一种基于工作流的大数据分析方法与流程
1.本发明涉及大数据分析技术领域,具体为一种基于工作流的大数据分析方法。
背景技术:
2.工作流(workflow)属于计算机支持的协同工作(computersupportedcooperativework,cscw)的一部分,是工作流程的计算模型,即将工作流程中的工作如何前后组织在一起的逻辑和规则在计算机中以恰当的模型进行表示并对其实施计算。
3.工作流要解决的主要问题是:为实现某个业务目标,在多个参与者之间,利用计算机,按某种预定规则自动传递,目前的工作流的大数据分析存在高效率损耗,动态数据可视效率低等问题,因此需要一种可以把基于因果关系的数据探索转变为流水线的方法,支持程序、自动化执行重复性的任务、数据捕获记录以及不同细节层次上的复杂数据分析过程的重用之间的转移,为程序流水线提供更多的便利为此,我们推出一种基于工作流的大数据分析方法。
技术实现要素:
4.本发明提供了一种基于工作流的大数据分析方法,具备本发明可有效地连接数据分析管线的不同阶段,减少创建可视化实例以及程序转移的效率损耗,提高动态数据可视效率的优点,解决了目前的工作流大数据分析在创建可视化实例以及程序转移的过程中存在效率损耗的问题问题。
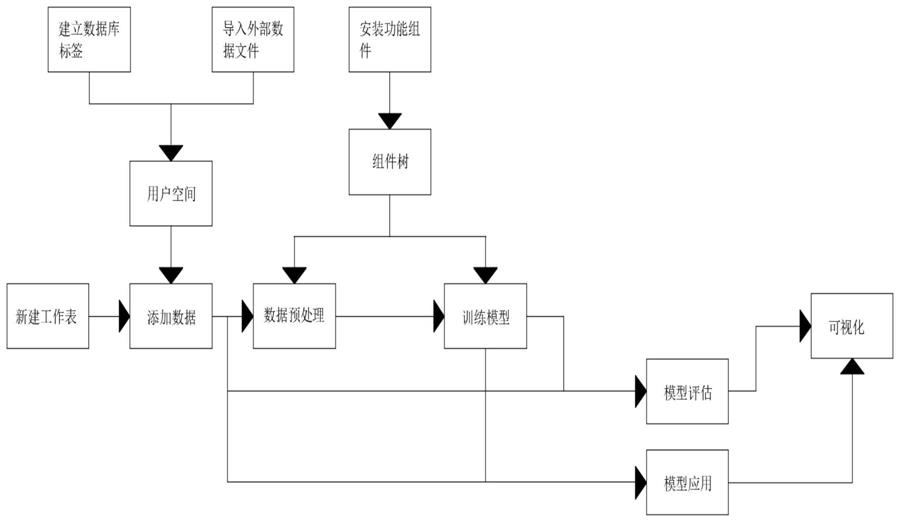
5.本发明提供如下技术方案:一种基于工作流的大数据分析方法,所述通过建立数据库标签和导入外部数据文件到用户空间,以便用户使用数据进行分析,建立数据库标签,连接数据库,获取数据库的数据,可以获取的数据库包括hive、mysql、mssql、transwarpinceptor、postgres、oracle、neo4j和elasticsearch等,构建工作流、添加数据、数据预处理、安装功能组件、构建训练模型、模型评估和模型应用和数据的可视化,导入外部数据文件,用户可以导入csv、excel、text、xml等形式的数据。
6.一、构建工作流
7.在工作流编辑器面板上,新建工作流,打开工作流构建面板。
8.二、添加数据
9.将用户空间中的数据,拖拽到工作流编辑器,用来构建工作流。
10.三、数据预处理
11.在数据挖掘整体过程中,海量的原始数据中存在这大量复杂的,重复的,不完整的数据,严重影响到数据挖掘算法的执行效率,甚至可能导致挖掘结果的偏差。
12.四、安装功能组件
13.构成组件树,为用户进行工作流构建提供功能节点。
14.五、将组件树中的组件拖拽到工作流编辑器面板进行数据预处理
15.在数据预处理过程中,功能组件的使用没有先后顺序,可能某种预处理先后要多
次进行。
16.六、构建训练模型
17.用添加的数据,通过一些方法(最优化或者其他方法)确定函数的参数,参数确定后的函数就是训练结果,使用模型把新的数据代入函数中求值。
18.七、模型评估和模型应用
19.使用评估方法评价模型优劣,并进行模型选择,从而得到一个更好的模型。
20.八、可视化
21.将分析的结果进行可视化展示,完成从数据空间到可视空间的映射,将相对晦涩的数据通过可视的、交互的方式进行展示,从而形象、直观地表达数据蕴含的信息和规律。
22.优选的,在数据挖掘算法执行之前,必须对收集到的原始数据进行预处理,从大量的,不完全的,有噪声的,模糊的、随机的数据中,去除源数据集中的噪声数据和无关数据,处理遗漏数据和清洗脏数据,空缺值,识别删除孤立点,提取隐含在其中、事先不知道的,但有潜在的有用信息和知识,来改进数据的质量,提高数据挖掘过程的效率、精度和性能。
23.优选的,数据预处理的方法有很多,包括基本粗集理论的简约方法,复共线性数据预处理方法,基于hash函数取样的数据预处理方法,基于遗传算法数据预处理方法;基于神经网络的数据预处理方法,web挖掘的数据预处理方法等等。
24.优选的,这里的可视化展示主要是通过自助分析和自助报告进行展示,用户使用自助报告完成报表;使用工作流和发布编辑器进行自助分析完成分析挖掘成果。
25.本发明具备以下有益效果:
26.1、该基于工作流的大数据分析方法,通过本发明所有的数据处理积木(数据源、操作以及结果)都是使用功能图标来表示,同时使用定向箭头将组件连接在一起来表示组件所代表的数据之间的处理流程,即完整的保存分析思路,也可以随时对工作流进行局部修改,极大的提高了用户的工作效率。
27.2、该基于工作流的大数据分析方法,通过本发明把基于因果关系的数据探索转变为流水线的方法,支持程序、自动化执行重复性的任务、数据捕获记录以及不同细节层次上的复杂数据分析过程的重用之间的转移,本发明针对高效率损耗的问题,把静态的多视图显示扩展到气泡的隐喻界面中,这样可自由地布局来支持数据分析任务,每一个气泡是一个功能单元,可以用于编程计算,也可以用来创建一个可视化实例,支持多个气泡组成一个组的操作,同一组中的气泡操作统一化,增强了用户体验,本发明可有效地连接数据分析管线的不同阶段,以减少创建可视化实例以及程序转移的效率损耗,提高动态数据可视效率。
附图说明
28.图1为本发明方法流程示意图。
具体实施方式
29.下面将结合本发明实施例中的附图,对本发明实施例中的技术方案进行清楚、完整地描述,显然,所描述的实施例仅仅是本发明一部分实施例,而不是全部的实施例。基于本发明中的实施例,本领域普通技术人员在没有做出创造性劳动前提下所获得的所有其他实施例,都属于本发明保护的范围。
30.请参阅图1,一种基于工作流的大数据分析方法,通过建立数据库标签和导入外部数据文件到用户空间,以便用户使用数据进行分析,建立数据库标签,连接数据库,获取数据库的数据,可以获取的数据库包括hive、mysql、mssql、transwarpinceptor、postgres、oracle、neo4j和elasticsearch等,构建工作流、添加数据、数据预处理、安装功能组件、构建训练模型、模型评估和模型应用和数据的可视化,导入外部数据文件,用户可以导入csv、excel、text、xml等形式的数据,其步骤如下:
31.一、构建工作流
32.在工作流编辑器面板上,新建工作流,打开工作流构建面板。
33.二、添加数据
34.将用户空间中的数据,拖拽到工作流编辑器,用来构建工作流。
35.三、数据预处理
36.在数据挖掘整体过程中,海量的原始数据中存在这大量复杂的,重复的,不完整的数据,严重影响到数据挖掘算法的执行效率,甚至可能导致挖掘结果的偏差。
37.四、安装功能组件
38.构成组件树,为用户进行工作流构建提供功能节点。
39.五、将组件树中的组件拖拽到工作流编辑器面板进行数据预处理
40.在数据预处理过程中,功能组件的使用没有先后顺序,可能某种预处理先后要多次进行。
41.六、构建训练模型
42.用添加的数据,通过一些方法(最优化或者其他方法)确定函数的参数,参数确定后的函数就是训练结果,使用模型把新的数据代入函数中求值。
43.七、模型评估和模型应用
44.使用评估方法评价模型优劣,并进行模型选择,从而得到一个更好的模型。
45.八、可视化
46.将分析的结果进行可视化展示,完成从数据空间到可视空间的映射,将相对晦涩的数据通过可视的、交互的方式进行展示,从而形象、直观地表达数据蕴含的信息和规律。
47.其中,数据挖掘算法执行之前,必须对收集到的原始数据进行预处理,从大量的,不完全的,有噪声的,模糊的、随机的数据中,去除源数据集中的噪声数据和无关数据,处理遗漏数据和清洗脏数据,空缺值,识别删除孤立点,提取隐含在其中、事先不知道的,但有潜在的有用信息和知识,来改进数据的质量,提高数据挖掘过程的效率、精度和性能。
48.其中,数据预处理的方法有很多,包括基本粗集理论的简约方法,复共线性数据预处理方法,基于hash函数取样的数据预处理方法,基于遗传算法数据预处理方法;基于神经网络的数据预处理方法,web挖掘的数据预处理方法等等。
49.其中,这里的可视化展示主要是通过自助分析和自助报告进行展示,用户使用自助报告完成报表;使用工作流和发布编辑器进行自助分析完成分析挖掘成果。
50.其中,本发明所有的数据处理积木(数据源、操作以及结果)都是使用功能图标来表示,同时使用定向箭头将组件连接在一起来表示组件所代表的数据之间的处理流程,即完整的保存分析思路。
51.需要说明的是,在本文中,诸如第一和第二等之类的关系术语仅仅用来将一个实
体或者操作与另一个实体或操作区分开来,而不一定要求或者暗示这些实体或操作之间存在任何这种实际的关系或者顺序。而且,术语“包括”、“包含”或者其任何其他变体意在涵盖非排他性的包含,从而使得包括一系列要素的过程、方法、物品或者设备不仅包括那些要素,而且还包括没有明确列出的其他要素,或者是还包括为这种过程、方法、物品或者设备所固有的要素。
52.尽管已经示出和描述了本发明的实施例,对于本领域的普通技术人员而言,可以理解在不脱离本发明的原理和精神的情况下可以对这些实施例进行多种变化、修改、替换和变型,本发明的范围由所附权利要求及其等同物限定。
相关技术
网友询问留言
已有0条留言
- 还没有人留言评论。精彩留言会获得点赞!
1