基于语义规则和多维模型的多数据源NL2SQL系统的制作方法
基于语义规则和多维模型的多数据源nl2sql系统
技术领域
1.本发明涉及智能搜索技术领域,尤其涉及一种基于语义规则和多维模型的多数据源nl2sql系统。
背景技术:
2.智能化搜索中,计算机理解用户查询意图的过程成为了业界研究的热点,而在理解用户意图之前,首先需要把自然语言转化为计算机可以理解并生成准确表达语句语义的可执行程序式语言。naturallanguage to sql(nl2sql)是将用户的自然语言语句转换成计算机可读懂、可运行、符合计算机规则语义表示的一种方法。
3.目前,nl2sql技术中,需要专业的知识储备进行词典配置,对 nlp和模型训练有一定的要求;另外,其对数据集的要求比较高,需要大量标注好的训练集语料和测试集语料和拒识数据(一些自然语言没有对应的sql语句,模型应该拒绝作出预测)来进行模型训练,环节流程复杂且完成时间长。
4.所以,现有的nl2sql技术在实际使用过程中很难推广应用。
技术实现要素:
5.为了解决现有技术中存在的技术问题,本发明提供了如下技术方案。
6.本发明提供了一种基于语义规则和多维模型的多数据源 nl2sql系统,包括用于实现nl2sql的业务层,所述业务层包括:
7.配置模块,用于配置匹配规则;
8.数据模型构建模块,用于构建可利用数据库的表和字段信息生成 sql语句的数据模型;
9.意图识别模块,用于根据所述匹配规则将输入的自然语句解析、匹配得到数据库的表和字段信息,并利用所述数据模型生成可执行的 sql语句。
10.优选地,所述配置模块包括:
11.语境配置模块,用于配置语境匹配规则;
12.用户词典配置模块,用于配置用户词典;
13.表字段配置模块,用于配置数据库的表、字段、表关系、表和字段关系;
14.语义片段配置模块,用于配置语义片段匹配规则。
15.优选地,所述用户词典配置模块包括用户自定义模块和专业词典模块,所述用户自定义模块用于配置用户自定义的同义词、停用词、关键词和/或实体,所述专业词典模块用于配置专业词典。
16.优选地,所述用户词典配置模块还包括第三方分词和实体识别模型调用模块,用于配置第三方分词和实体识别模型的调用接口。
17.优选地,所述语义片段匹配规则包括匹配词语、语义规则和要素字段。
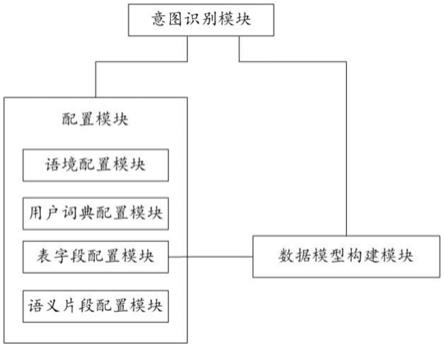
18.优选地,所述意图识别模块包括:
19.语境匹配模块,用于根据配置的语境匹配规则,将所述自然语句进行语境匹配,得到所述自然语句的语境信息;
20.标签识别模块,用于根据配置的用户词典,结合所述语境信息,对所述自然语句进行分词和实体识别,得到分词对应的实体类型;
21.语义片段匹配模块,用于根据配置的语义片段匹配规则进行分词匹配,得到语义片段;
22.数据库字段关联模块,用于利用所述语义片段匹配配置的数据库的表和字段,得到对应的表和字段信息以及表关系;
23.sql语句生成模块,用于根据匹配得到的表和字段信息以及表关系,利用所述数据模型生成可执行的sql语句。
24.优选地,所述根据配置的语义片段匹配规则进行分词匹配,得到语义片段包括:
25.将得到的每个分词与所述语义片段匹配规则中的词语进行匹配,获取语义规则;
26.根据所述语义规则匹配得到语义片段的要素信息。
27.优选地,所述将得到的每个分词与所述语义片段匹配规则中的词语进行匹配包括:
28.将所述分词转换为分词向量,计算所述分词向量与所述语义片段匹配规则中的词语的向量的相似度;若相似度达到阈值,则将所述分词替换为所述语义片段匹配规则中的词语。
29.优选地,所述数据模型构建模块包括:
30.表选择模块,用于加载数据表并选择事实表和维度表;
31.维度选择模块,用于选择维度;
32.指标选择模块,用于选择指标;
33.模型建立模块,用于选择统计方法,根据所选择的维度和指标建立数据模型。
34.优选地,所述系统还包括数据接入层、数据存储层和应用层;
35.所述数据接入层用于接收用户输入的数据和配置的匹配规则;
36.所述数据存储层用于数据存储;
37.应用层用于展示和查询自然语句转换为sql语句的结果。
38.本发明的有益效果是:本发明提供的基于语义规则和多维模型的多数据源nl2sql系统,不依赖标注语料和模型,通过界面简单的配置就可以实现基于意图的nl2sql;通过数据模型构建模块支持多选择嵌套,可以灵活配置;通过意图识别模块降低对数据集的要求,提升sql生成的成功率。所以,采用本发明提供的系统,能根据不同的项目快速构建业务场景,支持nosql和关系性数据库等多数据源的扩展。
附图说明
39.图1为本发明所述系统的业务层结构示意图;
40.图2为本发明所述表字段配置格式的截图;
41.图3为本发明所述数据模型的结构示意图;
42.图4为本发明所述数据模型构建流程示意图;
43.图5为本发明所述业务层实施过程流程示意图;
44.图6为本发明所述意图识别模块的结构示意图;
45.图7为本发明所述系统的结构示意图。
具体实施方式
46.为了更好的理解上述技术方案,下面将结合说明书附图以及具体的实施方式对上述技术方案做详细的说明。
47.本发明提供的系统可以在如下的终端环境中实施,该终端可以包括一个或多个如下部件:处理器、存储器和显示屏。其中,存储器中存储有至少一条指令,所述指令由处理器加载并执行以实现下述实施例所述的系统。
48.处理器可以包括一个或者多个处理核心。处理器利用各种接口和线路连接整个终端内的各个部分,通过运行或执行存储在存储器内的指令、程序、代码集或指令集,以及调用存储在存储器内的数据,执行终端的各种功能和处理数据。
49.存储器可以包括随机存储器(random access memory,ram),也可以包括只读存储器(read
‑
only memory,rom)。存储器可用于存储指令、程序、代码、代码集或指令。
50.显示屏用于显示各个应用程序的用户界面。
51.除此之外,本领域技术人员可以理解,上述终端的结构并不构成对终端的限定,终端可以包括更多或更少的部件,或者组合某些部件,或者不同的部件布置。比如,终端中还包括射频电路、输入单元、传感器、音频电路、电源等部件,在此不再赘述。
52.实施例一
53.如图1所示,本发明实施例提供了一种基于语义规则和多维模型的多数据源nl2sql系统,包括用于实现nl2sql的业务层,所述业务层包括:
54.配置模块,用于配置匹配规则;
55.数据模型构建模块,用于构建可利用数据库的表和字段信息生成 sql语句的数据模型;
56.意图识别模块,用于根据所述匹配规则将输入的自然语句解析、匹配得到数据库的表和字段信息,并利用所述数据模型生成可执行的 sql语句。
57.其中,在实际使用过程中,配置模块可以以界面的形式展现,用户登录系统打开配置模块后,出现配置界面,在界面中用户可以根据需求配置相应的内容,比如不同的项目或业务领域,配置的内容不相同。具体的,需要配置的内容可以设置在模板中,用户可以在模板中通过选择、拖曳或输入的方式配置相应的内容。
58.具体的,在本发明实施例中,配置模块包括:
59.语境配置模块,用于配置语境匹配规则;
60.用户词典配置模块,用于配置用户词典;
61.表字段配置模块,用于配置数据库的表、字段、表关系、表和字段关系;
62.语义片段配置模块,用于配置语义片段匹配规则。
63.其中,语境配置模块中配置的语境匹配规则,可以在使用过程中,作为确定输入语句语境的依据。而在对输入的自然语句进行处理过程中,首先进行语境的确定,可以为进一步的语句处理过程奠定基础,使得语句的后续处理能够在匹配的语境环境下进行,提高处理效率和召回精准率。作为一个实例,比如:用户需要查询张三的出行记录,可以分析“出
行”这一场景的要素,然后提取对应的要素配置规则,比如记录中包括要素人、出行、轨迹等一系列代表出行的特征词,根据该规则完成语境匹配。
64.用户词典配置模块可以包括用户自定义模块和专业词典模块,所述用户自定义模块用于配置用户自定义的同义词、停用词、关键词和 /或实体,所述专业词典模块用于配置专业词典。
65.对于某个特定的业务专业领域,存在较多的专业语言或新生成的词语,利用常规词典往往无法对专业领域自然语句进行准确的分词处理,为了解决该问题,本发明实施例中,设置了专业词典模块和用户自定义模块,用户可以利用专业词典模块配置专业词典。在专业词典中,包含了对专业语言和/或新生成词语等的解释和实体类型等的说明。另外,用户可以通过自定义同义词、停用词、关键词和/或实体等,对专业语言和/或新生成词语等进行丰富,以辅助专业词典对词语的处理能力。如果一个基准词对应多个同义词或多个停用词等,则将各词之间通过间隔号分开。由于专业词典与专业语句的匹配度更好,所以,采用专业词典进行分词和实体识别的处理,可以提高精度且更符合业务场景。同时,利用用户自身对专业领域的深入认知,通过自定义的同义词、停用词、关键词和/或实体等,对专业词典的内容进行补充,能够进一步的提高分词和实体识别的精度。
66.在本发明的一个优选实施例中,所述用户词典配置模块还可以包括第三方分词和实体识别模型调用模块,用于配置第三方分词和实体识别模型的调用接口。在实际使用过程中,可以通过接口直接调用第三方分词和实体识别模型,通过模型完成对自然语句的分词和实体识别处理。
67.在表字段配置模块中,将数据库中要转化为sql的字段进行配置,具体需要配置的信息有:数据库类型、表名称、表字段名称、类型等。作为一个实例,其配置的格式可如图2所示。
68.在语义片段配置模块中,通过界面配置的方式配置能够从语义片段并中提取字段信息的内容,比如,包括如下信息:匹配词语、语义规则、语义片段、规则类型和要素字段等。
69.在本发明的一个实施例中,所述数据模型构建模块包括:
70.数据源选择模块,用于选择数据源;
71.表选择模块,用于加载数据表并选择事实表和维度表;
72.维度选择模块,用于选择维度;
73.指标选择模块,用于选择指标;
74.模型建立模块,用于选择统计方法,根据所选择的维度和指标建立数据模型。
75.其中,构建的数据模型主要包括数据库表和表关系或者表和字段关系,可以是单表,也可以是多表。其中,生成的数据模型的结构可如图3所示。
76.数据模型构建模块的主要任务是构建一个能生成sql关系的模型,用户通过拖拽和配置的方式可完成模型的构建。构建的过程如图 4所示,包括:选择数据源;加载数据表,选择事实表和维度表;选择维度和指标;选择统计方法,利用所述统计方法基于所选择的维度和指标建立数据模型。
77.采用本发明提供的数据模型构建模块构建数据模型具有如下的功能特点:
78.可支持多种数据源选择,包含关系型数据库,如mysql、oracle、 postgresql等,也可以选择非关系型数据库,如es、hbase、hive 等;数据源选择来源于表字段的配置;
97.and dm_person_locus.cfsj<
‘
2020
‑
08
‑
23 17:15:07’98.and(
99.dm_person_locus.ddd like
‘
%a地%’100.or dm_person_locus.ddd like
‘
%b地的%’101.)
102.and(1=1)
103.在实际应用过程中,意图识别模块结合配置模块中配置的各种匹配规则以及数据模型构建模块中构建的数据模型,完成sql语句的生成。因此,在业务层中,主要完成了规则的配置和数据模型的构建过程,以及利用规则和模型将输入的自然语句转化为sql语句的过程。
104.系统具体的工作流程可如图5所示。
105.图5中,a
‑
g表示用户配置nl2sql功能的流程:
106.a从数据源中选择数据配置表字段;
107.b根据表字段的配置信息构建数据模型;
108.c得到构建的数据模型;
109.d配置用户词典;
110.e配置意图识别模块中的信息;
111.f将配置信息和数据模型保存至数据源中;
112.g将配置信息和数据模型用于意图识别。
113.①
~
⑨
步骤表示用户输入自然语句查询时转换为sql语句查询的流程:
114.①
用户输入查询语句,系统根据语境匹配规则,将自然语句匹配到语境配置;
115.②
使用用户词典和实体识别相结合的标签模型进行分词和实体识别;
116.③
将分词后的词进行语义规则匹配,得到语义片段;
117.④
根据语义片段关联数据库字段,完成语义片段映射,得到表和字段信息以及表关系;
118.⑤⑥
按照数据模型的表关联规则拼接成可执行的sql;
119.⑦
将sql通过数据适配器进行转换成不同数据库查询语言;
120.⑧⑨
按照sql规则查询数据库数据,返回查询结果。
121.其中,意图识别模块的结构可如图6所示。
122.在本发明的一个实施例中,所述根据配置的语义片段匹配规则进行分词匹配,得到语义片段包括;
123.将得到的每个分词与所述语义片段匹配规则中的词语进行匹配,获取语义规则;
124.根据所述语义规则匹配得到语义片段的要素信息。
125.其中,所述将得到的每个分词与所述语义片段匹配规则中的词语进行匹配包括:
126.将所述分词转换为分词向量,计算所述分词向量与所述语义片段匹配规则中的词语的向量的相似度;若相似度达到阈值,则将所述分词替换为所述语义片段匹配规则中的词语。
127.采用这种语义匹配方式,可以极大的提高语义识别的召回率以及泛化能力。
128.如图7所示,本发明提供的系统还包括数据接入层、数据存储层和应用层;
129.所述数据接入层用于接收用户输入的数据和配置的匹配规则,比如语境匹配规则、用户词典、数据库的表字段、语义片段匹配规则等;
130.所述数据存储层用于数据存储,比如存储用户词典、语境配置、数据模型、语义片段、字段关系映射和用户nl2sql日志等,提供用户配置的规则和数据;
131.应用层用于展示和查询自然语句转换为sql语句的结果。
132.尽管已描述了本发明的优选实施例,但本领域内的技术人员一旦得知了基本创造性概念,则可对这些实施例作出另外的变更和修改。所以,所附权利要求意欲解释为包括优选实施例以及落入本发明范围的所有变更和修改。显然,本领域的技术人员可以对本发明进行各种改动和变型而不脱离本发明的精神和范围。这样,倘若本发明的这些修改和变型属于本发明权利要求及其等同技术的范围之内,则本发明也意图包含这些改动和变型在内。
相关技术
网友询问留言
已有0条留言
- 还没有人留言评论。精彩留言会获得点赞!
1