一种电网故障中SCADA数据频繁项集挖掘方法与流程
本发明属于电网故障诊断技术,具体涉及一种电网故障中scada数据频繁项集挖掘方法。
背景技术:
电力系统的故障诊断是实现电网自我修复和迭代的重要方法。电网的故障诊断通常是利用故障前后的电气量信息、开关量信息和保护动作信息的变化来发现故障原因和完成故障定位的。准确的故障识别能够大幅的提高故障的诊断速度,同时降低故障损失。目前在故障诊断领域常见的故障诊断方法运用故障历史数据加之一定的机器学习或深度学习算法,如专家系统、贝叶斯网络、petri网、粗糙集理论、人工神经网络等。这些算法往往对故障数据的要求较高,故障数据的稍微变化会对整个诊断的结果产生重要的影响。
随着5g时代的到来和智能电网的加速推进,一方面,太阳能及风能等间歇式能源的接入使得电网复杂度不断增加;另一方面,智能电表的大量部署、故障录波信息网的建设与应用使得信息的获取渠道更为多元。这些都导致信息管理侧的数据更加的复杂及庞大,因此当电网发生故障时,调度中心的调度人员面对的是多达数万条甚至数十万条的数据,对这些数据的使用需要进行逻辑关联及属性设定,这就要求调度人员掌握电网运行特点和基本的保护原理,工作量异常大并且琐碎。因此本发明提出了使用fp-growth算法对scada数据进行频繁项集的挖掘,并找出数据潜在的关联性,从而提高辅助分析决策的能力。
技术实现要素:
发明目的:针对电网故障时大量数据涌入电网调度平台,调度人员难以及时处理大量数据并对故障及时做出诊断和处理的问题,本发明的提供一种电网故障中scada数据频繁项集挖掘方法。
技术方案:一种电网故障中scada数据频繁项集挖掘方法,所述方法基于fp-growth算法,包括以下步骤:
(1)采集电网故障的scada数据,包括电网故障设备信息、故障时间点和设备运行数据;
(2)对scada数据进行预处理和分类,基于故障数据文本的相似度计算进行数据的删除,包括去重、异常值过滤和数据重组,并将处理完的scada数据以变电站进行数据分类;
(3)将分类处理后的scada数据按照时间进行排序,并确定事件折叠窗口的时间度,并根据事件窗口将排序好的scada数据进行事件的划分,将同属于一个事件折叠窗口的scada数据化分为同一个事件;
(4)将经过划分后的独立事件的属性进行离散化处理,同时将相同的电网设备贴上相同的标识,然后将离散化后的属性与电网标识相结合构成简化后的数据项;
(5)基于fp-growth算法对事件集进行频繁项集挖掘,包括设定支持度和设定置信度,并构建fp-tree,所述频繁项集为支持度大于等于最小支持度的集合;
(6)将步骤(5)得到的频繁项集进行语义转化,将离散化和模糊化的独立事件转化描述成具体的对应的变电站和遥测事件信息,确定电网各故障事件之间的相互关联关系,从而分析出故障发生后可能发生的潜在电网故障事件。
进一步的,步骤(1)所述的电网故障设备包括变电站名称、故障设备名称;所述的故障时间点指的是故障发生的具体的年月日及时分秒;所述的设备运行数据包括设备故障类型、遥测值、越线极值及越线时间。
步骤(2)所述的判断数据相似度以删除重复数据的方法是:将scada数据遥信信息按时序排列方式输入文本相似度计算模型,其计算表达式如下:
上式中,n(a,b)表示字符串a,b之间的最长公共子串长度;l(a)和l(b)分别表示字符串a和b的长度。
当2条信息长度一致且文本相似度为1时,删除1条数据。步骤(2)所述的数据分类是通过将上述数据处理后的数据,与变电站信息词库进行匹配,以此将数据按照变电站进行分类。
步骤(3)所述的事件折叠窗口的时间度设置为1小时,并通过事件折叠窗口对有序的scada数据进行事务集的划分,将属于同一事件窗口的scada数据称作一个事件,事件中的每个scada数据称作项。
步骤(4)中所述的数据属性离散化处理,是通过使用k-means算法对属性遥测值、越限极值和越线时间进行聚类处理,设置聚类中心的数目为3。优选处理,对于遥测值和越线极值将聚类中心值最小的称为“低”,最大的称为“高”,中间值称为“中”;对于越线时间将聚类中心值最小的称为“短”,最大的称为“长”,中间值称为“中”。然后将模糊化的属性与电网设备的简化字母结合组成简化的数据项,以此便于后续的处理。
步骤(5)中所述的支持度表达式为:
其中n代表事务集的总数,∑(x,y)代表包含{x,y}的事务集的个数。置信度表达式为:
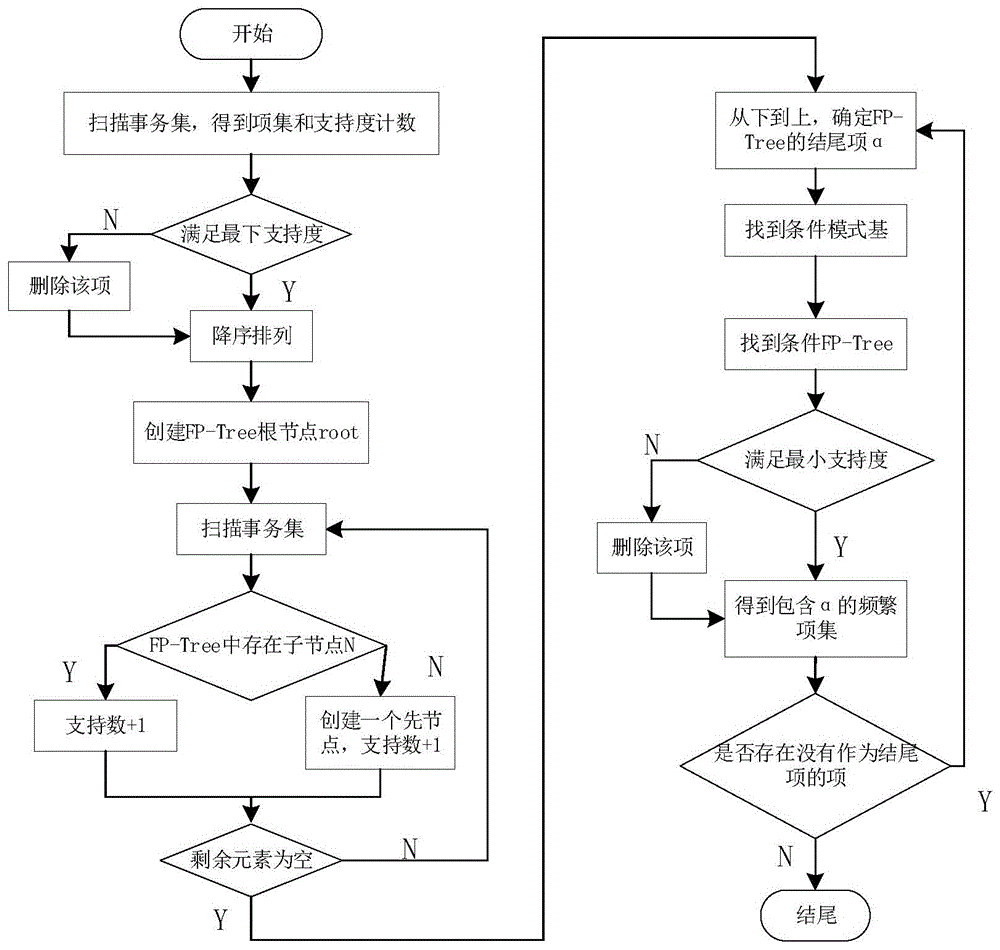
其中∑(x)代表包含{x}项的事务集的个数。并将支持度和置信度阈值设为0.5,通过扫描事务集并根据支持度和置信度来构建fp-tree,然后确定频繁项集和特征指标集。具体如下:
(51)先扫描一遍事务集,得到项数为1的包含属性的项目集,删除小于支持度的1项目集,同时删除原始事务集中的对应的项,然后将1项目集进行降序排列,并将原始事务集的每个事务中的项进行按1项目集的次数降序排列;
(52)再次扫描原始事务集,每扫描一条事务就将该事务中的每个项以结点的形式添加到以null为头结点的fp树中,并记录每个项的出现的次数,如果该项没有在fp树中出现则新创建节点,如果已出现则将该结点次数加1;
(53)根据(52)构建的fp树,从叶子节点向上找到条件模式基,以所查找的项为结尾的路径集合;
(54)每一条路径就是一条前缀路径,根据条件模式基找出后续项目集,并删除不满足支持度和置信度的项目集,得到频繁项集。
步骤(6)中对频繁项集的语义转化和分析,将根据步骤(5)中对scada数据的精简过程的反向过程,对频繁项集进行语义的填补,转化为具体的变电站的各故障事件,从而确定某故障发生后,可能发生的潜在故障事件,以此来帮助调度人员提前做好应对准备。
有益效果:与现有的apriori算法多次扫描数据库,每次利用候选频繁集产生频繁项集,本发明所述方法中fp-growth则利用树形结构,无需产生候选项集而是直接得到频繁项集,大大减少了访问数据库的次数,从而提高了算法的效率,而面对电网大量的数据,提高执行效率有利于调度人员快速做出决策,避免更大的损失。
附图说明
图1为本发明所述的fp-growth算法的流程图。
具体实施方式
为详细的说明本发明所公开的技术方案,下面结合说明书附图和具体实施例做进一步的阐述。
本发明所提供的一种电网故障中scada数据频繁项集挖掘方法,其实施流程如图1所示,所述方法基于fp-growth算法,包括以下步骤:
(1)采集电网故障的scada数据,包括电网故障设备信息、日期时间说明和设备运行数据;
(2)对步骤(1)采集的电网故障数据进行预处理,主要通过计算文本相似度来对重复性的数据进行删减,并将处理完的数据进行分类;
(3)将步骤(2)中经分类处理后的数据按照时间进行排序,并确定事件折叠窗口的时间度,并根据事件窗口将排序好的scada数据进行事件的划分,将同属于一个事件折叠窗口的scada数据化分为同一个事件;
(4)将步骤(3)中划分后的独立事件的属性进行离散化处理,同时将相同的电网设备使用相同的简化字母进行标识,然后将离散化后的属性与电网标识字母相结合构成了简化后的数据项;
(5)利用fp-growth算法对事件集进行频繁项集的挖掘,包括设定支持度和设定置信度,并构建fp-tree(频繁模式树),所述频繁项集为支持度大于等于最小支持度的集合;
(6)将步骤(5)得到的频繁项集进行语义转化,将离散化和模糊化的独立事件转化描述成具体的对应的变电站和遥测事件信息,因此可以通过转化后的描述信息来确定,电网各故障事件之间的相互关联关系,从而分析出某故障发生后,可能发生的潜在的故障事件,以此来帮助调度人员提前做好应对准备。
具体以某地区2020年5月份scada系统的遥测信息数据记录表,共6个属性,3159条信息。作为示例,表1只列了前几项数据。该数据记录表中包含了连续量、开关量和事件信息,使用数据库sqlserver2000进行管理。通过数据挖掘来确定故障发生的原因,为加快事故的分析处理和设备维修提供依据。
步骤1、完成数据的电网故障scada数据及变电站等设备数据的收集处理。
经由电网调度系统采集的电网scada数据,包括电网故障设备、电网数据采集日期时间和设备运行数据。作为示例,下面仅例举了前几项数据,如表1所示。
表1.scada数据事务集
步骤2、进行数据预处理,完成文本相似度计算,数据的去重、简化以及分类处理。
判断数据相似度以删除重复数据的方法是:将scada数据遥信信息按时序排列方式输入文本相似度计算模型:
当2条信息长度一致且文本相似度为1时,删除1条数据。上式中,n(a,b)表示字符串a,b之间的最长公共子串长度;l(a)和l(b)分别表示字符串a和b的长度;数据分类是通过,将上述数据处理后的数据,与变电站信息词库进行匹配,以此将数据按照变电站进行分类。
表2.分类后数据
步骤3、划分事件窗口
事件折叠窗口的时间度设置为1小时,并通过事件折叠窗口对有序的scada数据进行事务集的划分,将属于同一事件窗口的scada数据称作一个事件,事件中的每个scada数据称作项。
当一组事件发生在一个指定的时间段内,就可以被认为发生在一个相同的事件折叠窗口,以此减少数据的记录条数,时间度的确定主要依靠电网故障处理的经验,根据事件窗口将排序好的scada数据进行事件的划分,将同属于一个事件折叠窗口的scada数据化分为同一个事件。
步骤4、数据属性离散化处理
数据属性离散化处理,是通过使用k-means算法对属性遥测值、越限极值和越线时间进行聚类处理,设置聚类中心的数目为3。为了便于处理,对于遥测值和越线极值将聚类中心值最小的称为“低”,最大的称为“高”,中间值称为“中”;对于越线时间将聚类中心值最小的称为“短”,最大的称为“长”,中间值称为“中”。然后将模糊化的属性与电网设备的简化字母结合组成简化的数据项,以此便于后续的处理。
表3.简化数据表
例如,属性遥测值和越限极值将值低于3000的归为低、将值为3000-10000的归为中、将超过10000的值归为高;而对于越线时间而言将低于100000的归为短、将100000-1000000的归为中、将超过1000000的归为长。由此就将数据属性离散化了,之后将离散化后的属性与设备名称一起称为一个事件。
步骤5、完成fp-tree的构建
构建fp-tree需要对数据事务集进行扫描,将扫描结果中满足支持度和置信度的事务建立表格,然后扫描表来建立fp-tree。其中所述的支持度表达式为:
其中n代表事务集的总数,∑(x,y)代表包含{x,y}的事务集的个数。置信度表达式为:
其中∑(x)代表包含{x}项的事务集的个数。并将支持度和置信度阈值设为0.5,根据fp-tree来确定特征指标集。
步骤6、分析关联性
对频繁项集的语义转化和分析,将根据步骤(5)中对scada数据的精简过程的反向过程,对频繁项集进行语义的填补,转化为具体的变电站的各故障事件,从而确定某故障发生后,可能发生的潜在故障事件,以此来帮助调度人员提前做好应对准备。
表4.挖掘结果
表4中给出了使用fp-growth算法挖掘scada数据频繁项集的最终结果,表中可以看出,对于支持度和置信度满足要求的项集都作为算法的输出结果,对于表中的数据a(extreme为“高”,keeptime为“长”)=>b(extreme为“低”,keeptime为“短”),可解释为:在1号主变有功功率越线,并且越线的极值较高,保持时间很长时,将会导致211馈线短期的电流越线。
- 还没有人留言评论。精彩留言会获得点赞!