一种基于多层采样的主动学习溯源攻击方法
本发明涉及深度学习安全技术领域,尤其涉及一种基于多层采样的主动学习溯源攻击方法。
背景技术:
工业信息物理系统(industrialcyber-physicalsystems,icps)是一类应用于工业生产的控制系统的统称,它包含监视控制与数据采集系统(scada)、分布式控制系统(dcs)和其他一些常见于工业部门与关键基础设施的小型控制系统(如可编程逻辑控制器)等。它包含了化工化学、制药、水电能源、石油、天然气、离散制造、自动化生产、交通、航空航天等领域,在国家基础设施中扮演着至关重要的角色。
随着机器学习的发展,越来越多攻击者开始监听系统网络流量并开始建模分析,从设备的网络的独特属性开始攻击系统。而在实际icps中,攻击者面临的现实是:未标记攻击数据数目众多,易于获得;已标记的攻击数据数量稀少,难以获得。攻击者对于工位节点的状态情况并不能完全了解,那么攻击者需要通过监听icps的网络流量信息并利用构建的攻击模型实现源节点的溯源攻击。由于攻击者对进行攻击的icps缺乏认知并且为了在攻击的时候不被发现,那么攻击者需要以最小时间空间代价与最小步长完成溯源攻击。
已有的icps攻击研究中,主要采用随机攻击模型,其随机的方式不符合实际的攻击模型,并且如何在部署了众多工位节点的icps中溯源寻找真实源节点进行攻击也是攻击者所需要解决的。传统的监督学习算法无法适用于真实icps攻击情形,而具有学习能力的主动学习攻击模型可以自适应地进行数据采样、数据筛选和数据标注。
技术实现要素:
为建立智能化的溯源攻击模型,本发明提出了一种基于多层采样的主动学习溯源攻击方法(activelearningtrackingattackbasedonmulti-layersamplingstrategy,alta-mlss)来模拟工业信息物理系统的源节点被攻击问题。该方法中的模型是一种“随机游走+主动学习”的迭代学习模型,是攻击者在网络节点进行随机游走的基础上加入主动学习提升溯源游走性能的一种模型,采用ε-贪心策略随机游走策略。其中,在攻击模型初始阶段以较大概率进行随机游走和较小概率进行主动学习游走,随着迭代学习的进行,增大主动学习游走概率并降低随机游走概率。在迭代过程中,攻击模型利用基于多层采样策略的主动学习进行高效采样。主要解决在少量已标记训练样本数据的情况下分类器学习迭代的问题,通过增加训练样本数据的信息度、空间性和多样性,从而筛选出高价值样本,解决分类器在少量样本下的学习问题。为了解决在传统主动学习中可能选出离群点的问题,并且同时要避免在采样过程中选出和已有样本相似度极高的样本造成资源浪费,构建了基于样本信息度的多重采样策略算法;为了有效地表达整体样本空间的分布情况,构建了基于样本空间性采样策略算法;为了解决采样过程中存在的信息冗余问题,构建了基于样本多样性的采样策略算法。
本发明采用的技术方案如下:
一种基于多层采样的主动学习溯源攻击方法,包括以下步骤:
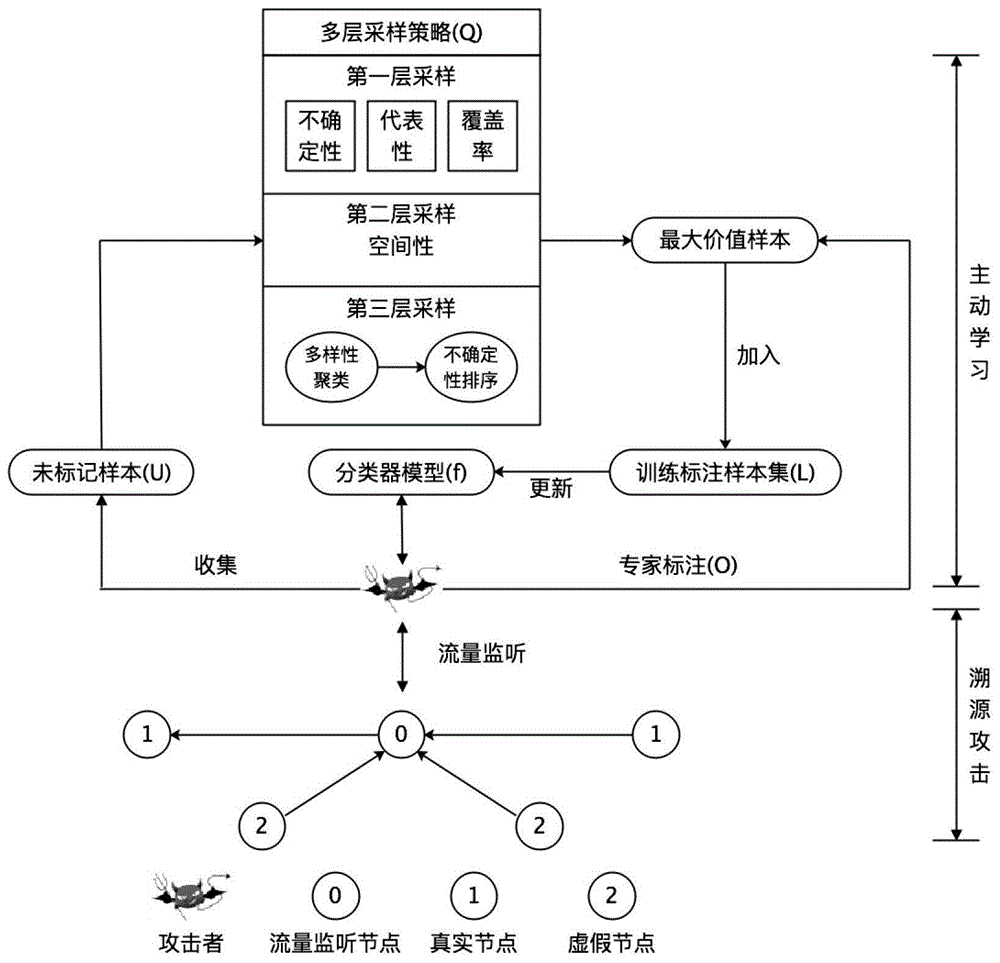
1)、构建基于多层采样策略的主动学习溯源攻击模型,整个多层采样策略的主动学习溯源攻击模型分为主动学习部分与溯源攻击部分,过程如下:
1.1):攻击者可以通过流量监控不断窃取系统设备的流量信息,并将其输入到攻击者自己构建的初始分类模型中;
1.2):攻击者利用已构建的主动学习分类器预测当前位置的下一步游走方向的概率分布情况,选择最高概率的游走方向进行移动,直至到达源节点位置;
1.3):攻击者在收集并存储在游走期间接收到的网络流量,并将其作为下一次主动学习的未标记样本集;
1.4):攻击者使用“多层采样策略”对未标记的数据集进行采样,选择出k个“价值”最大的样本;其中,在“多层采样策略”中,第一层样本采样将样本的不确定性、代表性和覆盖率作为样本价值的评价标准,第二层采样主要以样本的空间性作为评价标准,第三次采样中对第二层采样的候选样本进行聚类生成多个聚类簇,然后针对每个簇以样本的不确定性进行重新排序,最终选择出k个“价值”最大的预测集样本;过程如下:
1.4.1)为了解决在传统主动学习中可能选出离群点的问题,并且同时要避免在采样过程中选出和已有样本相似度极高的样本造成资源浪费,进而提高攻击模型的学习样本训练集对整个icps样本空间的覆盖率,本发明在step4中建立了一个基于样本信息度的多重采样策略算法,主要涉及对于采样样本的信息熵、代表性和覆盖率的信息度加权策略,信息度的定义式为:
i(x)=α×h(x)+β×r(x)+(1-α-β)×c(x)(1)
其中h(x)为样本x的信息熵,r(x)为样本x的代表性,c(x)为样本x的覆盖率,i(x)表示样本的信息度,结合了信息熵、代表性与覆盖率的加权值,α,β分别为信息熵和代表性的加权系数,α∈[0,1],β∈[0,1],α+β≤1。
样本x的信息熵h(x)是度量训练样本集中样本不确定性的最常用方法之一,计算公式如下:
其中,
样本x的代表性r(x)为样本x与训练样本集合中的其他样本的相似度,样本间的相似度采用标准化后的皮尔逊相关系数计算如下:
sim(xi,xj)=0.5+0.5×rp(xi,xj)(3)
样本代表性形式化定义为:
其中,rp(xi,xj)表示样本xi和xj的皮尔逊相关系数,sim(xi,xj)表示标准化到[0,1]的样本相似度,
样本x对样本整体空间的覆盖率c(x)为该样本x与训练样本集合中的其他样本的差异性。针对训练集中的两个不同样本xi和xj,分别计算这两个样本与样本训练集l的相似度,再对两者的系数向量sim(xi,l)和sim(xj,l),计算其余弦相似度cos(·),公式如下:
最后定义样本的覆盖率c(x)形式化定义为:
其中l为样本训练集,sim(xi,l)表示样本xi与训练集l的相似度,
1.4.2)为了在不降低攻击性能的情况下,最小化采样样本数量。本发明在step4中提出一个基于样本空间性采样策略算法,主要是一种采样样本数量大小的寻优算法。为了精确得到每次主动学习攻击时该选取的采样样本数量大小,结合统计学中的置信度概念设计算法。具体来说,主要先将样本信息度i(x)进行排序,再利用置信度计算两个相邻样本的信息度i(x)的偏差γd,并判断是否超过置信度阈值γ,公式如下:
其中,iu+1和iu为两个信息度相邻的样本。计算所有的样本偏差集合为γd。
当两个相邻样本的信息度偏差较大,说明该样本的信息度相对较大,那么将其加入采样样本中,即采样样本数量加一。综合所有偏差可得到最小化的采样样本数量n,具体公式如下:
由式(9)得到采样样本数量n后,攻击者可以针对无标签的训练样本集合筛选是信息度最高的n个训练样本作为下一个算法的输入样本集,公式如下:
基于样本空间性采样策略算法的具体算法步骤如下:
1.4.2.1):在上节可以得到无标签的网络流量样本集合的信息度集合z;
1.4.2.2):提取其中的样本信息度集合i,并进行排序处理;
1.4.2.3):初始化采样样本数量n;
1.4.2.4):遍历样本信息度集合i,根据式(9)计算相邻样本的信息度i(x)的偏差γd;
1.4.2.5):判断偏差γd是否小于置信度阈值γ,若是,则执行step6;
1.4.2.6):n=n+1;
1.4.2.7):取信息度最高的n个未标记训练样本为ucandicates。
1.4.3)考虑到ss-sps得到的未标记训练样本为ucandicates可能存在样本相似度较大,为了解决采样过程中存在的信息冗余问题。本发明step4提出一种基于样本多样性的采样策略算法(ss-sd)来确保筛选的训练样本的多样性。首先利用机器学习算法中的常用聚类算法对未标记训练样本为ucandicates进行聚类操作处理,可得到k个不同的簇,xc={xc1,xc2,…,xck}。再聚类后,不同簇之间的样本空间距离较大,不同簇的样本之间所含信息也差别较大。为了减小信息冗余并提高攻击性能,攻击者更加偏向去筛选不同簇内的样本,来保证筛选的样本集合具有较大的信息度并且具有多样性。在聚类得到k个不同的簇后,为了得到最高信息度的训练样本,本算法针对每个簇xck,对其中所含的训练样本进行信息度i(x)排序处理,再从每个簇xck中筛选出信息度最高的训练样本,从而形成最终的训练样本集合l,公式如下:
基于样本多样性的采样策略算法的具体算法步骤如下:
1.4.3.1):可以得到候选样本集合ucandicates;
1.4.3.2):将选样本集合ucandicates进行聚类得到k个不同的簇,为xc={xc1,xc2,…,xck};
1.4.3.3):初始化待标注样本集合δl;
1.4.3.4):遍历k个不同的簇xc={xc1,xc2,…,xck},计算得到每个簇中信息度最高的样本xi,将其加入待标注样本集合δl;
1.4.3.5):对待标注样本集合δl中的样本进行专家标注;
1.4.3.6):将待标注样本集合δl加入到专家标注样本集合l;
1.4.3.7):返回更新后的专家标注样本集合l。
1.5):攻击者凭借自身的专业知识和对系统的认知对预测集样本进行正确标记,并将其加入训练集,更新得到一个新的分类器;
1.6):重复上述过程,直至攻击者能以最快速度游走至源节点完成攻击。
2)、基于多层采样的主动学习溯源攻击算法,过程如下:
首先,攻击者在网络中随机一个节点作为初始节点。随后攻击者通过“随机游走+主动学习”的贪心算法方式进行溯源攻击,不断进行游走并收集流量数据。当它到达源节点后将收集到的游走数据作为下一次迭代学习的数据,再通过多层采样筛选出k个最大价值样本进行更新主动学习分类器。接着,攻击者从同一起始节点位置开始重新游走迭代更新,直至迭代至最大次数。
考虑到攻击者在攻击初步阶段,监听获取网络流量数据较少,进而高价值的样本数据更少,难以分辨虚假节点与真实节点,即分类器性能较差。随着攻击的进行,监听的网络流量数据越来越多,分类器模型性能也会越来越强。因此,提出的alta-mlss中嵌套了贪心算法,从而解决随机游走和主动学习在节点溯源方向上的冲突。在攻击过程的初始阶段,溯源攻击模型会以较大概率选择随机游走,但是随着攻击的进行,主动学习分类器决定节点溯源方向的概率会逐渐增大,进而提升攻击模型性能。
具体而言,溯源攻击的“随机游走+主动学习”中嵌套ε-greedy算法,在决策游走方向的时候有两种游走策略:1.节点随机游走;2.分类器根据现在的节点位置选择最大可能性的游走方向。考虑到在攻击初始阶段训练样本较少,分类器模型泛化能力较差,而在攻击后期阶段,分类器预测性能较好,攻击者能通过采样样本进行学习从而提高攻击性能。因此,在贪心系数ε的设置上从较大值开始,逐渐减小,符合本章提出的主动学习溯源攻击模型。在理想的情况下,当攻击模型中的分类器拥有了对虚假节点的准确辨别,那么攻击者便具备了最高效的溯源能力。
进一步,基于多层采样的主动学习溯源攻击模型算法的步骤如下:
2.1):初始化贪婪系数ε,初始化迭代次数episode为1;
2.2):初始化系统环境u,并初始化攻击节点的位置s;
2.3):将攻击节点位置s收集进u中;
2.4):随机(0,1)中的一个数,判断该数是否大于贪婪系数ε,若是,则执行步骤2.5),否则执行步骤2.6);
2.5):利用分类器f来得到当前攻击节点位置在当前的分类器f下游走概率最大的方向a;
2.6):根据当前的攻击节点位置s进行随机指定下一个游走方向a,游走方向皆为攻击节点的邻近节点;
2.7):攻击节点根据游走方向a进行游走,更新攻击节点s;
2.8):将更新后的攻击节点位置s收集进u中;
2.9):判断攻击代理a下的攻击节点位置s是否到达源节点,若是,结束循环,执行步骤2.10),否则继续执行步骤2.4)~2.8);
2.10):判断贪婪系数ε是否大于0.05,若是,则执行步骤2.11),否则执行步骤2.12);
2.11):更新贪婪系数ε为ε-δε;
2.12):利用基于样本信息度的多重采样策略算法对游走过程中收集的网络流量数据u根据样本信息度进行多重采样处理得到无标签的网络流量样本集合的信息度集合z;
2.13):利用基于样本空间性的采样策略算法对无标签的网络流量样本集合的信息度集合z根据样本空间性进行采样处理得到候选样本集合u_candicates;
2.14):利用基于样本多样性的采样策略算法对候选样本集u_candicates根据样本多样性进行采样处理并进行专家标注后得到专家标注样本集合l;
2.15):利用专家标注样本集合l更新分类器;
2.16):更新攻击代理a;
2.17):判断迭代次数episode是否大于最大迭代次数i_max,若是,结束算法,否则执行步骤2.2)~2.16)。
本发明的有益效果为:构建了基于样本空间性采样策略算法,可以有效地表达整体样本空间的分布情况;构建了基于样本多样性的采样策略算法,解决了采样过程中存在的信息冗余问题;本发明提出的主动学习的溯源攻击比随机游走的溯源攻击具有更优的溯源攻击能力,提出的算法比其他主动学习算法具有较优的采样性能,从而提高溯源攻击的攻击效果。
附图说明
图1是本发明基于多层采样策略的主动学习溯源攻击模型的整体框架图;
图2是本发明基于样本空间性的采样策略算法的算法流程图;
图3是本发明基于样本多样性的采样策略算法的算法流程图;
图4是本发明基于多层采样的主动学习溯源攻击算法的算法流程图;
具体实施方式:
下面结合附图和实施例对本发明做进一步详细描述,需要指出的是,以下所述实施例旨在便于对本发明的理解,而对其不起任何限定作用。
参照图1~图4,一种基于多层采样的主动学习溯源攻击方法,包括以下步骤:
1)、构建基于多层采样策略的主动学习溯源攻击模型,整个多层采样策略的主动学习溯源攻击模型分为主动学习部分与溯源攻击部分,过程如下:
1.1):攻击者可以通过流量监控不断窃取系统设备的流量信息,并将其输入到攻击者自己构建的初始分类模型中;
1.2):攻击者利用已构建的主动学习分类器预测当前位置的下一步游走方向的概率分布情况,选择最高概率的游走方向进行移动,直至到达源节点位置;
1.3):攻击者在收集并存储在游走期间接收到的网络流量,并将其作为下一次主动学习的未标记样本集;
1.4):攻击者使用“多层采样策略”对未标记的数据集进行采样,选择出k个“价值”最大的样本;其中,在“多层采样策略”中,第一层样本采样将样本的不确定性、代表性和覆盖率作为样本价值的评价标准,第二层采样主要以样本的空间性作为评价标准,第三次采样中对第二层采样的候选样本进行聚类生成多个聚类簇,然后针对每个簇以样本的不确定性进行重新排序,最终选择出k个“价值”最大的预测集样本;过程如下:
1.4.1)为了解决在传统主动学习中可能选出离群点的问题,并且同时要避免在采样过程中选出和已有样本相似度极高的样本造成资源浪费,进而提高攻击模型的学习样本训练集对整个icps样本空间的覆盖率,本发明在step4中建立了一个基于样本信息度的多重采样策略算法,主要涉及对于采样样本的信息熵、代表性和覆盖率的信息度加权策略,信息度的定义式为:
i(x)=α×h(x)+β×r(x)+(1-α-β)×c(x)(1)
其中h(x)为样本x的信息熵,r(x)为样本x的代表性,c(x)为样本x的覆盖率,i(x)表示样本的信息度,结合了信息熵、代表性与覆盖率的加权值,α,β分别为信息熵和代表性的加权系数,α∈[0,1],β∈[0,1],α+β≤1。
样本x的信息熵h(x)是度量训练样本集中样本不确定性的最常用方法之一,计算公式如下:
其中,
样本x的代表性r(x)为样本x与训练样本集合中的其他样本的相似度,样本间的相似度采用标准化后的皮尔逊相关系数计算如下:
sim(xi,xj)=0.5+0.5×rp(xi,xj)(3)
样本代表性形式化定义为:
其中,rp(xi,xj)表示样本xi和xj的皮尔逊相关系数,sim(xi,xj)表示标准化到[0,1]的样本相似度,
样本x对样本整体空间的覆盖率c(x)为该样本x与训练样本集合中的其他样本的差异性。针对训练集中的两个不同样本xi和xj,分别计算这两个样本与样本训练集l的相似度,再对两者的系数向量sim(xi,l)和sim(xj,l),计算其余弦相似度cos(·),公式如下:
最后定义样本的覆盖率c(x)形式化定义为:
其中l为样本训练集,sim(xi,l)表示样本xi与训练集l的相似度,
1.4.2)为了在不降低攻击性能的情况下,最小化采样样本数量。本发明在step4中提出一个基于样本空间性采样策略算法,主要是一种采样样本数量大小的寻优算法。为了精确得到每次主动学习攻击时该选取的采样样本数量大小,结合统计学中的置信度概念设计算法。具体来说,主要先将样本信息度i(x)进行排序,再利用置信度计算两个相邻样本的信息度i(x)的偏差γd,并判断是否超过置信度阈值γ,公式如下:
其中,iu+1和iu为两个信息度相邻的样本。计算所有的样本偏差集合为γd。
当两个相邻样本的信息度偏差较大,说明该样本的信息度相对较大,那么将其加入采样样本中,即采样样本数量加一。综合所有偏差可得到最小化的采样样本数量n,具体公式如下:
由式(9)得到采样样本数量n后,攻击者可以针对无标签的训练样本集合筛选是信息度最高的n个训练样本作为下一个算法的输入样本集,公式如下:
基于样本空间性采样策略算法的具体算法步骤如下:
1.4.2.1):在上节可以得到无标签的网络流量样本集合的信息度集合z;
1.4.2.2):提取其中的样本信息度集合i,并进行排序处理;
1.4.2.3):初始化采样样本数量n;
1.4.2.4):遍历样本信息度集合i,根据式(9)计算相邻样本的信息度i(x)的偏差γd;
1.4.2.5):判断偏差γd是否小于置信度阈值γ,若是,则执行step6;
1.4.2.6):n=n+1;
1.4.2.7):取信息度最高的n个未标记训练样本为ucandicates。
1.4.3)考虑到ss-sps得到的未标记训练样本为ucandicates可能存在样本相似度较大,为了解决采样过程中存在的信息冗余问题。本发明step4提出一种基于样本多样性的采样策略算法(ss-sd)来确保筛选的训练样本的多样性。首先利用机器学习算法中的常用聚类算法对未标记训练样本为ucandicates进行聚类操作处理,可得到k个不同的簇,xc={xc1,xc2,…,xck}。再聚类后,不同簇之间的样本空间距离较大,不同簇的样本之间所含信息也差别较大。为了减小信息冗余并提高攻击性能,攻击者更加偏向去筛选不同簇内的样本,来保证筛选的样本集合具有较大的信息度并且具有多样性。在聚类得到k个不同的簇后,为了得到最高信息度的训练样本,本算法针对每个簇xck,对其中所含的训练样本进行信息度i(x)排序处理,再从每个簇xck中筛选出信息度最高的训练样本,从而形成最终的训练样本集合l,公式如下:
基于样本多样性的采样策略算法的具体算法步骤如下:
1.4.3.1):可以得到候选样本集合ucandicates;
1.4.3.2):将选样本集合ucandicates进行聚类得到k个不同的簇,为xc={xc1,xc2,…,xck};
1.4.3.3):初始化待标注样本集合δl;
1.4.3.4):遍历k个不同的簇xc={xc1,xc2,…,xck},计算得到每个簇中信息度最高的样本xi,将其加入待标注样本集合δl;
1.4.3.5):对待标注样本集合δl中的样本进行专家标注;
1.4.3.6):将待标注样本集合δl加入到专家标注样本集合l;
1.4.3.7):返回更新后的专家标注样本集合l。
1.5):攻击者凭借自身的专业知识和对系统的认知对预测集样本进行正确标记,并将其加入训练集,更新得到一个新的分类器;
1.6):重复上述过程,直至攻击者能以最快速度游走至源节点完成攻击。
2)、基于多层采样的主动学习溯源攻击算法,过程如下:
首先,攻击者在网络中随机一个节点作为初始节点,随后攻击者通过“随机游走+主动学习”的贪心算法方式进行溯源攻击,不断进行游走并收集流量数据,当它到达源节点后将收集到的游走数据作为下一次迭代学习的数据,再通过多层采样筛选出k个最大价值样本进行更新主动学习分类器,接着,攻击者从同一起始节点位置开始重新游走迭代更新,直至迭代至最大次数。
考虑到攻击者在攻击初步阶段,监听获取网络流量数据较少,进而高价值的样本数据更少,难以分辨虚假节点与真实节点,即分类器性能较差。随着攻击的进行,监听的网络流量数据越来越多,分类器模型性能也会越来越强。因此,提出的alta-mlss中嵌套了贪心算法,从而解决随机游走和主动学习在节点溯源方向上的冲突。在攻击过程的初始阶段,溯源攻击模型会以较大概率选择随机游走,但是随着攻击的进行,主动学习分类器决定节点溯源方向的概率会逐渐增大,进而提升攻击模型性能。
具体而言,溯源攻击的“随机游走+主动学习”中嵌套ε-greedy算法,在决策游走方向的时候有两种游走策略:1.节点随机游走;2.分类器根据现在的节点位置选择最大可能性的游走方向。考虑到在攻击初始阶段训练样本较少,分类器模型泛化能力较差,而在攻击后期阶段,分类器预测性能较好,攻击者能通过采样样本进行学习从而提高攻击性能。因此,在贪心系数ε的设置上从较大值开始,逐渐减小,符合本章提出的主动学习溯源攻击模型。在理想的情况下,当攻击模型中的分类器拥有了对虚假节点的准确辨别,那么攻击者便具备了最高效的溯源能力。
进一步,基于多层采样的主动学习溯源攻击模型算法的步骤如下:
2.1):初始化贪婪系数ε,初始化迭代次数episode为1;
2.2):初始化系统环境u,并初始化攻击节点的位置s;
2.3):将攻击节点位置s收集进u中;
2.4):随机(0,1)中的一个数,判断该数是否大于贪婪系数ε,若是,则执行步骤2.5),否则执行步骤2.6);
2.5):利用分类器f来得到当前攻击节点位置在当前的分类器f下游走概率最大的方向a;
2.6):根据当前的攻击节点位置s进行随机指定下一个游走方向a,游走方向皆为攻击节点的邻近节点;
2.7):攻击节点根据游走方向a进行游走,更新攻击节点s;
2.8):将更新后的攻击节点位置s收集进u中;
2.9):判断攻击代理a下的攻击节点位置s是否到达源节点,若是,结束循环,执行步骤2.10),否则继续执行步骤2.4)~2.8);
2.10):判断贪婪系数ε是否大于0.05,若是,则执行步骤2.11),否则执行步骤2.12);
2.11):更新贪婪系数ε为ε-δε;
2.12):利用基于样本信息度的多重采样策略算法对游走过程中收集的网络流量数据u根据样本信息度进行多重采样处理得到无标签的网络流量样本集合的信息度集合z;
2.13):利用基于样本空间性的采样策略算法对无标签的网络流量样本集合的信息度集合z根据样本空间性进行采样处理得到候选样本集合u_candicates;
2.14):利用基于样本多样性的采样策略算法对候选样本集u_candicates根据样本多样性进行采样处理并进行专家标注后得到专家标注样本集合l;
2.15):利用专家标注样本集合l更新分类器;
2.16):更新攻击代理a;
2.17):判断迭代次数episode是否大于最大迭代次数i_max,若是,结束算法,否则执行步骤2.2)~2.16)。
以下利用本发明的基于多层采样的主动学习溯源攻击方法对nsl-kdd数据集进行具体的试验,采用nsl-kdd数据集中的基本特征与流量特征两类网络流量数据信息来模拟攻击者监听到的网络流量数据信息。
如图2所示,为本实施例采用的基于样本空间性的采样策略算法的算法流程图。首先从无标签的网络流量样本集合的信息度集合z中筛选出信息度集合i,并进行排序;其次初始化采样样本数量n,遍历样本信息度集合i,依据相邻样本的信息度偏差是否小于置信度阈值来决定是否对采样样本数量n进行加一操作,最后筛选信息度最高的n个未标记训练样本为ucandicates。
如图3所示,为本实施例采用的基于样本多样性的采样策略算法的算法流程图。首先将候选样本集合进行聚类得到k个簇为xc,其次将计算得到每个簇中信息度最高的样本进行集合,最后将采样样本进行专家标注,并输出所有标注的样本集合。
如图4所示,为本实施例采用的基于多层采样的主动学习溯源攻击算法的算法流程图。
本实施例采用的基于多层采样的主动学习溯源攻击方法在虚假节点数量占比为50%时的性能分析效果展示。主要针对在20×20网格的icps节点模型下布置占比为50%的虚假节点数量进行实验,icps攻击者构建主动学习溯源攻击模型进行攻击,其溯源攻击游走步长随着学习迭代次数不断减小,并且大幅度低于无学习能力的随机游走。分别从f值、准确率和精确率三个方面针对分类器性能进行分析,从图中可以看出,主动学习的溯源攻击优于传统的随机游走攻击模型,并且溯源攻击的性能逼近理想的溯源游走步长。此外,本发明提出的基于多层采样的主动学习溯源攻击(alta-mlss)算法在各类虚假节点数量占比下的溯源游走性能和分类器性能都高于其他三种主动学习算法。
以上所述的实施例对本发明的技术方案和有益效果进行了详细说明,应理解的是以上所述仅为本发明的具体实施例,并不用于限制本发明,凡在本发明的原则范围内所做的任何修改、补充和等同替换,均应包含在本发明的保护范围之内。
- 该技术已申请专利。仅供学习研究,如用于商业用途,请联系技术所有人。
- 技术研发人员:洪榛;叶蕾;郑德华;安曼
- 技术所有人:浙江工业大学
- 我是此专利的发明人
- 该领域下的技术专家
- 如您需求助技术专家,请点此查看客服电话进行咨询。
- 1、李老师:1.计算力学 2.无损检测
- 2、毕老师:机构动力学与控制
- 3、袁老师:1.计算机视觉 2.无线网络及物联网
- 4、王老师:1.计算机网络安全 2.计算机仿真技术
- 5、王老师:1.网络安全;物联网安全 、大数据安全 2.安全态势感知、舆情分析和控制 3.区块链及应用
- 如您是高校老师,可以点此联系我们加入专家库。
- 还没有人留言评论。精彩留言会获得点赞!