”、“右”、“前”、“后”等指示的方位或位置关系为基于附图所示的方位或位置关系,仅是为了便于描述本发明和简化描述,而不是指示或暗示所指的装置或元件必须具有特定的方位、以特定的方位构造和操作,因此附图中描述位置关系的用语仅用于示例性说明,不能理解为对本发明的限制,对于本领域的普通技术人员而言,可以根据具体情况理解上述术语的具体含义。
本发明提供了一种基于自然语言处理的企业新闻动态监测方法,首先通过网络爬取或者人工添加的方法构建新闻数据库、业务动态关键字数据库、企业数据库,然后利用线性条件随机场(crf)方法训练得到命名实体识别(ner)模型,利用ner模型和名称匹配的方法在新闻数据中识别筛选出企业实体,再对新闻数据进行动态关键字匹配,最后将新闻数据、动态关键字、企业实体名称写入数据库,以企业为主体建立企业、新闻、业务动态维度的关联关系。如附图1所示,具体步骤如下:
1.构建数据库。爬取主流新闻网站,如新浪、搜狐、腾讯等网站的公开新闻数据构建新闻数据库;爬取公开的企业信息和人工添加企业等方法构建企业数据库;通过人工梳理监测动态的关键字,如“上市”、“减产”、“签约”等字段,构建监测动态关键字数据库;
2.训练命名实体识别ner模型;采用成熟的线性链条件随机场(conditionalrandomfield,crf)方法和中文语料库训练命名实体识别(namedentityrecognition,ner)模型;
对新闻数据库中每一条新闻,进行步骤3-8操作:
3.读取新闻数据并进行数据清洗;按照预定方法从新闻数据库中读取新闻标题、新闻源文本、新闻发布时间等维度数据,并对新闻数据清洗,去除无效字符;
4.从新闻标题中提取企业实体和业务动态信息;利用命名实体识别和企业名称匹配的方法从新闻标题文本中提取企业实体,利用文本匹配的方法提取业务动态信息,若标题中可提取到实体,则跳过步骤5,否则转到步骤5;
5.从新闻正文中提取企业实体;利用命名实体识别的方法从新闻正文文本中提取企业实体;
6.筛选正文企业实体;根据新闻正文中出现企业实体次数的数量、排名等信息,筛除关联性不大的企业实体,保留主要企业实体作为该新闻识别结果;
7.根据筛选后的企业实体从新闻正文中提取相应的业务动态信息;查找正文中出现的业务动态关键字,计算各业务动态关键字与企业实体的空间距离,按照距离大小提取业务动态信息;
8.将结果写入数据库;将步骤6中获得的主要企业实体、新闻数据、步骤4和步骤7中获得的涉及业务动态维度,按照预定关联方法写入数据库进行保存,以企业为主体建立企业、新闻、业务动态维度的关联关系;
进一步地,构建数据库步骤中的企业数据库信息,包括但不限于企业基本信息、投融资信息、经营信息、司法欠税信息、产品技术信息等数据维度。动态关键字数据库可包括多级关键字,举例如一级关键字为“业务动态”,二级关键字为“业务合作”、“产能动态”、“调研访谈”等,三级关键字为“拜访”、“交流”、“考察”、“调研”等。
进一步的,所述步骤4中,若标题中提取到企业实体,则有理由认为新闻明确与该企业实体相关联,可省略从新闻正文中再查找筛选企业实体的步骤;
进一步的,所述步骤4-6中,判断新闻数据是否与企业相关时,一方面通过实体识别和名称匹配的方法识别出新闻中出现的企业,另一方面通过各企业实体出现的次数、排名、位置等信息构建筛选模型,去除关联性不强的企业,保留新闻涉及的主要企业实体;
具体分为以下步骤:
s01:判断新闻标题中是否出现企业实体;由于大量新闻标题中的企业以企业简称的形式出现,且标题存在语言结构不严谨、实体识别效果不好的现象,因此新闻标题采用文本匹配和实体识别相结合的方法进行判断;对前述企业数据库中的企业名称,包括全称和简称,按文本匹配的方法在新闻标题中查找是否出现企业名称,同时利用ner模型提取标题实体后查结合企业数据库判断该实体是否属于企业,二者结合得到新闻标题中出现的企业实体列表y*;若y*不为空集,则完成企业识别,否则转到s02;
s02:判断新闻正文中是否出现企业实体;利用前述ner模型对新闻正文文本进行实体识别,识别结果进行去重后得到实体名称列表y=(y1,y2,y3...ym),对y中每一个实体yi,在前述企业数据库中查询是否存在该实体,若存在,则表明该实体属于企业;若不存在,则丢弃该实体,得到新闻正文中出现的企业实体列表y'=(y1,y2,y3...yn);
s03:筛选企业实体;根据新闻正文中出现企业实体列表y'中各实体次数的数量、排名等信息,筛除关联性不大的企业实体,具体的筛选逻辑及维度可根据模型实际运行效果进行调整,保留主要企业实体作为该新闻识别结果;
进一步的,所述步骤4、步骤7中,判断新闻数据是否与业务动态维度相关时,一方面通过业务关键字匹配的方法识别到业务动态信息,另一方面,通过业务关键字与主要企业实体的空间距离对业务动态维度进行筛选,保留与企业关联性较强的业务动态维度,其中关键字与企业实体的空间距离计算方法和阈值可根据模型实际运行效果进行调整;
最后说明的是,以上实施例仅用以说明本发明的技术方案而非限制,尽管参照较佳实施例对本发明进行了详细说明,本领域的普通技术人员应当理解,可以对本发明的技术方案进行修改或者等同替换,而不脱离本技术方案的宗旨和范围,其均应涵盖在本发明的权利要求范围当中。
- 还没有人留言评论。精彩留言会获得点赞!