一种基于预训练模型的古体诗自动生成方法与流程
[0001]
本发明涉及一种自然语言处理技术,具体为一种基于预训练模型的古体诗自动生成方法。
背景技术:
[0002]
现如今,深度学习技术得到了极大的发展,且在图像识别、语言识别、机器翻译、文本生成等任务上取得了重大突破,相比之前基于规则和模板的古体诗自动生成方法,基于深度学习的古体诗自动生成方法可以生成更好的古体诗质量,生成结果更加主题明确、流畅通顺。然而,目前大多基于深度学习的古体诗自动方法通常都是由若干个负责生成某一句的模型组成,相对复杂,比如基于rnn encoder-decode框架的经典做法就是由4个模型组成,首先由用户给定的关键词生成第一句,然后由第一句生成第二句,由一,二句生成第三句,由一,二,三句生成第四句,这个过程中每个模型负责生成一句,单独训练。这种方法虽然已经取得不错的效果,但整体相对复杂,而且解码速度较慢。
[0003]
基于深度学习技术的模型存在的一个问题是对数据的依赖性极强,如果有足够的训练数据,那么模型就可以达到比较好的生成效果,而古体诗作为一种领域稀缺的数据,其数据量是有限的而且并不是很大,从唐到清大概有三十多万首,针对自然语言处理技术而言属于数据稀缺,这样存在的一个潜在问题就是可能无法充分训练模型,比如用户输入一个偏现代词语的关键词,由于古体诗数据中这种词往往是低频词,所以效果会比较差,因此生成的古体诗质量有待提高,运用预训练技术可以在一定程度上缓解这个问题。
技术实现要素:
[0004]
针对现有技术中古体诗自动生成系统没有充分的双语语料导致模型的生成效果不佳等不足,本发明要解决的技术问题是提供一种基于预训练的古体诗自动生成方法,能够在有限的古体诗训练数据下,充分利用大规模单语语料预训练语言模型任务,然后将预训练模型提取到的信息迁移到古体诗生成模型中,显著提高模型的生成质量。
[0005]
为解决上述技术问题,本发明采用的技术方案是:
[0006]
本发明公开一种基于预训练模型的古体诗自动生成方法,包括以下步骤:
[0007]
1)收集海量的单语语料,包括现有古体诗词、文言文,然后进行分词数据预处理,使用单语语料训练语言模型得到预训练模型;
[0008]
2)利用收集到的现有古体诗数据构建训练语料,得到古体诗的训练数据;
[0009]
3)利用步骤2)中提取到的关键词训练一个语言模型作为关键词扩展模块;
[0010]
4)利用步骤2)中构建好的古体诗训练语料在步骤1)中训练好的预训练模型上进行微调;
[0011]
5)将用户输入的关键词利用步骤3)中的关键词扩展模块进行扩展并结合格式控制符构建成模型输入,送入到训练好的模型中生成古体诗。
[0012]
步骤1)中,收集中文单语语料和现有古体诗词、文言文语料,对数据进行预处理,
利用公开脚本进行清洗、分词操作形成训练数据,然后利用开源预训练模型进行语言模型任务的训练,最终得到收敛的预训练模型参数。
[0013]
在步骤2)中,构建古体诗训练语料具体为:
[0014]
201)利用关键词提取技术从现有每句古体诗中提取出关键词组成整首古体诗的关键词,每一句保留一个关键词作为提取结果,将各句的提取结果拼接形成关键词序列;
[0015]
202)关键词序列结合古体诗格式控制序列以及二者之间加设的标识符形成训练数据中的头部,其中,格式控制包括五言绝句、七言绝句、五言律诗、七言律诗;
[0016]
203)将古体诗的内容看做一个序列,即将每一句进行首尾拼接形成古体诗内容序列作为训练数据中的内容,最终古体诗序列化为格式化的文本序列<格式控制+关键词+古体诗内容>。
[0017]
在步骤3)中,用关键词序列训练一个语言模型作为关键词扩展模块,具体为:
[0018]
对于关键词序列w:w1,w2,...,w
n
,利用双向单层循环神经网络模型训练一个语言模型,一元、二元、三元的语言模型定义如下:
[0019][0020][0021][0022]
其中p为序列w的概率,wi为w中的第i个单词,n为序列w的长度。
[0023]
采用双向单层循环神经网络模型进行优化训练,最后得到一个关键词扩展模块,该模块用于扩展用户输入的关键词,丰富模型的输入信息,这样使得模型生成的古体诗整体会更加主题明确和具有相关性。
[0024]
在步骤4)中,利用古体诗训练语料在步骤1)中预训练好的模型上进行微调,具体为:
[0025]
将构建好的古体单语数据输入模型中训练一个自回归语言模型,其目标是优化任何观测到的序列,使其生成的概率最大化:
[0026][0027]
其中p为序列x的生成概率,xi为序列x中的第i个单词。微调只需要进行4-6轮训练即可。
[0028]
步骤5)包括:
[0029]
501)对于用户输入的关键词,如果关键词的个数是i个,则先用关键词扩展模型预测另外4-i个关键词,最后将最多4个关键词结合格式控制,二者之间用标识符隔开组成模型输入序列;
[0030]
502)模型在解码时,模型会自动在需要位置预测出逗号和句号,保证新生成的古
体诗形式正确,当模型预测到终止标识符时,解码过程结束;
[0031]
503)整个解码过程采用束搜索来获得多个生成结果,保证内容的多样性。
[0032]
本发明具有以下优点:
[0033]
1.本发明提出了基于预训练的古体诗自动生成方法,通过海量的单语数据预训练语言模型,然后用构建的古体诗训练数据进行微调,通过在大量单语数据中进行预训练,可以将学习到的知识迁移到古体诗生成任务中,显著提高生成的古体诗内容的质量。
[0034]
2.本发明整体架构相对简单,只用一个模型就可以生成四种体裁的古体诗,不需要任何人工设定规则或者特性,也没有设计任何额外的神经元组件,完全靠模型自动学习到古体诗规则,不仅可以显著提高生成质量,还可以加快解码速度。
[0035]
3.本发明从实际应用角度来看,其成果可以封装成api,直接对外提供服务,如以下几种应用场景:诗词教育——用作诗词教育的辅助工具,帮助学生了解诗词中的关键词、意象、押韵等元素是如何在诗词中起作用的;文学研究——课题关于词频、意象之间的关系的发现,能给文学研究带来一定的启发作用;娱乐场景——如朋友圈、qq空间等,能大大降低普通人进行诗歌创作的门槛,使其广泛用于日常交流娱乐,人们可以轻易通过诗意的方式去表达自己的情感。
附图说明
[0036]
图1为本发明基于预训练模型的古体诗自动生成方法涉及的关键词扩展模块;
[0037]
图2为关键词扩展模块用到的gru模型结构图示;
[0038]
图3为本发明中预训练模型gpt2的结构图示;
[0039]
图4为本发明中古体诗的训练数据序列图示。
具体实施方式
[0040]
下面结合说明书附图对本发明作进一步阐述。
[0041]
本发明提供一种基于预训练的古体诗自动生成方法,包括以下步骤:
[0042]
1)收集海量的单语语料,包括现有古体诗词、文言文,然后进行分词数据预处理,使用单语语料训练语言模型得到预训练模型;
[0043]
2)利用收集到的现有古体诗构建训练语料,得到古体诗的训练数据和关键词;
[0044]
3)利用步骤2)中提取到的关键词训练一个语言模型作为关键词扩展模块(如图1所示);
[0045]
4)利用古体诗训练语料在步骤1)中训练好的预训练模型上进行微调;
[0046]
5)将用户输入的关键词利用步骤3)中的关键词扩展模块进行扩展并结合格式控制符构建成模型输入,送入到训练好的预训练模型中生成古体诗。
[0047]
步骤1)中,收集中文单语语料和现有古体诗词、文言文语料,利用公开脚本进行清洗、分词操作形成训练数据,然后利用开源预训练模型进行语言模型任务的训练,最终得到收敛的预训练模型参数。
[0048]
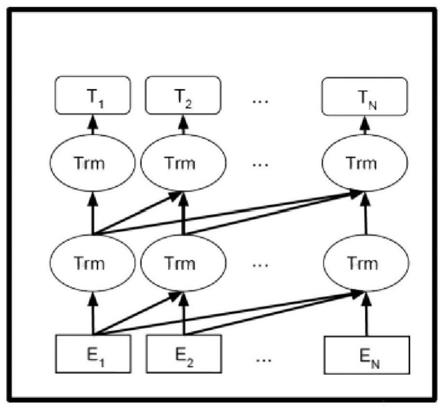
本步骤采用wiki中文数据集、一些公开的中文数据集和爬取到的现存古诗词、文言文数据进行预训练,预训练语言模型基于语言模型任务从单语语料中学习知识,本发明中采用gpt2作为预训练模型,即transformer的decoder,gpt2的模型架构基于多层单向转
换解码,预训练模型gpt2的结构如图3所示,通过训练模型训练一个语言模型,具体如下:
[0049]
给定一个大型单语语料,通过前述数据预处理过程最终可以得到单句的训练数据集合,记其中每一个序列为u={u1,u2,
…
},gpt2通过最大化以下似然函数来训练语言模型:
[0050][0051]
其中,k表示上下文窗口的大小,ui代表序列中的第i个词,p代表序列的生成概率,theta代表模型的参数。由于使用的是单向模型,所以计算每个单词的预测概率时只考虑左侧窗口大小的词汇信息。
[0052]
步骤2)中,构建古体诗训练语料具体为:
[0053]
201)利用关键词提取技术从每句现有古体诗中提取出关键字组成整首古体诗的关键词,每一句保留一个关键词作为提取结果,将各句的提取结果拼接形成关键词序列;
[0054]
202)关键词序列结合古体诗格式控制序列以及二者之间加设的标识符形成训练数据中的头部;(如图4所示)
[0055]
203)将古体诗的内容看做一个序列,即将每一句进行首尾拼接形成古体诗内容序列作为训练数据中的内容,最终古体诗序列化为格式化的文本序列<格式控制+关键词+古体诗内容>。
[0056]
为了能让模型利用到更多有用的信息,分别对每一句诗进行关键词提取,采用top1做为结果,最终对于每首诗提取出四个关键词作为模型生成一首诗的创作信息,为了能够控制古体诗的格式,在关键词序列头部加上格式控制信息“五言绝句”、“七言绝句”、“五言律诗”、“七言律诗”作为模型的软约束,由于格式控制信息和古诗内容是一种强关联,因此模型能自动从中学到控制信息,从而保证生成内容格式的正确性。
[0057]
步骤3)中,用关键词序列训练一个语言模型作为关键词扩展模块,具体为:
[0058]
对于关键词序列w:w1,w2,...,w
n
,利用双向单层循环神经网络模型训练一个语言模型,一元、二元、三元的语言模型定义如下:
[0059][0060][0061][0062]
其中p为序列w的概率,wi为w中的第i个单词,n为序列w的长度。
[0063]
采用双向单层循环神经网络模型进行优化训练,最后得到一个关键词扩展模块,该模块用于扩展用户输入的关键词,使每一句拥有一个关键词,这样使得模型生成的古体诗整体会更加主题明确和具有相关性。
[0064]
对于关键词来说由于训练的时候是四个关键词生成一首新的古体诗,而用户输入
并不一定有四个关键词,所以需要训练一个关键词扩展模块来对关键词扩展到四个,对于一组关键词w1,w2,..,w4,构建成语言模型训练数据<w1,w2>,<w1w2,w3>,<w1w2w3,w4>,然后采用双向单层gru进行训练。
[0065]
在步骤4)中,利用古体诗训练语料在步骤1)中训练好的预训练模型上进行微调,具体为:
[0066]
将所有古体诗序列输入模型中训练一个自回归语言模型,其目标是优化任何观测到的序列,使其生成的序列概率最大化:
[0067][0068]
其中p为序列x的生成概率,xi为序列x中的第i个单词微调只需要进行4-6轮训练即可,否则如果训练轮数太多,模型就会倾向于从古体诗语料库中直接用原始句子。用构建好的古体诗双语数据进行微调时,大部分模型的超参数跟预训练时差不多,因为古体诗数据集较少,batchsize,学习率,epochs等超参数需要手动调整。
[0069]
在步骤5)中,将用户输入的关键词利用关键词扩展模块进行扩展并结合格式控制符构建成模型输入,具体包括:
[0070]
501)对于用户输入的关键词,如果关键词的个数是i个,则先用关键词扩展模型预测另外4-i个关键词,最后将最多4个关键词结合格式控制,二者之间用标识符隔开组成模型输入序列;
[0071]
502)模型在解码时,会自动在需要位置预测出逗号和句号,保证新生成的古体诗形式正确,当模型预测到终止标识符“eos”时,解码过程结束;
[0072]
503)整个解码过程采用束搜索来获得多个生成结果,保证内容的多样性。
[0073]
步骤5)不使用硬约束来保证格式的正确性,由于输入中具有很强的提示信息,模型会自动在合适的位置预测出逗号和句号。模型训练完成后,将用户输入的关键词送入到关键词扩展模块中扩展至4个,然后在头部加上格式控制信息,最后输入到模型中,模型通过束搜索生成结果。
[0074]
本实施例采用gpt2作为预训练模型,gpt2使用语言模型在海量的单语语料上训练,是目前最常用的预训练模型;关键词扩展模块使用gru(gru模型结构如图2所示),相比传统rnn,它具有更好的性能和效率,在数据集方面,从网上爬取了从唐至清大约三十万首来构建微调数据集。
[0075]
本发明方法在有限的古体诗数据条件下,利用海量的单语数据预训练语言模型,构造古体诗训练语料进行微调,从而提高生成质量。
[0076]
评价古体诗的质量是一项比较困难的工作,目前还没有专门的自动评价方法,虽然可以使用机器翻译中的bleu作为古体诗词的自动评价方法,但与人工评价相比,bleu不足以充分体现一种古体诗词生成方法的有效性。就目前来看,人工评估在古体诗生成任务上是一种最有效的评估方法。本发明采用人工评价方法,从前后押韵、语言流畅、内容一致、意义四个部分去判断生成的古体诗好坏,每个部分设置最高分为5分,得分越高越好。在本发明中,系统在语言流畅、内容一致、意义等更方面得分都比基线高,押韵度略有下降。本系统的特点在于面对用户输入的关键词是现代词语的情况下比较有效,这些词语在古体诗数
据集中大多是低频词,然而通过预训练模型,这些词在大量单语数据中得到了充分的学习,这证明了本方法的有效性。
[0077]
目前主流的自然语言处理范式是以gpt为代表的“预训练+微调”的方法。其基本思想是将大型的端到端神经网络模型的训练分为两步进行:首先,在大规模单语数据上进行无监督训练,其优化目标通常是一个语言模型,待训练完成后,在特定的自然语言处理任务中加入与任务相关的神经网络然后根据特定下游任务的双语数据进行微调。通过这种方式,模型可以通过预训练将从大规模单语数据中学习到的语言知识迁移到下游的自然语言处理和生成任务模型的学习中。预训练语言模型在几乎所有的自然语言下游任务中都取得了优异的性能,包括命名实体识别、文本蕴含、问答、语义角色标注、指代消解和情感分析等。本发明利用该方法来自动生成古体诗,从而从一定程度上克服古体诗数据集稀缺的问题。
[0078]
下面以一个具体的生成案例为例子:
[0079]
比如用户输入“雪后凋”作为关键词,选择生成七言绝句,模型的处理过程如下:
[0080]
1.如果需要进行关键词扩展,则先利用关键词扩展模块对用户的输入关键词“雪后凋”进行扩展,否则直接进行下一步;
[0081]
2.将关键词和格式控制符构造成如下形式:“七言绝句#雪后凋#”,将此序列送到模型中,设置超参数beam=5
[0082]
3.模型输出如下生成结果:
[0083]
雪后园林冻未消,
[0084]
梅花如雪柳如条。
[0085]
东风不管人憔悴,
[0086]
吹作飞花满地飘。
[0087]
可以看到,生成的古诗在内容上主题明确,比如“雪”、“冻”、“梅”、“飘”等字描写的都是冬天下雪,万物凋零的景象;在格律上合辙押韵,比如“消、条、飘”。
[0088]
模型在训练时,能够从训练数据中学习到古诗的一些规律,比如有关“雪”的诗,它的特征是和冬天有关,那么它的内容里面很可能有冬天、梅花等相关信息,当用户输入“雪后凋”关键词时,模型就会自动使用这些信息来生成古诗内容,由于输入模型的信息头部控制信息指示了模型生成古诗的类型是“七言绝句”,所以模型会在生成七个字后就预测出逗号和句号,从而保证生成的内容格式正确。
[0089]
本发明通过预训练从大规模文本数据中学到的语言知识,迁移到下游的自然语言处理和生成任务模型的学习中。预训练语言模型在几乎所有自然语言的下游任务,不管是自然语言理解(nlu)还是自然语言生成(nlg)任务上都取得了优异的性能。对于古体诗自动生成任务,由于其数据有限,因此采样预训练的方法可以让模型从大规模的单语数据中更加充分的学习到潜在的知识,然后将其应用到古体诗生成任务中,从而从一定程度上克服古体诗数据集稀缺的问题,并提高了系统对于低频词的生成效果。
相关技术
网友询问留言
已有0条留言
- 还没有人留言评论。精彩留言会获得点赞!
1