基于自动构建目标实体集的政策文件信息匹配和推送方法与流程
[0001]
本发明属于自然语言处理技术领域,更具体地讲,涉及一种基于自动构建目标实体集的政策文件信息匹配和推送方法。
背景技术:
[0002]
政策文件是指国家党政机关等部门或组织,以正式标准化的格式和文字,对需要完成的特定事件形成的文字材料,是一种国家行政机关公文。《国家行政机关公文处理办法》规定:公文一般由发文机关、秘密等级、紧急程度、发文字号、签发人、标题、主送机关、正文、附件、发布层次、印章、成文时间、附注、主题词、抄送机关、印发机关和时间等组成,《党政机关公文格式》则规定了公文的具体排版要求和格式要求等国家标准,适用于各级机关制发的公文。即政策文件所有的内容,都有统一的标准格式。
[0003]
此前,国家公文主要以纸质文件的形式逐级下发,这种方式不仅成本高,同时公文的时效性也得不到保证。于是我国在2016年正式发布了党政电子公文系列国家标准,大力推进电子公文网上传输工作,并于2017年正式实施。
[0004]
目前,电子公文传输系统应用十分广泛。电子公文传输系统就是利用计算机网络和安全技术,实现部门与部门之间、单位与单位之间政策性文件的起草、制作、分发、接收等功能,以现代的电子公文传输模式取代传统的纸质公文传输模式。电子公文传输系统在应用于电子公文传输的功能之外,同时也可应用于信息的起草、分发、接收等工作,一个系统兼顾多个功能,降低了开发成本,同时使工作效率大幅提高。
[0005]
电子公文传输系统在分发电子公文时,现有的方法是根据文件发布层次、主送和抄送单位,在系统中进行人工手动勾选文件需要发至的单位和部门,并点击发送。一般普发性政策文件都有根据发布层次制作好的分发模板,点击相应的模板再点击发送即可。然而,当某些特殊的政策文件没有特定的发布层次时,则需要根据文件的主送和抄送,手动勾选发送范围内的单位,工作效率低下。尤其是在编写、分发信息时,还需要阅读信息的内容,确定与该信息内容相关的部门都在分发范围之内,没有遗漏。在分发结束之后,还要给重点推送单位去电或短信通知,确保重要的文件或信息不被遗漏,及时办理。上述文件推送的工作方式仍然主要依赖于人力,工作效率低,且容易出现错误。
技术实现要素:
[0006]
针对现有技术中存在的不足,本发明的目的之一在于解决上述现有技术中存在的一个或多个问题。例如,本发明的目的之一在于提供一种能够提高政策文件推送效率的推送方法。
[0007]
本发明提供了一种基于自动构建目标实体集的政策文件信息匹配和推送方法,可以包括以下步骤:扫描待推送政策文件,获取待推送政策文件主送抄送实体集以及发布层次;提取待推送政策文件中的主题和关键信息,基于主题和关键信息生成与其领域相关的应推送实体集;比较应推送实体集与获取的主送抄送实体集之间是否存在相同实体,若存
在相同实体,则对相同实体进行重点标记,并将应推送实体集中含有而主送抄送实体集中不含有的实体加入主送抄送实体集组合为初推送实体集;确定初推送实体集中的所有实体是否均符合发布层次,若全部符合,初推送实体集则为待推送实体集,若存在不符合实体,则将不符合实体删除得到待推送实体集;将待推送实体集与推送系统中已存储的推送实体进行匹配,向匹配成功的推送实体直接推送政策文件,将待推送实体集含有而推送系统中不含有的推送实体加入推送系统中并进行人工审核以确定是否向其推送政策文件。
[0008]
本发明通过自然语言处理技术,自动提取待推送政策文件的主送、抄送实体以及发布层次,基于电子公文传输系统自动对文件进行转发推送,同时,提取待推送政策文件中的主题和关键内容信息,根据提取主题和关键内容信息,判断相关领域的重点部门,生成文件内容信息概述,对重点部门以短信的方式自动进行重点推送。
[0009]
与现有技术相比,本发明的有益效果至少包含以下中的至少一项:(1)本发明的推送方法取代了人工手动勾选需发送的主送、抄送单位和部门,能够实现政策文件的自动推送,工作效率得到显著提高;(2)本发明的推送方法不需要对政策文件内容进行人为阅读,能够基于自然语言处理技术自动识别关键信息,利用关键信息能够生成与内容相关的部门和概述,能够确保推送单位不被遗漏,并能够将生成的概述自动转发给重点推送单元联系人,取代了人为通知。
附图说明
[0010]
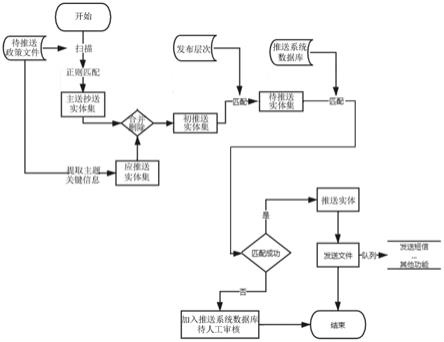
通过下面结合附图进行的描述,本发明的上述和其他目的和特点将会变得更加清楚,其中:图1示出了本发明一个示例性实施例的基于自动构建目标实体集的政策文件信息匹配和推送方法流程示意简图。
具体实施方式
[0011]
在下文中,将结合附图和示例性实施例详细地描述根据本发明的一种基于自动构建目标实体集的政策文件信息匹配和推送方法。
[0012]
本发明提供了一种基于自动构建目标实体集的政策文件信息匹配和推送方法。在本发明一种基于自动构建目标实体集的政策文件信息匹配和推送方法的一个示例性实施例中,推送方法可以包括:s01,扫描待推送政策文件,获取待推送政策文件主送抄送实体集以及发布层次。
[0013]
s02,提取待推送政策文件中的主题和关键信息,基于主题和关键信息生成与其领域相关的应推送实体集。
[0014]
s03,比较应推送实体集与获取的主送抄送实体集之间是否存在相同实体,若存在相同实体,则对相同实体进行重点标记,并将应推送实体集中含有而主送抄送实体集中不含有的实体加入主送抄送实体集组合为初推送实体集。
[0015]
s04,确定初推送实体集中的所有实体是否均符合发布层次,若全部符合,初推送实体集则为待推送实体集,若存在不符合实体,则将不符合实体删除得到待推送实体集。
[0016]
s05,将待推送实体集与推送系统中已存储的推送实体进行匹配,向匹配成功的推送实体直接推送政策文件,将待推送实体集含有而推送系统中不含有的推送实体加入推送
系统中并进行人工审核以确定是否向其推送政策文件。
[0017]
进一步地,对于s01,扫描待推送政策文件,获取待推送政策文件主送抄送实体集以及发布层次可以包括:采用正则表达式扫描待推送政策文件以获取待推送政策文件主送抄送实体集以及发布层次。由于政策文件具有标准化的格式,因此,正则表达式可以通过归纳总结政策文件特点得到。具体地,基于政策文件格式,可以根据主送实体、抄送实体以及发布层次的位置规则、前后标点符号规则和/或前后特殊符号规则建立正则表达式。例如,主送实体在文件整体的前侧,位置位于标题的后方,且与标题之间以2-3个“回车换行符”为间隔,以“逗号”或“顿号”分隔需要主送的实体名称,并以“冒号”结束。抄送主体以“抄送”两个汉字和“冒号”开始,以“逗号”“顿号”“分号”或“回车”分隔需要抄送的实体名称,一般以“句号”结束,且在抄送主体的前后,一般有一定数量的“横线符号”作为文件版记的标志。文件发布层次在正文与版记之间,通常以“左括号”开始,“右括号”结束,并有特定表达方式,例如发至地州市师级、发至县团级等。这里,需要说明的是,主送抄送实体集是由政策文件中出现的多个主送实体和抄送实体组成。主送实体可以是指政策文件需要主送的单位或部门。抄送实体可以是指政策文件需要抄送的单位或部门。实体集可以是各种实体的集合,实体可以是指各单位和各部门。
[0018]
进一步地,对于s02,可以根据nlp模型对待推送政策文件中提到的主体和关键信息进行提取。nlp模型可以包括ulmfit、transformer或bert等模型。当然,本发明使用的模型不限于此。根据提取的主题和关键信息,可以生成与待推送政策文件领域相关的应推送实体集。例如,待推送政策文件中含有“金融”,可以生成与“金融”相关的实体包括“金融监管局”、“财政局”、“税务局”及银行等相关单位。“金融监管局”、“财政局”、“税务局”及银行等相关单位就组成应推送实体集。再例如,待推送政策文件中含有“建筑”、“土地”等关键字,判定文件与土建行业有关,则生成与其相关的应推送实体集包括“发改委”、“国土局”、“规划局”、“建设局”、“环保局”、“行政执法局”、“水利局”以及“交通局”等。
[0019]
进一步地,对于s03,在添加新的推送实体时,会在现有主送抄送实体集中进行检查,确定是否已经包含该实体,若包含则不作任何操作,若不包含,则将该实体加入主送抄送实体集中组合得到初推送实体集。
[0020]
进一步地,对于s04,根据获取的发布层次检查初推送实体集中的所有实体。若实体行政级别不符合发布层次要求,则将该实体去除,如该文件的发布层次为“公开发布”,则所有实体均符合发布层次要求。
[0021]
进一步地,对于s05,根据得到的待推送实体集,在推送系统的数据库中进行匹配,匹配成功的实体可以通过电子公文系统直接向该部门发送文件或信息。对于主送和重点标记的单位,有重点提醒的文字信息。若文件中提取到的实体在推送系统的数据库中没有与其相关联的实体,则把它们加入推送系统的数据库中,但不进入信息发送阶段,待人工进行处理,进一步确定文件或信息的发送方式。这里的推送系统可以是现有的电子公文系统。在现有的电子公文系统中均存储有一定量的推送实体。
[0022]
进一步地,向匹配成功的推送实体直接推送政策文件的同时,采用消息队列给推送实体的实体部门联系人发送提醒短信,消息队列中间考虑到实际需求采用rabbitmq。对于标记的实体,则在短信中加入重点提醒的相关文字信息,如有需要,还可将提取的关键文件内容信息形成消息(形成概述),发送给目标实体、重点标注实体和/或主送实体。
[0023]
进一步地,如图1所示,将待推送政策文件扫描后利用正则表达式匹配得到主送抄送实体集。将主送抄送实体集与利用主题和关键信息得到的应推送实体集进行匹配,将相同的删除,将不同的进行合同,得到初推送实体集。然后再将初推送实体集与发布层次进行匹配,判定初推送实体集中的全部实体是否符合发布层次,得到待推送实体集。待推送实体集与推送系统数据库进行匹配,若匹配成功,则获得推送实体,直接向推送实体发送文件,若匹配不成功,则加入推送系统数据库进行人工审核,确定是否推送。对于向推送实体发送文件可以采用队列想实体部门的联系人发送短信。其它功能还可以包括拨打电话等。
[0024]
进一步地,提取待推送政策文件中的主题和关键信息可以包括以下步骤:s201,构建政策文件语料库。
[0025]
s202,基于构建的政策文件语料库进行模型训练以生成政策文件信息提取模型。
[0026]
s203,利用政策文件信息提取模型提取待推送政策文件中的主题和关键信息。
[0027]
对于s201,构建政策文件语料库可以包括:s2011,对现有开源语料库进行筛选,保留与政策文件相关性大于80%的语料,并将现有开源语料库中的其它语料删除。在对现有开源语料库进行筛选的过程中,可以保留百度百科、维基百科以及人民日报等语料库中绝大部分语料,删除和政策文件相关性较差的微博、金融新闻等语料库。保留与政策相关性大,删除与政策文件相关小的语料,能够使构建的政策文件语料库更加专业。
[0028]
s2012,收集现有政策文件,整理分类后得到政策文件常用词语语料集、政府各部门领导名单语料集以及政策文件目录语料集,并对现有政策文件中出现的一机构对应多名称的语料进行标注。在现有的语料库基础上,收集并整理现有的政策性文件,分类汇总后得到政策文件常用词语语料集、政府各部门领导名单语料集以及政策文件目录语料集。同时,对一机构对应多名称的语料进行人工标注,确保该机构可以识别为同一个实体。一机构对应多名称,是指一个机构可能有多种名称。例如,中华人民共和国工业和信息化部是该部门的全称,工业和信息化部、工信部、国家航天局、国家原子能机构等名称都指该部门。当文件中同时出现中华人民共和国工业和信息化部、工信部以及国家航天局时,经过人工标注后,能够对上述三种不同的叫法名称识别为同一部门。在不同的文件,同一机构对应多个名称同样适用。通过对“一机构多名称”进行人工标注,增加了文件信息提取和分类的准确性,减小了文件转发的工作量,提供了工作效率。这里的机构同样包含部门等。在政策文件常用词语语料集中可以包含公文常用语料,特别是一些在普通文章中不常使用语料,例如“狠抓”“兹”“为荷”“此复”等语料。政策文件目录语料集可以包含近5年或近10年上级机关下发的文件信息,包括文件标题、文号、发布层次等作为语料。
[0029]
s2013,对政策文件常用词语语料集、政府各部门领导名单语料集以及政策文件目录语料集定期更新并加入筛选后的现有开源语料库中,得到初始政策文件语料库。
[0030]
s2014,对包含政策文件的网页进行爬取,人工阅读后提取政策文件信息并将其加入初始政策文件语料库,得到扩充后政策文件语料库。对初始政策文件语料库进行扩充,通过爬虫爬取需要的政策文件信息,人工阅读爬取的文件信息,保留部门或机构官方网站发布且文件信息完整的语料,去掉非官方渠道发布或转发的、重复的、文件信息不完整的语料。
[0031]
s2015,对扩充后政策文件语料库进行标注,完成政策文件语料库的构建。标注关
键信息,标注时可采用构建“黑名单词典”,即同时多人标注,然后取多人识别的黑名单词典的交集作为标注结果。标注时可以使用thulac中文词法分析工具包对政策文件进行中文分词(4-tag法)和词性标注。thulac标注能力强大,准确率高,速度较快。
[0032]
标注的词性可以包括:n/名词,np/人名,ns/地名,ni/机构名,nz/其它专名,m/数词,q/量词,mq/数量词,t/时间词,f/方位词,s/处所词,v/动词,vm/能愿动词,vd/趋向动词,a/形容词,d/副词,h/前接成分,k/后接成分,i/习语,j/简称,r/代词,c/连词,p/介词,u/助词,y/语气助词,e/叹词,o/拟声词,g/语素,w/标点,x/其它。
[0033]
对于s202,政策文件语料库构建完毕后,进入模型训练阶段。模型训练阶段主要可以包括政策文件语料库数据集的读取、特征的转换、模型训练以及参数保存。基于构建的政策文件语料库,可以以现有的模型为与训练模型进行训练。训练的方式可以是常规的方式进行训练后得到政策文件信息提取模型。进一步地,基于构建的政策文件语料库进行模型训练以生成政策文件信息提取模型可以包括:s2021,对构建的政策文件语料库进行预处理,生成训练集和验证集。首先,将构建的政策文件语料库汇总为文件格式,并可以将文本数据分为两个部分,分别为train: train.tsv(训练集)和evaluate: dev.tsv(验证集)。上述两个部分可以按照(7~8):(2~3)进行划分。按照上述比例划分,能够确保训练集损失不太多的情况下,充分评估模型效果。如果训练集数据划分过少,容易导致相对少数据模型与实际预测的完全数据模型偏差较大。例如,按照7:3或者8:2进行划分。也可是使用k-folds进行交叉验证。对于train和evaluate,一列为需要做分类的文本数据,另一列则是对应的label。
[0034]
s2022,基于bert预训练模型读取训练集和验证集数据,生成包含序号、中文文本以及类别的列表。bert预训练模型可以为谷歌的中文模型“bert-base,chinese”。下载预训练模型后,将构建的政策文件语料库在此预训练模型上进行训练。采用pytorch的bert代码,训练阶段首先读取政策文件语料库数据,一般包括两个模块,分别是基类模块和用于自己的数据读取的模块。根据自己的文件格式不同可以对读取方式进行修改。在数据读取完毕后,可以得到一个包含序号、中文本和类别的列表。
[0035]
s2023,对列表进行特征转换得到特征值。列表获取后,可以通过bert的convert_examples_to_features将列表转换为特征值。
[0036]
s2024,将特征值输入bert预训练模型进行模型训练。转换后得到的特征值就可以作为输入,用于模型的训练。bert模型训练主要采用mask lm和next sentence prediction两种策略。在将单词序列输入给 bert之前,每个序列中有 15% 的词被 [mask] token 替换。然后模型尝试基于序列中其他未被 mask (掩盖)的单词上下文来预测被掩盖的原词。这需要在编码器的输出上添加一个分类层,用softmax计算词汇表中每一个词的概率,用以分类。为了理解两个句子之间的关系,bert 训练过程中还使用了next sentence prediction(下一句预测)。模型会从数据集抽取两句话,其中 b 句有 50% 的概率是 a 句的下一句,然后将这两句话转化前面所述的输入特征。随机遮掩(mask 掉)输入序列中 15% 的词,并要求 transformer 预测这些被遮掩的词,以及 b 句是 a 句下一句的概率这两个任务。训练时基于google 提供的模型训练源码,其文本分类的代码放在 run_classifier.py 中,提供了4 个基准数据集上的测试代码,对应 xnliprocessor,mnliprocessor,mrpcprocessor 和 colaprocessor ,然后根据本发明文本分类要求改写
processor类即可。
[0037]
s2025,利用adam优化函数进行优化训练,获取最佳模型参数,得到政策文件信息提取模型。
[0038]
进一步地,对于s2025,可以通过以下方法得到最佳模型参数:步骤a,采用adam优化函数,利用训练中的模型对每个epoch在验证集上进行验证,每个epoch后调整模型参数并生成每个epoch对应的f1分数。在模型训练时,可以采用bert专用的adam优化函数,对每一个epoch,训练中的模型都会在验证集上进行验证,并给出对应的f1分数(f1分数可以表示为衡量分类模型精度的一个指标,表示召回率和精确率的调和平均数,取值范围0-1之间,分数越高则代表分类能力越强,用于综合反应整体指标)。生成得到f1分数的方法可以为常规使用方法。对于每一个epoch,均会对模型参数进行相应的调整,下一个epoch就可以得到不同的f1分数。理论上来讲,随着对模型参数的调整,f1分数是会逐步提升的。这里,调整的模型参数可以包括神经网络各层的偏置、权重以及kernel、beta参数等。可以利用验证集调整模型参数,通过训练得到模型后,模型会使用验证集来验证模型的效果。模型参数的调整,就是去拟合预测验证集得到的标签逐渐趋近于验证集原本的标签的过程,此过程中模型参数是训练过程中模型自行调整的。在逐步拟合的过程中,f1分数是不断提高的。
[0039]
步骤b,对f1分数进行判定,根据判定结果,确定最佳模型参数,其中,判定包括:若f1分数大于0.95,则停止训练,保存此时的模型参数,此时的模型参数即为最佳模型参数;若f1分数不大于0.95,对f1分数进一步判定,若f1分数大于0.9且相邻两个epoch对应的f1分数变化小于千分之一,则停止训练,保存此时的模型参数,反之,则继续进行模型训练。将模型的正确率设定在0.95或者大于0.9且稳定,可以确保政策文件信息提取的准确性。
[0040]
本发明采用bert模型,对下游任务进行fine-tune,从而构成embedding层,同样使用双向lstm层以及最后的crf层来完成序列预测。相比传统nlp(自然语言)处理方法,bert所使用的transformer抽取特征能力更强。并且,bert的一体化融合特征方式比双向拼接融合特征能力也更强,在标准数据集中效果提升明显。bert 模型是将预训练模型和下游任务模型结合在一起的,即在做下游任务时仍然是用bert模型,而且天然支持文本分类任务,在做文本分类任务时不需要对模型做修改。结合bert-ner和特定的分词、词性标注等中文语言处理方式,能获得更高的准确率和更好的效果,同时能在政策文件领域的中文信息抽取任务中取得优异的效果。
[0041]
进一步地,对连续多个epoch对应的f1分数进行比较,若f1分数没有提升,则设置早停系数,停止模型训练。训练过程中设置早停系数,能够在连续多个训练的性能都没有继续优化时停止训练过程。
[0042]
进一步地,在构件政策文件语料库中还包括在对现有政策文件中出现的一机构对应多名称的语料进行标注的同时对名称特殊或名称较长的专项计划进行标注。
[0043]
综上所述,本发明通过构建专业、特有的政策文件语料库,并基于构建的政策文件语料库训练用于提取政策性文件的模型,训练的模型在实体识别、政策性文件内容解读方面更加准确,提高了政策文件中的主题和关键信息抽取的效率和准确率,使生成的实体更
加全面准确,对政策文件的重点推送等工作奠定良好的基础;本发明的推送方法利用政策文件格式的特殊性,使用正则表达式准确识别政策文件的推送目标实体,同时可以根据nlp模型提取文件内容用于判定相关目标实体,对文件或信息进行自动分发或转发,并采用rabbitmq消息队列对特定目标进行重点推送,提高了文件流转的实时性和高效性,降低了系统的耦合性,保证了消息的传递。
[0044]
尽管上面已经通过结合示例性实施例描述了本发明,但是本领域技术人员应该清楚,在不脱离权利要求所限定的精神和范围的情况下,可对本发明的示例性实施例进行各种修改和改变。
相关技术
网友询问留言
已有0条留言
- 还没有人留言评论。精彩留言会获得点赞!
1