感知方法、感知装置、感知系统及相关设备与流程
1.本技术涉及智能车领域,尤其涉及一种感知方法、感知装置、感知系统及相关设备。
背景技术:
2.随着智能车(intelligent car)领域的快速发展,包括深度学习等计算机技术逐渐被应用于自动驾驶(automated driving)技术中,而如何精准感知智能车周围的对象是自动驾驶研究的热点。传统的目标物感知方法主要依赖于摄像头或雷达识别目标物,但是,由于摄像头和雷达均存在局限性,例如,摄像头感知结果受光照等外部环境因素影响较多,雷达感知仅在测量目标物距离上有较为成熟的算法,均无法精准感知智能车周围的路况,影响自动驾驶的体验和安全性。因此,如何提供一种更精准的对象感知方法成为亟待解决的技术问题。
技术实现要素:
3.本技术提供了一种感知方法、装置、系统和相关设备,以此为智能车提供更精准的对象感知结果,提升智能车驾驶的安全性。
4.第一方面,提供一种感知方法,该方法包括:先获取由第一采集设备采集的第一数据和由第二采集设备采集的第二数据;再根据第一数据和第二数据确定待识别对象的感知结果。上述方法可以由控制器执行,通过上述方法,可以结合多种设备采集的数据确定感知结果,得到高精度的感知结果。
5.在一种可能的实现方式中,根据第一数据和第二数据确定待识别对象的感知结果可以具体包括:先根据第一数据确定待识别对象的第一信息,其中,第一信息包括待识别对象的类别和尺寸;再根据第一信息和第二数据获得第二信息,其中,第二信息包括待识别对象的定位结果,定位结果用于标识待识别对象与第二采集设备所在智能车的相对位置。控制器可以利用从第一数据中获得的类别和尺寸,结合第二数据,共同获得高精度的定位结果。
6.在另一种可能的实现方式中,根据第一数据确定待识别对象的第一信息可以具体包括:先根据第一数据确定待识别对象的类别;再根据待识别对象的类别,在第一数据表中确定待识别对象的尺寸的第一值,其中,第一数据表用于记录不同类别的对象的尺寸的映射关系;最后修正待识别对象的尺寸的第一值,获得待识别对象的尺寸的第二值,其中,第二值与待识别对象的尺寸的真实值的误差小于第一值与待识别对象的尺寸的真实值的误差。控制器利用第一数据中的类别信息和第一数据表中的统计结果估计待识别对象的尺寸第一值,弥补了第一数据提供对象三维尺寸信息能力的不足。控制器还进一步对尺寸值进行了修正,获得了离真实尺寸更为接近的尺寸值。
7.在另一种可能的实现方式中,根据第一数据确定待识别对象的第一信息还可以具体包括:先根据第一数据确定待识别对象的类别和待识别对象被识别为该类别的概率;再
根据待识别对象的类别和概率,在第一数据表中确定待识别对象的尺寸的第一值,其中,第一数据表用于记录不同类别的对象的尺寸的映射关系;最后修正待识别对象的尺寸的第一值,获得待识别对象的尺寸的第二值,其中,第二值与待识别对象的尺寸的真实值的误差小于第一值与待识别对象的尺寸的真实值的误差。控制器可以计算出待识别对象被识别为不同概率下的类别时的尺寸信息,适用于获取对象类别的算法结果中具有不确定性的场景。
8.在另一种可能的实现方式中,在根据第一信息和第二数据获得第二信息之前,可以对第一数据和第二数据进行校准,包括:校准第一数据和第二数据,以获得在同一坐标系中标识第一数据和第二数据的结果。可以建立第一数据中的元素和第二数据中的元素的关系,以方便后续结合第一信息和第二数据一起获取第二信息。
9.在另一种可能的实现方式中,根据第一信息和第二数据获得第二信息可以具体包括:先将第一信息作为聚类算法的初始参数;再对第二数据执行聚类,获得聚类结果,其中,聚类结果用于标识第二数据中属于同一个待识别目标的数据;最后根据聚类结果确定待识别对象的第一定位结果并修正第一定位结果,获得待识别对象的第二定位结果,其中,第二定位结果与待识别对象的真实定位结果的误差小于第一定位结果与待识别对象的真实定位结果的误差。可以使用第一信息提高聚类算法的效率和聚类效果,以获得更高精度的定位结果。
10.在另一种可能的实现方式中,第一数据包括图像数据,第二数据包括点云数据。本技术提供的感知方法可以同时结合图像数据具有丰富的对象语义信息和点云数据具有精确的对象定位信息的优势,获得高精度的感知结果。
11.第二方面,本技术提供一种感知装置,所述感知装置包括用于执行第一方面或第一方面任一种可能实现方式中的感知方法的各个模块。
12.第三方面,本技术提供一种感知系统,包括第一设备,第二设备和控制器。第一设备用于生成第一数据,第二设备用于第二数据,控制器用于实现如上述第一方面及第一方面任意一种可能实现方式中相应主体所执行的方法的操作步骤。通过上述感知系统,使用多种设备采集不同的数据,以便控制器可以结合多种数据,得到高精度的感知结果。
13.第四方面,本技术提供一种计算机设备,所述计算机设备包括处理器和内存,所述内存中用于存储计算机执行指令,所述计算机设备运行时,所述处理器执行所述内存中的计算机执行指令以利用所述计算机设备中的硬件资源执行第一方面或第一方面任一种可能实现方式中所述方法的操作步骤。
14.第五方面,本技术提供一种计算机可读存储介质,所述计算机可读存储介质中存储有指令,当其在计算机上运行时,使得计算机执行上述第一方面或第一方面任一种可能实现方式中所述方法的操作步骤。
15.第六方面,本技术提供了一种包含指令的计算机程序产品,当其在计算机上运行时,使得计算机执行第一方面或第一方面任一种可能实现方式中所述方法的操作步骤。
16.本技术在上述各方面提供的实现方式的基础上,还可以进行进一步组合以提供更多实现方式。
附图说明
17.图1为本技术实施例提供的一种感知系统的结构示意图;
18.图2为本技术实施例提供的一种感知方法的流程示意图;
19.图3为本技术实施例提供的另一种感知方法的流程示意图;
20.图4为本技术实施例提供的另一种感知方法的流程示意图;
21.图5为本技术实施例提供的一种感知方法的示例图;
22.图6为本技术实施例提供的一种实现感知方法的装置示意图。
23.图7为本技术实施例提供的一种计算机设备示意图。
具体实施方式
24.下面结合附图对本技术实施例中的技术方案进行描述。
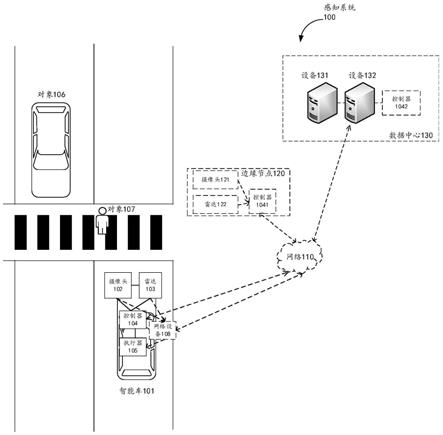
25.图1为本技术实施例提供的一种感知系统100的结构示意图,如图所示,感知系统100包括智能车101和待识别的对象(例如,对象106和对象107),其中,智能车101中包括数据采集设备(例如,摄像头102、雷达103)、控制器104以及执行器105。
26.在感知系统100中,智能车101的控制器104通过摄像头102和雷达103获取智能车周围待识别对象的感知数据(也可以称为数据),并根据得到的感知数据确定每个待识别对象的感知结果,包括类别、尺寸以及定位结果。其中,定位指的是获取待识别对象在与智能车相同坐标系(例如,世界坐标系)中的坐标,并根据该坐标计算出待识别对象与智能车的相对位置。控制器可以将感知结果在智能车内显示屏中呈现给驾驶员,辅助驾驶员安全驾驶车辆;或者控制器将感知结果发送给执行器,由执行器利用感知结果规划车辆的行驶路径和操作指令并执行。待识别的对象不仅包括车辆、行人等动态对象,也包括交通设施、障碍物等静态对象。
27.其中,摄像头102和雷达103因为工作原理的不同,获取到的感知数据的类型也不同。当采用摄像头采集数据时,通过镜头生成目标物体的光学图像,并将该光学图像投射到图像传感器上,进而将光学成像中的光信号转变为电信号,再经过处理将模拟信号转换为数字信号后变为数字图像信号,最后由数字信号处理芯片将信号处理成特定格式的图像数据。常见的摄像头包括单目摄像头、双目立体摄像头、全景摄像头以及红外摄像头。当采用雷达采集数据时,雷达可以向目标物体发射探测信号(例如,激光束),然后,接收到的从目标物体反射的信号(例如,目标回波),将目标物体反射的信号与发射信号进行比较和处理后,生成点云数据。常见的雷达类传感器包括激光雷达(lidar)、毫米波雷达(millimeter-waveradar,mmw radar)以及超声波雷达。进一步地,对于激光雷达,根据激光线束数量的不同又可以分为16线、32线、64线和128线激光雷达,相对来说,16线及以下线束的激光雷达被称为低线雷达。
28.值得说明的是,图1所示的系统中,同一智能车(例如,智能车101)中设置摄像头和雷达,但是,对同一智能车中设置的摄像头或雷达的数量不做限定。此外,同一智能车中摄像头的类型也不构成对本技术的限定,例如,同一智能车中可以设置1个单目摄像头,或者1个单目摄像头和1个双目立体视觉摄像头。同一智能车中雷达的类型也不构成对本技术的限定,例如,同一智能车中可以设置1个激光雷达,或者1个激光雷达和1个毫米波雷达。
29.控制器104,用于根据摄像头102和雷达103采集的感知数据实现目标物体(也可以称为待识别对象)的感知,控制器104可以利用摄像头和雷达获取的数据通过不同处理过程,得到最终的感知结果。例如,当控制器获取摄像头采集的图像数据时,可以利用基于机
器学习的图像处理算法对图像数据进行特征提取和处理,为车辆提供待识别对象的类型和尺寸。当控制器获取雷达采集的点云数据时,可以结合图像数据所确定的类型和尺寸,并利用聚类算法对点云数据进行分类和识别,进而确定待识别对象的定位结果。
30.作为一种可能的实现方式,为了保证感知结果的准确性,控制器在获取摄像头和雷达采集的数据时,还可以校准摄像头和雷达采集的数据,以在同一坐标系中标识待识别对象,建立点云数据中的点和图像数据中的像素之间的对应关系。
31.可选地,为了减少控制器处理的感知数据的数据量,并且避免因为摄像头或雷达的污渍造成的数据缺失,以及避免智能车外环境影响造成的数据噪声,还可以使用控制器104对从摄像头和雷达获取的数据进行预处理,以提高后续感知算法的效率和精度。例如,控制器104,可以在时间轴上对图像数据进行采样,以减少后续感知处理过程中的数据处理量;或者,控制器104,还可以通过差值算法,利用图像数据中已有的数据去估计缺失的数据。
32.可选地,图1所示的感知系统中还可以包括数据中心130。控制器可以通过网络110将本车控制器计算出的感知结果发送至数据中心130,以共享给其他智能车;同时,控制器还可以通过网络110从数据中心130获取其他智能车控制器计算出的感知结果,从而获得更大范围的交通环境状况。
33.图1中网络110可以使用无线传输方式,包括第5代移动通信技术(5th generation mobile networks)、移动热点(wi-fi)、蓝牙和红外,具体实施过程中,可以利用一个或多个交换机和/或路由器实现数据中心和控制器的通信连接。
34.可选地,除了将控制器设置在智能车101中外,控制器104还可以部署于智能车101外部,例如,控制器104还可以部署在边缘节点120或者数据中心130中。
35.作为一种可能的实现方式,当控制器部署于边缘节点120中时,例如,图1中控制器1041,智能车101通过车辆上的网络设备108和网络110将摄像头102和雷达103采集的数据发送至边缘节点120,边缘节点中的控制器1041可以进一步完成待识别对象的感知处理,并将感知结果再通过网络110和网络设备108传回至智能车101。其中,网络设备108可以是智能车101中任一具有数据交换能力的交换设备或芯片。具体实施中,可以按照物理区域设置一个或多个边缘节点,每个边缘节点接收一个区域内一个或多个智能车的数据,连接同一个边缘节点的智能车具有较近的物理距离。边缘节点可以部署于红绿灯设备上或者电子警察监控杆上,由多辆智能车共享,减少了在每一辆智能车中部署控制器所带来的成本。
36.可选地,边缘节点中也可以设置摄像头和/或雷达,例如,图1中摄像头121和/或雷达122,用来代替智能车中的摄像头和/或雷达,减少每一辆智能车部署数据采集设备的成本或者用来作为对智能车中摄像头和雷达视野不足或遮挡的补充,提高驾驶的安全性。
37.作为一种可能的实现方式,当控制器部署于数据中心130中时,例如,图1中控制器1042,智能车101通过车辆上的网络设备108和网络110将摄像头和雷达数据发送至数据中心130,由数据中心中的控制器1042完成感知处理,并将感知结果通过网络110和网络设备108传回至车辆101。具体实施中,数据中心130中可以包括用于实现计算功能的设备(例如,服务器)、存储(例如,存储阵列)功能的设备和网络(例如,交换机)功能的设备。应当理解,数据中心130中设备的数量并不构成对本技术的限定,图1仅以数据中心包括两台设备为例进行说明。另外,对于数据中心中设备的类型、虚拟化管理方式本技术也不作限定。
38.当控制器部署于数据中心中时,能利用虚拟化以及多服务器并行计算的优势,加快对感知数据的处理速度。此时,为了满足智能车获得感知结果的实时性,网络110的传输方式可以使用第5代移动通信技术(5th generation mobile networks)和第6代移动热点(wi-fi)技术。
39.应该理解,上述智能车可以为无人驾驶交通工具,也可以为有人驾驶的交通工具。交通工具包括汽车、轿车、卡车、公交车、船、飞机、直升机。此外,机器人装置或其他移动设备也可用于执行本文描述的方法和系统。
40.值得说明的是,图1所示的系统架构仅仅是为了更好的说明本技术所提供的感知方法所提供的系统架构的示例,并不构成对本技术实施例的限定。
41.基于图1所示的系统,本技术实施例提供一种感知方法,结合摄像头采集的图像数据和雷达采集的点云数据,提供高精度的待识别对象感知结果,并且可以根据控制器的计算能力以及网络对感知数据的传输速度,选择将控制器部署于数据中心、边缘节点或智能车中,满足多种驾驶场景的需要。本技术的详细方案请参考下述实施例的描述。
42.接下来,进一步结合图2详细介绍本技术提供的感知方法。图2为本技术提供的一种感知方法的流程示意图,如图所示,具体方法包括:
43.s201、控制器对摄像头进行标定。
44.确定待识别对象表面某点在以摄像头的中心位置为原点的世界坐标系中的位置与其在摄像头图像数据中对应像素之间的相互关系。标定的方法包括:直接线性变换(direct linear transformation,dlt)以及基于径向排列约束方法(radial alignment constraint,rac)。
45.值得说明的是,上述标定方法也可以选择其他位置作为世界坐标系的原点,例如,摄像头所在智能车的中心位置为世界坐标系的原点。
46.可选地,也可以由摄像头对自身进行标定。
47.s202、获取摄像头采集的图像数据。
48.为了便于描述,也可以将摄像头采集的图像数据称为第一数据。可选地,获取图像数据之后,还可以对摄像头不同时刻采集的图像数据打上相应的时间标签。
49.可选地,控制器获取第一数据之后对第一数据进行预处理,预处理的方法可以采用以下方法中至少一种:
50.方法一:对一段连续时间内的图像数据在时间轴上进行采样,例如每隔0.5秒取一帧数据,以减少后续目标感知算法的数据处理量;
51.方法二:对图像数据在像素点上进行采样,例如原图像大小为1080*1080,在长和宽上均每隔一个像素点采样一次,则采样后图像大小变为540*540。采样后可以减少后续感知算法中模型的参数数量,提高算法速度;
52.方法三:采用差值算法,利用图像数据中已有的数据去估计缺失的数据,避免因为传感器污渍造成的目标感知信息的不准确;
53.方法四:采用滤波算法,减少因为环境因素或者传感器图像生成或传输带来的图像数据噪声;
54.方法五:采用尺度不变特征变换(scale invariant feature transform,sift)算法将多个摄像头同时拍摄的图像数据拼接在一起。由于摄像头感知的范围有限,一些位于
摄像头感知边缘的对象可能被截断,只能部分地显示在图像数据中,而将多个摄像头生成的图像拼接在一起,能完整地呈现这些被截断的对象,提高驾驶的安全性。
55.接下来,由控制器基于第一数据或预处理后的图像数据进一步获得待识别对象的类别和尺寸。为了便于描述,本技术以下实施例以控制器基于第一数据进一步获得待识别对象的语义信息为准进行描述。此外,也可以将基于第一数据获得的待识别对象的类别和尺寸称为第一信息。具体步骤包括:
56.s203、控制器提取图像特征。
57.控制器可以根据摄像头采集的第一数据提取图像特征,将第一数据转换为标识待识别对象的属性的信息。其中,图像特征包括图像的颜色、纹理、形状和空间关系等特征。颜色,用于标识图像或图像区域所对应的景物的颜色分类;纹理,用于标识图像或图像区域所对应景物的表面性质,例如水中倒影;形状,用于标识图像的外边界轮廓以及形状区域;空间关系,用于标识图像中分割出来的多个目标之间的相互的空间位置或相对方向关系,这些关系也可分为连接/邻接关系、交叠/重叠关系和包含/包容关系等。
58.提取图像特征的方法可以采用以下方式中至少一种:尺度不变特征变换(scale-invariant features transform,sift)、方向梯度直方图(histogram of oriented gradient,hog)以及高斯函数差分(difference of gaussian,dog)。
59.可选地,除了上述图像特征的提取方法外,还可以采用深度学习的方法提取图像特征,所用的网络模型包括深度残差网络(deep residual network,drn)、牛津大学视觉几何实验室提出的网络(visual geometry group network,vggnet)和轻量级深层神经网络(mobile network,mobilenet)。
60.s204、控制器基于提取的图像特征获得待识别对象的语义信息。
61.基于上述四种图像特征,使用检测算法,可以将提取到的待识别对象的图像特征与已知类别的对象的图像特征进行匹配,以获取待识别对象的语义信息。检测算法可以采用以下方式中至少一种:支持向量机(support vector machine,svm)、自适应增强(adaptive boosting,adaboost)算法以及贝叶斯网络。
62.语义信息包括:待识别对象的类别。其中,对象的类别包括静态对象和动态对象,其中,静态对象包括智能车所在路段的基础设施。动态对象包括可移动的人、车、物体。更具体地,针对每种类别的对象又可以进一步区分该类别的属性,例如,当动态对象为车时,可以进一步确定车的型号;当动态对象为人时,可以进一步确定是儿童还是成人。此外,控制器还可以确定待识别对象被识别为具体类别的概率,例如,微型机动车的概率为20%,小型机动车的概率为70%,中型机动车的概率为10%。
63.可选地,语义信息还包括待识别对象的第一图像检测框和第一图像检测框的中心点。
64.第一图像检测框为在第一数据中标识包括待识别对象所有像素点的区域,例如,该区域可以是包括待识别对象所有像素点的最小区域,根据该区域的中心点所在世界坐标系中的坐标可以估计待识别物体与智能车的相对位置,在后续的步骤中可以进一步结合待识别对象的尺寸和雷达采集的点云数据确定精准的定位结果。
65.可选地,在获得待识别图像的类别的基础上,还可以执行分割算法,判断图像中每一个像素点是否属于检测算法得到的待识别对象的类别。常见的分割算法有基于阈值的分
割算法、分水岭算法以及基于边缘检测的分割算法。本技术对分割算法不做限定,具体实施过程中可以根据实际情况选择具体分割算法。
66.s205、控制器计算待识别对象的尺寸。
67.下面将参考图3,阐述基于步骤s204获取的待识别对象的语义信息,控制器如何计算得到待识别对象的尺寸,s205具体步骤如下:
68.s301、控制器使用待识别对象的类别计算该对象的尺寸的第一值。
69.根据步骤s204得到的待识别对象的类别,在控制器中预置的先验尺寸表中检索该对象对应的尺寸,作为待识别对象的尺寸的第一值,为了便于描述,也可以将先验尺寸表称为第一数据表。
70.第一数据表构建方法如下:预先采集不同类别的对象的真实尺寸,例如不同类型、不同品牌的车辆的尺寸。采集的方法可以采用以下方法中至少一种:使用网络爬虫的方式采集网上已有的对象的尺寸数据,采集各个车厂提供的车辆尺寸数据以及采集真实场景中摄像头拍摄的视频中出现的对象的尺寸数据。然后统计各种不同对象的类别以及尺寸,建立第一数据表。
71.示例地,表1为本技术实施例提供的一种第一数据表,如表所示,表中标识了不同类型的对象对应的尺寸值。需要说明的是,这个实施例中尺寸值仅使用长宽高代替,具体实施例中还可以根据目标的形状选择更合适的参数类型和参数个数作为先验尺寸表中的尺寸值。
72.表1、第一数据表
73.对象类别长宽高微型机动车2.81.61.6小型机动车3.41.61.6中型机动车4.01.82.0
74.根据对象类别的识别结果形式的不同,可以通过表1获取该类别所对应的待识别对象的尺寸的第一值。具体可以采用以下方式中任意一种:
75.方式一:当s204待识别对象被识别为一种类别时,根据第一数据表获取该类别的尺寸的值,该值包括用于标识待识别对象的尺寸的大小的集合,例如,如表1所示,当待识别对象被识别为小型机动车时,可以在第一数据表中检索到其对应的尺寸的第一值包括长为3.4,宽为1.6,高为1.6。
76.方式二:当s204待识别对象的类别为两种或两种以上时,该待识别对象的尺寸可以根据上述两种或两种类别对应的尺寸获得。
77.首先,利用向量形式标识待识别对象已被识别的类别,该向量中包括类别和被识别为该类别的概率。例如:待识别对象被识别为微型机动车的概率为20%,待识别对象被识别为小型机动车的概率为70%,待识别对象被识别为中型机动车的概率为10%,则该待识别对象的类别的向量形式可以表示为((微型机动车:0.2),(小型机动车:0.7),(中型机动车:0.1))。则待识别对象的尺寸的第一值可以根据上述各个类别和概率的加权和确定。例如,在上述示例中,该待识别对象的尺寸的第一值包括长为0.2*2.8+0.7*3.4+0.1*4.0,宽为0.2*1.6+0.7*1.6+0.1*1.8,高为0.2*1.6+0.7*1.6+0.1*2.0,即第一值为长为3.34、宽为1.62、高为1.64。
78.可选地,在对象类别为多种不确定类别的场景下,在确定待识别对象的尺寸的第一值时,除了结合待识别对象的概率确定第一值外,还可以结合权值确定第一值。具体地,该权值可以根据待识别对象被识别为不同类别时,对自车的安全影响力。例如,当同一待识别对象被识别为微型机动车时,对自车的安全影响力为0.9;待识别对象被识别为小型机动车时,对自车的安全影响力为1.0;待识别对象被识别为中型机动车时,对自车的安全影响力为1.1。例如,参见表1所示的内容,当待识别对象的类别的向量形式为((微型机动车:0.2:0.9),(小型机动车:0.7:1.0),(中型机动车:0.1:1.1))时,结合权值参数后,该待识别对象的尺寸的第一值的长为0.9*0.2*2.8+1.0*0.7*3.4+1.1*0.1*4.0,宽为0.9*0.2*1.6+1.0*0.7*1.6+1.1*0.1*1.8,高为09*0.2*1.6+1.0*0.7*1.6+1.1*0.1*2.0。最终确认的第一值中长为3.324,宽为1.606,高为1.628。
79.s302、控制器对待识别对象的尺寸的第一值进行修正,得到该对象的尺寸的第二值。
80.控制器可以将待识别对象的第一图像检测框和尺寸的第一值同时作为预置的尺寸修正模型的输入,获得尺寸的第二值。
81.其中,预置的尺寸修正模型为经过机器学习训练后获得的一种人工智能(artificial intelligence,ai)模型,训练尺寸修正模型的过程可以使用监督训练中的反向传播算法实现,具体过程可以如下:
82.(1)构建标定的样本集。
83.预先使用摄像头采集多个对象的图像数据,并利用图像数据获取这些对象的图像检测框。其中,从图像数据中获取图像检测框的方法可以采用与本技术提供的感知方法中从第一数据中获取待识别对象的第一图像检测框类似的方法,例如步骤s203-s204。进一步利用采集的数据构建标定的样本集,样本集包括多个样本,样本集中每个样本包括一个对象的图像检测框、根据第一数据表查找该对象的类别确定的尺寸初始值和标签(该标签为该对象的真实尺寸)。
84.(2)初始化尺寸修正模型。
85.尺寸修正模型可以采用三层结构的全连接神经网络模型,第一层为输入层,包括两个节点,分别用来接收一个样本的图像检测框和尺寸初始值。其中,用来接收图像检测框的节点由多个子节点构成,每一个子节点接收样本的图像检测框的一个像素。
86.尺寸修正模型的第二层为隐藏层,包括至少一个节点,需要说明的是,这些节点可以组成一层或多层结构,每一层可以包括一个或多个节点,层数和每一层的节点数量不受本技术的限制。隐藏层的第一层的每一个节点都与输入层的每一个节点相连,第一层每一个节点的值由与之相连的输入层的每一个节点的加权和得到;隐藏层的中间层的每一层的每一个节点都与其上一层的每一个节点相连,每一层每一个节点的值由与之相连的上一层的每一个节点的加权和得到;隐藏层的最后一层的每一个节点还与输出层的每一个节点相连,输出层的每一个节点的值由与之相连的最后一层的每一个节点的加权和得到。将所有节点的权值作为待训练的参数。
87.尺寸修正模型的第三层为输出层,包括一个节点,用于输出样本经过隐藏层的节点计算之后得到的尺寸修正值。
88.(3)设置尺寸修正模型中待训练的参数的初始参数值,初始参数值不收本技术的
限制。
89.(4)将样本集中一个样本的图像检测框和尺寸的初始值作为尺寸修正模型的输入,计算该样本经过尺寸修正模型后输出的尺寸修正值与标签的误差。
90.(5)使用梯度下降法,根据误差与待训练参数的偏导数,从最后一层的节点开始,反向更新每一个节点的权值。
91.(6)使用更新后的参数值返回执行步骤(4)和步骤(5)直到得到的误差的数值小于第一阈值。第一阈值应该小于样本集中所有样本的尺寸估计值与该样本标签之间的误差的最小值。
92.(7)重复步骤(4)、(5)和(6),直到样本集中的所有样本执行完毕,即得到最终的尺寸修正模型。
93.经过训练之后,尺寸修正模型输出的尺寸修正值与标签(真实尺寸)之间的误差小于第一阈值,即小于输入的尺寸估计值与标签(真实尺寸)之间的误差。因此,在步骤s302中,相比于尺寸的第一值,将待识别对象的尺寸第一值和第一图像检测框输入训练好的尺寸修正模型后,得到的尺寸的第二值与待识别对象的真实尺寸的误差更小。
94.需要说明的是,预置的尺寸修正模型可以在步骤s302之前执行,例如;可以将预置的尺寸修正模型存储在控制器中,在执行感知过程时直接获取。训练尺寸修正模型的处理也可以是在步骤s203之前训练获得预置的尺寸修正模型。
95.可选地,尺寸的第二值也可以不通过上述尺寸修正模型得到,而是直接使用尺寸的第一值加上权值的第一图像检测框在世界坐标系中的实际大小计算得到,该权值可以使用经验值。
96.s206、控制器对雷达进行标定。
97.与步骤s201类似,控制器确定待识别对象表面某点在以雷达为原点的世界坐标系中的位置与其在雷达点云数据中对应的点之间的相互关系。
98.可选地,也可以由雷达对自身进行标定。
99.s207、控制器获取雷达采集的点云数据。
100.为了便于描述,也可以将雷达采集的点云数据称为第二数据。可选地,与步骤s202类似,获取点云数据之后,对雷达不同时刻采集的点云数据打上相应的时间标签。
101.s208、控制器校准摄像头采集的图像数据和雷达采集的点云数据,以在同一坐标系中获得标识图像数据和雷达数据。
102.根据摄像头标定结果,可以得到图像数据中待识别对象表面某点在以摄像头为原点的世界坐标系中的坐标。同样,根据雷达标定结果,可以得到雷达数据中待识别对象表面某点在以雷达为原点的世界坐标系中的坐标。选取具有相同时间标签的图像数据和点云数据,可以采取以下方式中至少一种,在同一坐标系中标识图像数据和雷达数据的结果:
103.方式一:根据摄像头相对于雷达的位置,计算摄像头在以雷达为原点的世界坐标系中的坐标,并与图像数据中待识别对象表面某点在以摄像头为原点的世界坐标系中的坐标求和,即可在以雷达为原点的世界坐标系中,同时标识图像数据和雷达数据的坐标。
104.方式二:根据雷达相对于摄像头的位置,计算雷达在以摄像头为原点的世界坐标系中的坐标,并与点云数据中待识别对象表面某点在以雷达为原点的世界坐标系中的坐标求和,即可在以雷达为原点的世界坐标系中,同时标识图像数据和雷达数据的坐标。
105.方式三:根据摄像头和雷达相对于智能车中心点的位置,分别计算摄像头和雷达在以智能车中心点为原点的世界坐标系中的坐标,并将摄像头的坐标与图像数据中待识别对象表面某点在以摄像头为原点的世界坐标系中的坐标求和,以及将雷达的坐标与点云数据中待识别对象表面某点在以雷达为原点的世界坐标系中的坐标求和,即可在以智能车中心点为原点的世界坐标系中,同时标识图像数据和雷达数据的坐标。
106.值得说明的是,步骤s201和s206的标定过程可以在智能车出厂时进行处理;或者,在获取第一数据和第二数据之前进行处理,控制器可以同时对摄像头和雷达进行标定,也可以先对摄像头进行标定,再对雷达进行标定。
107.接下来,由控制器基于第二数据进一步获得待识别对象的定位结果。为了便于描述,也可以基于第二数据获得待识别对象的第二信息,第二信息包括待识别对象的定位结果,该定位结果标识待识别物体的与智能车的相对位置。参考图4,阐述控制器如何计算得到待识别对象的定位结果,s209具体步骤如下:
108.s401、控制器基于点云数据执行聚类,识别点云数据中属于同一个待识别对象的点。
109.将s204中获得的待识别对象的第一图像检测框的中心点和s302获得的尺寸的第二值作为聚类算法的输入参数,确定待识别对象的点云数据所在区域,再使用聚类算法对第二数据进行聚类,由此结合图像数据获得的结果确定点云数据中聚类区域。其中,聚类算法包括基于密度的聚类方法,例如具有噪声的基于密度的聚类方法(density-based spatial clustering of applications with noise,dbscan)。
110.可选地,控制器也可以使用待识别对象的第一图像检测框的中心点和尺寸的第二值的偏移值作为聚类算法的输入参数,确定待识别对象的点云数据所在区域。其中,偏移值可以按照历史数据的统计值获得,也可以根据控制器的计算能力和对业务处理的时延确定偏移值。
111.可选地,还可以根据步骤s204得到的待识别对象的类别和基于图像数据的定位结果,在控制器中预置的先验点云数据表中检索该对象对应的点云数据,叠加在获取到的点云数据中,一起执行聚类。为了便于描述,也可以将先验点云数据表称为第二数据表。
112.第二数据表构建方式如下:预先采集真实场景下的不同类别的对象在不同距离下的点云数据,采集的方法可以收集已有场景的点云数据库,或者采集真实场景中雷达生成的对象的点云数据。然后统计采集到的数据中的不同类别的对象以及该对象与智能车之间的不同距离所对应的点云数据,建立第二数据表。
113.示例地,表2为本技术实施例提供的一种先验点云数据表,如表所示,表中标识了不同类型的对象,以及该对象与雷达之间的不同距离所对应的点云数据。
114.表2、第二数据表
115.对象类别距离点云数据微型机动车10点云数据1微型机动车20点云数据2微型机动车30点云数据3小型机动车10点云数据4小型机动车20点云数据5
小型机动车30点云数据6中型机动车10点云数据7中型机动车20点云数据8中型机动车30点云数据9
116.根据s204中获得的待识别对象的基于图像数据的定位结果计算出对象与雷达之间的距离,再利用s204中获得的待识别对象的类别,可以在点云数据先验表中检索到对应的点云先验数据。
117.聚类完毕之后,执行s402,控制器计算待识别对象的第一定位结果。可以将一个的聚类范围的所有点云数据的点的坐标加权平均,作为聚类范围的中心点,并计算该点的坐标值与智能车中心点之间的相对位置。需要说明的是,该权值可以使用经验值。
118.s403、控制器对待识别对象的第一定位结果进行修正,得到该对象的第二定位结果。
119.相比于尺寸的第一值,第二定位结果与待识别对象的真实定位结果的误差更小。具体方法如下:
120.(1)将同一个对象的第一定位结果和第一图像检测框的中心点进行匹配,匹配算法可以采用匈牙利(hungarian)算法或者扩展匈牙利(kuhn-munkres algorithm,km)算法。
121.(2)将第一定位结果和第一图像检测框的中心点同时输入至控制器中预置的定位修正模型,得到第二定位结果。定位修正模型的训练过程与步骤s302中尺寸修正模型的训练过程类似,区别为,在样本集构建阶段,除了预先获取多个对象的图像检测框外,还需要预先使用雷达采集这些对象的点云数据,并利用点云数据获取这些对象的估计定位结果。其中,从点云数据中获取估计定位结果的方法可以采用与本技术提供的感知方法中从第二数据中获取待识别对象的第一定位结果类似的方法,例如步骤s401-s402。进一步构建样本集,包括多个样本,样本集中每个样本包括一个对象的图像检测框的中心点坐标、初始定位结果和标签(该标签为该对象的真实定位结果),训练方法在此不做赘述。
122.可选地,第二定位结果也可以不通过上述定位修正模型得到,而是直接使用第一定位结果加上权值的第一图像检测框的中心点在世界坐标系中的坐标计算得到,该权值可以使用经验值。
123.通过上述过程的描述可知,控制器在对校准后的点云数据进行聚类之前,使用待识别对象的语义信息和尺寸作为聚类算法的关键参数,提高了聚类算法的效率和精度。同时利用事先建立好的先验点云数据表作为先验信息,叠加在实际获取的点云数据中,弥补了雷达点云数据有可能存在的密度上的不足,最终得到高精度的定位信息。
124.接下来,结合具体示例进一步解释本技术提供的感知方法。
125.图5将直观的呈现对一个水平剖面上的点云数据进行聚类的过程:
126.图a)表示智能车101上标定好的摄像头102采集的图像数据,包括三个待识别对象(501-503)。其中,待识别对象501上的点510在以摄像头为原点的坐标系中的坐标为(x1,y1)。
127.图b)表示智能车101上标定好的雷达103采集的同一时间标签的点云数据。其中,点云数据的点511在以雷达为原点的坐标系中的坐标为(x2,y2)。
128.经过校准之后在以智能车为原点的坐标系中同时标识图像数据和点云数据,如图
c)所示,摄像头102在以智能车位原点的坐标系中坐标为(n1,m1),雷达在以智能车位原点的坐标系中坐标为(n2,m2),则图像数据中点510在以智能车位原点的坐标系中坐标为(n1+x1,m1+y1),点云数据中点511在以智能车位原点的坐标系中坐标为(n2+x2,m2+y2)。
129.可以单独利用图像数据获取待识别对象的第一图像检测框,具体方法参见步骤s203和s204。如图d)所示,矩形框520标识对象501的第一图像检测框,空心五角星521标识对象501的第一图像检测框的中心点,后续步骤中将作为聚类算法的输入参数之一,用于作为实现点云数据聚类操作的中心点。还可以利用图像数据获取待识别对象的尺寸的第二值,参见步骤s205,例如,对象501的长宽高分别为3.4、1.6和1.6。
130.接下来,结合待识别对象的第一图像检测框的中心点和尺寸的第二值,确定待识别对象在校准后的点云数据中的所在区域,设置聚类算法的参数。如图e)所示,以第一图像检测框的中心点作为聚类算法搜索过程的中心点,以尺寸的第二值中的最大参数作为聚类算法搜索过程的半径,例如使用对象501的第一图像检测框的中心点521作为聚类算法搜索过程的中心点531,尺寸的第二值中长宽高三个参数中最大的值3.4作为聚类算法搜索过程的半径532,则虚线圆框533即为对象501的聚类算法的搜索区域。
131.图f)是聚类算法的结果,包括三个聚类范围,分别由黑色实心圆、空心圆和虚点圆表示,虚线椭圆标识聚类范围的边界线,黑色实心五角星标识聚类范围的中心点,中心点的坐标是聚类范围内所有点的坐标的加权平均值,例如,对象501的聚类范围的边界线542和聚类范围的中心点541。根据点541与坐标原点(即智能车中心)之间的相对位置可以得到对象501的第一定位结果。一些处于虚线椭圆范围之外的黑色实心圆不属于任何的聚类目标,为噪声点,例如点543。
132.可选地,由于实际获得的点云数据可能比较稀疏,聚类效果较差,因此可以将先验点云数据叠加在实际点云数据中,一起进行聚类,如图g)所示,较小的黑色实心点即为叠加在实际点云数据中的先验点云数据,例如点551。
133.图h)为叠加先验点云数据之后的聚类结果,与图f)类似,虚线椭圆标识聚类范围的边界线,黑色实心五角星标识聚类范围的中心点,例如,对象501的聚类范围的边界线562和聚类范围的中心点561。根据点561与坐标原点(即智能车中心)之间的相对位置可以得到对象501的第一定位结果。
134.综上所述,本技术实施例提供一种感知方法,结合摄像头图像数据和雷达点云数据,综合利用图像感知算法在获取对象语义信息和尺寸信息方面的优势以及点云数据聚类算法在获取定位信息方面的优势,并使用图像感知算法的结果优化了聚类算法,最终实现了获得了高精度的感知结果。
135.作为一种可能的实施例,当控制器部署在数据中心时,由智能车上的摄像头和雷达分别完成对自身的标定,并由智能车的网络设备将摄像头采集的图像数据和雷达采集的点云数据通过高速无线网络发送给数据中心。部署于数据中心的控制器获取到感知数据后,采用类似s203-s205的步骤从图像数据中获得带识别对象的尺寸,并采用类似s208-s209的步骤结合图像数据和点云数据获得待识别对象的定位结果。最后,控制器可以将得到的感知结果返回给该智能车。智能车的网络设备接收到感知结果后,可以在智能车内显示屏中呈现给驾驶员,辅助驾驶员安全驾驶车辆;还可以将感知结果发送给执行器,由执行器利用感知结果规划车辆的行驶路径和操作指令并执行。
136.可选地,部署于数据中心的控制器在从图像数据中获得待识别对象尺寸之前,还可以采用类似s202的步骤对图像数据进行预处理。
137.作为一种可能的实施例,当控制器部署在边缘节点时,采用与控制器部署于数据中心的类似的方法,部署于边缘节点的控制器可以获取智能车的感知数据,并将得到感知结果返回给该智能车。
138.可选地,边缘节点中也可以设置摄像头和/或雷达,部署于边缘节点的控制器也可以获取边缘节点中的摄像头和/或雷达采集的图像数据和/点云数据,并将得到感知结果返回给所有连接该边缘节点的智能车。
139.值得说明的是,对于上述方法实施例,为了简单描述,故将其都表述为一系列的动作组合,但是本领域技术人员应该知悉,本技术并不受所描述的动作顺序的限制。
140.本领域的技术人员根据以上描述的内容,能够想到的其他合理的步骤组合,也属于本技术的保护范围内。其次,本领域技术人员也应该熟悉,说明书中所描述的实施例均属于优选实施例,所涉及的动作并不一定是本技术所必须的。
141.上文中结合图1至图5,详细描述了本技术实施例所提供的感知方法,下面将结合图6和图7,进一步介绍本技术实施例所提供的感知装置和计算机设备。
142.图6为本技术提供的一种感知装置600的示意图,包括第一获取单元601、第二获取单元602、处理单元603和通讯单元606。
143.第一获取单元601,用于获取第一数据。
144.第二获取单元602,用于获取第二数据。
145.处理单元603,用于根据所述第一数据和所述第二数据确定待识别对象的感知结果。
146.应理解的是,本技术实施例的感知装置600可以通过专用集成电路(application-specific integrated circuit,asic)实现,或可编程逻辑器件(programmable logic device,pld)实现,上述pld可以是复杂程序逻辑器件(complex programmable logical device,cpld),现场可编程门阵列(field-programmable gate array,fpga),通用阵列逻辑(generic array logic,gal)或其任意组合。也可以通过软件实现图2至图5所示的感知方法时,感知装置600及其各个模块也可以为软件模块。
147.可选地,处理单元可以包括第一处理单元604和第二处理单元605。
148.所述第一处理单元604,用于根据第一数据确定待识别对象的第一信息,第一信息包括待识别对象的类别和尺寸。
149.所述第二处理单元605,用于根据第一信息和第二数据获得第二信息,第二信息包括待识别对象的定位结果。其中,定位结果用于标识待识别对象与第二设备所在智能车的相对位置。
150.可选地,第一处理单元604,还用于根据所述第一数据确定所述待识别对象的类别,以及根据所述类别,在第一数据表中确定检索待识别对象的尺寸的第一值,其中,第一数据表用于记录不同类别的对象的尺寸的映射关系。并且,第一处理单元还用于修正待识别对象的尺寸的所述第一值,获得待识别对象的尺寸的第二值。其中,第二值与待识别对象的尺寸的真实值的误差小于第一值与待识别对象的尺寸的真实值的误差。
151.可选地,第一处理单元604,还用于根据所述第一数据待识别对象的类别和待识别
对象被识别为该类别的概率,以及根据所述类别和所述概率,在第一数据表中确定检索待识别对象的尺寸的第一值。
152.可选地,第二处理单元605,用于将第一信息作为聚类算法的初始参数,以及,对第二数据执行聚类,获得聚类结果,其中,聚类结果用于标识第二数据中属于同一个待识别目标的数据。并且,第二处理单元还用于根据聚类结果确定待识别对象的第一定位结果,以及,修正第一定位结果,获得待识别对象的第二定位结果。其中,第二定位结果与待识别对象的真实定位结果的误差小于第一定位结果与待识别对象的真实定位结果的误差。
153.可选地,第二处理单元605,还用于在根据第一信息和第二数据获得所述第二信息之前,对第一数据和第二数据进行校准,以获得在同一坐标系中标识第一数据和第二数据的结果。
154.可选地,感知装置600还包括通讯单元606,用于与部署于其他智能车的装置共享所述感知结果。
155.根据本技术实施例的感知装置600可对应于执行本技术实施例中描述的方法,并且感知装置600中的各个单元的上述和其它操作和/或功能分别为了实现图2至图5中的各个方法的相应流程,为了简洁,在此不再赘述。
156.综上所述,本技术实施例提供的感知装置600,处理单元可以结合多种类型的数据,获得待识别物体的高精度的类别、尺寸和定位结果,为智能车自动驾驶功能或者智能车驾驶员提供准确的环境信息,提高智能车驾驶的安全性。
157.图7为本技术实施例提供的一种计算机设备700的示意图,如图所示,计算机设备700包括处理器701、存储器702、通信接口703总线704和内存705。其中,处理器701、存储器702、通信接口703、内存705通过总线704进行通信,也可以通过无线传输等其他手段实现通信。内存705用于存储计算机执行指令,处理器701用于执行内存705存储的计算机执行指令以实现下述操作步骤:
158.获取第一数据。
159.获取第二数据。
160.根据所述第一数据和所述第二数据确定待识别对象的感知结果。
161.应理解,在本技术实施例中,该处理器701可以是cpu,该处理器701还可以是其他通用处理器、数字信号处理器(digital signal processing,dsp)、专用集成电路(application specific integrated circuit,asic)、现场可编程门阵列(field programmable gate array,fpga)或者其他可编程逻辑器件、分立门或者晶体管逻辑器件、分立硬件组件等。通用处理器可以是微处理器或者是任何常规的处理器等。
162.该存储器702可以包括只读存储器和随机存取存储器,并向处理器701提供指令和数据。存储器702还可以包括非易失性随机存取存储器。例如,存储器702还可以存储设备类型的信息。
163.该存储器702可以是易失性存储器或非易失性存储器,或可包括易失性和非易失性存储器两者。其中,非易失性存储器可以是只读存储器(read-only memory,rom)、可编程只读存储器(programmable rom,prom)、可擦除可编程只读存储器(erasable prom,eprom)、电可擦除可编程只读存储器(electrically eprom,eeprom)或闪存。易失性存储器可以是随机存取存储器(random access memory,ram),其用作外部高速缓存。通过示例性
但不是限制性说明,许多形式的ram可用,例如静态随机存取存储器(static ram,sram)、动态随机存取存储器(dram)、同步动态随机存取存储器(synchronous dram,sdram)、双倍数据速率同步动态随机存取存储器(double data date sdram,ddr sdram)、增强型同步动态随机存取存储器(enhanced sdram,esdram)、同步连接动态随机存取存储器(synchlink dram,sldram)和直接内存总线随机存取存储器(direct rambus ram,dr ram)。
164.该总线704除包括数据总线之外,还可以包括电源总线、控制总线和状态信号总线等。但是为了清楚说明起见,在图中将各种总线都标为总线704。
165.应理解,根据本技术实施例的计算设备700可对应于本技术实施例中的感知装置600,并可以对应于执行根据本技术实施例中图2至图5所示的方法200中的控制器,并且计算设备700中的各个模块的上述和其它操作和/或功能分别为了实现图中的各个方法的相应流程,为了简洁,在此不再赘述。
166.综上所述,本技术实施例提供的计算机设备,结合至少两种类型的感知数据,利用多种数据提供的不同方面的信息,获得高精度的感知结果。
167.本技术还提供一种感知系统,包括第一设备,第二设备和控制器。第一设备用于采集第一数据,具体地,第一设备可以为摄像头;第二设备用于采集第二数据,具体地,第二设备可以为雷达;控制器用于实现上述感知装置或计算机设备中所执行的方法的操作步骤,控制器可以部署于智能车上、边缘节点中或数据中心中。控制器通过上述感知系统,使用多种设备采集不同的数据,以便控制器可以结合多种数据,得到高精度的感知结果。
168.上述实施例,可以全部或部分地通过软件、硬件、固件或其他任意组合来实现。当使用软件实现时,上述实施例可以全部或部分地以计算机程序产品的形式实现。所述计算机程序产品包括一个或多个计算机指令。在计算机上加载或执行所述计算机程序指令时,全部或部分地产生按照本技术实施例所述的流程或功能。所述计算机可以为通用计算机、专用计算机、计算机网络、或者其他可编程装置。所述计算机指令可以存储在计算机可读存储介质中,或者从一个计算机可读存储介质向另一个计算机可读存储介质传输,例如,所述计算机指令可以从一个网站站点、计算机、服务器或数据中心通过有线(例如同轴电缆、光纤、数字用户线(digital subscriber line,dsl))或无线(例如红外、无线、微波等)方式向另一个网站站点、计算机、服务器或数据中心进行传输。所述计算机可读存储介质可以是计算机能够存取的任何可用介质或者是包含一个或多个可用介质集合的服务器、数据中心等数据存储设备。所述可用介质可以是磁性介质(例如,软盘、硬盘、磁带)、光介质(例如,dvd)、或者半导体介质。半导体介质可以是固态硬盘(solid state drive,ssd)。
169.以上所述,仅为本技术的具体实施方式。熟悉本技术领域的技术人员根据本技术提供的具体实施方式,可想到变化或替换,都应涵盖在本技术的保护范围之内。
相关技术
网友询问留言
已有0条留言
- 还没有人留言评论。精彩留言会获得点赞!
1