一种基于源代码文件依赖关系的软件缺陷定位系统的制作方法
[0001]
本发明涉及人工智能领域,尤其涉及一种基于源代码文件依赖关系的软件缺陷定位系统。
背景技术:
[0002]
开源软件通常使用缺陷追踪系统(如bugzilla和jira)对缺陷进行记录,每天都有大量的缺陷报告提交。缺陷报告中包含对缺陷的描述,失效时的相关程序状态、日志等。因此,研究人员试图根据提交的缺陷报告,自动定位到出错的程序实体。基于缺陷报告的缺陷定位可被看作是一个查询问题,即对于给定的缺陷报告(查询),需要从应用的所有源代码文件(文档)中找到可能出错的文件,并将可疑的源码文件按照出错的可能性进行排名。近些年来,围绕缺陷报告进行定位的研究工作主要可划分为两类:采用信息检索技术和采用深度学习技术。
[0003]
基于信息检索的缺陷定位的相关研究工作可从信息检索的三个要素进行分类:检索模型、文档(表示)、以及查询(表示)。多数研究工作关注于如何利用或优化信息检索模型来提高缺陷定位的准确性。其中,对于缺陷定位,向量空间模型(vsm)已被证明效果优于其他常用信息检索模型。buglocator是利用vsm 的代表性研究工作。该工作利用tf-idf分别将缺陷报告和源代码文件向量化,然后通过计算余弦相似度来衡量它们之间的相似性。buglocator在vsm的基础上还考虑了源代码文件大小(即文件越大,出错的可能性越高),和已被修复缺陷的修复信息(即如果两个缺陷报告相似度较高,那它们可能需要修复相似的文件)。
[0004]
基于深度学习的缺陷定位为基于信息检索的定位方法,主要依赖于缺陷报告和源代码文件的文本相似度。但以自然语言为主的缺陷报告和以编程语言为主的源代码文件之间存在词法失配问题。当缺陷报告和源码文件的重叠信息较少时,定位效果并不好。因此,深度学习技术被引入用来提高定位的准确性。采用深度学习技术的缺陷定位中,一些研究工作不仅利用词嵌入(word embedding)技术 (如word2vec)来捕获缺陷报告和源代码文件之间的语义相似度,还利用深度神经网络(dnn)对多种特征(例如,基于vsm的文本相似度,基于dnn的相似度,缺陷修复历史(如文件被修复的频率和时近性))进行非线性组合来计算源代码文件的可疑度,如hyloc以及dnnloc。还有一些研究工作利用不同的网络模型来处理缺陷报告和源代码文件,以便更好地提取源代码的结构信息,如 np-cnn。或是利用不同的向量化方法(如词嵌入、句子嵌入)来表示缺陷报告和源代码文件,如deeploc。
[0005]
其中,yoon kim提出的用于文本分类的卷积神经网络(cnn)模型经常被用于处理词嵌入之后的本文向量。
[0006]
以上现有技术存在如下问题:
[0007]
基于信息检索的缺陷定位,不能解决缺陷报告和源代码文件之间的词法失配问题。基于深度学习技术的缺陷定位中,虽然利用不同的嵌入技术(如词嵌入、句子嵌入、文档嵌入等)和不同的网络模型(如卷积神经网络、循环神经网络) 来捕获缺陷报告和源代码中
的语义信息,但并未考虑源代码之间的关联关系。而通研究发现,对于一些缺陷,虽然出错的源代码文件与缺陷报告并不高度相似,但该文件与那些和缺陷报告高度相似的源代码文件之间存在依赖关系。因此,依赖关系可以被用于提高缺陷定位的准确性。
[0008]
此外,现有工作中,虽然tf-idf向量经常被用于缺陷报告和源代码文件的表示,但仅通过简单的余弦相似度来衡量它们之间的文本相似度。事实上,缺陷报告和源代码文件的tf-idf向量还可用捕获除文本相似度之外的特征,有助于提高定位的准确性。
[0009]
本发明针对基于缺陷报告的缺陷自动定位问题,旨在提出一种基于源代码文件依赖关系的缺陷定位方法,解决现有方法定位不够准确,且未考虑文件依赖关系的问题。
[0010]
具体来说,主要解决的问题包括:(1)直接利用源代码间的依赖关系进行定位会引入较多不相关文件,因此需要寻找一种依赖关系的量化方法,该方法需要满足两个条件:能有效区分错误和非错误源码文件;能覆盖当前应用中的所有源码文件。(2)现有缺陷报告和源代码文件的tf-idf向量表示未被充分利用,现有研究工作仅利用这些向量去获得文本相似度,本发明试图利用这些向量去捕获除文本相似度以外的特征,从而提高定位的准确度。
技术实现要素:
[0011]
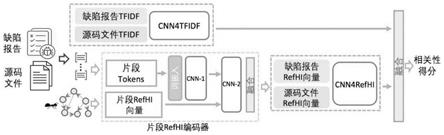
为此,本发明提出了一种基于源代码文件依赖关系的软件缺陷定位系统,系统分为输入、运算、输出三个模块,其中所述输入模块用于导入缺陷报告和源码文件,所述运算模块采用dependloc框架,由三个子模块cnn4tfidf模型子模块、片段refhi编码器子模块和cnn4refhi子模块组成,具体地:
[0012]
cnn4tfidf模型子模块根据缺陷报告和源码文件的tf-idf向量,以卷积神经网络的方法捕获文本相似度、源码文件长度以及相似缺陷报告等特征;
[0013]
片段refhi编码器子模块首先在将所述缺陷报告和源码文件拆分成等大小的片段,片段词汇通过词嵌入并输入卷积神经网络一,若词嵌入的向量维度为k,一条语句包含n个词汇,则将n
×
k维的向量输入所述卷积神经网络一,令所述卷积神经网络一的卷积核高度为k
h
,k
h
为正整数,则卷积核大小为k
h
×
k,可同时设置多个不同规格的卷积核,即卷积核的高度k
h
可同时设置为多个值,常用的值包括3、4、5,然后对不同卷积核大小得到的结果进行最大池化操作,再将最大池化后的结果进行拼接,最后,所述卷积神经网络一通过两个全连接层输出一个n
hi
维向量,同时构建文件依赖图,进而结合所述基于文件依赖图,采用一种基于文件依赖图的定制化蚁群算法来模拟可能的文件引用路径,得到反应每个文件被引用的次数的引用热度值,并将所述引用热度值划定引用热度区间,利用引用热度区间向量的构建方法得到片段refhi向量,将缺陷报告和源码文件编码成具有源码依赖关系特征的向量;
[0014]
cnn4refhi子模块基于缺陷报告和源码文件的refhi向量它们之间的相关性得分;
[0015]
所述输出模块用于将源码文件按照相关性得分排序后对外输出。
[0016]
所述cnn4tfidf模型子模块针对输入的缺陷报告和源码文件,根据源代码文件的词汇空间,所述词汇空间大小为n,n为正整数,生成两个n维的tf-idf 向量,将缺陷报告和源码文件的tf-idf向量合并为2
×
n维张量作为卷积神经网络模型的输入,并设定卷积核的大小为2
×
k
w
,k
w
为所述卷积核宽度,所述卷积核个数为k
n
,进行卷积运算后得到(n-k
w
+1)维的向量,设定池化窗口大小为 p,完成最大池化操作后,得到用于与所述cnn4refhi子模块
的输出拼接并融合的,尺寸为k
n
×
((n-k
w
+1)/p)的输出向量,k
w
、k
n
、p均为正整数。
[0017]
所述片段refhi编码器子模块采用的所述一种基于文件依赖图的定制化蚁群算法具体实现方式为:首先,定义蚁群算法中每只蚂蚁的能量,并设定路径集合初始化为空,所述文件依赖图中所有节点作为起始节点集合,从所述起始节点集合中随机选择一个节点作为起始,若当前节点的出度为0,则重新从所述起始节点集合中随机选择一个节点作为起始;否则,蚂蚁从当前节点的出节点中随机选择一个节点作为下一步,如果所述下一步未被访问,即不在所述路径集合中,则所述下一步加入所述路径集合;如果所述下一步已被访问,即在所述路径集合中,且所述下一步的出节点中仍有节点未被访问,则所述下一步加入所述路径集合;如果所述下一步已被访问,且所述下一步的所有出节点均被访问过,则蚂蚁停止;同时设置检查下一步的出节点是否均被访问过的机制来避免环形依赖导致的无限循环,收集所述路径集合后,每个文件被引用的次数即为蚂蚁访问过的次数,通过所述蚂蚁访问过的次数定义文件的依赖特征,即为引用热度值。
[0018]
所述每只蚂蚁的能量的定义方法为:对于当前应用中源码文件的数目为n
src
,设置蚂蚁个数为100*n
src
,且每只蚂蚁初始能量为
[0019]
所述引用热度区间向量的构建方法为:将所有文件的引用热度值取对数后的值域等分为n
hi
个区间定义为引用热度区间,且每个源码文件所属的所述引用热度区间为该文件的引用热度值取对数后落入的区间,
[0020]
根据所有源码中的词汇,定义n为所有源码的词汇空间大小,t
ij
表示源码文件s中,s∈[1,n
src
],第i个词汇在第j维的值,i
s
指示源码文件s是否属于第j 个引用热度区间,t
ij
正规化为t
′
ij
,则第i个词汇的引用热度值词汇向量被表示为t
i
,根据下列关系为每一个词汇生成一个n
hi
维的向量:
[0021][0022][0023][0024]
则每个词汇从所属的源码文件中继承了引用热度特征,进一步,根据下列关系:
[0025][0026][0027]
分别计算出每个缺陷报告片段和源码文件片段的引用热度值词汇向量,f
r
(i) 和f
s
(i)分别代表缺陷报告r和源码文件s中词汇i的个数,表示在所有源码文件中词汇i的idf值,通过上述方法为每个片段计算出一个n
hi
维的引用热度值向量,将所述卷积神经网络一输出的向量和每个片段计算出的引用热度值向量两个向量组合成一个2
×
n
hi
维的向量输入卷积神经网络二,采用2
×
1大小的卷积核,输出一个n
hi
维的向量,表示当前片段属于n
hi
个区间的不同概率,则该片段落入最大概率值对应的区间,每个缺陷报告片段或源码
文件片段的引用热度值词汇向量为片段内词汇的加权引用热度值词汇向量,片段中的相同词汇不进行重复加权计算,对词汇i的权重w
i
通过tf-idf计算得到,每个片段的目标引用热度值即为片段所属文档的引用热度值。
[0028]
所述cnn4refhi子模块基于片段refhi编码器得到的片段引用热度值向量,并根据下列方法计算缺陷报告和源码文件的引用热度值向量r
′
和s
′
:
[0029][0030][0031]
seg表示来自缺陷报告或源码文件的片段,q
seg
表示由片段中refhi编码器得到的n
hi
维引用热度值向量,w
seg
表示每个片段的权重,由该片段中不重复词汇的 tf-idf值累加得到,将向量r
′
和s
′
组合成一个2
×
n
hi
维的向量输入cnn4refhi的卷积神经网络模型,卷积核大小为卷积核个数为最大池化的窗口大小为p
hi
,p
hi
均为正整数,则该模型输出向量的形状为数,则该模型输出向量的形状为最后,将cnn4tfidf模型子模块和cnn4refhi子模块的输出向量拼接,并通过三个全连接层输出一个相关性得分。
[0032]
本发明所要实现的技术效果在于:
[0033]
通过cnn4tfidf模型子模块、片段refhi编码器子模块和cnn4refhi子模块之间的配合,实现系统层面上
[0034]
1.能有效区分错误和非错误源码文件;覆盖当前应用中的所有源码文件;
[0035]
2.能充分利用缺陷报告和源代码文件的tf-idf向量表示中的信息;
[0036]
从而能够提高利用深度学习方法进行缺陷定位的准确性。
附图说明
[0037]
图1: dependloc框架;
[0038]
图2 :cnn4tfidf模型;
[0039]
图3:定制化的蚁群算法;
[0040]
图4:用于词嵌入文本的cnn模型;
具体实施方式
[0041]
以下是本发明的优选实施例并结合附图,对本发明的技术方案作进一步的描述,但本发明并不限于此实施例。
[0042]
本发明提出了一种基于源代码文件依赖关系的缺陷定位系统,系统分为输入、运算、输出三个模块,其中所述输入模块用于导入缺陷报告和源码文件,所述运算模块采用dependloc框架,dependloc框架总体框架如图1所示。dependloc 由三个子模块组成:
[0043]
cnn4tfidf模型子模块:根据缺陷报告和源码文件的tf-idf向量捕获文本相似度、源码文件长度以及相似缺陷报告等特征。
[0044]
用tf-idf分别计算缺陷报告和源码文件的向量表示。假设当前应用中,源代码文件的词汇空间大小是n,则得到两个n维的tf-idf向量。如图2所示,将缺陷报告和源码文件
的tf-idf向量合并(2
×
n维)作为卷积神经网络(cnn) 模型的输入。卷积核的大小为2
×
k
w
,k
w
为卷积核宽度,卷积核个数为k
n
。则卷积后得到一个(n-k
w
+1)维的向量。池化窗口大小为p,完成最大池化操作后,得到的向量形状为k
n
×
((n-k
w
+1)/p)。该向量将在dependloc最后的融合层与cnn4refhi模型的输出拼接并融合。
[0045]
该模型能不仅能捕获缺陷报告和源码文件的文本相似度,还能学习源码文件长度和相似缺陷报告(即相似的缺陷可能修复相似的源码文件)等特征。
[0046]
片段refhi编码器:将缺陷报告和源码文件编码成具有源码依赖关系特征的向量。
[0047]
(1)文件依赖图(file dependency graph,fdg)
[0048]
若文件a引用文件b,则称a依赖于b,记作a
→
b。根据当前应用的所有源码文件,可构建一个文件依赖图。
[0049]
(2)基于文件依赖图(fdg)的文件引用热度(refheat)
[0050]
为了量化源码文件的依赖关系,本专利通过提出一种基于文件依赖图的定制化蚁群算法来模拟可能的文件引用路径。与传统蚁群算法(蚂蚁之间共享信息) 不同,该算法中每只蚂蚁进行路径选择是彼此独立。每只蚂蚁均按照图3所示的算法流程图执行。首先,每只蚂蚁能量初始化为e,路径集合path初始化为空, fdg中所有节点作为起始节点集合n
start
。从n
start
中随机选择一个节点作为起始。若当前节点的出度为0,则重新从n
start
中随机选择一个节点作为起始;否则,蚂蚁从当前节点的出节点(n
out
(node
cur
))中随机选择一个节点作为下一步(即 node
next
)。如果node
next
未被访问(即不在path中),则node
next
加入path。令下一步的出节点集合(n
out
(node
next
))中未被访问过的节点的集合为n
unvisited
。如果node
next
已被访问(即在path中),且n
unvisited
不为空,则node
next
加入path。如果node
next
已被访问,且node
next
的所有出节点均被访问过(即n
unvisited
为空),则蚂蚁停止。由于fdg中可能存在环形依赖,因此需要检查n
unvisited
来避免环形依赖导致的无限循环。假设当前应用中源码文件的数目为n
src
,则设置蚂蚁个数为100*n
src
,且每只蚂蚁初始能量为
[0051]
收集所有蚂蚁的路径(即path)后,可通过每个文件被引用(即蚂蚁访问过)的次数来量化文件的依赖特征,称之为引用热度(reference heat,refheat)。
[0052]
(3)引用热度区间(reference heat interval,refhi)向量
[0053]
由于引用热度值是离散的,因此,将所有文件的引用热度值取对数后的值域等分为n
hi
个区间(且),称之为引用热度区间(refhi)。每个源码文件所属的refhi为该文件的refheat值取对数后落入的区间。
[0054]
根据所有源码中的词汇,按照公式(1)-(3)为每一个词汇生成一个n
hi
维的向量。n为所有源码的词汇空间大小,t
ij
表示源码文件s(s∈[1,n
src
])中,第i个词汇在第j维的值。i
s
指示源码文件s是否属于第j个引用热度区间。t
ij
正规化为t
′
ij
,则第i个词汇的refhi词汇向量被表示为t
i
。因此,每个词汇从所属的源码文件中继承了引用热度特征。
[0055]
refhi向量。即每个文档(缺陷报告或源码文件)的refhi向量为文档内词汇的加权refhi向量。需要注意的是,文档中的相同词汇不进行重复加权计算。词汇 i的权重w
i
通过tf-idf计算可得。f
r
(i)和f
s
(i)分别代表缺陷报告r和源码文件 s中词汇i的个数。表示在所有源码文件中词汇i的idf值。
[0056][0057][0058]
(4)片段refhi向量
[0059]
给定一个缺陷报告,需要通过refhi来匹配出错的源码文件。对于源码文件,其目标rehi即为该文件所属的引用热度区间。对于缺陷报告,其目标rehi为该缺陷对应的缺陷文件所属的引用热度区间。然而,由公示(4)和(5)计算的静态 refhi向量并不足以准确地预测热度区间。此外,文档(缺陷报告和源码文件) 长度变化较大且通常在输入模型之前会进行截断处理,一些关键信息可能丢失。因此,为得到更有效的refhi向量,且更好地捕获文档语义信息,本发明设计了片段refhi编码器(图1)。其中,文档被拆分成等大小(即每个片段包含相等个数的词汇)的片段,片段词汇通过词嵌入并输入cnn-1,cnn-1和yoon kim 提出的用于文本分类的cnn模型类似,如图4所示。若词嵌入的向量维度为k,一条语句包含n个词汇,则将n
×
k维的向量输入cnn-1,令cnn-1的卷积核高度为k
h
(正整数),则卷积核大小为k
h
×
k,可同时设置多个不同规格的卷积核,即卷积核的高度k
h
可同时设置为多个值,常用的值包括3、4、5。然后对不同卷积核大小得到的结果进行最大池化操作,再将最大池化后的结果进行拼接。最后,cnn-1通过两个全连接层输出一个n
hi
维向量。同时,类似公式(4)和(5),可以为每个片段计算出一个n
hi
维的refhi向量。将这两个向量组合成一个2
×
n
hi
维的向量输入cnn-2。cnn-2的卷积核大小为2
×
1,cnn-2的输出是一个n
hi
维的向量,表示当前片段属于n
hi
个区间的不同概率,则该片段落入最大概率值对应的区间。
[0060]
用于训练的缺陷报告和所有源码文件的片段均被用于训练片段refhi编码器,且每个片段的目标refhi即为片段所属文档的refhi。对于有多个出错源码文件的缺陷报告,则采用与该报告文本相似度最高的源码文件所对应的refhi。片段refhi编码器中的词嵌入采用现有工作中非监督的skip-gram模型及当前应用中的所有源码文件训练得到。
[0061]
cnn4refhi子模块:基于缺陷报告和源码文件的refhi向量发掘它们之间的相关性。
[0062]
基于片段refhi编码器得到的片段refhi向量,可根据公式(6)和(7)计算缺陷报告
和源码文件的refhi向量r
′
和s
′
。公式中,seg表示来自缺陷报告或源码文件的片段,q
seg
表示由片段中refhi编码器得到的n
hi
维refhi向量,w
seg
表示每个片段的权重,由该片段中不重复词汇的tf-idf值累加得到。
[0063][0064][0065]
将向量r
′
和s
′
组合成一个2
×
n
hi
维的向量输入cnn4refhi模型,cnn4refhi 的卷积核大小为卷积核个数为最大池化的窗口大小为p
hi
,且,且p
hi
均为正整数,则该模型输出向量的形状为
[0066]
最后,将cnn4tfidf和cnn4refhi的输出向量拼接,并通过三个全连接层输出一个相关性得分,用于表示缺陷报告与源码文件的相关程度。
相关技术
网友询问留言
已有0条留言
- 还没有人留言评论。精彩留言会获得点赞!
1