一种神经网络加速协处理器、处理系统及处理方法与流程
本发明涉及人工智能和芯片设计领域,具体涉及一种神经网络加速协处理器、处理系统及处理方法。
背景技术:
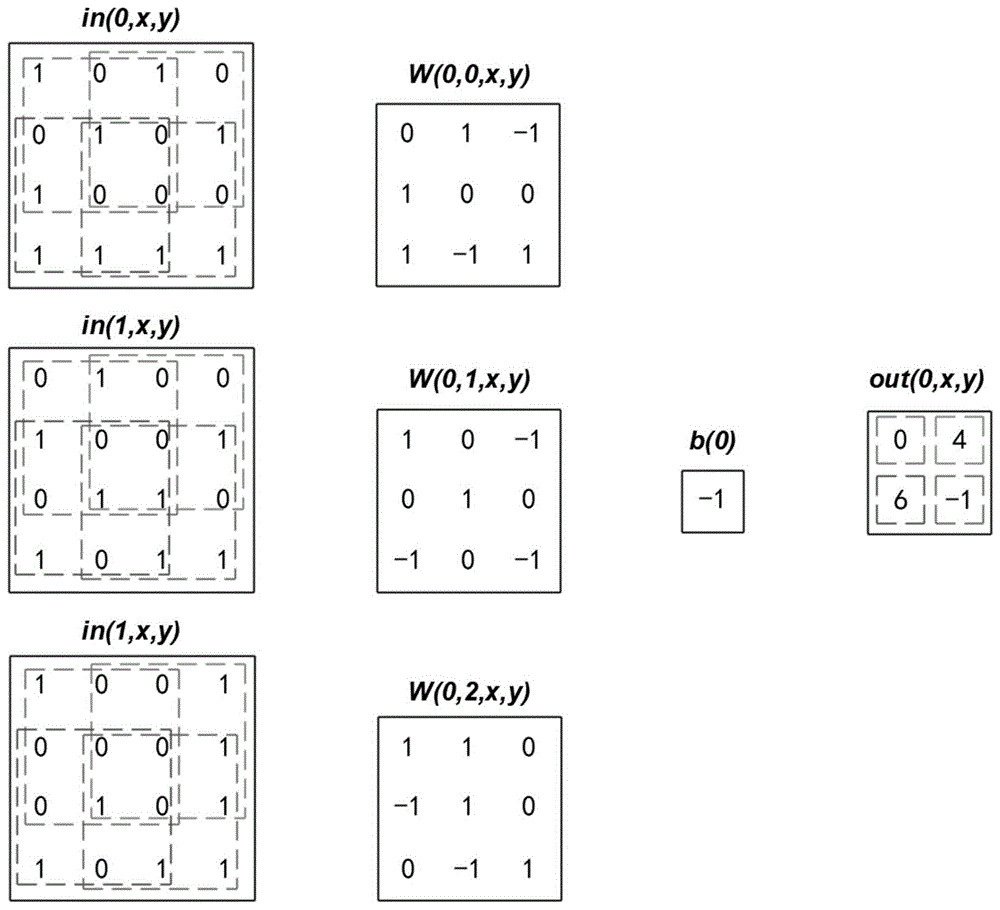
:卷积层是卷积神经网络中的核心计算模块,通常卷积层计算量在整个卷积网络计算中占比超过90%。图1展示的是卷积计算一幅输出特征图的过程,每幅输入特征图对应一个卷积核,输入图中不同颜色的虚线框对应着不同的输出,每一个输出是由不同输入图相同位置和卷积核乘积累加而得到。每一个输出是输入的局部信息处理结果,反映了局部的特征信息,同一输入特征图使用相同卷积核进行特征处理,这是卷积网络中的权重共享机制。卷积层可以完成对输入特征图的局部特征提取,通过卷积核在输入特征图上滑动计算完成整个输入特征图的处理。卷积层的计算公式如公式1,其中out(f0,x,y)表示第f0幅输出特征图中x,y位置对应的值,w是卷积核权重矩阵,而in表示输入特征图,b表示卷积层的偏置,k是卷积核尺寸,s是卷积核的滑动步长,可以看到一个卷积层输出是由n通道输入特征图中相应区域和卷积核进行乘加累加得到。从公式1可以看出,卷积中包含大量乘加操作,计算量非常大,通过纯软件的方式去实现,运算效率很低,需要开发一种神经网络加速算法以及外协硬件处理器,与ai指令配合实现算法加速。技术实现要素:本发明实施例提供一种神经网络加速协处理器、处理系统及处理方法,用以解决当前通过纯软件的方式去处理卷积层计算的运算效率非常低的问题。本发明一方面的实施例提供一种神经网络加速协处理器,包括控制模块、地址产生模块、乘累加模块和输出饱和模块;所述地址产生模块用于为输入数据和对应输出数据匹配存储地址;所述乘累加模块用于进行神经网络卷积运算;所述输出饱和模块用于限定输出数据的范围,输出运算结果;所述控制模块用于接收主处理器发送的扩展指令,根据扩展指令控制地址产生模块对输入和对应输出数据匹配地址,按照匹配地址从存储器中读取数据,控制乘累加模块对读取的数据进行卷积计算,控制输出饱和模块输出计算结果,并将输出结果按照匹配的输出数据地址存入存储器中。优选的,所述扩展指令包括用于初始化卷积参数的配置指令和用于执行卷积运算的运算指令;所述配置指令为单周期指令,用于配置输入、输出数据的地址、参数和卷积核的参数;所述运算指令为可变的多周期指令,该指令执行周期数由一级指令中设定的卷积运算的参数决定。在上述任意一项实施例中优选的,所述配置指令包括下述第一至第六指令;第一指令用于设定输入、输出张量通道数;第二指令用于设定输入、输出张量尺寸;第三指令用于设定卷积核的尺寸和步长;第四指令用于设定填充大小和滤波器权重数据起始地址;第五指令用于设定输入、输出数据的起始地址;第六指令用于设定偏移量和偏差数据起始地址。在上述任意一项实施例中优选的,还包括控制模块将扩展指令进行解码,根据解码后的扩展指令读取操作数,并将读取的操作数写入寄存器中;所述操作数用于传输输入数据数据在存储器中的存放地址;根据操作数指向的存放地址,从存储器中读取输入数据。本发明还提供一种神经网络加速处理系统,包括上述协处理器,还包括主处理器和存储器;所述存储器,用于存储数据;主处理器,用于发送拓展指令;协处理器,用于接收主处理器所发送的拓展指令,根据接收到的拓展指令,从存储器中读取输入数据,对输入数据进行神经网络计算,得到输出数据,将所述输出数据存入存储器。本发明还提供一种神经网络加速处理方法,应用于上述处理系统,包括以下步骤:主处理器向协处理器发送扩展指令;协处理器接收主处理器所发送的扩展指令,根据接收到的扩展指令,从存储器中读取输入数据,对读取的输入数据进行神经网络运算,得到输出数据,将所述输出数据写入存储器中;主处理器从存储器中读取由协处理器存储的输出数据,完成神经网络算法处理。在上述任意一项实施例中优选的,主处理器向协处理器发送扩展指令,控制协处理器进行初始化卷积参数的配置和卷积运算的执行;在所述初始化卷积参数配置中包括单周期配置输入、输出数据的地址、参数和卷积核的参数;所述卷积运算的执行周期由一级指令中设定的卷积运算的参数决定。在上述任意一项实施例中优选的,在对初始化卷积参数进行配置时,包括如下操作:设定输入、输出张量通道数;设定输入、输出张量尺寸;设定卷积核的尺寸和步长;设定填充大小和滤波器权重数据起始地址;设定输入、输出数据的起始地址;设定偏移量和偏差数据起始地址。在上述任意一项实施例中优选的,还包括将每一条扩展指令按照如下编码格式进行编写:a、指令的第一比特区间为opcode编码段;b、设定三个比特位,用于控制是否需要读源寄存器和写目标寄存器。在上述任意一项实施例中优选的,在根据接收到的扩展指令,从存储器中读取输入数据时,还包括所述协处理器将扩展指令进行解码,根据解码后的扩展指令读取操作数,并将读取的操作数写入寄存器中;所述操作数用于传输输入数据数据在存储器中的存放地址;根据操作数指向的存放地址,从存储器中读取输入数据。有益效果1、本申请提供的神经网络加速处理方法、协处理器及处理系统,处理神经网络时,设置协处理器,由协处理器来处理卷积神经网络中的耗时操作,主处理器通过拓展指令,控制协处理器对输入数据进行神经网络计算,降低了cpu的利用率,与纯软件相比,提升卷积运算效率达到20倍以上;2、本申请通过扩展指令配置协处理器时,简化了协处理器指令集扩展的方式,设置7条扩展指令,进行参数的初始化和卷积运算的执行,算法简单,提高了系统的鲁棒稳定性,满足算法灵活多变的计算要求。3、本申请的协处理器在对扩展指令进行解码时,会直接将操作数读出来送到寄存器中,利用操作数进行地址传递,相比于直接读写数据地址,读写速度更快,缓冲结构利用率更高。4、本申请采用的扩展指令编码格式,利用指令的第一比特区间(低七位)作为opcode编码段,利用该编码段每个指令组和额外的编码空间,可以编码出更多协处理器指令,极大的提高了协处理器的可扩展性。附图说明构成本申请的一部分的说明书附图用来提供对本发明的进一步理解,本发明的示意性实施例及其说明用于解释本发明,并不构成对本发明的不当限定。在附图中:图1为本申请
背景技术:
中提出的卷积神经网络模型输入输出特征的示意图;图2为本申请实施例提供的神经网络加速协处理器的结构框图;图3为本申请实施例提供的神经网络处理系统的结构框图;图4为本申请实施例提供的神经网络加速处理方法的流程图;图5为本申请实施例中卷积计算协处理器执行流程示意图;图6为本申请另一个示例的数据加速计算示意图;具体实施方式下面将参考附图并结合实施例来详细说明本发明。需要说明的是,在不冲突的情况下,本申请中的实施例及实施例中的特征可以相互组合。以下详细说明均是示例性的说明,旨在对本发明提供进一步的详细说明。除非另有指明,本发明所采用的所有技术术语与本申请所属领域的一般技术人员的通常理解的含义相同。本发明所使用的术语仅是为了描述具体实施方式,而并非意图限制根据本发明的示例性实施方式。如图2所示,本发明一方面的实施例提供一种神经网络加速协处理器,包括控制模块301、地址产生模块302、乘累加模块303和输出饱和模块304;所述地址产生模块302用于为输入数据和对应输出数据匹配存储地址;所述乘累加模块303用于进行神经网络卷积运算;所述输出饱和模块304用于限定输出数据的范围,输出运算结果;所述控制模块301用于接收主处理器发送的扩展指令,根据扩展指令控制地址产生模块对输入和对应输出数据匹配地址,按照匹配地址从存储器中读取数据,控制乘累加模块对读取的数据进行卷积计算,控制输出饱和模块输出计算结果,并将输出结果按照匹配的输出数据地址存入存储器中。其中,扩展指令包括用于初始化卷积参数的配置指令和用于执行卷积运算的运算指令;进一步,配置指令为单周期指令,用于配置输入、输出数据的地址、参数和卷积核的参数;运算指令为可变的多周期指令,该指令执行周期数由一级指令中设定的卷积运算的参数决定。所述配置指令包括下述第一至第六指令;第一指令用于设定输入、输出张量通道数;第二指令用于设定输入、输出张量尺寸;第三指令用于设定卷积核的尺寸和步长;第四指令用于设定填充大小和滤波器权重数据起始地址;第五指令用于设定输入、输出数据的起始地址;第六指令用于设定偏移量和偏差数据起始地址。如图5所示,在本实施例中,对于卷积运算协处理器的实现定义了7条扩展指令,其中6条配置指令分别为设定输入输出张量通道数的init_ch、设定输入输出张量尺寸的init_im、设定滤波器核尺寸和步长的init_fs、设定填充大小和滤波器权重数据起始地址init_pw、设定输入输出数据的起始地址的init_imaddr和设定偏移量和偏差数据起始地址的init_bias;用来初始化卷积参数的指令;用来参数初始化的几条指令都是单周期指令,当收到相应的指令时,会直接将操作数读出来送到寄存器中,以备后续计算使用。具体为控制模块将扩展指令进行解码,根据解码后的扩展指令读取操作数,并将读取的操作数写入寄存器中;所述操作数用于传输输入数据数据在存储器中的存放地址;根据操作数指向的存放地址,从存储器中读取输入数据。运算指令采用loop指令是用来执行卷积运算的指令。执行卷积运算的loop指令是一个可变的多周期指令,该指令执行周期数由卷积运算相关参数决定。各指令的具体定义如表1所示。表1卷积协处理器指令列表在上表中,opcode指的是编码段,使用编码custom-0、custom-1、custom-2和custom-3指令组。xs1、xs2和xd比特位分别用于控制是否需要读源寄存器和写目标寄存器。funct7区间,可作为额外的编码空间,用于编码更多的指令,因此一种custom指令组可以使用funct7区间编码出128条指令。在本实施例中,通过设置协处理器,由协处理器接收到扩展指令后,处理卷积神经网络中的耗时操作,对输入数据进行神经网路卷积计算,灵活地对卷积神经网络的卷积、池化和激活操作进行结合运算,能够适应于多种轻量化卷积神经网络。如图3所示,本发明还提供一种神经网络加速处理系统,包括上述协处理器3,还包括主处理器1和存储器2;所述存储器2,用于存储数据;主处理器1,用于发送拓展指令;协处理器3,用于接收主处理器所发送的拓展指令,根据接收到的拓展指令,从存储器中读取输入数据,对输入数据进行神经网络计算,得到输出数据,将所述输出数据存入存储器。如图4所示,本发明还提供一种神经网络加速处理方法,应用于上述处理系统,包括以下步骤:s1、主处理器向协处理器发送扩展指令;s2、协处理器接收主处理器所发送的扩展指令,根据接收到的扩展指令,从存储器中读取输入数据,对读取的输入数据进行神经网络运算,得到输出数据,将所述输出数据写入存储器中;s3、主处理器从存储器中读取由协处理器存储的输出数据,完成神经网络算法处理。其中,在s1或s2中,扩展指令包括用于初始化卷积参数的配置指令和用于执行卷积运算的运算指令;配置指令为单周期指令,用于配置输入、输出数据的地址、参数和卷积核的参数;运算指令为可变的多周期指令,该指令执行周期数由一级指令中设定的卷积运算的参数决定。在配置时,包括如下操作:设定输入、输出张量通道数;设定输入、输出张量尺寸;设定卷积核的尺寸和步长;设定填充大小和滤波器权重数据起始地址;设定输入、输出数据的起始地址;设定偏移量和偏差数据起始地址。如上表1所示,在本实施例中,对于卷积运算协处理器的实现定义了7条扩展指令,其中6条配置指令分别为设定输入输出张量通道数的init_ch、设定输入输出张量尺寸的init_im、设定滤波器核尺寸和步长的init_fs、设定填充大小和滤波器权重数据起始地址init_pw、设定输入输出数据的起始地址的init_imaddr和设定偏移量和偏差数据起始地址的init_bias;用来初始化卷积参数的指令;用来参数初始化的几条指令都是单周期指令,当收到相应的指令时,会直接将操作数读出来送到寄存器中,以备后续计算使用。运算指令采用loop指令是用来执行卷积运算的指令。执行卷积运算的loop指令是一个可变的多周期指令,该指令执行周期数由卷积运算相关参数决定。如上表所示,扩展指令的编码格式,包括1、指令的第一比特区间为opcode编码段;2、设定三个比特位,用于控制是否需要读源寄存器和写目标寄存器。具体为,在上表中,opcode指的是编码段,使用编码custom-0、custom-1、custom-2和custom-3指令组。一般采用第一比特位至第6比特位,为第一比特区间作为opcode编码段,xs1、xs2和xd比特位分别用于控制是否需要读源寄存器和写目标寄存器。funct7区间,可作为额外的编码空间,用于编码更多的指令,因此一种custom指令组可以使用funct7区间编码出128条指令。将本方法应用在上述系统进行测试时,得出如图6所示的实施例,cifar-10数据集是由hinton的两个徒弟alexkrizhevsky和ilyasutskever为了便于普通物体识别而收集的数据集。该数据集共包含10类图像集,分别是飞机、汽车、鸟、猫、鹿、狗、青蛙、马、船和卡车,总共包含60000张图片,其中,每类图像集包含6000张图片。数据集中的每张图片像素大小为32*32,通道数为rgb3通道。处理结果如下表所示,处理阶段基于协处理器纯软件加速比卷积46752549459578920.23表2为处理结果列表在本实施例中,通过在卷积计算阶段的对比,当前纯软件的处理方法需要94595789个cycle,而通过本发明实施例提供的基于协处理器的处理方法需要4675254个cycle,加速比为20.23。本领域内的技术人员应明白,本申请的实施例可提供为方法、系统、或计算机程序产品。因此,本申请可采用完全硬件实施例、完全软件实施例、或结合软件和硬件方面的实施例的形式。而且,本申请可采用在一个或多个其中包含有计算机可用程序代码的计算机可用存储介质(包括但不限于磁盘存储器、cd-rom、光学存储器等)上实施的计算机程序产品的形式。本申请是参照根据本申请实施例的方法、设备(系统)、和计算机程序产品的流程图和/或方框图来描述的。应理解可由计算机程序指令实现流程图和/或方框图中的每一流程和/或方框、以及流程图和/或方框图中的流程和/或方框的结合。可提供这些计算机程序指令到通用计算机、专用计算机、嵌入式处理机或其他可编程数据处理设备的处理器以产生一个机器,使得通过计算机或其他可编程数据处理设备的处理器执行的指令产生用于实现在流程图一个流程或多个流程和/或方框图一个方框或多个方框中指定的功能的装置。这些计算机程序指令也可存储在能引导计算机或其他可编程数据处理设备以特定方式工作的计算机可读存储器中,使得存储在该计算机可读存储器中的指令产生包括指令装置的制造品,该指令装置实现在流程图一个流程或多个流程和/或方框图一个方框或多个方框中指定的功能。这些计算机程序指令也可装载到计算机或其他可编程数据处理设备上,使得在计算机或其他可编程设备上执行一系列操作步骤以产生计算机实现的处理,从而在计算机或其他可编程设备上执行的指令提供用于实现在流程图一个流程或多个流程和/或方框图一个方框或多个方框中指定的功能的步骤。由技术常识可知,本发明可以通过其它的不脱离其精神实质或必要特征的实施方案来实现。因此,上述公开的实施方案,就各方面而言,都只是举例说明,并不是仅有的。所有在本发明范围内或在等同于本发明的范围内的改变均被本发明包含。当前第1页12
相关技术
网友询问留言
已有0条留言
- 还没有人留言评论。精彩留言会获得点赞!
1