一种结合知识库的基于MRC的公司实体消歧方法与流程
一种结合知识库的基于mrc的公司实体消歧方法
技术领域
[0001]
本发明涉及人工智能领域,尤其涉及一种结合知识库的基于mrc的公司实体消歧方法。
背景技术:
[0002]
文本资讯是公司实体信息传播的主要媒介,精确定位发生新闻的公司实体 (公司关联)直接决定如何开展下游金融工作。在金融资讯中,公司实体(公司实体数以千万计)多以领域简称的形式出现,极易引发歧义。例如,老百姓可以指一家上市公司,也可以是“普通群众”;五粮液可以指上市公司也可指向五粮液白酒。实体消歧的本质在于一个词可能有多个意思,需结合上下文和知识库的相关知识确定它所表达的确切含义。公司实体的歧义消解对后续理解金融新闻资讯内容,关联准确的公司实体信息具有重要意义。
[0003]
当前阶段,公司实体消歧常用的方法有:(1)基于正则表达式匹配的方法:维护各个可能出现歧义公司的正负样例(无歧义为正样例,有歧义为负样例) 规则,通过正则匹配的方式判断有无歧义;(2)基于无监督样本聚类的方法:通过对包含公司实体简称文本的语义聚类,发掘正负样例簇,进行消歧;(3) 基于有监督样本分类的方法:通过标注可能出现歧义公司的正负样本,训练二分类模型,进行消歧。
[0004]
上述方法中,基于正则表达式匹配的方法,虽然具有较高的准确率,但召回低,扩展性差,需要持续不断地通过人工来维护规则库,效率低下;基于无监督样本聚类的方法,一方面由于缺乏监督信息,准确率相对较低,另一方面,对于每一个新增加的待消歧公司实体,都需要新增其相对应的无监督语料,并重新聚类;基于有监督样本分类的方法,一方面,由于只针对正负样本进行二分类,无法确定负样本即有歧义样本的具体歧义类别,另一方面,由于没有引入实体知识库的信息,无法有效利用知识库对于实体的描述。
技术实现要素:
[0005]
针对现有技术的不足,本发明提供了一种结合知识库的基于mrc的公司实体消歧方法,以解决现有技术中存在的准确率相对较低的问题。
[0006]
为解决上述技术问题,本发明采用的技术方案为:
[0007]
一种结合知识库的基于mrc的公司实体消歧方法,包括如下步骤:
[0008]
获取待消歧语句;
[0009]
将所述待消歧语句与提问句进行拼接,得到mrc结构;
[0010]
从实体知识库中获取待消歧语句中歧义简称对应的不同的实体描述语句;
[0011]
将不同的实体描述语句拼接在mrc结构的最后;
[0012]
将拼接了不同实体描述语句的mrc结构输入至bert模型中;
[0013]
所述bert模型输出歧义简称对应的真实实体,实现语句消歧。
[0014]
进一步的,所述bert模型的输出端设置有两个损失函数;所述损失函数包括第一任务损失函数和第二任务损失函数。
[0015]
进一步的,所述第一任务损失函数为二分类损失;第二任务损失函数为多分类损失。
[0016]
进一步的,所述第一任务损失函数通过如下公式表示:
[0017]
output
1
=sigmoid(w
1
×
h
[cls]
)
[0018]
loss
1
=binary_crossentropy(output
1
,label
1
)
[0019]
式中,output
1
表示任务一的模型输出;sigmoid()表示逻辑(logistic)函数; w
1
表示任务计算任务一输出的权重矩阵;h
【cls】
表示句首位置处的语义向量; loss
1
表示任务一的损失;binary_crossentropy()表示二分类交叉熵损失计算函数;label
1
表示任务一的真实标签。
[0020]
进一步的,所述第二任务损失函数通过如下公式表示:
[0021]
entity_output
i
=sigmoid(w
entity_i
×
h
entity_i
)
[0022]
loss
entity_i
=binary_crossentropy(entity_output
i
,label
entity_i
)
[0023][0024]
式中,entity_output
i
表示第i个实体处的模型输出;w
entity_i
表示计算第i个实体处输出的权重矩阵;h
entity_i
表示第i个实体位置处的语义向量;loss
entity_i
表示第i个实体的损失;label
entity_i
表示第i个实体的真实标签;loss
2
表示任务二的损失;n表示歧义实体简称可能对应实体的数量。
[0025]
进一步的,所述bert模型通过第一任务损失函数和第二任务损失函数对拼接了不同实体描述语句的mrc结构进行消歧,具体的消歧过程如下:
[0026]
通过所述第一任务损失函数判断待消歧语句中是否存在歧义简称;
[0027]
若存在,则通过第二任务损失函数从不同实体描述语句中获取歧义简称对应的真是实体。
[0028]
进一步的,所述bert模型通过12层的基础神经网络结构堆叠而来。
[0029]
进一步的,对bert模型进行训练,将mrc结构输入至训练后的bert模型中实现语句消歧;所述bert模型的训练方法包括:
[0030]
设置bert模型中基础神经网络结构的参数;
[0031]
将最后3层基础神经网络结构的参数等概率随机初始化;
[0032]
训练参数随机初始化后的bert模型,待bert模型的损失函数收敛后,停止训练,得到训练优化后的bert模型。
[0033]
与现有技术相比,本发明所达到的有益效果是:
[0034]
本发明通过实体知识库中实体描述的引入,给模型输入了更多的有效信息,提升了模型的预测能力,同时利用mrc的输入构造方式,契合了bert模型预训练阶段的输入特点,进一步提升了实体消歧的准确率,另外还通过对实体指代内容的具体分类,对不同类型的歧义进行了更进一步的细致区分,此外多任务学习和权重再初始化的使用,也加快了模型收敛,增强了训练稳定性。
附图说明
[0035]
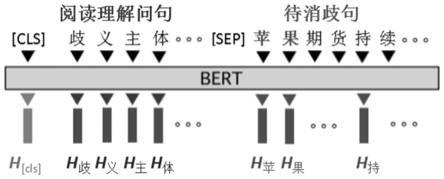
图1为通过与提问句拼接的方式来构造类似阅读理解输入的样例图;
[0036]
图2为通过有效关联待消歧句与实体描述语句的样例图。
具体实施方式
[0037]
为了使本发明的目的、技术方案及优点更加清楚明白,以下结合实施例,对本发明进行进一步详细说明。应当理解,此处所描述的具体实施例仅仅用以解释本发明,并不用于限定本发明。
[0038]
一种结合知识库的基于mrc的公司实体消歧方法,包括如下步骤:
[0039]
(1)获取待消歧语句;
[0040]
(2)将待消歧语句与提问句进行拼接,得到mrc结构;
[0041]
首先,通过类似阅读理解的方式构造输入,即将待消歧语句作为阅读理解的文本,与提问句进行拼接得到mrc结构并将mrc结构作为输入。
[0042]
(3)从实体知识库中获取待消歧语句中歧义简称对应的不同实体描述语句;
[0043]
(4)将不同的实体描述语句拼接在mrc结构的最后;
[0044]
借助实体知识库,将其中对于同一歧义简称但不同指代的各实体描述语句接在mrc结构输入的最后,用于提供更详细的歧义消解信息。
[0045]
(5)将拼接了不同实体描述语句的mrc结构输入至bert模型中;
[0046]
(6)所述bert模型输出歧义简称对应的真实实体,实现语句消歧。
[0047]
在bert模型的输出端,利用多任务学习之间会互相促进的特点,设计了两种任务并累加损失,一个是判断是否有歧义的二分类损失,另一个是确定具体歧义类别的多分类损失。
[0048]
在bert模型的训练初始,只保留靠近输入层的模型权重,对于靠近输出层的模型权重,重新随机初始化,这样可以加快模型的收敛速度,减少训练过程中的损失抖动,提高训练稳定性。
[0049]
本发明的具体步骤如下:
[0050]
step1-构造mrc方式的输入
[0051]
构造mrc方式的模型输入,将需要消歧的句子作为阅读文本,通过与提问句拼接的方式来构造类似阅读理解的输入,样例如图1所示,图1中待消歧句为“苹果期货持续承压,但波动逐渐减小”,阅读理解问题为“歧义主体的指代”,通过自注意力(self-attention)机制,问题与待消歧句之间互相“注意”,让模型学会根据问题从句中提取有利消歧的信息。
[0052]
step2-结合实体知识库的输入
[0053]
为了充分利用结构化知识库中的有效信息,需要设计一种可以融合模型与知识库知识的结构。而实体知识库中最有效的信息来自实体描述语句,通过将歧义简称所有可能的实体描述依次拼接在mrc结构输入的最后,通过注意力机制,有效关联待消歧句与实体描述语句,样例如图2所示,图2中,待消歧句中的歧义简称为“苹果”,这个关键词在结构化实体知识库中有多个对应实体,例如“苹果属植物”即我们平常食用的水果和“一家高科技公司”即美国的苹果公司。通过这样的融合方式,可以有效利用实体知识库中的结构化信息,有助模型理解待消歧句语义,提高消歧准确性。
[0054]
step3-多任务学习
[0055]
在输出端,损失函数的设计也至关重要。利用多任务学习之间会相互促进的特点,
设计两种任务,并累加损失。
[0056]
1)第一个任务是区分待消歧句中是否包含歧义实体简称;
[0057]
output
1
=sigmoid(w
1
×
h
[cls]
)
[0058]
loss
1
=binary_crossentropy(output
1
,label
1
)
[0059]
式中,output
1
表示任务一的模型输出;sigmoid()表示逻辑(logistic)函数; w
1
表示任务计算任务一输出的权重矩阵;h
【cls】
表示句首位置处的语义向量; loss
1
表示任务一的损失;binary_crossentropy()表示二分类交叉熵损失计算函数;label
1
表示任务一的真实标签。
[0060]
第二个任务是确定歧义实体简称对应的实体具体是哪一个;
[0061]
entity_output
i
=sigmoid(w
entity_i
×
h
entity_i
)
[0062]
loss
entity_i
=binary_crossentropy(entity_output
i
,label
entity_i
)
[0063][0064]
式中,entity_output
i
表示第i个实体处的模型输出;w
entity_i
表示计算第i个实体处输出的权重矩阵;h
entity_i
表示第i个实体位置处的语义向量;loss
entity_i
表示第i个实体的损失;label
entity_i
表示第i个实体的真实标签;loss
2
表示任务二的损失;n表示歧义实体简称可能对应实体的数量。
[0065]
step4-权重再初始化
[0066]
通常对基于bert的模型而言,只需要保留预训练好的bert模型全部12层基础神经网络结构参数,并直接在下游任务上微调即可。但此方法的训练过程并不稳定,且收敛速度慢。原因在于预训练好的bert模型所有12层网络结构的权重并不都对下游任务有正面作用,靠近输入层学到的是通用语义信息,例如词性、句法等,而靠近输出层学到的则是下游任务强相关的知识。显然bert 预训练时的下游任务,与本方案中的消歧任务并不相同,因此预训练好的bert 中靠近输出层的网络权重对下游任务的训练有负面作用,为此提出权重再初始化的方法,解决下游任务训练不稳定的问题:
[0067]
1)复制预训练好的bert中全部12层基础神经网络结构参数到本方案模型中去;
[0068]
2)将本方案模型最后3层网络结构的参数,通过0~1之间等概率随机初始化的方式替换;
[0069]
3)训练最后3层网络结构参数再初始化后的模型,待模型损失函数收敛后,停止训练,得到训练优化后的模型;
[0070]
4)利用训练好的模型,接受输入,得到消歧输出。
[0071]
step1-构造包含公司实体信息的知识库,需要包含可能引发歧义的实体简称对应的各类实体及其描述信息。
[0072]
step2-标注一定量的监督语料,包含无歧义的语料,以及有歧义的语料,其中有歧义的语料需要具体标注出对应的歧义实体类别。
[0073]
step3-构造mrc方式的输入,问句与待消歧句拼接,并在句尾逐个拼接歧义实体简称所有可能对应实体的描述语句。
[0074]
step4-输入bert模型,在输出端计算两种损失并叠加,一种是判断句子对公司实体描述是否有歧义的二分类损失,另一种是确定具体歧义类别的多分类损失。
[0075]
step5-训练初始时,只保留接近输入层的bert权重,对于靠近输出层的权重,重新随机初始化。
[0076]
step6-训练结束得到完整的公司实体歧义消解模型,在预测时,输入与step3 保持一致,输出有两个,一个用来判断句子中是否包含有歧义的公司实体,另一个用来确定实体对应的具体歧义类别。
[0077]
本发明公开的一种结合知识库的基于mrc(machine readingcomprehension)的公司实体消歧(entity disambiguation)方法。针对公司实体关联中存在的歧义问题,本技术基于bert模型,首先通过mrc(machine readingcomprehension)的方式构造消歧问句,然后结合实体知识库中的实体描述信息构造模型输入,在输出端通过多任务学习,累加是否包含实体的二分类损失与具体是哪个实体的多分类损失,来构造损失函数,最后通过权重再初始化(weight re-initializing)加快模型训练的收敛速度,提高训练稳定性。本发明有效解决了大量金融新闻资讯中多以简称出现的公司实体的歧义问题,避免了多种含义的公司实体引发的语义理解偏差,提高了公司关联的准确率,为下游各类金融分析算法提供重要基础技术支持。
[0078]
本发明相比基于正则表达式匹配的方法,通过初期的标注语料,利用模型的泛化能力,可以有效避免后续大量的人工规则维护工作。相比基于无监督样本聚类的方法,标注数据的引入,有效提升了模型预测的准确率,同时有监督模型的泛化能力也避免了在新增公司实体时对于重新标注和模型训练的需要。
[0079]
本发明并不局限于上述实施例,在本发明公开的技术方案的基础上,本领域的技术人员根据所公开的技术内容,不需要创造性的劳动就可以对其中的一些技术特征作出一些替换和变形,这些替换和变形均在本发明的保护范围内。
相关技术
网友询问留言
已有0条留言
- 还没有人留言评论。精彩留言会获得点赞!
1