一种基于注意力机制的轻量级网络实时语义分割方法与流程
:
[0001]
本发明属于图像语义分割技术领域,涉及一种基于注意力机制的轻量级网络实时语义分割方法。
背景技术:
:
[0002]
近年来,随着计算机技术和传感器技术的飞速发展,机器人研究取得了巨大的进步,越来越多的服务机器人被广泛地应用于社会生产生活中。机器人服务人类时,首先需要建立对周围环境的认知和理解,然后完成一系列其他任务,如机器人定位、导航、路径规划等,因此对环境的认知和理解能力直接影响着机器人性能的优劣。语义分割是场景理解的基石性技术,它将图像中的每个像素按照语义含义的不同进行分组,也就是对图像中的每个像素进行分类。图像经过语义分割后,通过将低层图像特征映射为高层语义特征,可以帮助机器人更好地理解图像中的高层信息,为后续的分析决策提供参考依据。目前,利用语义分割技术构建语义地图,能够帮助机器人更好地理解周围场景,已经成为机器人地图构建的主要趋势。然而语义分割需要大量的计算,机器人不能实时进行环境感知。针对上述问题,有学者提出利用轻量化模型,以减少网络的参数量,提高实时性,但轻量化模型为了减少网络层数,简化了解码器中的操作,忽视了解码器恢复信息的能力,导致准确性大大降低。因此,面向机器人环境感知的实时语义分割是一个具有挑战性的问题。
[0003]
当前,基于深度神经网络的语义分割的研究主要集中在两个方向:(1)通过增加网络深度来提高分割精度;(2)通过降低网络层数,构建轻量级模型,提高分割效率。在提高网络分割精度方面,2017年zhao,h.,shi,j.,qi,x.,wang,x.,jia,j.:pyramid scene parsing network.in:2017 ieee conference on computer vision and pattern recognition(cvpr)(2017)提出利用金字塔池化模块来聚合不同区域的上下文信息,进而提高获取全局信息的能力;2017年lin,g.,milan,a.,shen,c.,reid,i.d.:refinenet:multi-path refinement networks for high-resolution semantic segmentation in:2017 ieee conference on computer vision and pattern recognition(cvpr)(2017)引入长距离残差连接融合不同尺度特征,通过递归方法提取低分辨率特征信息来生成高分辨率特征。上述语义分割算法在分割精度方面有了很大的提高,但网络结构过于复杂,无法满足实际应用的实时性要求。在提升网络效率方面,2016年paszke a,chaurasia a,kim s,et al.enet:a deep neural network architecture for real-time semantic segmentation[j].2016.(2016)设计了具有瓶颈模块的非对称编解码器结构,在网络前端不断向下采样以降低特征图的分辨率,并将瓶颈模块与非对称卷积结合以进一步提高分割效率,2018年zhao,h.,qi,x.,shen,x.,shi,j.,jia,j.:icnet for real-time semantic segmentation on high-resolution images:15th european conference,munich,germany,september 8
–
14,2018,proceedings,part iii edn,pp.418
–
434(2018)设计了一种将特征融合单元与标签引导相结合的图像级联网络,可以在较低计算量下逐步细化分割预测。虽然这些工作在降低计算成本和模型参数方面取得了很大进展,但由于没有有效联
合编解码的信息,导致分割精度降低,难以满足实际应用中的可靠性要求。
技术实现要素:
:
[0004]
本发明的目的在于提供了一种基于注意力机制的轻量级网络实时语义分割方法,更好地解决现有技术中的图像语义分割难以达到分割精度与分割效率平衡的问题,以满足机器人对现实环境实时分割的需求。
[0005]
为了达到上述目的,本发明的技术方案是提供一种基于注意力机制的轻量级网络实时语义分割方法,通过在编码器中利用轻量化模块-可分离非对称模块(sam),降低模型参数,在解码器中利用注意力机制联合编码器信息,恢复图像丢失的细节信息,提高分割精度,包括以下步骤:
[0006]
步骤1:准备图像数据集用于训练和测试;
[0007]
步骤2:构建基于注意力机制的轻量级实时语义分割网络;
[0008]
步骤3:将训练集图像输入到轻量级实时语义分割网络中,得到预测图像,将其与数据集中的语义标签图像进行对比,计算出交叉熵函数作为损失函数,利用随机梯度下降法作为参数优化算法更新模型参数,获得训练好的轻量级实时语义分割模型;
[0009]
步骤4:将测试集图像输入到训练好的轻量级实时语义分割模型中,得到图像语义分割结果。
[0010]
步骤2中,所述的基于注意力机制的轻量级实时语义分割网络采用非对称编码-解码结构。不同于以往语义分割方法所用的非对称结构,本发明没有在解码器中直接使用简单的双线性插值进行上采样,而是利用注意力机制联合编解码信息,恢复编码器中丢失的信息。因为,利用插值法扩大图像尺寸会增加无用信息,并且会造成图像位置信息损失,影响分割精度。注意力机制可以有选择性地关注重要信息,其核心思想是对编码器的所有输出进行加权组合后,将原始数据的上下文信息,输入到当前位置的解码器中来影响解码器的输出。具体来说,编码器中除了使用3个3
×
3的标准卷积外,还包含9个可分离非对称模块(sam)和2个平行下采样模块(pdm),其中可分离非对称模块包含两个分支,左分支包含一个3
×
1和一个1
×
3的非对称深度卷积来提取图像特征,右分支包含一个3
×
1和一个1
×
3的深度空洞卷积,可以有效增加特征图感受野,两个分支经过相加(add)之后再经过一个1
×
1卷积来恢复通道数,最后将相加后的结果与输入相加(add)组成残差连接。平行下采样模块由一个2
×
2的最大池化和一个3
×
3卷积concat后形成,其中3
×
3卷积可以增加感受野,最大池化操作可以提高分割效率。解码器包括顺次连接的1个1
×
1卷积、1个2倍双线性上采样单元、1个注意力特征融合模块(affm)、1个1
×
1卷积、1个4倍双线性上采样单元。注意力特征融合模块的具体操作为:首先将低级特征与高级特征通道连接,然后利用全局池化将连接后的特征转化为特征向量,并计算权重向量。权值向量v被定义为:
[0011]
v=σ[w2δ[w1(gf
n
)]]
[0012]
其中f
n
为连接后的特征图,g是全局池化操作,w1和w2为全连接操作,σ为sigmoid激活函数,δ为relu激活函数;
[0013]
最后将权值向量v与原始特征相乘得到更新后的特征图,逐点求和后与原始特征图相加。最终输出的特征图f根据下式得到:
[0014]
f=v
·
f
n
+f
n
[0015]
所述步骤3中的网络训练过程包括:
[0016]
步骤3.1:将训练集中的图像进行预处理和数据增强,具体来说,对训练集中的图像进行水平翻转、随机裁剪、随机缩放尺度来扩充数据集,其中随机缩放尺度范围为0.5到2倍之间。
[0017]
步骤3.2:初始化参数,将一次训练样本数量设为8,权重衰减值设为0.0001,初始学习率设为0.045,动量系数设为0.9。
[0018]
步骤3.3:将训练集中经过预处理和数据增强处理后的的图像输入到设计的轻量级实时语义分割模型中,得到预测结果,然后,计算预测结果与训练集中图像标签值的交叉熵损失函数值:
[0019][0020]
其中为模型预测值,y为预测特征图对应的语义标签值;
[0021]
步骤3.4:使用随机梯度下降法和多项式学习策略优化损失函数,其中多项式学习策略中的学习率lr被设置为:
[0022][0023]
其中baselr为初始学习率,iter为当前迭代次数,total_iter为总迭代次数,power为多项式的幂。
[0024]
本发明的有益效果为:
[0025]
(1)本发明在编码器中使用了一个可分离非对称模块和平行下采样模块,能够在显著减少模型参数量的情况下,有效提取图像特征信息。
[0026]
(2)本发明在解码器中设计了一个注意力特征融合模块,将编码器中的特征与解码器中的特征进行融合,将其融合后的特征经过注意力机制的选择和组合,增强对恢复图像信息有用的特征,有效提高了网络分割的精度。
附图说明
[0027]
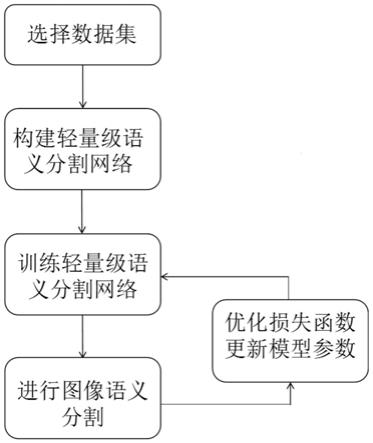
图1为本发明的实现流程图;
[0028]
图2为本发明提出的基于注意力机制的轻量级实时语义分割网络结构图;
[0029]
图3为本发明的平行下采样模块pdm结构图;
[0030]
图4为本发明的可分离非对称模块sam结构图;
[0031]
图5为本发明的注意力特征融合模块affm结构图;
[0032]
图6为本发明在cityscapes数据集上的分割结果图,(a1-a2)表示输入图像,(b1-b2)表示对应的标注图像,(c1-c2)表示本发明的预测结果图。
具体实施方式
[0033]
下面结合具体实施例与附图对本发明进行详细描述。
[0034]
如图1所示,一种基于注意力机制的轻量级网络实时语义分割方法包括以下步骤:
[0035]
步骤1:准备图像数据集用于训练和测试;
[0036]
本实施例中以cityscapes数据集中的类别为基准,该数据集包含来自50个不同城市的街道场景的5000幅精细标注图像,其中训练集有2975幅图像,验证集有500幅图像,测
试集有1525幅图像,以及带有粗标注的19998幅图像。本实施例仅使用经过精细标注的图像进行训练,图像分辨率为1024
×
2048。数据集中的所有像素可以被标记为30个类别,其中选择19个类别进行训练和测试。
[0037]
步骤2:构建基于注意力机制的轻量级实时语义分割网络;
[0038]
如图2所示,所述基于注意力机制的轻量级实时语义分割网络采用非对称编码-解码结构,将网络分为4个阶段,其中前三个阶段为编码器,第四个阶段为解码器。阶段1负责提取低级特征,阶段2和阶段3负责提取更大范围的上下文信息,阶段4负责恢复图像信息和尺寸。具体来说,先将图像输入到阶段1中,网络前三层使用标准3
×
3卷积进行特征提取,随后经过平行下采样模块pdm将特征图尺寸缩小为原来的1/4,平行下采样模块pdm结构如图3所示,它由一个2
×
2的最大池化和一个3
×
3卷积concat后形成,其中3
×
3卷积可以增加感受野,最大池化操作可以提高分割效率。将阶段1得到的特征图输入到阶段2中,经过3个带有空洞率为2的可分离非对称模块sam,提取到特征的上下文信息,然后将阶段1的输出和第三个sam的输出进行连接操作c,接下来,利用平行下采样模块pdm降低特征图尺寸,减少参数量。可分离非对称模块sam结构如图4所示,首先将输入进行3
×
3卷积,然后将得到的特征图分为两部分,左分支包含一个3
×
1和一个1
×
3的非对称深度卷积来提取图像特征,右分支包含一个3
×
1和一个1
×
3的深度空洞卷积,可以有效增加特征图感受野,两个分支经过相加(add)之后再经过一个1
×
1卷积来恢复通道数,最后将相加后的结果与输入相加(add)组成残差连接。阶段3包含6个可分离非对称模块sam,空洞率分别为4,4,8,8,16,16,可以有效提取特征图不同尺度的上下文信息。最后将阶段2的输出和第6个sam的输出进行连接操作c,得到编码后的特征图。图像经过编码后特征图尺寸变为原来的1/8,因此需要经过解码器恢复到原始图像尺寸。在阶段4中,将第三阶段得到的编码后的特征图首先经过1
×
1卷积减少通道数,然后经过2倍上采样得到图像的高级特征,接下来与第一阶段得到的低级特征进行连接操作c得到原始特征f
n
,利用注意力特征融合模块affm完成对原始特征f
n
的重新选择和组合,最后利用1
×
1卷积和4倍上采样,恢复到图像原始尺寸。
[0039]
其中,注意力特征融合模块affm的工作过程具体为:利用全局池化将原始特征f
n
转化为特征向量,并依次经过1
×
1卷积、relu激活函数、1
×
1卷积、sigmoid激活函数,得到权重向量v,接下来,将权值向量v与原始特征f
n
相乘得到更新后的特征图,最后,更新后的特征图与原始特征图f
n
逐点相加,完成对特征的重新选择和组合,其中,权值向量v的计算公式如下:
[0040]
v=σ[w2δ[w1(gf
n
)]]
[0041]
其中f
n
为连接后的特征图,g是全局池化操作,w1和w2为全连接操作,σ为sigmoid激活函数,δ为relu激活函数;
[0042]
基于注意力机制的轻量级实时语义分割网络具体结构如表1所示:
[0043]
表1网络的详细结构
[0044][0045]
步骤3:将cityscapes训练集图像输入到轻量级实时语义分割网络中,得到预测图像,将其与数据集中的语义标签图像进行对比,计算出交叉熵函数作为损失函数,利用随机梯度下降法作为参数优化算法更新模型参数,获得训练好的轻量级实时语义分割模型;
[0046]
具体的网络训练过程包括:
[0047]
步骤3.1:首先将cityscapes训练集中的图像进行归一化处理,然后将其随机裁剪为512
×
1024尺寸大小,再对训练集中的图像进行数据增强处理,具体增强方式包括:水平翻转、随机裁剪、随机缩放尺度;
[0048]
步骤3.2:初始化参数,将一次训练样本数量设为8,权重衰减值设为0.0001,初始学习率设为0.045,动量系数设为0.9;
[0049]
步骤3.3:将数据集中预处理后的图像输入到设计的轻量级实时语义分割模型中,得到预测结果,然后,计算预测结果与训练集中图像标签值的交叉熵损失函数值:
[0050][0051]
其中为模型预测值,y为预测特征图对应的语义标签值;
[0052]
步骤3.4:使用随机梯度下降法和多项式学习策略优化损失函数,完成对轻量级实时语义分割网络的训练,其中多项式学习策略中的学习率lr被设置为:
[0053][0054]
其中baselr为初始学习率,iter为当前迭代次数,total_iter为总迭代次数,power为多项式的幂;
[0055]
步骤4:将cityscapes测试集图像输入到训练好的轻量级语义分割模型中,得到图像语义分割结果;
[0056]
本发明在cityscapes数据集上的分割结果图如图6所示,其中(a1-a2)表示输入图像,(b1-b2)表示对应的标注图像,(c1-c2)表示本发明的预测结果图。
[0057]
表2展示了本发明在cityscapes数据集上与其他最先进方法在分割精度(miou)与分割速度(fps)上的比较,本发明的模型参数为0.9m,与lednet非常接近,但精度比lednet有1.9%的改进。此外,enet是目前最小的语义分割模型,比本发明少了3倍的参数,但是精度远低于本发明取得的72.5%miou。为了公平地比较速度,所有的速度比较实验都在一个
980ti gpu上进行。对于512
×
1024的输入,本发明能够取得46.7fps的速度,满足了实时性要求。综上可知,本发明取得了分割精度与分割效率的平衡,满足了实际应用的需求。
[0058]
表2本发明在测试集上与其他最先进方法对比
[0059]
相关技术
网友询问留言
已有0条留言
- 还没有人留言评论。精彩留言会获得点赞!
1