一种面向识别的低分辨率人脸图像超分辨率方法与流程
[0001]
本发明涉及人脸图像超分辨率技术领域,特别涉及基于人脸超分辨率预处理的人脸识别方法。
背景技术:
[0002]
人脸识别技术具有非强制性、非接触式和并发处理等优势,在实际应用场景下能够同时满足对多个人脸的过滤、认证及识别,已经被广泛用于楼宇、小区、商场和地铁的视频监控及手机等移动客户端的金融支付安全认证等生活领域。
[0003]
近年来,随着深度学习的发展,人脸识别技术的识别精度得到了质的提升,其识别准确性在认证数据集lfw上已经超越了人类肉眼辨识的精度。但是,这些主流的人脸识别算法主要围绕在高清人脸识别任务上。如,人脸认证数据集lfw源于网络名人集,这些人脸图片大都是由专业摄影师用专业摄像机抓拍,人脸图片不仅分辨率高且光照条件理想,使人脸细节纹理丰富、姿态变化小,从而获取的人脸特征分布比较理想。而在监控场景中,由于监控摄像头架设角度、环境光照变化及抓拍过程中人脸与摄像头距离较远和目标相对运动等因素。抓拍到的人脸图像呈现不同低分辨率、光照及姿态变化大和不同程度的模糊,丢失了大量的人脸身份细节纹理信息,导致这些算法直接用于监控场景,其识别性能显著下降。如何提高监控场景低分辨率人脸识别精度对人脸识别研究提出了新的挑战。
[0004]
最直观的解决方案是先对低分辨率人脸图像进行超分辨率重构,然后用生成的高分辨率人脸图像进一步人脸识别。目前,人脸图像超分辨率技术一直是研究的热点,尤其是近年来,基于深度学习的人脸图像超分辨率技术取得了令人振奋的发展。但是,一个低分辨率人脸可能对应多个高分辨率人脸,因此,人脸图像超分辨率是一个典型的病态求逆问题,需要引入更多的人脸先验信息来约束学习过程进行精准建模。但是目前大多数基于深度学习的人脸图像超分辨率方法一般采用均方误差(mse)【1】作为优化目标,重建的人脸图像过于平滑,缺少纹理细节,不利用后续的人脸识别任务。当前改进的方法主要围绕在联合多损失函数指导和人脸先验信息的指导两个方面。典型地,ledig.c【2】等人提出对抗生成网络的人脸图像超分辨率方法可以获取更多的纹理细节,通过对抗损失指导模型训练,提升视觉上的图像质量。但是,研究表明这些对抗生成的纹理细节很多都是噪声纹理,进一步误导了后续的识别任务;johnson.j【3】等人使用预训练好的分类模型,通过计算图像的中间语义损失来促进生成高分辨率图像的语义保持;为了进一步约束超分辨率网络的学习,bulat.a【4】等人利用人脸关键点结构先验知识来辅助人脸图像的超分辨率网络学习;chen.y【5】等人利用人脸解析部件作为结构先验知识来辅助人脸图像的超分辨率网络学习。这些研究都是联合不同的损失函数和挖掘不同的人脸先验知识来改善人脸图像的视觉质量效果,并没有充分考虑对超分辨率人脸图像身份信息的增强。
[0005]
此外,目前大部分人脸超分辨率研究中,低分辨率样本的获取均是通过下采样插值来获取,将图像的降质过程简化为了插值下采样操作。然而,由于监控环境的不可控性,天气光照条件复杂多变,导致抓拍的人脸图像降质复杂多样,多种影响因素混合交叠导致
了最终的成像效果。简单的插值下采样不足以模拟实际环境下的复杂图像降质过程。仅仅使用插值下采样合成的降质样本对无法表达监控场景中的复杂降质过程。由于模拟降质数据域(训练集)和实际降质数据域(测试集)存在域的偏移,进一步导致了现有人脸超分辨率模型难以在监控场景中有效应用。
[0006]
因此,基于以上几个问题,亟需一种面向识别的人脸图像超分辨率方法,不仅能实现对监控场景图像降质过程的精准刻画,同时提高超分辨率人脸图像的识别精度。
[0007]
【1】c.dong,c.c.loy,k.he and x.tang,"image super-resolution using deep convolutional networks,"[j]//ieee transactions on pattern analysis and machine intelligence,vol.38,no.2,pp.295-307,1feb.2016.
[0008]
【2】c.ledig et al.,"photo-realistic single image super-resolution using a generative adversarial network,"[c]//ieee conference on computer vision and pattern recognition(cvpr),2017,pp.105-114.
[0009]
【3】johnson j.,alahi a.,fei-fei l.perceptual losses for real-time style transfer and super-resolution.[c]//european conference on computer vision.2016,vol 9906.springer,cham.
[0010]
【4】a.bulat and g.tzimiropoulos,"super-fan:integrated facial landmark localization and super-resolution of real-world low resolution faces in arbitrary poses with gans,"[c]//conference on computer vision and pattern recognition,salt lake city,ut,2018,pp.109-117.
[0011]
【5】y.chen,y.tai,x.liu,c.shen and j.yang,"fsrnet:end-to-end learning face super-resolution with facial priors,"[c]//conference on computer vision and pattern recognition,salt lake city,ut,2018,pp.2492-2501.
技术实现要素:
[0012]
本发明提供一种面向识别的低分辨率人脸图像的超分辨率方法。其主要目的是在于解决现在人脸图像超分辨率方法只关注图像视觉上的质量提升,而没有显式关注身份信息恢复的问题,提高超分辨率人脸图像的识别精度。
[0013]
本发明的技术方案:一种面向识别的人脸图像超分辨率方法,主要分为两个阶段。第一阶段是样本准备阶段,该阶段首先收集少量的监控场景低分辨率降质人脸数据样本;其次用变分自编码网络学习采集样本的降质分布规律;再次利用学习的降质分布的模型,通过采样的方式生成多样稠密的降质样本集,对降质分布进行完备表达。第二阶段是人脸图像超分辨率网络训练阶段,该阶段首先使用第一阶段生成的模拟真实数据降质的高低样本对训练人脸图像超分辨率网络;其次,将超分辨率人脸和高分辨率人脸分别输入到训练好的人脸识别网络,提取高分辨率人脸图像和超分辨率人脸图像的身份表达特征向量,再将身份表达特征向量解开到特征空间的角度域和幅度域分别计算角度损失和幅度损失,同时联合超分辨率人脸图像和高分辨率人脸图像的内容损失,使用反向传播训练人脸图像超分辨率网络。
[0014]
具体包括以下步骤:
[0015]
step 1:采集真实降质样本,用于变分自编码网络学习实际环境样本数据的降质
分布规律;所述变分自编码网络采用无监督学习策略,包含编码器、解码器两个部分;
[0016]
step 2:基于变分自编码网络学习的图像降质规律,通过采样的策略生成随机变量输入到变分自编码的解码网络,生成服从数据降质分布的多样降质样本数据;
[0017]
step 3:联合step1采集的真实降质样本和step2生成的多样降质样本构建完备真实降质样本集,并进一步利用完备真实降质样本集构建服从真实数据降质分布的高低样本对;
[0018]
step 4:将高低样本对的低分辨率人脸图像输入到人脸图像超分辨率网络,生成超分辨率人脸图像;
[0019]
step 5:将高分辨率人脸图像和超分辨率人脸图像分别输入到人脸识别网络,提取人脸的身份表达特征向量作为对应的人脸图像身份表达,进一步将身份表达特征向量解开到角度域和幅度域;
[0020]
step 6:计算高分辨率人脸图像和超分辨率人脸图像之间的图像内容损失函数是否到达设计要求,即损失函数降低到某一范围内即符合设计要求;
[0021]
step 7:将高分辨率人脸图像和超分辨率图像的身份表达特征解开到角度域,计算身份表达特征之间的角度差异损失是否达到设计要求,即损失函数不在下降即符合设计要求;
[0022]
step 8:计算高分辨率人脸图像和超分辨率人脸图像的身份表达特征在幅度域上的损失是否达到设计要求,即损失函数不在下降即符合设计要求;
[0023]
step 9:如果达到设计要求,则输出最终训练好的人脸超分辨率网络模型,否则继续提取训练集数据迭代训练;
[0024]
step 10:最终得到训练完成的人脸超分辨率网络作为低分辨率人脸超分辨率重建模型,即输入低分辨率人脸图像得到超分辨率人脸图像。
[0025]
进一步的,所述step 1中变分自编码网络中的编码器g由一个卷积操作和4个残差卷积模块组成,每2个残差卷积模块后连接一个平均池化操作来扩大感受野,最后一个平均池化操作连接一个全连接层,输出图像降质隐变量空间表达的参数;解码器与编码器g网络结构相对称,由4个残差卷积模块构成,每2个残差卷积模块后面连接一个上采样模块,最后残差模块连接一个卷积模块和一个sigmoid模块进行图像重构。
[0026]
进一步的,所述step 2中,利用变分自编码学习到的降质分布规律,通过分布采样来进一步扩充服从降质分布的多样降质样本,形成更多更完备的降质表达样本集。
[0027]
进一步的,step 3中构建服从真实数据降质分布的高低样本对的具体实现方式如下,
[0028]
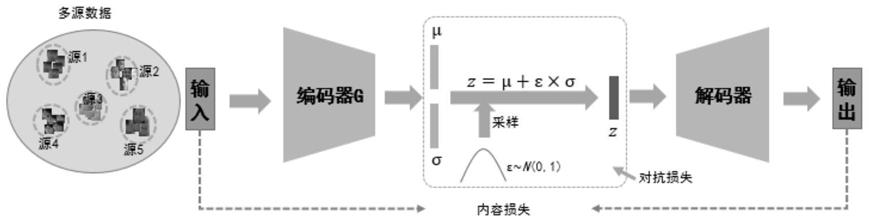
step 31,从完备真实降质样本集中随机采样一张降质人脸样本来提供风格信息,具体是通过变分自编码网络中的编码器来提取特定实例的风格参数,然后通过随机采样来构建实例相似风格信息表达z;
[0029]
step 32,构建风格迁移网络,所述风格迁移网络包括内容编码器和内容解码器两个部分,通过风格迁移网络对开源的高分辨率人脸样本进行模拟真实低质量人脸降质生成;
[0030]
step 33,利用风格迁移网络生成降质样本,与从完备真实降质样本集中随机采样的降质样本输入到判别器网络,计算对抗损失来判别生成降质样本与随机采样的降质样本
是否服从同一数据降质分布,通过对抗博弈的学习策略,构建服从真实数据降质分布的高低样本对。
[0031]
进一步的,所述step 32中内容编码器由6层残差卷积模块组成,每2个残差卷积模块接1个卷积操作和最大池化操作,内容编码器用来提取图像的本质特征表达,提供图像内容信息f
content
;
[0032]
风格迁移网络的内容解码器中,将降质风格信息z与图像内容信息f
content
进行多层次融合,多尺度调控生成图像的风格,在每个特征尺度上,通过两个独立的全连接层将降质风格信息z解开为风格统计量σ
z
和μ
z
,然后采用adin模块将内容表达和风格表达自适应进行融合,adin模块的具体操作如下所示:
[0033][0034]
其中,σ
z
和μ
z
是隐变量z通过两层全连接网络学习获得的参数,μ(f
content
)是求f
content
的均值,σ(f
content
)是求f
content
的方差。
[0035]
进一步的,所述step 4中人脸图像超分辨率网络的结构为:输入为16*16像素的低分辨率人脸图像,首先使用64个卷积核大小为9
×
9、步长为1的卷积层提取特征,然后通过6个残差卷积块,连接3个上采样模块,将特征图放大到高分辨率图像的尺寸,其输出通道数为256;最后通过通道数为3、卷积核大小为9
×
9、步长为1、通道数为3的卷积层输出超分辨率人脸图像。
[0036]
进一步的,所述step 5中的人脸识别网络为当前state-of-art高分辨率人脸模型lightcnn,身份表达特征向量采用当前state-of-art人脸识别模型lightcnn的softmax层前一层的全连接层向量。
[0037]
进一步的,所述step 6中的人脸超分辨率网络训练中,计算人脸超分辨率内容损失函数:
[0038]
l
p
=||i
sr-i
hr
||2[0039]
其中,l
p
为内容损失函数,i
sr
和i
hr
分别为超分辨率人脸图像和高分辨率人脸图像,||
·
||2为2范数。
[0040]
进一步的,所述step 7中的人脸超分辨率网络训练中,计算人脸超分辨率网络在身份特征向量解开表达的角度域身份信息损失函数:
[0041]
lc=1-cosθ
[0042]
其中,l
c
为身份嵌入角度损失函数,为超分辨率人脸与对应高分辨率人脸的余弦距离,f
sr
为超分辨率人脸的身份特征向量,f
hr
为高分辨率人脸的身份特征向量,||
·
||2为2范数。
[0043]
进一步的,所述step 8中的人脸超分辨率网络训练中,计算人脸超分辨率网络在身份特征向量解开表达的幅度域身份信息损失函数:
[0044]
l
a
=||norm(f
sr
)-norm(f
hr
)||2[0045]
其中,l
a
为身份嵌入幅度损失函数,f
sr
为超分辨率人脸的身份特征向量,f
hr
为高分辨率人脸的身份特征向量,norm(
·
)为取向量模操作,||
·
||2为2范数。
[0046]
本发明与现有超分辨率技术相比的优点在于:
[0047]
(1)能够有效的模拟监控环境中的低分辨率人脸图像的复杂降质过程
[0048]
传统的超分辨率方法在准备低分辨率人脸图像的时候,绝大部分采用的插值下采样的策略,或者采用对高分辨率图像进行先进行模糊处理,然后进行下采样,最后对降采样之后的图像添加高斯白噪声处理,如公式i
lr
=(s*i
hr
)
↓
+n。该降质模型串通过模糊、下采样和噪声串联序列处理,不能准确刻画监控环境中图像复杂多样的降质过程。训练数据和实际环境的数测试据之间降质分布域的差异,导致了超分辨率模型性能的下降。本发明通过收集的少量多样降质样本,利用变分自编码网络学习样本的降质分布规律,并通过学习到的降质分布规律,用采样的方式进一步扩充降质样本类型,形成对监控环境的样本降质分布的稠密完备表达。然后用生成的降质样本和原始降质样本,通过风格迁移网络对高分辨率人脸图像进行降质模拟,形成更加符合监控环境降质的高低样本对,为人脸图像超分辨率网络的训练提供了高质量的训练数据样本对。
[0049]
(2)能够有效的提高低分辨率人脸图像的识别精度
[0050]
传统的人脸图像超分辨率网络训练的过程中,无论是采样新的损失函数还是挖掘人脸结构语义先验知识做指导,仅仅关注超分辨率人脸图像在视觉效果上的质量提升,没有显式的考虑超分辨率人脸图像身份信息的恢复。本发明在进行人脸图像超分辨率网络学习时,不仅考虑视觉效果上的质量提升约束,同时通过引入身份先验信息约束,进一步关注与人脸身份信息相关纹理细节的合成,提高了低分辨率人脸识别的精度。
附图说明
[0051]
图1为本发明的学习数据降质分布的变分自编码网络图;
[0052]
图2为本发明的生成降质样本的风格迁移网络架构图;
[0053]
图3为本发明的人脸图像超分辨率网络的残差卷积模块;
[0054]
图4为本发明的人脸图像超分辨率网络的上采样模块;
[0055]
图5位本发明的人脸图像超分辨率网络图;
[0056]
图6位本发明人脸图像超分辨率网络整体训练框架图;
具体实施方式
[0057]
下面结合附图及实施例对本发明进行详细说明。
[0058]
为了使本领域技术人员更好地理解本发明方案,下面将结合本发明实施例中的附图,对本发明实施例中的技术方案进行详细地描述,显然,所描述的实施例仅仅是本发明一部分的实施例,而不是全部的实施例。基于本发明中的实施例,本领域普通技术人员在没有做出创造性劳动前提下多获得的所有其他实施例,都应当属于本发明保护的范围。
[0059]
需要说明的是,本发明所说的低分辨率人脸图像是分辨率在12x12至20x20像素区间的人脸图像;高分辨率人脸图像是分辨率大于100x100像素的人脸图像。
[0060]
图1是根据本发明实施例中基于低分辨率人脸降质样本学习数据降质分布规律的变分自编码网络架构图,如图1所示,包括:
[0061]
从多个监控场景收集的多源低分辨率人脸降质样本数据,该降质人脸通过mtcnn人脸检测算子自动获取,取人脸尺寸在12x12至20x20像素区间的低分辨率人脸样本构建降质样本数据集;
[0062]
基于变分自编码网络学习的图像降质规律,将采集的降质人脸图像缩放至16x16像素大小,通过变分自编码的编码器g将原始降质图像映射到隐特征表达空间,编码器g主要由一个卷积操作和4个残差卷积模块组成,每2个残差卷积模块后连接一个平均池化操作来扩大感受野,最后一个平均池化操作连接一个全连接层,输出图像降质隐变量空间表达的参数;
[0063]
为了使约束隐变量特征表达变量更好的学习原始数据的降质分布,本设计约束原始数据的降质分布服从高斯分布假设。随机采样向量,通过公式z=μ+ε
×
σ进行采样服从高斯分布的隐变量,其中ε服从标准高斯分布ε~n(0,1);
[0064]
将采样隐变量z输入到解码器来重构原始输入图像,解码器与编码器g网络结构相对称,由4个残差卷积模块构成,每2个残差卷积模块后面连接一个上采样模块,最后残差模块连接一个卷积模块和一个sigmoid模块进行图像重构;
[0065]
为保证网络输出内容的一致性,本项目采用l1损失函数对输入图像x和输出图像y进行内容约束,则像素内容损失l
p
为:
[0066]
l
p
=||y-x||1[0067]
为保证隐变量空间能学习到原始数据的真实降质分布,本项目采用kl散度(kullback-leibler divergence)来对隐变量空间分布进行约束。对于输入图像空间x,z为隐变量空间,q(z|x)代表了图像空间到隐变量空间的后验概率,p(z)为隐变量空间的先验分布,kl散度约束后验分布q(z|x)与先验分布p(z)要尽可能一致,其分布损失函数l
kl
具体形式如下:
[0068]
l
kl
=d
kl
(q(z|x)||p(z))
[0069]
网络通过训练,获取变分自编码网络最优的完备模型参数;
[0070]
通过学习的数据降质分布规律,进行采样生成,进一步生成服从降质分布的不同类型的降质样本,构建更稠密更完备的降质样本集;
[0071]
通过上述低分辨率样本降质分布规律的学习和对降质样本的扩充,可以通过少量的降质样本构建满足降质分布的多类型多数量的降质样本集。该策略在应用中非常实用,因为实际应用中很难收集到足够多数量和充分降质变化的样本,这需要大量的人力和物力。通过本发明的方法,可以在少量收集降质样本的基础上,来生成更多服从降质分布的“没看见过”降质类型的样本。因此,该方法在不增加人力物力成本的前提下实现了更多真实降质样本数据的收集,特别适用于工业应用。
[0072]
图2是根据本发明实施例中低分辨率人脸降质样本生成的风格迁移网络架构图,如图2所示,包括:
[0073]
收集大量的高质量人脸图像样本集,主要从casia-web face人脸数据集,vggface2人脸数据集和ms-celeb-1m人脸数据集,deepglint人脸数据集中选取实际人脸分辨率尺度大于100像素,用现有图像质量估计模型分数在80以上人脸图像来构建高质量人脸样本集;
[0074]
将高质量人脸样本输入到内容编码器来提取图像的本质特征表达,其网络架构主要由6层残差卷积模块组成,每2个残差卷积模块接1个卷积操作和最大池化操作,除了最后的输出为单个参数维度向量表达,该模块主要为下一步风格迁移网络提供图像内容信息f
content
;
[0075]
从多样完备的降质样本集中随机采样一张降质人脸样本来提供风格信息,具体通过编码器g来提取特定实例的风格参数,然后通过随机采样来构建实例相似风格信息表达z;
[0076]
风格迁移网络的内容解码器中,将降质风格信息z与图像内容信息f
content
进行多层次融合,多尺度调控生成图像的风格,在每个特征尺度上,通过两个独立的全连接层将降质风格信息z解开为风格统计量σ
z
和μ
z
,然后采用adin模块将内容表达和风格表达自适应进行融合,adin模块的具体操作如下所示:
[0077][0078]
其中,σ
z
和μ
z
是隐变量z通过两层全连接网络学习获得的参数,μ(f
content
)是求均值,σ(f
content
)是求方差;
[0079]
为保证生成图像与真实低质图像降质分布的一致性,本项目将生成的降质图像输入到判别网络进行对抗学习,其判别网络架构前面部分与内容编码网络保持一致,后续添加了全连接层,输出真假两类进行判断。通过对抗学习的方式来促进图像降质的学习,对抗损失函数l
adv
形式如下:
[0080][0081]
网络通过训练,获取最优的完备降质图像生成模型参数;
[0082]
图3是根据本发明实施例中人脸图像超分辨率网络架构图,如图3所示,包括:
[0083]
输入为16*16像素的低分辨率人脸图像,首先使用64个卷积核大小为9
×
9、步长为1的卷积层提取特征,然后每通过6个残差卷积块,连接3个上采样模块,将特征图放大到高分辨率图像的尺寸,其输出通道数为256;最后通过通道数为3、卷积核大小为9
×
9、步长为1、通道数为3的卷积层输出超分辨率人脸图像。其中,图4为人脸图像超分辨率网络的残差卷积块,每个残差块包含两个conv+bn操作,中间包含了一个prelu操作;图5为人脸图像超分辨率网络的上采样模块,其依次包含conv->pixelshuffle->prelu操作。
[0084]
图6是根据本发明实施例中人脸图像超分辨率网络学习训练架构图,如图6所示,包括:
[0085]
将通过风格迁移网络生成的降质人脸样本i
lr
输入到人脸超分辨率网络g,输出增强后的超分辨率人脸图像i
sr
;
[0086]
计算人脸超分辨率内容损失函数:
[0087]
l
p
=||i
sr-i
hr
||2[0088]
将超分辨人脸图像i
sr
和真实高分辨率人脸图像i
hr
分别输入到人脸识别网络(lightcnn)提取身份表达特征f
sr
和f
hr
,并将身份特征向量解开到角度域和幅度域,计算人脸超分辨率网络在特征解开空间的角度域身份信息损失函数:
[0089]
l
c
=1-cosθ
[0090]
其中,l
c
为身份嵌入角度损失函数,为超分辨率人脸与对应高分辨率人脸的余弦距离,f
sr
为超分辨率人脸的身份特征向量,f
hr
为高分辨率人脸的身份特征向量,||
·
||2为2范数;
[0091]
计算人脸超分辨率网络在特征解开空间的幅度域身份信息损失函数:
[0092]
l
a
=||norm(f
sr
)-norm(f
hr
)||2[0093]
其中,l
a
为身份嵌入幅度损失函数,f
sr
、f
hr
和||
·
||2同上述,norm(
·
)为取向量模操作;
[0094]
通过对人脸超分辨率网络引入身份先验信息,并显式的解开到角度域和幅度域分别进行监督,不仅关注身份信息相关纹理的合成,同时使身份表达投影到幅度域的更大半径的球面上,增强了生成人脸图像的身份表达特征的鲁棒性;
[0095]
总之,本发明提高了监控场景下低分辨率人脸识别的精度,通过模拟监控场景降质样本的生成和超分辨率网络训练中引入身份先验信息进行监督,促使人脸超分辨率网络更加关注身份信息相关纹理细节的生成,提高了监控场景下超分辨率人脸图像的识别精度;
[0096]
本文中所描述的具体实施例仅是对本发明精神做举例说明。本发明技术领域的技术人员可以对所描述的具体实施例做各样的修改补充或者采用类似的方式替代,但并不会偏离本发明精神或者超越所附权利要求书所定义的范围。
相关技术
网友询问留言
已有0条留言
- 还没有人留言评论。精彩留言会获得点赞!
1