一种基于循环矩阵的行人重识别方法与流程
[0001]
本发明属于人工智能技术领域,涉及到计算机视觉,特别涉及到一种基于循环矩阵的行人重识别方法。
背景技术:
[0002]
近年来,行人重识别变得越来越火,主要是因为它的应用场景很广阔。公共场所安装监控摄像保证了个人财产生命的安全,在公共交通中,查找违法车辆,追踪车辆轨迹;在大型广场中,查找失踪儿童,帮扶孤寡老人等等,现在都离不开行人重识别技术。
[0003]
然而行人重识别技术在很多方面都面临了挑战,例如行人之间的遮挡问题,由于摄像头安装角度,导致行人图片的不对齐问题,摄像头参数不一致,行人姿态发生变化等等问题,都是现在主要的研究挑战。
技术实现要素:
[0004]
本发明要解决的技术问题是:弥补上述现有方法的不足,提出一种基于循环矩阵的行人重识别方法,解决了行人图片中不对齐的问题。
[0005]
本发明的技术方案:
[0006]
一种基于循环矩阵的行人重识别方法,步骤如下:
[0007]
(1)首先,划分行人重识别数据集market1501,一半数据分为训练集数据,一半数据为测试集数据;
[0008]
在训练集中取anchor为待预测图片,再选取与之具有相同身份的人的图片为正样本图片,与之身份不同的人的图片为负样本,这样三张图片组成一个三元组,作为特征网络的输入;
[0009]
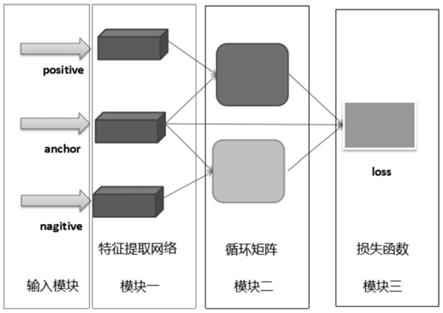
(2)三元组图片的每一张图片都是一张彩色图,有三个通道信息,大小是3*256*128;图片通过大小为7*7卷积核进行特征提取,之后是一个最大池化层来降低图片分辨率;随后经过四个卷积块结构,每一个块结构中都是由三个卷积层构成,卷积核大小分别为1*1,3*3和1*1;在每一个卷积核之后都跟随着一个bn层和relu层,其中bn层是batchnorm层,relu层是激活函数层;经过上述网络特征的提取之后,生成了特征大小变成w*h*c的三维特征图,其中w表示特征图的宽度,h表示特征图的高度,c表示特征图的通道数;
[0010]
(3)上述生成的三维特征图经过循环矩阵大小变为(w*h)*(w*h)*c;循环矩阵的公式为,x=f*diag(x^)*f
h
,其中f表示离散傅里叶矩阵,f
h
表示离散傅里叶矩阵的共轭转置矩阵,x表示输入到循环矩阵的三维特征,diag表示是矩阵取对角矩阵的操作,这里我们选取当时4个点和8个点的离散傅里叶矩阵;循环矩阵是一个方阵,其中第一行,或者第一列为原来特征向量的原始向量,第二行向量是第一行向量向右平移一个单位,这是一个一维特征向量的循环矩阵;二维特征向量是一维特征向量循环矩阵的延伸,这其中用到了块循环矩阵;块循环矩阵把矩阵分块,每一块放在一起进行上下左右平移构成二维循环矩阵;经过循环矩阵后,在通道层次上进行降维归一化,我们这里选取通道上的平均池化技术,对于(w*
h)*(w*h)上的每一个点跨通道加和再除以通道数,最后对于每一个三元组图片都会变为(w*h)*(w*h)大小的二维特征图;
[0011]
(4)三元组图片经过循环矩阵后,选取最不相近正样本对和最相近负样本对进行最后的损失函数计算;首先,anchor最后生成的(w*h)*(w*h)大小的特征图,正样本和负样本分辨率与之相同;三元组图片特征图的每一行或者每一列都是原来图片位置的平移结果;因此可以解决行人重识别中人像不对齐的问题;其次,我们要把anchor与正样本组成正样本对,anchor与负样本组成负样本对;在正样本对中,我们取两个特征图进行矩阵相乘,生成的矩阵大小也是(w*h)*(w*h),其上每一个点(i,j)表示anchor的第i行与正样本对第j列相乘的结果,表示两种平移之后相似度的一种度量;这样我们在正样本对中选取结果最小正样本对进行训练,可以训练出鲁棒的特征;同理在负样本对中,anchor和负样本两个特征矩阵相乘,生成的矩阵中的每一个点也代表平移之后的一种相似性度量,不过在负样本中我们选取了相似度最大的负样本参与训练,其原因和正样本相同,都是为了训练出更鲁棒的特征;
[0012]
(5)选择的损失函数是难样本采样的三元组损失函数;难样本采样三元组损失函数是输入一次性输入三个特征,包络正样本对和负样本对;通过三元组损失函数,它使正样本对之间距离变小,使负样本对之间变大;而从达到聚类的效果,类内间距变小,类间距离变大;在具体选择样本的时候,我们选择了最难训练的正样本对和负样本对;也就是最不像的正样本以及最像的负样本对,进行训练;这样可以学到更鲁棒的特征,也会减少样本数量不够的压力;损失函数如下:其中l为损失函数,()
+
操作为与数0比取最大值;a是anchor图片,p是正样本图片,n表示负样本图片,d表示上述矩阵相乘后的相似性度量,max表是最大值,min表示取最小值,α表示正负样本对距离间隔的阙值;通过深度学习网络框架回传梯度,更新网络参数,使损失函数的值不断下降,最终趋于稳定,即训练完成。
[0013]
本发明的有益效果:本发明实现了基于卷积神经网络的行人重识别网络框架。设计了一个由resnet50网络特征提取器提取的特征,送入到三元组损失函数里,构成了一个端到端的整体网络。
[0014]
本文的创新点在于基于循环矩阵解决了图片的不对齐问题,该方法利用特征矩阵通过循环矩阵生成了图片中的人在所有位置的一个大的特征矩阵,其中,该矩阵中的每一个行向量与列向量都是原图片中人的位置的一个平移,从而我们可以得到一个最佳位置的特征向量,再对该特征向量进行匹配与度量,进而解决图片不对齐问题。本文在在market1501上比baseline高出2-3个百分点,说明本算法的有效性。
附图说明
[0015]
图1是本发明的基本网络图。
[0016]
图2是循环矩阵的具体架构。
[0017]
图3本发明在market1501上的检测结果。
具体实施方式
[0018]
以下结合附图和技术方案,进一步说明本发明的具体实施方式。本发明的构思是:
由于行人重识别数据集中大多数图片里面的人物没有对齐,导致在做度量学习的时候,不能很精确对比两张图片是否具有相同的身份。本发明利用特征矩阵通过循环矩阵生成了图片中的人在所有位置的一个大的特征矩阵,其中,该矩阵中的每一个行向量与列向量都是原图片中人的位置的一个平移,从而我们可以得到一个最佳位置的特征向量,再对该特征向量进行匹配与度量,进而解决图片不对齐问题。
[0019]
本发明在选取正负样本时候,选取了最不相近的正样本对,最相近的负样本对,通过最难的训练,这样可以学习到鲁棒性的特征,使网络具有更强的泛化能力。
[0020]
本发明具体实施如下:
[0021]
(1)首先,划分行人重识别数据集market1501,一半数据分为训练集数据,一半数据为测试集数据。
[0022]
在训练集中取anchor为待预测图片,再选取与之具有相同身份的人的图片为正样本图片,与之身份不同的人的图片为负样本,这样三张图片组成一个三元组,作为特征网络的输入。
[0023]
(2)三元组图片的每一张图片都是一张彩色图,有三个通道信息,大小是3*256*128。图片通过大小为7*7卷积核进行特征提取,之后是一个最大池化层来降低图片分辨率。随后经过四个卷积块结构,每一个块结构中都是由三个卷积层构成,卷积核大小分别为1*1,3*3和1*1。在每一个卷积核之后都跟随着一个bn层和relu层,其中bn层是batchnorm层,relu层是激活函数层。经过上述网络特征的提取之后,生成了特征大小变成w*h*c的三维特征图,其中w表示特征图的宽度,h表示特征图的高度,c表示特征图的通道数。
[0024]
(3)上述生成的三维特征图经过循环矩阵大小变为(w*h)*(w*h)*c。循环矩阵的公式为,其中f表示离散傅里叶矩阵,f
h
表示离散傅里叶矩阵的共轭转置矩阵,x表示输入到循环矩阵的三维特征,diag表示是矩阵取对角矩阵的操作,这里我们选取当时4个点和8个点的离散傅里叶矩阵。循环矩阵是一个方阵,其中第一行,或者第一列为原来特征向量的原始向量,第二行向量是第一行向量向右平移一个单位,这是一个一维特征向量的循环矩阵。二维特征向量是一维特征向量循环矩阵的延伸,这其中用到了块循环矩阵。块循环矩阵把矩阵分块,我们把每一块放在一起进行上下左右平移构成二维循环矩阵。经过循环矩阵后,在通道层次上进行降维归一化,我们这里选取通道上的平均池化技术,对于(w*h)*(w*h)上的每一个点跨通道加和再除以通道数,最后对于每一个三元组图片都会变为(w*h)*(w*h)大小的二维特征图。
[0025]
(4)三元组图片经过循环矩阵后,选取最不相近正样本对和最相近负样本对进行最后的损失函数计算。首先,anchor最后生成的(w*h)*(w*h)大小的特征图,正样本和负样本分辨率与之相同。对于三元组图片特征图的每一行或者每一列都是原来图片位置的平移结果。因此可以解决行人重识别中人像不对齐的问题。其次,我们要把anchor与正样本组成正样本对,anchor与负样本组成负样本对。在正样本对中,我们取两个特征图进行矩阵相乘,生成的矩阵大小也是(w*h)*(w*h),其上每一个点(i,j)表示anchor的第i行与正样本对第j列相乘的结果,表示两种平移之后相似度的一种度量。这样我们在正样本对中选取结果最小正样本对进行训练,可以训练出鲁棒的特征。同理在负样本对中,anchor和负样本两个特征矩阵相乘,生成的矩阵中的每一个点也代表平移之后的一种相似性度量,不过在负样本中我们选取了相似度最大的负样本参与训练,其原因和正样本相同,都是为了训练出更
鲁棒的特征。
[0026]
(5)选择的损失函数是难样本采样的三元组损失函数。难样本采样三元组损失函数是输入一次性输入三个特征,包络正样本对和负样本对。通过三元组损失函数,它使正样本对之间距离变小,使负样本对之间变大。而从达到聚类的效果,类内间距变小,类间距离变大。在具体选择样本的时候,我们选择了最难训练的正样本对和负样本对。也就是最不像的正样本以及最像的负样本对,进行训练。这样可以学到更鲁棒的特征,也会减少样本数量不够的压力。损失函数如下:其中l为损失函数,()
+
操作为与数0比取最大值。a是anchor图片,p是正样本图片,n表示负样本图片,d表示上述矩阵相乘后的相似性度量,max表是最大值,min表示取最小值,α表示正负样本对距离间隔的阙值。通过深度学习网络框架回传梯度,更新网络参数,使损失函数的值不断下降,最终趋于稳定,即训练完成。
相关技术
网友询问留言
已有0条留言
- 还没有人留言评论。精彩留言会获得点赞!
1