一种LSTM模型的生成方法、充电时长预测方法及介质与流程
本发明涉及机器学习领域和负荷预测领域,更具体地,本发明涉及一种lstm模型的生成方法、充电时长预测方法及介质。
背景技术:
电动汽车(bev)是指以车载电源为动力,用电机驱动车轮行驶,符合道路交通安全法规各项要求的车辆。由于对环境影响相对传统汽车较小,其前景被广泛看好,分为纯电动汽车(bev)、混合动力汽车(hev)、燃料电池汽车(fcev)、新能源汽车等。近年来,随着新能源电动汽车的快速发展,车辆的充电安全问题日益显著,尤其是电动车过充所带来的严重后果。电动汽车在长期过充的情况下,可导致汽车电池加速老化,严重者甚至会使电池急速增温从而导致汽车爆炸,威胁我们的生活和生命安全。
传统的充电安全保护机制是根据电动汽车的电池管理系统(bms),bms是一套保护动力电池组使用安全的控制系统,能够实时监测动力电池组的充放电过程,电压电流值、soc值估计和温度等。但是随着电池的老化,bms的各个功能会下降,尤其是soc值的估计不准确,这使得过充的风险显著上升。
目前,大部分的电动车的预测都是基于用户与电动车方面,而在充电桩和电池组方面的电池时长预测的研究较少。对于充电完成的车辆,充电桩侧应该及时断电,若由于估计不准确导致过充,将使得电动车充电的风险系数上升。因此,对电动汽车进行充电剩余时长预测进行研究,防止电动汽车过充,具有重要的意义。
技术实现要素:
为了解决上述问题,本发明第一个方面提供了一种lstm模型的生成方法,包括:
步骤一:获取历史报文数据;
步骤二:对所述历史报文数据进行特征提取,进行归一化得到特征数据组;
步骤三:通过长短时记忆网络lstm对特征数据组进行训练,得到lstm模型。
作为本发明一种优选的技术方案,所述历史报文数据包括每个时刻的soc值、电压、电流。
作为本发明一种优选的技术方案,所述步骤二中,对历史报文数据进行特征提取,分别计算每个soc值对应的平均电压、平均电流和充电时长,得到数据集,将数据集进行归一化,获得与数据集对应的特征数据组;包括:
根据如下公式进行归一化处理,获得与数据集对应的特征数据组:
其中,ai是soc值为i时数据组中的数据,amin是数据组中所有数据的最小值、amax是数据组中所有数据的最大值,xi是ai进行归一化处理后获得的特征数据组中的特征数据。
作为本发明一种优选的技术方案,所述步骤二中,将数据集根据soc值进行分类,将soc值<80%的数据集中数据放入数据集一中,将soc值≥80%的数据集中数据放入数据集二中,分别对数据集一和数据集二中数据进行归一化,获得与数据集一、数据集二分别对应的特征数据组一、特征数据组二。
作为本发明一种优选的技术方案,所述步骤三中,通过长短时记忆网络lstm分别对特征数据组一和特征数据组二进行训练,分别得到阶段一的lstm模型和阶段二的lstm模型,用于分段充电模式下的lstm预测充电时长。
作为本发明一种优选的技术方案,所述步骤三中,将特征数据一中每个soc值对应的平均电压、平均电流、充电时长归一化后的数据分成矩阵x1和矩阵y1,其中矩阵x1为特征矩阵一中每个soc值对应的平均电压、平均电流归一化后的数据,和soc值合并成的矩阵,矩阵y1为特征矩阵一中充电时长归一化后的数据组成的矩阵;使用矩阵x1、矩阵y1作为训练集对lstm进行训练,得到阶段一的lstm模型;
将特征数据二中每个soc值对应的平均电压、平均电流、充电时长归一化后的数据分成矩阵x2和矩阵y2,其中矩阵x2为特征矩阵二中每个soc值对应的平均电压、平均电流归一化后的数据,和soc值合并成的矩阵,矩阵y2为特征矩阵二中充电时长归一化后的数据组成的矩阵;使用矩阵x2、矩阵y2作为训练集对lstm进行训练,得到阶段二的lstm模型。
本发明第二个方面提供一种基于lstm的充电时长预测方法,包括以下步骤:
(1)根据如上所述的生成方法生成lstm模型;
(2)获取目标的实时报文数据,提取实时特征数据;
(3)将实时特征数据输入lstm模型预测充电时长。
作为本发明一种优选的技术方案,所述步骤(2)中,获取目标的当前soc值、当前电压和当前电流作为实时报文数据,并计算当前soc值的平均电压和平均电流作为实时特征数据。
作为本发明一种优选的技术方案,所述步骤(3)中,判断当前soc值的大小,当当前soc值<80%,将实时特征数据输入阶段一的lstm模型中预测充电时长;当当前soc值≥80%,将实时特征数据输入阶段二的lstm模型中预测充电时长。
本发明第三个方面提供了一种计算机可读存储介质,所述计算机可读存储介质用于存储计算机程序,所述计算机程序用于执行如上所述的基于lstm的充电时长预测方法。
本发明与现有技术相比具有以下有益效果:本发明结合了机器学习方法的优势,利用长短时记忆人工神经网络(lstm)来给出充电剩余时长,可以有效的根据当前的soc状态、电压、电流等信息选择不同的预测阶段,进行分段充电模式下的充电时长预测,可提高预测的准确性,减少过充等现象的发生对电动汽车安全和使用寿命的影响;且在进行分段充电模式的lstm模型的建立中,申请人根据电动汽车实际充电过程中,随着剩余电量soc值的增加,一般充电模式会从恒流改为恒压充电,申请人经过观察成千上万次完整的充电过程中首次电流正常突变时的soc绝大部分大于80%,将soc的阈值设为80%,分别建立阶段一和阶段二的lstm模型,并分段进行预测,极大提高了预测的稳定性和可靠性,且方法简单,处理快速。
附图说明
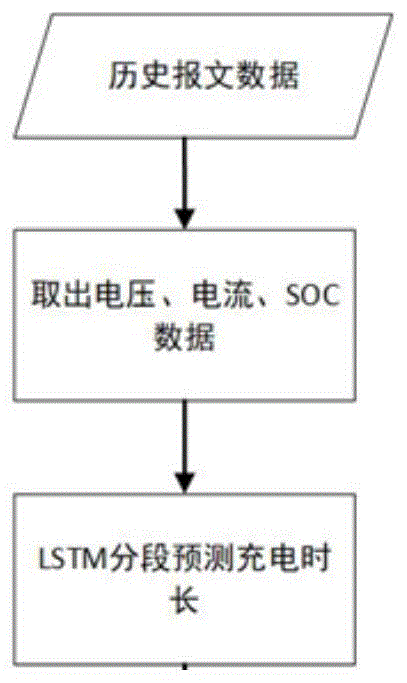
图1为所述lstm模型的生成方法的流程图。
图2为所述基于lstm的充电时长预测方法的流程图。
具体实施方式
参选以下本发明的优选实施方法的详述以及包括的实施例可更容易地理解本发明的内容。除非另有限定,本文使用的所有技术以及科学术语具有与本发明所属领域普通技术人员通常理解的相同的含义。当存在矛盾时,以本说明书中的定义为准。
单数形式包括复数讨论对象,除非上下文中另外清楚地指明。“任选的”或者“任意一种”是指其后描述的事项或事件可以发生或不发生,而且该描述包括事件发生的情形和事件不发生的情形。
说明书和权利要求书中的近似用语用来修饰数量,表示本发明并不限定于该具体数量,还包括与该数量接近的可接受的而不会导致相关基本功能的改变的修正的部分。相应的,用“大约”、“约”等修饰一个数值,意为本发明不限于该精确数值。在某些例子中,近似用语可能对应于测量数值的仪器的精度。在本申请说明书和权利要求书中,范围限定可以组合和/或互换,如果没有另外说明这些范围包括其间所含有的所有子范围。
此外,本发明要素或组分前的不定冠词“一种”和“一个”对要素或组分的数量要求(即出现次数)无限制性。因此“一个”或“一种”应被解读为包括一个或至少一个,并且单数形式的要素或组分也包括复数形式,除非所述数量明显旨指单数形式。
以下通过具体实施方式说明本发明,但不局限于以下给出的具体实施例。
如图1所示,本发明第一个方面提供了一种基于lstm的充电时长预测方法,包括:
步骤一:获取历史报文数据;
步骤二:对所述历史报文数据进行特征提取,进行归一化得到特征数据组;
步骤三:通过长短时记忆网络lstm对特征数据组进行训练,得到lstm模型;
步骤(2):获取目标的实时报文数据,提取实时特征数据;
步骤(3):将实时特征数据输入lstm模型预测充电时长。
步骤一
本发明获取的历史报文数据为目标的历史充电报文数据,所述目标可以是以电作为能量来源的介质,可列举的有,电动汽车、电动自行车、电动三轮车、手机等,以电动汽车为例,历史报文数据可根据目标电动汽车的车牌进行获取,若目标电动汽车无历史充电报文数据,可获取相同或相似型号的电动汽车的充电报文数据作为历史报文数据。电动汽车,如新能源电动汽车的用户在公司的充电桩充电时会产生新能源车与充电桩之间的通讯报文;充电桩会根据公司与充电桩企业签订的协议来筛选部分通讯报文发送到公司的云平台中,并存入数据库,数据库中的报文均为历史报文数据。
在一种实施方式中,所述历史报文数据包括每个时刻的soc值、电压、电流。soc值也即剩余电量(stateofcharge,简称soc),是指电池内的可用电量占标称容量的比例,是电池管理系统的一个重要监控数据,电池管理系统根据soc值控制电池工作状态。电池的剩余电量也即反映的是电池的荷电状态。
步骤二
在一种实施方式中,本发明所述步骤二中,对历史报文数据进行特征提取,分别计算每个soc值对应的平均电压、平均电流和充电时长,得到数据集,将数据集进行归一化,获得与数据集对应的特征数据组;包括:
根据如下公式进行归一化处理,获得与数据集对应的特征数据组:
其中,ai是soc值为i时数据组中的数据,amin是数据组中所有数据的最小值、amax是数据组中所有数据的最大值,xi是ai进行归一化处理后获得的特征数据组中的特征数据。将将数据集进行归一化,获得与数据集对应的特征数据组中,包括每个soc值对应的平均电压、平均电流、充电时长归一化后的数据,以及soc值的数据,例如计算每个soc值对应的平均电流归一化后的数据时,根据上式,分别将ai、amin、amax带入数据组中soc值为i的平均电流、数据组中最小平均电流和数据组中最大平均电流进行计算,得到的xi为soc值为i时对应的平均电流归一化后的数据。
历史报文数据中每个soc值为0%~100%的整数,故可能不同时刻对应的soc值相同,而电压和电流不同,故需要对每个soc值对应的电压和电流进行平均。另外,充电时长为该soc值和上一soc值间隔的时间,表示的是从上一soc值充电到该soc值的时间,例如从soc值为13%充电到14%的时间为soc值为14%时的充电时长。
在一种实施方式中,本发明所述步骤二中,将数据集根据soc值进行分类,将soc值<80%的数据集中数据放入数据集一中,将soc值≥80%的数据集中数据放入数据集二中,分别对数据集一和数据集二中数据进行归一化,获得与数据集一、数据集二分别对应的特征数据组一、特征数据组二。在实际电动汽车充电过程中,随着soc值增加,充电模式会从恒流充电变为恒压充电,此时电流会发生突变,申请人通过观察成千上万次完整的充电过程中首次电流正常突变时的soc值,发现绝大部分大于80%,且随着充电模式的改变,充电规律也会发生改变,故若采集所有soc值的数据集进行充电预测,存在较大的误差,需要根据充电模式的不同,选择不同的充电模型,本发明令80%作为节点,分别对数据集进行处理,得到不同充电模式下的lstm预测模型,提高预测的准确和可靠性。
步骤三
在一种实施方式中,本发明所述步骤三中,通过长短时记忆网络lstm分别对特征数据组一和特征数据组二进行训练,分别得到阶段一的lstm模型和阶段二的lstm模型,用于分段充电模式下的lstm预测充电时长。
优选地,本发明所述步骤三中,将特征数据一中每个soc值对应的平均电压、平均电流、充电时长归一化后的数据分成矩阵x1和矩阵y1,其中矩阵x1为特征矩阵一中每个soc值对应的平均电压、平均电流归一化后的数据,和soc值合并成的矩阵,矩阵y1为特征矩阵一中充电时长归一化后的数据组成的矩阵;使用矩阵x1、矩阵y1作为训练集对lstm进行训练,得到阶段一的lstm模型;
将特征数据二中每个soc值对应的平均电压、平均电流、充电时长归一化后的数据分成矩阵x2和矩阵y2,其中矩阵x2为特征矩阵二中每个soc值对应的平均电压、平均电流归一化后的数据,和soc值合并成的矩阵,矩阵y2为特征矩阵二中充电时长归一化后的数据组成的矩阵;使用矩阵x2、矩阵y2作为训练集对lstm进行训练,得到阶段二的lstm模型。
在lstm训练阶段,分别提取特征矩阵中每个soc对应的平均电压、平均电流归一化后的数据集和soc合并成矩阵作为lstm的输入数据,归一化后的时间数据集合并成矩阵作为lstm的输出数据,进行lstm训练。其中lstm长短期记忆网络(longshort-termmemory)是一种时间循环神经网络,是为了解决一般的rnn(循环神经网络)存在的长期依赖问题而专门设计出来的,所有的rnn都具有一种重复神经网络模块的链式形式。在标准rnn中,这个重复的结构模块只有一个非常简单的结构,例如一个tanh层。lstm神经网络有输入层,隐含层和输出层三部分,训练前根据训练集确定好隐含层节点数,在整个训练过程中只需要为输入权值和隐含层偏置随机赋值,训练过程不需要迭代,且得到最优解,大大减少了训练时间。
lstm有三个门分别是输入门、遗忘门、输出门;以及两个记忆:长时以及和短时记忆。其工作流程为:每一时刻,lstm单元通过3个门接收当前状态xi,上一个时刻的隐藏状态ht-1,还有内部信息ct-1。每个门在接手记忆后决定是否激活。输入门的输入经过非线性变换后与遗忘门处理过单元进行叠加,形成新的记忆单元,在通过输出门的运算和控制得到最后的输出ht。lstm记忆单元的结构门结构控制着数据在lstm记忆单元中的传输,包括不同单元之间的数据传输和单元内部的数据传输。lstm记忆单元的计算公式如下:
it=σ(wxixt-whiht-1+wcict-1+bi);
ft=σ(wxfxt-whfht-1+wcfct-1+bf);
ct=ftct-1+tanh(wxcxt-whcht-1+bc);
ot=σ(wxoxt-whoht-1+wcoct+bo);
ht=ot·tanh(ct);
其中,wxc表示单元、输入数据间的权重矩阵;wxi表示输入门、输入数据间的权重矩阵;wxf表示遗忘门、输入数据间的权重矩阵;wxo表示输出门、输入数据间的权重矩阵;whi表示输入门、隐藏层间的(hidden-inputgate)权重矩阵;whf表示遗忘门、隐藏层间的权重矩阵;whc表示单元、隐藏层间的权重矩阵;who表示输出门、隐藏层间的权重矩阵;wci表示输入门、单元间的权重矩阵;wcf表示遗忘门、单元间的权重矩阵;wco表示输出门、单元间的权重矩阵;bi表示输入门偏置项;bf表示遗忘门偏置项;bc表示单元状态偏置项;bo表示输出门偏置项;σ是激活函数,一般为tanh或sigmod函数;it为t时刻的输入门状态、ft为t时刻的遗忘门状态、ot为t时刻的输出门状态,ct表示t时刻单元状态(activationvector),ht表示t时刻的隐藏状态(hiddenvector);xt表示t时刻的输入值。
lstm训练好之后,将应用于汽车的充电时长预测,具体预测过程可描述为:在一种实施方式中,所述步骤三得到lstm模型后,获取目标电动汽车充电报文数据,根据充电报文数据的soc值,将充电报文数据放入对应的lstm模型中,预测充电时长,并将充电报文数据和充电时长放入历史报文数据中,重复步骤二和三,更新对应的lstm模型,用于下次充电时长预测。本发明所述目标电动汽车的充电报文数据包括充电时的soc值、电流和电压。在预测目标电动汽车充电报文数据时,根据分段充电的模式,当充电报文数据的soc值≥80%时,将充电报文数据放入阶段二的lstm模型中,否则放入阶段一的lstm模型进行预测。
本发明所述lstm训练过程为离线程序,只有在定期维护或出现大量错误时才会重新训练lstm的权值,但随着当前充电的时间和建立lstm模型的间隔增加,最初建立的lstm模型可能和当前充电的模型有误差,为了减少误差,在建立lstm模型,目标电动汽车充电时产生的充电报文数据和预测的充电时长数据也会放入历史报文数据中,此时相比于最初的lstm模型训练时的训练集中的数据增多,从而更新相应的模型,提高下一次预测时长时的准确性和可靠性。
如图2所示,本发明第二个方面提供一种基于lstm的充电时长预测方法,包括以下步骤:
(1)根据如上所述的生成方法生成lstm模型;
(2)获取目标的实时报文数据,提取实时特征数据;
(3)将实时特征数据输入lstm模型预测充电时长。
步骤(2)
在一种实施方式中,本发明所述步骤(2)中,获取目标的当前soc值、当前电压和当前电流作为实时报文数据,并计算当前soc值的平均电压和平均电流作为实时特征数据。所述目标和步骤一中历史充电报文数据中目标一致,同样以电动汽车为例,每当一个充电桩与电动汽车,如新能源汽车握手成功之后并且产生第一条充电报文数据开始,开始提取实时特征数据进行预测,在步骤(3)中,对实时特征数据进行归一化处理,作为lstm模型的输入数据,预测充电时长,其中本发明预测得到的充电时长是当前soc值的充电时长,剩余充电时长为从充电开始到结束每个soc值的充电时长相加。
步骤(3)
在一种实施方式中,本发明所述步骤(3)中,判断当前soc值的大小,当当前soc值<80%,将实时特征数据输入阶段一的lstm模型中预测充电时长;当当前soc值≥80%,将实时特征数据输入阶段二的lstm模型中预测充电时长。本发明所述步骤(2)和步骤(3)为在线程序,且处理的时间为分钟级;当一个充电桩与电动汽车,如新能源汽车握手成功之后并且产生第一条充电报文数据开始,就要启动在线程序,进行预测,且随着充电进行,soc值也随之变化,故需要对soc值进行判断,当soc值<80%采用阶段一lstm模型预测,随着充电进行,当soc值≥80%,需要使用阶段二模型进行预测,直至充电完成,停止充电。
本发明第三个方面提供了一种计算机可读存储介质,所述计算机可读存储介质用于存储计算机程序,所述计算机程序用于执行如上所述的基于lstm的充电时长预测方法。
前述的实例仅是说明性的,用于解释本发明所述方法的一些特征。所附的权利要求旨在要求可以设想的尽可能广的范围,且本文所呈现的实施例仅是根据所有可能的实施例的组合的选择的实施方式的说明。因此,申请人的用意是所附的权利要求不被说明本发明的特征的示例的选择限制。在权利要求中所用的一些数值范围也包括了在其之内的子范围,这些范围中的变化也应在可能的情况下解释为被所附的权利要求覆盖。
- 还没有人留言评论。精彩留言会获得点赞!