一种基于机器学习的学业异常预测方法与流程
本发明涉及数据预测技术领域,特别涉及一种基于机器学习的学业异常预测方法。
背景技术:
随着校园一卡通的普及,学生在校生活消费、成绩、图书馆借阅等数据逐年翻倍增加。目前国内大部分高校正致力于智慧校园建设,智慧校园建设的一个重要部分是充分利用校园一卡通数据进行数据挖掘,通过数据挖掘技术能够发现学生日常生活中的隐藏信息,进而对学生管理和校园治理提供有力的决策支持。学生在校的学习状况一直是家长、学校最关心的问题,学校的综合水平同在校学生的学习状况息息相关,因此如何挖掘学生一卡通数据及时发现学业异常的学生并进行督促与辅导是高校所关心的问题。基于上述问题,本发明提出一种基于机器学习的学业异常预测方法。
技术实现要素:
为了克服上述现有技术的不足,本发明的目的在于提供一种基于机器学习的学业异常预测方法,通过收集学生在校的一卡通和成绩相关数据,采用机器学习的方法预测学业异常学生,为高校学生管理工作提供帮助。
为了实现上述目的,本发明采用的技术方案是:
一种基于机器学习的学业异常预测方法,包括以下步骤;
步骤一:
针对某高校学生一卡通数据进行数据预处理,并按学校毕业要求的相关规定标定学业异常学生和非学业异常学生;
步骤二:
采用dpca(desitypeaksclusteringalgorithm)对训练集中的非学业异常学生(多数类)聚类,按照聚类结果中不同簇的数量比例以不同的采样率进行欠采样,最后将欠采样后的数据与原训练集中的学业异常学生(少数类)合并形成新的训练集。
所述步骤一中的学业异常学生为学分低于2.5分,将学分不达标的学生标为1,学分达标的学生标为-1。
所述步骤二中dpca-adaboost的详细流程如下:
输入:
样本的训练集t={(x1,y1),(x2,y2),…,(xn,yn)},xi为特征数据,训练集中有n个样本,yi属于标记集合{1,-1};adaboost模型弱分类器的个数为m,弱分类器gm(x);
步骤1:
标记训练集t的类别;将训练集中的非学业异常类标记为-1,学业异常类标记为1;
步骤2:
dpca密度峰值聚类非学业异常类;选取yi=-1的数据集合作为dpca的输入并绘制决策图,选择决策图中聚类中心距离σ大且局部密度ρ相对较大的点作为簇中心点,之后将其余点划分到距离其最近且密度比自身大的同一簇中;
步骤3:
欠采样和合并数据集;根据每个簇的样本个数si、学业异常类的样本个数l和非学业异常类的样本个数m计算每个簇的采样率ωi,以采样率ωi对dpca聚类后的数据欠采样,之后将采样后的样本与学业异常类进行合并得到新的训练集数据;
步骤4:
初始化步骤3得到的新的训练集权值分布;式(2)中i表示第i个数据对象,训练集中数据个数为n;
w1i表示第i个数据对象的权值;
步骤5:
多次训练得到不同的弱分类器,用m=1,2,…,m表示第几个弱分类器;
a.训练权值分布为d(i)的样本集得到弱分类器gm(x);
b.计算弱分类器gm(x)的误差率
c.计算弱分类器在最终模型中的权重
d.计算新的权值分布如式(3)所示,zm是规范化因子。
步骤6:
最终的分类器模型:
gm(x)表示第m个弱分类器的输出值,其取值为-1或者1,误差率
dm+1(i)=(wm+1,1,wm+2,2,…,wm+1,i,…,wm+1,n),
所述步骤3中欠采样采样率ω定义如式(1)所示;
上式中l代表原始数据集中学业异常类的样本个数,m代表原始数据集中非学业异常类的样本个数,dpca选取的簇中心个数是c个,si是第i个簇中心的样本个数。
所述样本是原始采集到的学生数据集合,学生数据集合包含很多属性列,包括学分、消费数据、借阅图书数据;
对学分属性列按照低于2.5分的标记为1,1表示学业异常学生;高于2.5分的标记为-1表示为非学业异常学生,样本中除学分属性列的其他特征属性的学生数据为特征数据,按照学分标准划分的-1,1属性列的学生数据为标记集合。
所述样本需要按照一定的比例划分为训练集和测试集,一部分学生数据为训练集,另一部分学生数据为测试集,训练集用于训练模型,测试集用于测试模型,训练集和测试集中均包含异常学生和非异常学生。
使用训练集训练好模型后,用测试集的特征属性列数据去预测标记集合列,也就是输出为1表示学业异常,输出为-1表示非学业异常。
本发明的有益效果:
本发明采用密度峰值聚类算法可以解决传统k-means算法不能解决的非球状簇的分类问题且算法涉及的经验成分更少。
本发明采用的欠采样算法能够保留原始数据多数类中的数据分布特征。
本发明模型相较svm和rf算法g-mean值分别提升了17%和3%。因此,dpca-adaboost模型能较好应用在学业异常学生分类的场景。
附图说明
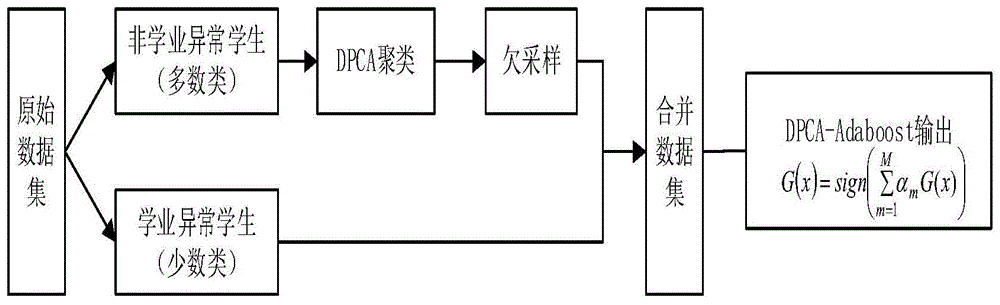
图1是本发明模型结构示意图。
图2是本发明模型的混淆矩阵示意图。
表1是本发明模型与svm和rf模型性能对比。
具体实施方式
下面结合实施例对本发明作进一步详细说明。
参见附图1,dpca-adaboost的详细流程如下:
输入:
样本的训练集t={(x1,y1),(x2,y2),…,(xn,yn)},xi为特征数据,训练集中有n个样本,yi属于标记集合{-1,+1};adaboost模型弱分类器的个数为m,弱分类器gm(x)。
算法:
步骤1标记训练集t的类别;将训练集中的非学业异常类标记为-1,学业异常类标记为1。
步骤2dpca密度峰值聚类非学业异常类;选取yi=-1的数据集合作为dpca的输入并绘制决策图,选择决策图中聚类中心距离σ大且局部密度ρ相对较大的点作为簇中心点,之后将其余点划分到距离其最近且密度比自身大的同一簇中。
步骤3欠采样和合并数据集;根据每个簇的样本个数si、学业异常类的样本个数l和非学业异常类的样本个数m计算每个簇的采样率ωi。以采样率ωi对dpca聚类后的数据欠采样,之后将采样后的样本与学业异常类进行合并得到新的训练集数据。
步骤4初始化新的训练集权值分布;式(2)中i表示第i个数据对象,训练集中数据个数为n。
步骤5多次训练得到不同的弱分类器,用m=1,2,…,m表示第几个弱分类器;
a.训练权值分布为d(i)的样本集得到弱分类器gm(x);
b.计算弱分类器gm(x)的误差率
c.计算弱分类器在最终模型中的权重
d.计算新的权值分布如式(3)所示,zm是规范化因子。
步骤6最终的分类器模型:
参见图2,本发明模型的混淆矩阵,为了验证本发明的优势,对本发明模型进行实验验证。
(1)数据选取某高校的不同学院2016-2017学年毕业年级学生校园一卡通数据和学生成绩数据,具体涉及图书馆借阅和门禁数据、生活等方面的原始数据,共计3668名学生数据。
(2)本发明选取的特征包括食堂消费数据、图书借阅和门禁数据、学生成绩数据;学生成绩数据包括学生的学分和排名。设定5点-9点为早餐时间,根据时间和日期属性统计学生各方面的数据,得到7维特征属性包括借阅图书的数量、进入图书馆的次数、消费次数、消费总金额、吃早餐的次数、淋浴次数、接开水次数。
(3)本发明认为学分低于2.5分的学生为学业异常学生,将学分不达标的学生标为1,学分达标的学生标为0。
(4)dpca-adaboost模型实验结果:tp(truepositive):将学业异常学生预测为学业异常学生。fn(falsenegative):将学业异常学生预测为非学业异常学生。fp(falsepositive):将非学业异常学生预测为学业异常学生。tn(truenegative):将非学业异常学生预测为非学业异常学生。
参见表1,本发明模型与svm算法和rf算法性能比对。本发明算法的查准率和查全率较rf算法提高了4%,较svm算法提高了12%。本发明算法f1值为60.67%,g-mean值为61.85%,而svm算法和rf算法的f1值和g-mean值均没有达到60%,预测性能不佳。
表13种分类算法的对比结果
- 还没有人留言评论。精彩留言会获得点赞!