一种天然气井修井暂堵剂用量神经网络预测方法与流程
[0001]
本发明涉及天然气修井领域,具体涉及一种天然气井修井暂堵剂用量神经网络预测方法。
背景技术:
[0002]
天然气井中后期老井修井过程中应对高压差漏失井,需使用一定用量的暂堵剂完成暂时封堵。暂堵剂用量较低时,无法形成有效封堵;暂堵剂用量过多,导致暂堵剂残留井筒,影响井筒内管柱活动形成活塞抽汲效应,影响作业安全。
[0003]
汪道兵等(cn 108316915 a)针对暂堵转向剂提出了一种优化方法,其要求能计算井壁上切向应力及根据理想达西公式计算出对应的暂堵材料参数。牟春国等(cn 109267985 a)针对暂堵剂用量只能根据经验计算,提出了一种压裂暂堵剂计算方法。其要求暂堵剂用量根据裂缝封堵的暂堵剂、裂缝滤失的暂堵剂和近井筒滤失的暂堵剂计算。
[0004]
暂堵压裂过程,井筒完整,可对相关储层物性参数进行测井录井。但老井修井过程,管柱完整性差,并通常存在带压情况,无法获取当前井内参数,评价描述通常为存在断脱、存在窜漏等文字性描述。且老井长时间开采导致地层相关参数发生变化,井内管柱情况复杂,无法获取当前井内参数,难以用确定的公式预测暂堵剂用量。
技术实现要素:
[0005]
本发明的目的是提供一种天然气井修井暂堵剂用量神经网络预测方法,以克服现有技术中无法获取当前井内参数,只能通过文字描述井内工况的情况,并基于初始地质数据及生产情况提出修井过程暂堵剂用量。
[0006]
本发明的目的是通以下技术手段实现的,一种天然气井修井暂堵剂用量神经网络预测方法,包括以下步骤:
[0007]
第一步,数据收集,收集已作业井井场的地质数据、生产资料和现场文字判断,以及天然气修井暂堵剂用量;
[0008]
第二步,数据预处理,对第一步中收集到的数据进行预处理;
[0009]
第三步,模型建立,以标准化处理后的数据为输入层,以天然气修井暂堵剂用量为输出层,以第一步中得到的已作业井天然气修井暂堵剂用量为标准值,监督训练得到天然气井修井暂堵剂用量神经网络模型;
[0010]
第四步,暂堵剂用量预测,获得未作业井的地质数据、生产资料和现场文字判断,作为输入值带入到天然气井修井暂堵剂用量神经网络模型中,得到未作业井的天然气井修井暂堵剂用量。
[0011]
所述第二步中,标准化处理的具体方式为归一化,归一化公式为x=(x-x
min
)/(x
max-x
min
)
[0012]
式中,x为数据归一化后在0-1空间的映射值;
[0013]
x为原始数据值;
[0014]
x
max
为原始数据最大值;
[0015]
x
min
为原始数据最小值。
[0016]
所述天然气井修井暂堵剂用量神经网络模型建立的具体方法为建立bp神经网络,设置输入层、隐含层和输出层,初始化隐含层和输出层神经元之间的连接权值w、隐含层阈值a和输出层阈值b。
[0017]
所述神经网络隐含层为4-10层。
[0018]
所述第三步中,设定神经网络模型的最大迭代次数1000,学习率0.1,训练目标最小误差设置为0.0004。
[0019]
所述隐含层和输出层神经元之间的连接权值w、隐含层阈值a和输出层阈值b初始值均为系统给定随机数。
[0020]
本发明的有益效果在于:基于神经网络模型无具体的模型限制,减少常规公式中的理想条件而增加模型的可应用性;对不能实时获取的当前井内情况,通过已有资料进行模拟训练,对文本材料直接纳入模型训练,提高信息的涵盖程度。
附图说明
[0021]
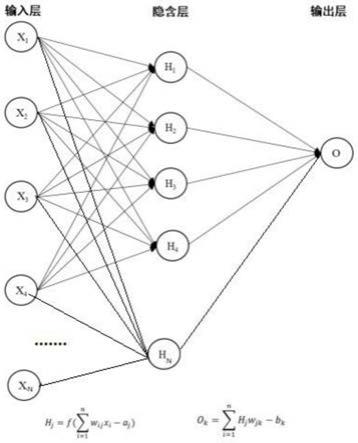
图1为本发明神经网络结构示意图;
[0022]
以下将结合附图及实施例对本发明做进一步详细说明。
具体实施方式
[0023]
【实施例1】
[0024]
如图1所示,一种天然气井修井暂堵剂用量神经网络预测方法,包括以下步骤:
[0025]
第一步,数据收集,收集已作业井井场的地质数据、生产资料和现场文字判断,以及天然气修井暂堵剂用量;
[0026]
第二步,数据预处理,对第一步中收集到的数据进行预处理;
[0027]
第三步,模型建立,以标准化处理后的数据为输入层,以天然气修井暂堵剂用量为输出层,以第一步中得到的已作业井天然气修井暂堵剂用量为标准值,监督训练得到天然气井修井暂堵剂用量神经网络模型;
[0028]
第四步,暂堵剂用量预测,获得未作业井的地质数据、生产资料和现场文字判断,作为输入值带入到天然气井修井暂堵剂用量神经网络模型中,得到未作业井的天然气井修井暂堵剂用量。
[0029]
其中,第一步中,已作业井井场的地质数据、生产资料和现场文字判断具体见表1,
[0030]
表1自变量因素类型表
[0031]
[0032][0033]
并且收集数据时,可以只收集其中的部分数据来进行神经网络模型训练,例如有些井可能不产水,就没有当前产水量和累计产水量。或者部分井数据缺失,则将能收集到的所有数据作为输入层进行训练。
[0034]
因此在实际收集中,按照表1内容,根据各井实际情况收集部分或所有数据,且收集的数据越多越好,只有部分数据也可以带入神经网络模型中训练。
[0035]
模型训练过程中,将收集到的数据先进行归一化,然后以表1内的数据作为训练数据和验证数据的自变量,已作业井的天然气修井暂堵剂用量作为因变量,经过训练得到关于天然气井修井暂堵剂用量的神经网络模型,最终将未作业井的因变量输入模型中,得到
未作业井的天然气井修井暂堵剂用量预测值,即是该未作业井的天然气井修井暂堵剂用量。
[0036]
所述第二步中,标准化处理的具体方式为归一化,归一化公式为x=(x-x
min
)/(x
max-x
min
)
[0037]
式中,x为数据归一化后在0-1空间的映射值;
[0038]
x为原始数据值;
[0039]
x
max
为原始数据最大值;
[0040]
x
min
为原始数据最小值。
[0041]
为消除数据量纲、量级影响,在作为训练数据和验证数据前进行对所有数据进行归一化处理。
[0042]
在第四步中,还对输出的预测结果进行反归一化。将反归一化后的输出结果作为最终的天然气修井暂堵剂用量预测值。
[0043]
所述天然气井修井暂堵剂用量神经网络模型建立的具体方法为建立bp神经网络,设置输入层、隐含层和输出层,初始化隐含层和输出层神经元之间的连接权值w、隐含层阈值a和输出层阈值b。
[0044]
所述神经网络隐含层为4-10层。
[0045]
所述第三步中,设定神经网络模型的最大迭代次数1000,学习率0.1,训练目标最小误差设置为0.0004。
[0046]
所述隐含层和输出层神经元之间的连接权值w、隐含层阈值a和输出层阈值b初始值均为系统给定随机数。
[0047]
根据归一化处理后的数据,开始进行生产数据和天然气井修井暂堵剂用量神经网络模型建立。网络训练信号由输入层至输出层前向传递、误差沿网络逆向传播。将处理后的输入数据x1、x2、x3、x4……
x
n
作为自变量,即输入变量。由于变量间存在相关关系,根据输入数据的个数,设定隐含层为4-10层。如图1初始化输入层、隐含层和输出层神经元之间的连接权值w初始化隐含层阈值a,输出层阈值b,其中连接权值w初始化隐含层阈值a,输出层阈值b的初始值均由系统给定随机数,在神经网络模型自优化的过程中不断优化到趋近真实值。
[0048]
给定学习速率和神经元激励函数,即隐含层和输出层之间存在的函数关系。根据输入向量x,输入层和隐含层间连接权值w
ij
,以及隐含层阈值a
j
,计算隐含层输出h
j
。其公式如下:
[0049][0050]
根据隐含层输出h
j
,连接权值w
jk
和阈值b
k
计算得到神经网络预测输出值o
k
[0051][0052]
模型建立后,选取部分数据训练数据,另外一部分验证数据;最大迭代次数1000,学习率0.1,训练目标最小误差设置为0.0004,得到训练模型。
[0053]
对将现场将作业g29x井,收集初始地质数据及生产情况,现场文字描述为存在
1300米下油管断脱,清水灌注不返液,将上述数据带入上神经网络训练模型,对暂堵剂用量进行预测。
[0054]
预测输出结果该井暂堵剂预测用量为71.2m3h。现场使用70m3暂堵剂进行作业,完成封堵现场无剩余暂堵剂,后期起捞管柱顺利,完成修井过程。
相关技术
网友询问留言
已有0条留言
- 还没有人留言评论。精彩留言会获得点赞!
1