一种基于层次用户表示的面向社交媒体的谣言检测系统的制作方法
本发明涉及面向社交媒体的谣言检测领域,特别是一种基于层次用户表示的面向社交媒体的谣言检测系统。
背景技术:
谣言(rumor),一般指的是未经核实的陈述或说明,它往往与公众关心的某一事件相关,并在大众之间广泛流传。这一未经核实的陈述有可能会被证实是真实的,或者部分乃至完全是虚假的,甚至其真实性也可能长期无法得到证实。随着社交网络的发展,互联网信息海量庞杂,但大量的信息中却夹杂着各种虚假信息,特别是谣言信息。近年来,随着微博、推特等社交媒体的深度普及,用户可以自由的发布信息,用户之间能够直接建立联系和交流,这直接加速了互联网平台信息的流动和传播,同时也使得谣言事件的产生和传播更加的容易和迅速,造谣者往往只需要少量的成本便可以编造和传播谣言。因此面向社交媒体的谣言检测,对于科技、经济、以及社会稳定和发展都具有非常重要的意义和价值,近年来,谣言检测也受到了更多的关注。
目前,许多研究者将谣言检测作为一个二分类问题来处理。近些年的研究工作大体上可以分为以下两类1)基于传统机器学习的谣言检测,主要集中在谣言事件的特征设计和选择上,通过手动提取的方式从事件消息中抽取显著的特征集,包括用户特征,内容特征,传播特征等,例如地理位置信息,质疑更正信号,情感极性,传播树特征。接着使用支持向量机、决策树等分类器进行分类,判断事件是否是谣言。该类方法取得了明显的效果,但是手工提取特征依赖于人工设计,需要消耗大量的时间和人力物力。2)基于特征表示学习的谣言检测,该类方法更多的是对谣言事件中的文本内容进行建模,通常对事件消息按照时间顺序分割成多个时间段,将每一个时间段内的帖子当成一个整体进行处理,接着对一个时间段的帖子计算出文本表示,然后通过各种神经网络,例如循环神经网络模型、卷积神经网络模型以及双向循环神经网络模型等对谣言事件进行学习,进而进行分类。但该方法忽视了时间段内微博的时序信息,因此,在此基础上,引入分层神经网络框架,首先对时间段的帖子采用合适的神经网络模型加以学习其潜在的隐层信息,最后再学习谣言的整体表示,取得了不错的效果。
但以上方法局限对文本内容捕捉其潜在的信息,而用户表示更多的依旧是采用传统的基于统计的方法对事件中用户行为进行统计计算,并以此作为用户表示,忽视了事件中用户表示潜在的时序信息对于谣言检测的重要性,谣言事件往往是由权威性较低的用户发布自己未经证实的观点为起点,进而被有影响力且权威性高的在线社区和用户转发和评论,最后在社交媒体中广泛传播,而用户粉丝数量、关注用户数、以及是否被认证等用户特征能够一定程度上反应用户的权威特性。在早期谣言检测任务中,消息传播初期通常存在大量的转发事件描述的重复信息,这些文本内容对于识别谣言并没有什么帮助,而用户特征则相对稳定,能够为早期谣言检测提供更加充分的特征线索。基于此,对谣言事件中的用户选择合适的算法进行表示学习,获取其潜在的变化规律,对于谣言检测,特别是早期谣言检测具有重要的意义和价值。
技术实现要素:
有鉴于此,本发明的目的是提供一种基于层次用户表示的面向社交媒体的谣言检测系统,能够自动抽取出有效特征,并对特征进行抽象和组合,最终检测出事件是否是谣言。
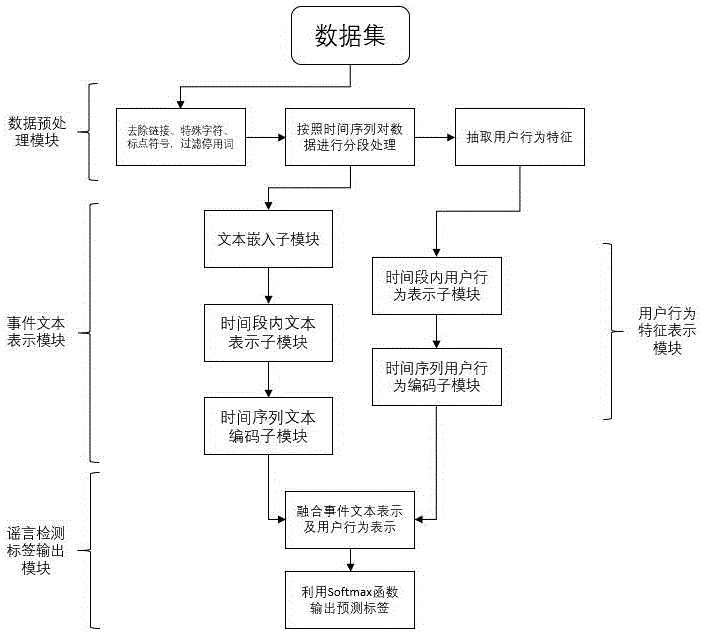
本发明采用以下方案实现:一种基于层次用户表示的面向社交媒体的谣言检测系统,包括数据预处理模块、文本表示模块、用户行为特征表示模块和谣言检测标签输出模块,所述数据预处理模块用于对谣言检测数据集,进行预处理,构造用户初始向量表示,按照微博/推特发布的时间对事件进行分段处理,每个时间段包含若干条帖子和相关用户,并将所输出的文本数据和用户初始特征向量分别作为文本表示模块以及用户行为特征表示模块的输入;所述文本表示模块用于从微博/推特社交媒体文本层面以及时间段层面学习词语序列和时间段文本序列所蕴含的隐层表达,作为事件文本特征向量,所述用户行为特征表示模块用于捕获用户行为特征潜在的变化规律及其隐层信息,作为事件用户特征向量,并将所述文本表示模块输出的事件文本特征向量与用户行为特征表示模块输出的事件用户特征向量作为所述谣言检测标签输出模块的输入,最终所述谣言检测标签输出模块输出预测事件所预测的标签,其中1代表谣言事件,0代表非谣言事件。
进一步地,所述数据预处理模块对谣言检测数据集进行预处理具体包括以下步骤:
步骤s1:通过正则匹配式去除文档中的网页链接、特殊字符和标点符号;采用结巴分词对中文文档进行分词处理,根据中英文的停用词表分别过滤掉数据集中包含的停用词;
步骤s2:数据预处理模块构造用户初始向量表示;用户行为特征包括推文内容长度、推文内容是否包含质疑或纠正短句、用户是否认证、用户个人描述内容长度、用户关注的用户的数量和用户的粉丝数量,对上述特征进行拼接,作为用户初始向量表示;除了判断是否包含质疑或纠正语气词需要额外利用正则匹配式进行提取外,其余用户行为特征均已包含在谣言检测数据集中;
步骤s3:将事件相关消息按照微博/推特发布的时间划分成不同的时间段,每个时间段中包含若干微博/推特内容以及所对应的用户,保证每个时间段内具有基本相同的微博密度。
进一步地,所述文本表示学习模块包括文本词嵌入表示、社交媒体文本表示和时间段表示。
进一步地,所述文本词嵌入表示将数据中的文本信息映射到便于计算机处理的向量空间,采用100维glove词向量模型对推特数据进行转换,而微博数据基于word2vec算法将微博文本转换成词向量e(wi),wi表示第i个单词。
进一步地,所述社交媒体文本表示采用循环卷积神经网络学习时间段内的文本信息,循环卷积神经网络包括一个双向长短期记忆神经网络和一个卷积神经网络;将文本词嵌入表示中获得的词向量e(wi)输入到双向长短期记忆神经网络中得到上下文隐层状态,假设hl(wi)是单词wi上一个单词的隐层向量,而hr(wi)是单词下一个单词的隐层状态,计算公式如下:
hl(wi)=f(wlhl(wi-1)+wele(wi-1))
hr(wi)=f(wrhr(wi+1)+were(wi+1))
其中,e(wi-1)和e(wi+1)分别为单词wi-1和单词wi+1的词向量表示;hl(wi-1)和hr(wi+1)分别代表单词wi-1和单词wi+1的隐层状态;wl,wel,wr,wer分别为各自的权重矩阵;f是一个非线性激活函数tanh;hl(wi)是单词wi的上一个单词的隐层状态,hr(wi)是单词wi的下一个单词的隐层状态;当计算获得当前单词wi的两个上下文隐层状态hl(wi)和hr(wi)之后,将两个状态与当前单词的词词向量进行拼接操作,即
xi=(hl(wi),e(wi),hr(wi))
接着采用卷积神经网络学习对xi捕获局部特征,并使用一个最大池化操作将不同长度的文本表示向量转换为固定长度,从而获得每个时间段的文本特征表示向量,具体公式如下:
ci=conv1d(xi)
其中ci是xi经过一维卷积conv1d操作之后的结果,yt是表示第t个时间段学习到的文本特征表示向量。
进一步地,所述时间段表示利用双向门控循环神经网络(bi-gru)从时间段层面学习时间段序列的隐层表示,作为事件的文本表示向量;
ht=(htf,htb)
其中,htf为前向gru神经网络在时间段t生成的隐层表示,htb为后向gru神经网络在时间段t生成的隐层表示,tn为时间段的长度,即时间段数量;ht是双向gru神经网络在第t个时间段的输出,由htf和htb连接得到;并结合注意力机制能够有所侧重考虑到各时间段的信息,最终作为事件的整体文本表示;注意力公式如下:
ut=tanh(whht+bh)
其中ut是双向门控循环神经网络(bi-gru)的输出ht采用tanh激活函数处理后得到的结果;而βt是经过注意力机制计算出的权重值,而ve是对每个时间段文本特征向量加权求和表示。
进一步地,所述用户行为特征表示学习模块包括社交媒体用户行为表示和时间段序列用户行为表示;
所述社交媒体用户行为表示将时间段内的用户行为特征以数据预处理阶段构造用户行为表示的初始向量xt作为输入,利用循环神经网络(lstm)和卷积神经网络(cnn)分别学习社交媒体用户行为特征潜在全局和局部变化规律,为谣言的检测提供判别线索,具体计算公式如下;
hc=meanpooling1d(cnn(xt))
hr=lstm(xt)
ht=(hc,hr)
hc为用户行为表示的初始向量xt,使用卷积神经网络捕获其局部特性,并经过平均池化操作的隐层输出;hr为循环神经网络的输出;ht为对hc,hr两个隐层向量进行拼接操作的结果;
所述时间段序列用户行为采用门控循环单元神经网络(gru)对各个时间段的用户行文特征隐层表示进一步学习其蕴含的时序信息,作为事件的整体用户表示;
vu=gru(ht)
其中ht是每个时间段用户特征向量,vu是门控循环单元网络(gru)学习到的时间段用户特征表示。
进一步地,谣言检测标签输出模块将文本表示模块以及用户行为特征表示模块所学习到的文本特征向量以及用户行为特征向量进行融合,作为事件的整体特征向量,并使用softmax函数对于该隐层向量进行计算,输出其预测标签;
最后将事件整体文本表示ve以及整体用户表示vu进行拼接操作,送入一个全连接层,并使用softmax函数进行激活,得到社交媒体事件的标签
与现有技术相比,本发明具有以下有益效果:
本发明能够较好地对社交媒体上的谣言事件进行检测,并且在早期谣言检测中具备更加快速和稳定的检测效果。
附图说明
图1为本发明实施例的谣言检测系统的示意配置图。
图2为本发明实施例的模型图。
具体实施方式
下面结合附图及实施例对本发明做进一步说明。
应该指出,以下详细说明都是例示性的,旨在对本申请提供进一步的说明。除非另有指明,本文使用的所有技术和科学术语具有与本申请所属技术领域的普通技术人员通常理解的相同含义。
需要注意的是,这里所使用的术语仅是为了描述具体实施方式,而非意图限制根据本申请的示例性实施方式。如在这里所使用的,除非上下文另外明确指出,否则单数形式也意图包括复数形式,此外,还应当理解的是,当在本说明书中使用术语“包含”和/或“包括”时,其指明存在特征、步骤、操作、器件、组件和/或它们的组合。
如图1,2所示,本实施例提供一种基于层次用户表示的面向社交媒体的谣言检测系统,包括数据预处理模块、文本表示模块、用户行为特征表示模块和谣言检测标签输出模块,所述数据预处理模块用于对谣言检测数据集,进行预处理,构造用户初始向量表示,按照微博/推特发布的时间对事件进行分段处理,每个时间段包含若干条帖子和相关用户,并将所输出的文本数据和用户初始特征向量分别作为文本表示模块以及用户行为特征表示模块的输入;所述文本表示模块用于从微博/推特社交媒体文本层面以及时间段层面学习词语序列和时间段文本序列所蕴含的隐层表达,作为事件文本特征向量,所述用户行为特征表示模块用于捕获用户行为特征潜在的变化规律及其隐层信息,作为事件用户特征向量,并将所述文本表示模块输出的事件文本特征向量与用户行为特征表示模块输出的事件用户特征向量作为所述谣言检测标签输出模块的输入,最终所述谣言检测标签输出模块输出预测事件所预测的标签,其中1代表谣言事件,0代表非谣言事件。所述谣言检测数据集为公开的数据集。
所述数据预处理模块用于对谣言检测数据集,包括微博数据集、推特数据集进行预处理,即对事件相关消息文本内容进行清洗,构造用户初始向量表示,按照微博/推特发布的时间对事件进行分段处理,每个时间段包含若干条帖子和相关用户;所述文本表示模块用于从微博/推特社交媒体文本层面以及时间段层面学习词语序列和时间段文本序列所蕴含的隐层表达,作为事件文本特征向量;所述用户行为特征表示模块用于捕获用户行为特征潜在的变化规律及其隐层信息,作为事件用户特征向量;所述谣言检测标签输出模块用于融合文本表示模块以及用户行为特征表示模块所学习到的文本表示以及用户表示,完成谣言检测的标签预测工作。
在本实施例中,所述数据预处理模块对谣言检测数据集进行预处理具体包括以下步骤:
步骤s1:通过正则匹配式去除文档中的网页链接、特殊字符和标点符号;采用结巴分词对中文文档进行分词处理,根据中英文的停用词表分别过滤掉数据集中包含的停用词;
步骤s2:数据预处理模块构造用户初始向量表示;用户行为特征包括推文内容长度、推文内容是否包含质疑或纠正短句、用户是否认证、用户个人描述内容长度、用户关注的用户的数量和用户的粉丝数量,具体特征说明如表1所示,对上述特征进行拼接,作为用户初始向量表示;除了判断是否包含质疑或纠正语气词需要额外利用正则匹配式进行提取外,其余用户行为特征均已包含在谣言检测数据集中;
步骤s3:将事件相关消息按照微博/推特发布的时间划分成不同的时间段,每个时间段中包含若干微博/推特内容以及所对应的用户,保证每个时间段内具有基本相同的微博密度。
表1
在本实施例中,所述文本表示学习模块包括文本词嵌入表示、社交媒体文本表示和时间段表示。
在本实施例中,所述文本词嵌入表示将数据中的文本信息映射到便于计算机处理的向量空间,采用100维glove词向量模型对推特数据进行转换,而微博数据基于word2vec算法将微博文本转换成词向量e(wi),wi表示第i个单词。
在本实施例中,所述社交媒体文本表示采用循环卷积神经网络学习时间段内的文本信息,循环卷积神经网络包括一个双向长短期记忆神经网络和一个卷积神经网络;将文本词嵌入表示中获得的词向量e(wi)输入到双向长短期记忆神经网络中得到上下文隐层状态,假设hl(wi)是单词wi上一个单词的隐层向量,而hr(wi)是单词下一个单词的隐层状态,计算公式如下:
hl(wi)=f(wlhl(wi-1)+wele(wi-1))
hr(wi)=f(wrhr(wi+1)+were(wi+1))
其中,e(wi-1)和e(wi+1)分别为单词wi-1和单词wi+1的词向量表示;hl(wi-1)和hr(wi+1)分别代表单词wi-1和单词wi+1的隐层状态;wl,wel,wr,wer分别为各自的权重矩阵;f是一个非线性激活函数tanh;hl(wi)是单词wi的上一个单词的隐层状态,hr(wi)是单词wi的下一个单词的隐层状态;当计算获得当前单词wi的两个上下文隐层状态hl(wi)和hr(wi)之后,将两个状态与当前单词的词词向量进行拼接操作,即
xi=(hl(wi),e(wi),hr(wi))
接着采用卷积神经网络学习对xi捕获局部特征,并使用一个最大池化操作将不同长度的文本表示向量转换为固定长度,从而获得每个时间段的文本特征表示向量,具体公式如下:
ci=conv1d(xi)
其中ci是xi经过一维卷积conv1d操作之后的结果,yt是表示第t个时间段学习到的文本特征表示向量。
循环卷积神经网络能够更大程度地捕捉时间段内长文本中所隐含的上下文信息,并且能够更大范围地保留词序信息。通过循环卷积神经网络捕获时间段内文本内容上下文依赖关系,获取其隐层向量表示。
在本实施例中,所述时间段表示利用双向门控循环神经网络(bi-gru)从时间段层面学习时间段序列的隐层表示,作为事件的文本表示向量;
ht=(htf,htb)
其中,htf为前向gru神经网络在时间段t生成的隐层表示,htb为后向gru神经网络在时间段t生成的隐层表示,tn为时间段的长度,即时间段数量;ht是双向gru神经网络在第t个时间段的输出,由htf和htb连接得到;并结合注意力机制能够有所侧重考虑到各时间段的信息,最终作为事件的整体文本表示;注意力公式如下:
ut=tanh(whht+bh)
其中ut是双向门控循环神经网络(bi-gru)的输出ht采用tanh激活函数处理后得到的结果;而βt是经过注意力机制计算出的权重值,而ve是对每个时间段文本特征向量加权求和表示。
在本实施例中,所述用户行为特征表示学习模块包括社交媒体用户行为表示和时间段序列用户行为表示;
所述社交媒体用户行为表示将时间段内的用户行为特征以数据预处理阶段构造用户行为表示的初始向量xt作为输入,利用循环神经网络(lstm)和卷积神经网络(cnn)分别学习社交媒体用户行为特征潜在全局和局部变化规律,为谣言的检测提供判别线索,具体计算公式如下;
hc=meanpooling1d(cnn(xt))
hr=lstm(xt)
ht=(hc,hr)
hc为用户行为表示的初始向量xt,使用卷积神经网络捕获其局部特性,并经过平均池化操作的隐层输出;hr为循环神经网络的输出;ht为对hc,hr两个隐层向量进行拼接操作的结果;
所述时间段序列用户行为采用门控循环单元神经网络(gru)对各个时间段的用户行文特征隐层表示进一步学习其蕴含的时序信息,作为事件的整体用户表示;
vu=gru(ht)
其中ht是每个时间段用户特征向量,vu是门控循环单元网络(gru)学习到的时间段用户特征表示。
在本实施例中,谣言检测标签输出模块将文本表示模块以及用户行为特征表示模块所学习到的文本特征向量以及用户行为特征向量进行融合,作为事件的整体特征向量,并使用softmax函数对于该隐层向量进行计算,输出其预测标签;
最后将事件整体文本表示ve以及整体用户表示vu进行拼接操作,送入一个全连接层,并使用softmax函数进行激活,得到社交媒体事件的标签
较佳的,在本实施例中,数据预处理模块中所述的数据预处理,对文本数据去除噪声,比如去除文本中的链接、特殊字符、标点符号等,过滤文本中的停用词。
较佳的,在本实施例中,数据预处理模块中所述的按照时间序列对数据进行分段处理,即将推文按照时间顺序,并选择合适的算法对推文集合进行切分,使得推文尽量均匀地分布在每个时间段,每个时间段内都有一定的推文。
较佳的,在本实施例中,文本嵌入表示学习借助了开源的glove模型,将时间段内的推文内容分别映射到低维的语义空间中获取词向量表示。
较佳的,在本实施例中,时间段序列文本表示采用双向门控循环神经网络从时间段层面学习时间段序列的隐层表示,并结合注意力机制能够有所侧重考虑到各时间段的信息,最终作为事件的整体文本表示。
较佳的,在本实施例中,事件用户行为特征表示学习模块包含两个部分:时间段内用户行为表示、时间段序列用户行为表示;时间段内用户行为表示将时间段内的用户行为建模为有序时间序列,并利用循环神经网络和卷积神经网络分别学习用户行为特征的潜在全局和局部变化规律,为谣言的检测提供判别线索。时间序列用户行为表示采用门控循环神经网络对每个时间段的用户行为表示进一步学习其蕴含的时序信息,作为事件的整体用户表示。
较佳的,在本实施例中,谣言检测标签输出模块将事件文本表示模块以及事件用户行为特征表示模块所学习到的事件文本表示以及事件用户行为表示进行融合,作为事件的整体特征向量,并使用softmax函数对于该隐层向量进行计算,输出其预测标签。
以上所述仅为本发明的较佳实施例,凡依本发明申请专利范围所做的均等变化与修饰,皆应属本发明的涵盖范围。
- 还没有人留言评论。精彩留言会获得点赞!