移动端CPU实时多功能人脸检测方法与流程
本发明属于人脸识别技术领域,具体涉及一种实时多功能人脸检测方法。
背景技术:
人脸识别系统以人脸识别技术为核心,是一项新兴的生物识别技术,是当今国际科技领域攻关的高精尖技术。它广泛采用区域特征分析方法,融合了计算机图像处理技术与生物统计学原理于一体,利用计算机图像处理技术从视频中提取人像特征点,利用生物统计学的原理进行分析建立数学模型,具有广阔的发展前景。人脸检测是自动人脸识别系统中的一个关键环节。但是由于人脸具有相当复杂的细节变化,不同的外貌如脸形、肤色等,不同的表情如眼、嘴的开与闭等;口罩遮挡等,这些内在因素及外在因素的变化使得人脸检测成为人脸识别系统中一个复杂的具有挑战性的模式检测问题。
尽管人们已经对基于卷积神经网络的人脸检测算法进行了广泛的研究,但是对于移动设备上的人脸检测算法来说,无法在移动端达到实时效果,也无法在只有cpu的情况下达到实时检测效果。
另外,现有人脸检测时,通常检测功能单一,没有关键点和口罩功能的检测,不能为后续工作提供更多关键数据。
技术实现要素:
本发明针对现有的人脸检测无法在移动端只有cpu的情况下达到实时检测,且检测功能较为单一的技术问题,目的在于提供一种移动端cpu实时多功能人脸检测方法。
移动端cpu实时多功能人脸检测方法,包括:
将图片放入预设的检测器中进行预测,通过所述检测器的主干网络中四个不同卷积层得到的特征与多个尺寸的锚点结合,进行人脸检测、人脸关键点检测和口罩识别,得到人脸框预测值、人脸关键点和口罩识别结果;
将所述人脸框预测值进行解码操作,转换为边界框的真实位置,将所述人脸关键点进行解码操作,转换为关键点的真实位置;
采用阈值为0.4的非极大值抑制算法消除重叠检测框,得到最终的人脸检测框、人脸关键点和口罩识别结果,包括检测框左上角坐标、右下角坐标、两只眼睛坐标、鼻子坐标、一对嘴角坐标和是否戴口罩置信度的信息。
可选的,所述将图片放入预设的检测器中进行预测之前,包括:
对图片进行预处理操作,所述预处理操作包括调整图像大小、标准化。
可选的,所述将图片放入预设的检测器中进行预测之前,还包括:
向所述检测器加载预设的预训练网络参数,根据预设的锚点的尺寸及长宽比例,生成默认锚点;
通过预设的数据集对所述检测器进行训练,得到训练后的检测器;
所述检测器包括主干网络、预测层和多任务损失层。
可选的,所述通过预设的数据集对所述检测器进行训练,得到训练后的检测器,包括:
采集包括未遮挡数据和遮挡数据作为数据集,将所述数据集中的bgr图片转换为yuv格式,进行数据增强,得到增强后的数据集;
采用动量为0.9,权重衰减因子为0.0005的随机优化算法进行网络训练,所述随机优化算法采用难样本挖掘的方式减少正负样本之间的不平衡,在训练的前100轮,初始化学习率设置为10-3,在之后的50轮和100轮各降低10倍,在训练期间,首先将每个预测值与最佳的jaccard重叠锚点进行匹配,之后将锚点匹配到具有高于0.35阈值的jaccard重叠人脸。
可选的,所述未遮挡数据为未佩戴口罩时的人脸图片,所述遮挡数据为佩戴口罩时的人脸图片,所述遮挡数据大于所述未遮挡数据。
可选的,所述进行数据增强,包括:
通过对所述数据集中的图片采用颜色失真、增加亮度对比、随机裁剪、水平翻转和变换通道中的至少一种或多种方式的组合增加数据以防止模型过拟合。
可选的,所述增强亮度对比采用的策略为降低目标框内的亮度,增加目标框外的亮度实现。
可选的,所述将图片放入预设的检测器中进行预测,通过所述检测器的主干网络中四个不同卷积层得到的特征与多个尺寸的锚点结合,进行人脸检测、人脸关键点检测和口罩识别,得到人脸框预测值、人脸关键点和口罩识别结果,包括:
将图片放入训练后的所述检测器中进行预测,预测时将所述主干网络中的第8、11、13和15个卷积层中的特征分别输入到各个预测层进行人脸框、人脸关键点定位和口罩识别操作;
对于每个锚点,使用相对其坐标的4个偏移量以及n个用于分类的分数进行表示,n=2;在检测器训练时针对每个锚点,最小化式多任务损失函数:
其中lobj为交叉熵损失函数检测锚点是否包含目标分类,pi为锚点有目标的概率,如果锚点包含目标,则
可选的,采用10到256像素的锚点来匹配相应的有效感受野的最小尺寸,每个用于检测特征的锚点尺寸分别设为(10,16,24)、(32,48)、(64,96)和(128,192,256)。
可选的,所述将所述人脸框预测值进行解码操作,转换为边界框的真实位置,将所述人脸关键点进行解码操作,转换为关键点的真实位置,包括:
将所述检测器得到的人脸框预测值l=(lcx,lcy,lw,lh)进行解码操作,转化为边界框的真实位置b=(bcx,bcy,bw,bh):
bcx=lcxdw+dcx,bcy=lcydh+dcy;
bw=dwexp(lw),bh=dhexp(lh);
将所述检测器得到的人脸关键点预测值
其中,d=(dcx,dcy,dw,dh)表示生成的默认锚点。
本发明的积极进步效果在于:本发明采用移动端cpu实时多功能人脸检测方法,具有如下显著优点:
1、能在移动端只有cpu的情况下达到实时检测效果;
2、在实时检测的前提下可以同时检测出人脸框、人脸关键点和是否戴口罩的检测结果;
3、在戴口罩情况下准确检测出人脸的关键点;
4、使用数据增强技术使得模型更加鲁棒,在光照较强的情况下也可以很好的检测人脸框、人脸关键点和戴口罩情况。
附图说明
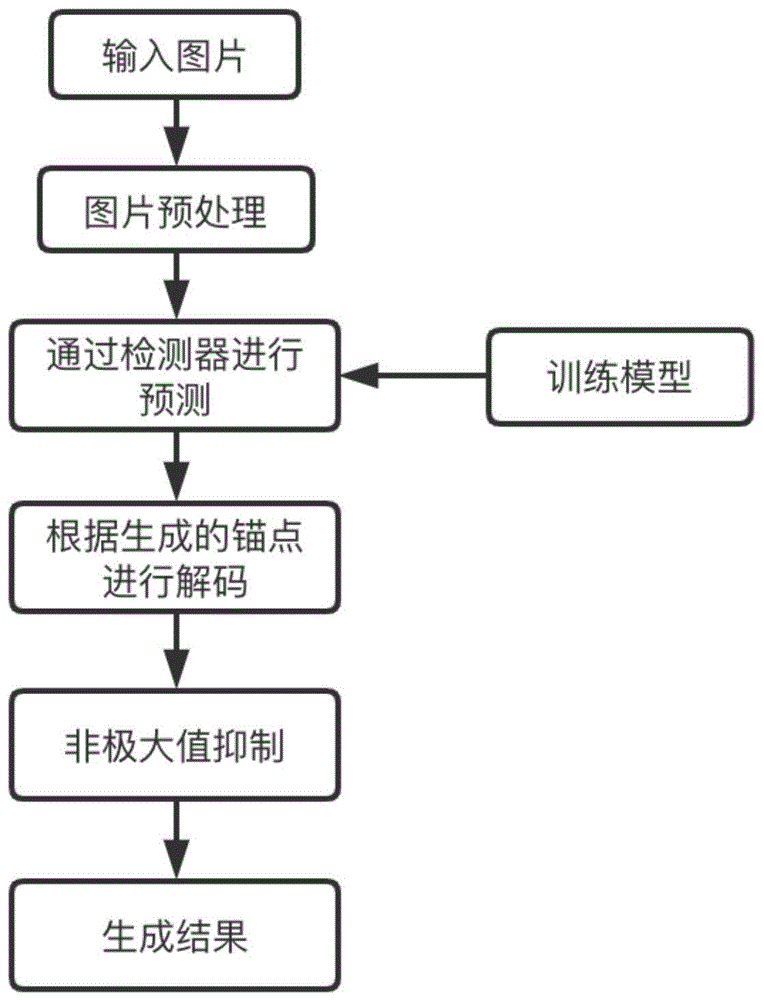
图1为本发明的一种流程示意图;
图2为本发明检测器的一种网络结构图;
图3为本发明的一种检测结果示意图;
图4为本发明的另一种检测结果示意图。
具体实施方式
为了使本发明实现的技术手段、创作特征、达成目的与功效易于明白了解,下面结合具体图示进一步阐述本发明。
参照图1,移动端cpu实时多功能人脸检测方法,包括:
s1,输入图片,并针对图片进行预处理操作。
本步骤中可以从采集端直接获取图片,或通过输入接口输入图片。对图片进行预处理操作包括调整图像大小、标准化。
s2,通过检测器进行预测:将图片放入预设的检测器中进行预测,通过检测器的主干网络中四个不同卷积层得到的特征与多个尺寸的锚点结合,进行人脸检测、人脸关键点检测和口罩识别,得到人脸框预测值、人脸关键点和口罩识别结果。
本步骤在将图片放入预设的检测器中进行预测之前,还包括:
向检测器加载预设的预训练网络参数,根据预设的锚点的尺寸及长宽比例,生成默认锚点,该默认锚点即为:d=(dcx,dcy,dw,dh)。
其中,参照图2,检测器包括主干网络、预测层和多任务损失层。主干网络中包含有15个卷积层,4个预测层,1个多任务损失层。15个卷积层中包含一个卷积模块1、十三个卷积模块2、一个卷积模块3。卷积模块1由卷积、归一化及激活层组成。卷积模块2由两组模块组成,分别为组卷积、归一化及激活层组成的第一模块,卷积、归一化及激活层组成的第二模块。卷积模块3由两组模块组成,分别为组卷积、归一化及激活层组成的第一模块,只含卷积的第二模块。本步骤将主干网络中的第8、11、13和15个卷积层中的特征分别输入到各个预测层进行人脸框、人脸关键点定位和口罩识别操作,各个预测层输入多任务损失层,以实现多个检测结果的拟合。
通过预设的数据集对检测器进行训练,得到训练后的检测器。检测器的算法优选采用pytorch开源深度学习库实现。在训练时,包括如下过程:
s201,数据采集:采集包括未遮挡数据和遮挡数据作为数据集。
未遮挡数据为未佩戴口罩时的人脸图片,遮挡数据为佩戴口罩时的人脸图片,遮挡数据大于未遮挡数据,优选大部分为戴口罩数据集。数据采集时,可以采用人工加工过的widerface未遮挡数据和mafa遮挡数据。
s202,数据处理及增强:将数据集中的bgr图片转换为yuv格式,进行数据增强,得到增强后的数据集。
在进行数据增强时包括通过对数据集中的图片采用颜色失真、增加亮度对比、随机裁剪、水平翻转和变换通道中的至少一种或多种方式的组合增加数据以防止模型过拟合。
其中,变换通道可以是从yuv格式转换为yyy格式。增强亮度对比采用的策略为降低目标框内的亮度,增加目标框外的亮度实现。
通过直接训练yuv和yyy格式的图片,避免移动端将yuv图片通过线性变换转成bgr时的时间浪费,使得模型在移动端只有cpu的情况下可以达到超实时检测的效果,并且可以实现一个模型同时检测红外图和yuv图的目的。上述数据增强的多种组合方式,使得模型在光照情况下可以更加鲁棒。
s203,训练:采用动量为0.9,权重衰减因子为0.0005的随机优化算法进行网络训练,随机优化算法采用难样本挖掘的方式减少正负样本之间的不平衡,在训练的前100轮,初始化学习率设置为10-3,在之后的50轮和100轮各降低10倍,在训练期间,首先将每个预测值与最佳的jaccard重叠锚点进行匹配,之后将锚点匹配到具有高于0.35阈值的jaccard重叠人脸。
通过上述设计后,得到训练后的检测器,则可进行图片的预测。
预测时,将主干网络中的第8、11、13和15个卷积层中的特征分别输入到各个预测层进行人脸框、人脸关键点定位和口罩识别操作。
对于每个锚点,使用相对其坐标的4个偏移量以及n个用于分类的分数进行表示,n=2;在检测器训练时针对每个锚点,最小化式多任务损失函数:
其中lobj为交叉熵损失函数检测锚点是否包含目标分类,pi为锚点有目标的概率,如果锚点包含目标,则
其中,采用10到256像素的锚点来匹配相应的有效感受野的最小尺寸,每个用于检测特征的锚点尺寸分别设为(10,16,24)、(32,48)、(64,96)和(128,192,256)。
本发明通过上述设计后,实现了端到端的口罩识别目的,无需增加额外的分类器单独识别是否戴口罩,在移动端只有cpu的情况下可以避免对图片旋转、抠图等操作,节省时间。另外,本发明针对戴口罩人脸的关键点检测做出优化,在戴口罩情况下,训练时只对可见的眼部特征损失进行优化。
s3,根据生成的锚点进行解码:将人脸框预测值进行解码操作,转换为边界框的真实位置,将人脸关键点进行解码操作,转换为关键点的真实位置。
具体的解码过程为:
将检测器得到的人脸框预测值l=(lcx,lcy,lw,lh)进行解码操作,转化为边界框的真实位置b=(bcx,bcy,bw,bh):
bcx=lcxdw+dcx,bcy=lcydh+dcy;
bw=dwexp(lw),bh=dhexp(lh);
将检测器得到的人脸关键点预测值
其中,d=(dcx,dcy,dw,dh)表示步骤s2生成的默认锚点。
s4,非极大值抑制:采用阈值为0.4的非极大值抑制算法消除重叠检测框,得到最终的人脸检测框、人脸关键点和口罩识别结果,包括检测框左上角坐标、右下角坐标、两只眼睛坐标、鼻子坐标、一对嘴角坐标和是否戴口罩置信度的信息。
实施例一:
在人脸识别场景中,将如图3所示的图片通过预处理的方式调整图像大小,使其标准化。将标准化后的图片格致转换为yuv格式,并采用数据增强处理后,输入已训练完成的检测器中进行预测。预测时的网络模型如图2中所示,多任务损失函数中,锚点包含目标,
实施例二:
将如图4所示的图片通过预处理的方式调整图像大小,使其标准化。将标准化后的图片格致转换为yuv格式,并采用数据增强处理后,输入已训练完成的检测器中进行预测。预测时的网络模型如图2中所示,多任务损失函数中,锚点包含目标,
以上显示和描述了本发明的基本原理、主要特征和本发明的优点。本行业的技术人员应该了解,本发明不受上述实施例的限制,上述实施例和说明书中描述的只是说明本发明的原理,在不脱离本发明精神和范围的前提下,本发明还会有各种变化和改进,这些变化和改进都落入要求保护的本发明范围内。本发明要求保护范围由所附的权利要求书及其等效物界定。
- 还没有人留言评论。精彩留言会获得点赞!