实体相似匹配方法及系统与流程
[0001]
本发明涉及自然语言处理技术领域,具体来说涉及一种实体相似匹配方法及系统。
背景技术:
[0002]
长文本相似度算法和检索算法目前已经有一些较为成熟的算法,比如谷歌的simhash算法,能够从海量长文本中较为高效的找到与目标文本相似的文本,但是这种算法不适用于短文本。传统的编辑距离算法、余弦相似度算法等能够适用于短文本相似度匹配,但是随着数据量增加,匹配效率逐渐降低,经过测试发现编辑距离算法在1000条短文本中查找相似文本效率较好,超过1000条则效率不高,原因在于编辑距离算法需要对输入的短文本与数据库中的所有短文本进行比较,计算量太大,但实际应用时其中大多数文本不必参与相似度计算。
技术实现要素:
[0003]
本发明旨在解决现有的短文本相似度匹配方法存在的效率较低的问题,提出一种实体相似匹配方法及系统。
[0004]
本发明解决上述技术问题所采用的技术方案是:实体相似匹配方法,包括以下步骤:
[0005]
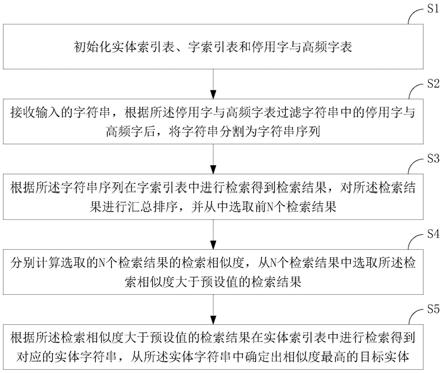
步骤1、初始化实体索引表、字索引表和停用字与高频字表,所述实体索引表用于存储所有实体,所述字索引表用于存储除开停用字与高频字的所有字与实体的映射关系,所述停用字与高频字表用于存储实体中的停用字与高频字;
[0006]
步骤2、接收输入的字符串,根据所述停用字与高频字表过滤字符串中的停用字与高频字后,将字符串分割为字符串序列;
[0007]
步骤3、根据所述字符串序列在字索引表中进行检索得到检索结果,对所述检索结果进行汇总排序,并从中选取前n个检索结果,所述n为大于1的整数;
[0008]
步骤4、分别计算选取的n个检索结果的检索相似度,从n个检索结果中选取所述检索相似度大于预设值的检索结果;
[0009]
步骤5、根据所述检索相似度大于预设值的检索结果在实体索引表中进行检索得到对应的实体字符串,从所述实体字符串中确定出相似度最高的目标实体。
[0010]
进一步的,步骤1中,所述实体索引表和字索引表使用哈希索引,实体索引表的hashkey为自增数字序列,实体索引表的hashvalue为实体;字索引表的hashkey为字,字索引表的hashvalue为实体索引表的hashvalue的长度。
[0011]
进一步的,步骤1中,所述停用字与高频字表中的停用字与高频字通过人为经验和统计方法得到。
[0012]
进一步的,步骤3中,所述n为20。
[0013]
进一步的,步骤4中,所述检索相似度的计算方法包括:
[0014]
设检索结果为ent1,l1为检索到的ent1的次数,l2为ent1的长度,则检索相似度find_sim=l1/l2。
[0015]
进一步的,步骤4中,所述预设值为0.5。
[0016]
进一步的,步骤5中,所述从实体字符串中确定出相似度最高的目标实体包括:
[0017]
使用编辑距离算法或余弦相似度算法计算各实体字符串的相似度,从实体字符串中确定出所述相似度最高的目标实体。
[0018]
本发明还提出一种实体相似匹配系统,包括:
[0019]
初始化单元,用于初始化实体索引表、字索引表和停用字与高频字表,所述实体索引表用于存储所有实体,所述字索引表用于存储除开停用字与高频字的所有字与实体的映射关系,所述停用字与高频字表用于存储实体中的停用字与高频字;
[0020]
接收单元,用于接收输入的字符串,根据所述停用字与高频字表过滤字符串中的停用字与高频字后,将字符串分割为字符串序列;
[0021]
检索单元,用于根据所述字符串序列在字索引表中进行检索得到检索结果;以及根据所述检索相似度大于预设值的检索结果在实体索引表中进行检索得到对应的实体字符串;
[0022]
选取单元,用于对所述检索结果进行汇总排序,并从中选取前n个检索结果,所述n为大于1的整数;以及从n个检索结果中选取检索相似度大于预设值的检索结果;
[0023]
计算单元,用于分别计算选取的n个检索结果的检索相似度;以及从所述实体字符串中确定出相似度最高的目标实体。
[0024]
本发明的有益效果是:本发明所述的实体相似匹配方法及系统,即使实体库中的实体量较大,也能高效的返回最相似的实体,在不损失相似匹配的准确率的同时大大提高了实体相似匹配的效率。
附图说明
[0025]
图1为本发明实施例所述的实体相似匹配方法的流程示意图;
[0026]
图2为本发明实施例所述的实体相似匹配系统的结构示意图;
[0027]
图3为本发明实施例所述的实体索引表的结构示意图;
[0028]
图4为本发明实施例所述的字索引表的结构示意图;
[0029]
图5为本发明实施例所述的停用字与高频字表的结构示意图。
具体实施方式
[0030]
下面将结合附图对本发明的实施方式进行详细描述。
[0031]
本发明所述的实体相似匹配方法,技术方案概括为:初始化实体索引表、字索引表和停用字与高频字表,所述实体索引表用于存储所有实体,所述字索引表用于存储除开停用字与高频字的所有字与实体的映射关系,所述停用字与高频字表用于存储实体中的停用字与高频字;接收输入的字符串,根据所述停用字与高频字表过滤字符串中的停用字与高频字后,将字符串分割为字符串序列;根据所述字符串序列在字索引表中进行检索得到检索结果,对所述检索结果进行汇总排序,并从中选取前n个检索结果,所述n为大于1的整数;分别计算选取的n个检索结果的检索相似度,从n个检索结果中选取所述检索相似度大于预
设值的检索结果;根据所述检索相似度大于预设值的检索结果在实体索引表中进行检索得到对应的实体字符串,从所述实体字符串中确定出相似度最高的目标实体。
[0032]
具体而言,首先,初始化实体索引表、字索引表和停用字与高频字表;然后,通过停用字与高频字表对输入实体中的停用字与高频字进行过滤,停用字与高频字对实体检索的作用不大,去除这部分字可以节约存储空间,然后将输入实体分割为字符串序列,将字符串序列在字索引表中进行检索,利用字索引表可以检索到与输入实体相近的所有实体,然后从检索结果中选取n个检索结果,通过对检索返回数量的控制实现对检索结果的第一次过滤,减少了进行检索相似度计算的输入,进而提高了检索效率。再然后,对选取的n个检索结果计算检索相似度,通过检索相似度对检索结果进行第二次过滤,减少了最终进行相似度计算的输入,进一步提高了检索效率。最后,根据第二次过滤后的结果在实体索引中进行实体检索,最终输出相似度最高的目标实体。
[0033]
实施例1
[0034]
本发明实施例所述的实体相似匹配方法,如图1所示,包括以下步骤:
[0035]
步骤s1、初始化实体索引表hash_ent、字索引表hash_char和停用字与高频字表sttf_word,所述实体索引表hash_ent用于存储所有实体,所述字索引表hash_char用于存储除开停用字与高频字的所有字与实体的映射关系,所述停用字与高频字表sttf_word用于存储实体中的停用字与高频字;
[0036]
本实施例中,所述实体索引表hash_ent和字索引表hash_char使用哈希索引,实体索引表的hashkey为自增数字序列,实体索引表hash_ent的hashvalue为实体;字索引表hash_char的hashkey为字,字索引表hash_char的hashvalue为实体索引表hash_ent的hashvalue的长度。
[0037]
在实体索引表中,哈希索引能够快速找到某个实体,其查找时间复杂度为o(1)。
[0038]
在字索引表hash_char中,其查找时间复杂度为o(1),哈希索引能够快速找到某个字存在于哪些实体中,可以查找到所有可以进行相似度计算的实体,查找次数为输入实体的长度,比如输入实体为“无间到”,则查找次数为3次,即通过3次时间复杂度为o(1)的查找,可以找出所有可以与“无间到”进行相似计算的实体,过滤了大量无关实体,提高了计算效率。
[0039]
所述停用字与高频字表sttf_word中的停用字与高频字可以通过人为经验和统计方法得到。这部分字对实体检索作用不大,去除这部分字可以节约存储空间,提高计算效率。
[0040]
步骤s2、接收输入的字符串,根据所述停用字与高频字表sttf_word过滤字符串中的停用字与高频字后,将字符串分割为字符串序列;
[0041]
通过停用字与高频字表sttf_word对输入实体进行过滤后,可以减少在字索引表中的查找次数,并且能够减少返回的查找结果。比如输入实体为“我和我的祖国”,其中“的”为停用字与高频字表sttf_word中的停用字,会被过滤掉,相当于最终输入的实体为“我和我祖国”,查找次数由6次减少到5次,而且由于很多实体中包含“的”字,因此可以大大减少了查找返回的实体,进而提高相似匹配的效率。
[0042]
步骤s3、根据所述字符串序列在字索引表中进行检索得到检索结果,对所述检索结果进行汇总排序,并从中选取前n个检索结果,所述n为大于1的整数;
[0043]
具体而言,通过对检索返回数量的控制实现对检索结果的第一次过滤,减少了进行检索相似度计算的输入,进而提高了检索效率。
[0044]
为了保证相似匹配的准确度,所述n优选为20。
[0045]
步骤s4、分别计算选取的n个检索结果的检索相似度,从n个检索结果中选取所述检索相似度大于预设值的检索结果;
[0046]
优选的,所述检索相似度的计算方法包括:
[0047]
设检索结果为ent1,l1为检索到的ent1的次数,l2为ent1的长度,则检索相似度find_sim=l1/l2。
[0048]
可以理解,通过检索相似度对检索结果进行第二次过滤,减少了最终进行相似度计算的输入,进一步提高了检索效率。
[0049]
为了保证相似匹配的准确度,所述预设值优选为20。
[0050]
步骤s5、根据所述检索相似度大于预设值的检索结果在实体索引表中进行检索得到对应的实体字符串,从所述实体字符串中确定出相似度最高的目标实体。
[0051]
其中,所述从实体字符串中确定出相似度最高的目标实体包括:
[0052]
使用编辑距离算法或余弦相似度算法计算各实体字符串的相似度,从实体字符串中确定出所述相似度最高的目标实体。
[0053]
基于上述技术方案,本实施例还提出一种实体相似匹配系统,如图2所示,包括:
[0054]
初始化单元,用于初始化实体索引表、字索引表和停用字与高频字表,所述实体索引表用于存储所有实体,所述字索引表用于存储除开停用字与高频字的所有字与实体的映射关系,所述停用字与高频字表用于存储实体中的停用字与高频字;
[0055]
接收单元,用于接收输入的字符串,根据所述停用字与高频字表过滤字符串中的停用字与高频字后,将字符串分割为字符串序列;
[0056]
检索单元,用于根据所述字符串序列在字索引表中进行检索得到检索结果;以及根据所述检索相似度大于预设值的检索结果在实体索引表中进行检索得到对应的实体字符串;
[0057]
选取单元,用于对所述检索结果进行汇总排序,并从中选取前n个检索结果,所述n为大于1的整数;以及从n个检索结果中选取检索相似度大于预设值的检索结果;
[0058]
计算单元,用于分别计算选取的n个检索结果的检索相似度;以及从所述实体字符串中确定出相似度最高的目标实体。
[0059]
可以理解,由于本发明实施例所述的实体相似匹配系统是用于实现实施例所述实体相似匹配方法的系统,对于实施例公开的系统而言,由于其与实施例公开的方法相对应,所以描述的较为简单,相关之处参见方法的部分说明即可。
[0060]
实施例2
[0061]
假设模块输入为:“无间到”,期望结果为100ms内返回与其最相似的正确结果“无间道”,本发明实施例的具体实施过程如下。
[0062]
步骤a、初始化实体索引表hash_ent、字索引表hash_char和停用字与高频字表sttf_word,假设实体索引表hash_ent中有三个片名实体:无间道、无间风云、盗墓笔记。实体索引表hash_ent如图3所示,字索引表hash_char如图4所示,停用字与高频字表sttf_word如图5所示;
[0063]
步骤b、接收输入的“无间到”,并分散字符串序列为[“无”,“间”,“到”],并过滤停用字与高频字;
[0064]
步骤c、检索字索引表hash_char,得到结果:["无":"0_3,1_4","间":"0_3,1_4","到":null];
[0065]
步骤d、对步骤c的结果汇总排序,并取前n个(默认20),得到结果:[(0_3,2),(1_4,1),(2_4,1)];
[0066]
步骤e、对步骤d的结果计算实体相似度find_sim,并过滤find_sim<0.5的结果:
[0067]
find_sim(0_3,2)=2/3>0.5;
[0068]
find_sim(1_4,1)=1/4<0.5;
[0069]
find_sim(2_4,1)=1/4<0.5;
[0070]
得到find_list=[(0_3,2)];
[0071]
步骤f、用步骤e的结果[(0_3,2)]查找实体索引表hash_ent,这里用索引“0”去查找,得到结果[“无间道”];
[0072]
步骤g、调用编辑距离算法库,对步骤f的结果求编辑距离:edit_distance(“无间到”,[“无间道”])=无间道。
相关技术
网友询问留言
已有0条留言
- 还没有人留言评论。精彩留言会获得点赞!
1