一种用于篇章级英译中机器翻译测试集的构建方法与流程
[0001]
本发明涉及一种机器翻译领域,特别涉及一种用于篇章级英译中机器翻译测试集的构建方法。
背景技术:
[0002]
目前,随着机器翻译技术的逐步完善,贴近实际应用的机器翻译方面的研究越来越多,机器翻译领域的研究重点也逐步从句子级别过渡到篇章级别。由于篇章级别的机器翻译相比于句子级别的机器翻译所关注的文本范围更广,所要考虑的问题与现象更多,所以难度也进一步增加。
[0003]
在研究机器翻译模型怎样进一步提高翻译能力的同时,如何能更加合理地对模型翻译能力进行评测也成为了研究者们关心的问题。篇章级的机器翻译模型除了要考虑句内的各种语言现象的翻译能力,还要考虑句间(跨句)的语言现象,这要求机器翻译模型对当前句的上下文有综合翻译能力。在评测篇章级机器翻译模型的翻译能力时,同样也要关注模型对于句间的语言现象的翻译能力。
[0004]
已有的评测指标多为自动评测时所用到的评测指标,在计算指标的分值时,多为仅考虑句内的各种语言现象,更适合对句内的各种语言现象进行评测,而没有特别为篇章级语言现象所设计的相关的评测指标。对于篇章级的语言现象还需要具有针对性的评测方法。
[0005]
在其他翻译语言对上,也有对于篇章级机器翻译的相关研究,对模型翻译能力的测评时,是从某个篇章级语言现象考虑。例如,在英法、英德翻译方向上考虑相应语言中代词的翻译效果,在法英、英德和法德等翻译方向上考虑篇章级连接词的翻译效果,而在省略现象中仅看到了英俄翻译方向上相关的研究。
[0006]
参考其他语言方向上的相关研究,结合英译中的机器翻译时的实际情况,在此发明中我们针对英译中时容易出现错误的三种语言现象:指代、篇章级连接词和省略现象提出构建相应测试集的方法,根据此方法构建的测试集,可以用来测试不同的篇章级机器翻译模型的翻译能力。
技术实现要素:
[0007]
本发明为解决公知技术中存在的技术问题而提供一种用于篇章级英译中机器翻译测试集的构建方法。
[0008]
本发明为解决公知技术中存在的技术问题所采取的技术方案是:一种用于篇章级英译中机器翻译测试集的构建方法,该方法包括:
[0009]
获取具有指代、连接、省略的衔接语法的篇章级英文文本数据及其对应的中文翻译文本数据;
[0010]
对获取的中英文文本数据进行初步过滤处理,形成仅包含中英文词汇的文本数据;将处理后的英文文本数据作为源语言数据,将处理后的中文翻译文本数据作为目标语
言数据;
[0011]
将同时具有单复数或男女性别两种表达含义的代词称为两义代词,选取两义代词作为查找参数,搜索源语言数据,当源语言数据中的某一句出现两义代词时,且该句的前一句给出决定单复数或男女性别的信息,则检查目标语言数据中对应的翻译文本,判断对应的单复数或性别表述是否正确,并对错误进行修正;
[0012]
将具有两种以上含义的英文篇章级连接词称为多义连词,选取若干个多义连词,作为查找参数搜索源语言数据,当源语言数据中的某一句出现多义连词时,则检查目标语言数据中该句对应的翻译文本及其上下文信息,判断对多义连词的翻译是否正确,并对错误进行修正;
[0013]
选取用于替代因上下句重复出现而被省略的动词的助动词,作为查找参数搜索源语言数据,当源语言数据中的某一句出现助动词以及相应的否定形式时,则检查目标语言数据中对应的翻译文本是否翻译出其省略动词的含义,并对错误进行修正;
[0014]
将检查修正后的源语言数据及其对应的目标语言数据分别进行分词处理,并对源语言数据进行词性标注后制成候选数据集;分别设置筛选参数,从候选数据集中筛选相应的源语言数据及其对应的目标语言数据,分别制成指代测试集、篇章级连接词测试集及省略测试集。
[0015]
进一步地,从候选数据集中筛选指代测试集的筛选方法为:
[0016]
设源语言数据中,单数名词词性标签为nn,复数名词词性标签为nns,专有词性标签为nr;
[0017]
第一筛选参数为:源语言数据中的某一句中包含有两义代词;该句的前一句包含有词性标签为nn、nns和nr的名词词性的单词,该句对应的目标语言数据中包含“他们”,“她们”,“它们”,“你”,“你们”或物主形式;
[0018]
第二筛选参数为:该句的前一句中包含单复数或男女性别的信息;
[0019]
先筛选出符合第一筛选参数的源语言数据及其对应的目标语言数据;对符合第一筛选参数条件的数据再采用第二筛选参数进行筛选,将同时满足第一筛选参数及第二筛选参数的源语言数据及其对应的目标语言数据,集合制成指代测试集。
[0020]
进一步地,从候选数据集中筛选篇章级连接词测试集的筛选方法为:
[0021]
设源语言数据中,并列连接词词性标签为cc,前/后置连词词性标签为in,特殊疑问词词性标签为wrb;
[0022]
第三筛选参数为:源语言数据中的某一句中包含有多义连词;并且该多义连词的词性标签满足cc、in、wrb中的一种;
[0023]
先筛选出符合第三筛选参数的源语言数据及其对应的目标语言数据,再检查筛选出的目标语言数据中是否存在对应的连词翻译,如果有对应的连词翻译,则该句源语言数据及其对应的目标语言数据符合筛选条件;
[0024]
如果没有,则继续检查目标语言数据的前一句是否包含连接词消除歧义所用的信息;如果有,则该句源语言数据及其对应的目标语言数据符合筛选条件;否则不符合;
[0025]
对应每个连接词的每种含义,从候选数据集中,对应筛选出相同数量的符合上述筛选参数条件的数据,集合制成指代测试集。
[0026]
进一步地,从候选数据集中筛选篇章级连接词测试集的筛选方法为:
[0027]
设源语言数据中,系动词词性标签为vc,动词词性标签为vb,动词过去式为vbd;
[0028]
第四筛选参数为:源语言数据中的某一句中包含有至少一个助动词;并且该助动词的词性满足vc、vb、vbd中的一个;
[0029]
先筛选出符合第四筛选参数的源语言数据及其对应的目标语言数据;再对筛选出的数据中包含助动词的源语言句子及其所对应的中文翻译文本进行检查,确认对应该句的动词翻译与前一句中的动词翻译是否一致,将前后句动词翻译一致的源语言数据及其对应的目标语言数据,集合制成省略测试集。
[0030]
进一步地,使用python系统中的匹配算法对获取的中英文文本数据进行初步过滤处理。
[0031]
进一步地,源语言数据采用moses工具进行分词处理。
[0032]
进一步地,目标语言数据采用结巴分词工具进行分词处理。
[0033]
进一步地,对源语言数据进行词性标注的方法为:
[0034]
采用python系统,先从stanfordcorenlp工具中导入stanfordcorenlp文件包,然后使用stanfordcorenlp工具生成原始的词性标注文件,之后根据不同的语言现象再在该标注文件中进行筛选。
[0035]
进一步地,从opensubtitles电影字幕数据集中获取具有指代、连接、省略的衔接语法的篇章级英文文本数据及其对应的中文翻译文本数据。
[0036]
本发明具有的优点和积极效果是:
[0037]
针对篇章级英译中机器翻译里常见的错误现象,采用本发明的方法能够构建分别对应指代、篇章级连接词和省略现象来构建相应的测试集。可用于测试及评估不同机器翻译模型篇章级翻译能力。
附图说明
[0038]
图1是本发明的一种工作流程图。
具体实施方式
[0039]
为能进一步了解本发明的发明内容、特点及功效,兹列举以下实施例,并配合附图详细说明如下:
[0040]
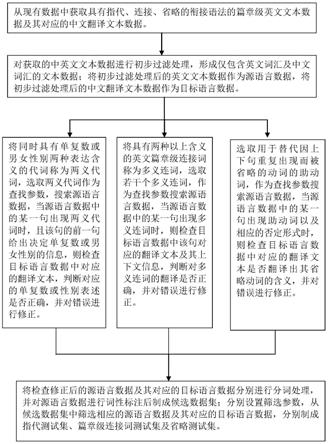
请参见图1,一种用于篇章级英译中机器翻译测试集的构建方法,该方法包括:
[0041]
从现有数据中获取具有指代、连接、省略的衔接语法的篇章级英文文本数据及其对应的中文翻译文本数据;可从opensubtitles电影字幕数据集等现有数据中获取具有指代、连接、省略的衔接语法的篇章级英文文本数据及其对应的中文翻译文本数据。
[0042]
对获取的中英文文本数据进行初步过滤处理,形成仅包含英文词汇及中文词汇的文本数据;将初步过滤处理后的英文文本数据作为源语言数据,将初步过滤处理后的中文翻译文本数据作为目标语言数据;
[0043]
将同时具有单复数或男女性别两种表达含义的代词称为两义代词,选取两义代词作为查找参数,搜索源语言数据,当源语言数据中的某一句出现两义代词时,且该句的前一句给出决定单复数或男女性别的信息,则检查目标语言数据中对应的翻译文本,判断对应的单复数或性别表述是否正确,并对错误进行修正;
[0044]
将具有两种以上含义的英文篇章级连接词称为多义连词,选取若干个多义连词,作为查找参数搜索源语言数据,当源语言数据中的某一句出现多义连词时,则检查目标语言数据中该句对应的翻译文本及其上下文信息,判断对多义连词的翻译是否正确,并对错误进行修正;
[0045]
选取用于替代因上下句重复出现而被省略的动词的助动词,作为查找参数搜索源语言数据,当源语言数据中的某一句出现助动词以及相应的否定形式时,则检查目标语言数据中对应的翻译文本是否翻译出其省略动词的含义,并对错误进行修正;
[0046]
将检查修正后的源语言数据及其对应的目标语言数据分别进行分词处理,并对源语言数据进行词性标注后制成候选数据集;分别设置筛选参数,从候选数据集中筛选相应的源语言数据及其对应的目标语言数据,分别制成指代测试集、篇章级连接词测试集及省略测试集。
[0047]
优选地,从候选数据集中筛选指代测试集的筛选方法可为:
[0048]
可设源语言数据中,单数名词词性标签为nn,复数名词词性标签为nns,专有词性标签为nr;
[0049]
第一筛选参数可为:源语言数据中的某一句中包含有两义代词;该句的前一句包含有词性标签为nn、nns和nr的名词词性的单词,该句对应的目标语言数据中包含“他们”,“她们”,“它们”,“你”,“你们”或物主形式;
[0050]
第二筛选参数可为:该句的前一句中包含单复数或男女性别的信息;
[0051]
可先筛选出符合第一筛选参数的源语言数据及其对应的目标语言数据;对符合第一筛选参数条件的数据再采用第二筛选参数进行筛选,将同时满足第一筛选参数及第二筛选参数的源语言数据及其对应的目标语言数据,集合制成指代测试集。
[0052]
优选地,从候选数据集中筛选篇章级连接词测试集的筛选方法可为:
[0053]
可设源语言数据中,并列连接词词性标签为cc,前/后置连词词性标签为in,特殊疑问词词性标签为wrb;
[0054]
第三筛选参数可为:源语言数据中的某一句中包含有多义连词;并且该多义连词的词性标签满足cc、in、wrb中的一种;
[0055]
可先筛选出符合第三筛选参数的源语言数据及其对应的目标语言数据,再检查筛选出的目标语言数据中是否存在对应的连词翻译,如果有对应的连词翻译,则该句源语言数据及其对应的目标语言数据符合筛选条件;
[0056]
如果没有,则继续检查目标语言数据的前一句是否包含连接词消除歧义所用的信息;如果有,则该句源语言数据及其对应的目标语言数据符合筛选条件;否则不符合;
[0057]
可对应每个连接词的每种含义,从候选数据集中,对应筛选出相同数量的符合上述筛选参数条件的数据,集合制成指代测试集。
[0058]
优选地,从候选数据集中筛选篇章级连接词测试集的筛选方法可为:
[0059]
可设源语言数据中,系动词词性标签为vc,动词词性标签为vb,动词过去式为vbd;
[0060]
第四筛选参数可为:源语言数据中的某一句中包含有至少一个助动词;并且该助动词的词性满足vc、vb、vbd中的一个;
[0061]
可先筛选出符合第四筛选参数的源语言数据及其对应的目标语言数据;再对筛选出的数据中包含助动词的源语言句子及其所对应的中文翻译文本进行检查,确认对应该句
的动词翻译与前一句中的动词翻译是否一致,将前后句动词翻译一致的源语言数据及其对应的目标语言数据,集合制成省略测试集。
[0062]
可采用现有技术中的软件及算法对获取的中英文文本数据进行初步过滤处理,优选地,可使用python系统中的匹配算法对获取的中英文文本数据进行初步过滤处理。
[0063]
可采用现有技术中的软件及算法对源语言数据进行分词处理,优选地,源语言数据可采用moses工具进行分词处理。
[0064]
可采用现有技术中的软件及算法对目标语言数据进行分词处理,优选地,目标语言数据可采用结巴分词工具进行分词处理。
[0065]
可采用现有技术中的软件及算法对源语言数据进行词性标注,优选地,对源语言数据进行词性标注的方法可为:
[0066]
采用python系统,先从stanfordcorenlp工具中导入stanfordcorenlp文件包,然后使用stanfordcorenlp工具生成原始的词性标注文件,之后根据不同的语言现象再在该标注文件中进行筛选。
[0067]
下面以本发明的一个优选实施例来进一步说明本发明的工作原理:
[0068]
本发明提出的一种用于篇章级英译中机器翻译测试集的构建方法,主要针对英译中翻译方向上容易出现翻译错误的三种语言现象而设计,分别是指代、篇章级连接词和省略现象,通过该方法构建的测试集可以测试不同的模型在这三种篇章级语言现象上的翻译能力,为篇章级机器翻译模型的评测提供新的角度。
[0069]
该方法可包括如下步骤:
[0070]
步骤一,相应语料的处理。
[0071]
因为公开的篇章级机器翻译数据较少,而从数据中寻找符合要求的测试用例需要大量的数据,本测试集构建时,选取公开的电影字幕数据集opensubtitles作为测试数据的来源。此数据集源自网络资源,数量较多,英译中方向上共有约1100万句,句子级对齐,但有部分未对齐现象。
[0072]
本发明中使用python系统对数据进行过滤处理。如果待选取测试用例的语料未经过处理,可能会包含一些除英文中文外的其他语言字符。首先,我们通过python中的匹配函数re.compile()的方式将其他语言字符过滤掉,仅留下包含英文和中文的相关文本,即匹配英文时为re.compile(
‘
[a-za-z]+’),匹配中文时为re.compile(ur
‘
[\u4e00-\u9fa5]+’)。因为本发明提出的测试集构建方法是针对于篇章级机器翻译,所以测试集中的测试用例需要体现出句间的语言现象,在本方法中除考虑当前句之外,还考虑其相邻的前一句上文,在过滤掉其他字符之后,将文本切分成相邻两句为一组句子对的形式,使用open语句将待处理的数据文件打开,再采用readlines()方法逐行读取文件中的语句,使用for循环语句遍历数据文件中的所有行,并依次将当前句和其前一句通过write()写入新的生成文件,之后选取测试用例的操作将在生成的句子对文件中进行。
[0073]
在处理原始语料时通过python中的re.compile()匹配英文和中文,以起到过滤其他语言字符的目的。然后通过python中readlines()逐行读入数据文件,并通过循环语句遍历所有行,并将前一句和当前句作为一组句子对写入新文件,形成初步处理后的文本,之后的测试集将在此数据的基础上进行挑选。
[0074]
re.compile()、readlines()、write()等为python系统的函数。
[0075]
步骤二,在设定测试集的挑选参数时,需要结合英译中的实际情况,本发明中选取篇章级英译中机器翻译里具有代表性的三种语言现象:指代、篇章级连接词和省略来构建相应的测试集。
[0076]
对于指代现象的测试集来说,本发明中的方法主要关注于相邻两句中人称代词翻译的一致性,考虑人称代词“you”和“they”等代词的英译中翻译结果。在英文中的“you”翻译成中文时可以根据上下文的不同翻译成“你”或“你们”,单数或复数形式取决于上下文的环境。英文中的“they”也有类似的情况,可以根据语境翻译成“她们”、“它们”或“他们”,需要有上下文的语境来决定具体翻译成哪种。寻找测试用例时,在源语言数据的当前句中需要出现这两种人称代词(或它们的宾格形式或物主代词形式)中的一种,而前一句给出决定单复数或性别的信息,如人名、名词等。在目标语言数据(汉语)当前句的翻译中应出现单复或性别正确的代词翻译。
[0077]
指代测试集中的测试用例,主要评测机器翻译模型对代词“you”和“they”的翻译能力,“you”翻译成中文时可以有两种含义,根据上下文语境可以翻译成单数形式的“你”或复数形式的“你们”,而“they”翻译时可以根据上下文翻译成不同的性别,男性复数形式“他们”、女性复数形式“她们”和一般非人类的第三人称复数“它们”。
[0078]
对于篇章级连接词的测试集,本发明可根据pdtb风格的英文篇章关系标注规范中提及的具有多种含义的英文篇章级连接词,从中选取五个篇章级连接词,它们分别是“while”、“as”、“since”、“though”和“or”,并且考虑它们出现最多的两种含义,分别是:“while”表示转折“而”和表示同时“当”,“as”表示原因“因为”和表示同时“当”,“since”表示原因“因为”和表示让步“既然”,“though”表示转折“虽然”和表示转折“但是”以及“or”表示转折“否则”和表示选择“或者”,对机器翻译模型在篇章级连接词的翻译能力进行测评。具体操作时,对于测试用例的要求是源语言数据中的当前句里包含所选取的五个篇章级连接词中的一个,在目标语言数据中的当前句根据上下文翻译成相应的两种含义中的一种。
[0079]
在挑选测试用例时,本测试集可仅考虑“while”、“as”、“since”、“though”和“or”这五个连接词各自常用的两种含义。
[0080]
在英文中动词省略是一种常见的现象,在相邻的两句话中,在第二句与前一句中的动词相同的情况下,经常在第二句中用助动词替代重复出现的动词。省略测试集的测试用例仅考虑英文中的动词省略现象,源语言数据中当前句和前一句的动词相同时,通常会使用助动词进行省略,而在中文里,通常会使用重复的动词,这就要求在对源语言数据进行筛选时,需要保证前一句中包含动词,而当前句中有相应的助动词、系动词、情态动词等,而目标语言数据中需要前一句和当前句含有相同的动词。
[0081]
在寻找测试用例时,具体是指源语言数据当前句中动词与前一句相同时,当前句的动词用助动词来代替,即当前句中出现“do”,“does”,“can”,“could”,“should”,“is”,“are”,“am”,“may”以及相应的否定形式,而在目标语言数据当前句中则需要翻译出其省略的前一句中的动词的含义。
[0082]
步骤三,在构建测试集的具体过程中,先使用分词工具moses和结巴分词分别对英文和中文进行分词,然后使用stanfordcorenlp词性标注工具对分词结果进行标注生成原始的标注文件,之后根据不同的测试集的具体要求,从标注文件里筛选相应的单词和词性,构成测试集。
[0083]
为提高选取测试用例的效率和准确性,需要在匹配相应单词前对数据文件进行分词及词性标注,本发明里英文分词工具使用moses,中文分词工具使用结巴分词,使用的词性标注工具为开源工具stanfordcorenlp,在使用该工具时,需要在python文件中先从stanfordcorenlp工具中导入stanfordcorenlp文件包。使用stanfordcorenlp工具生成原始的词性标注文件,之后根据不同的语言现象再在该标注文件中进行筛选。
[0084]
对于指代测试集,在原始的词性标注文件中进行筛选,条件为源语言数据中的前一句需要有“nn”,“nns”和“nr”等名词词性的单词,当前句中需要有“they”、“their”、“them”、“you”、“your”等代词,源语言数据中的某一句中包含有两义代词;该句的前一句包含有词性标签为nn、nns和nr的名词词性的单词,该句对应的目标语言数据中包含“他们”,“她们”,“它们”,“你”,“你们”或物主形式。
[0085]
如果所有条件均符合,则继续检查决定翻译单复数或性别的因素是否在前一句中,最后再从符合所有要求的句子对中挑选出一定数量的测试用例组成指代测试集。
[0086]
从所有符合条件的句子对中,每个代词的含义选取80个测试用例。例1显示了指代测试集中的一个测试用例,由于前一句中出现了复数名词“guys”,所以代词“you”表示了复数含义,在中文里应翻译为代词的复数形式“你们”。
[0087]
例1:
[0088]
源语言数据:
[0089]
前一句:you rich guys think that money can buy anything.
[0090]
当前句:how right you are.
[0091]
目标语言数据:
[0092]
前一句:你们富人总以为钱能买到一切。
[0093]
当前句:你们想的太对了。
[0094]
篇章级连接词测试集,需要源语言数据中的当前句中包含“as”、“or”、“while”,“since”、“though”等五个篇章级连接词中的一个,并且该连接词的词性需要满足“cc”、“in”、“wrb”中的一个,由于中文篇章级连接词表达较为多样,我们采用先自动筛选包含相应含义的句子对,然后再采取人工检查满足源语言数据中各项条件但目标语言数据中未含有相应连接词的句子对,然后检查连接词消除歧义所用到的信息是否在前一句中,最后每个连接词的每种含义选取相同数量的测试用例,组成篇章级连接词测试集。
[0095]
每个连接词的每种含义可选取40个测试用例。例2展示的是篇章级连接词测试集中的一个测试用例,该测试用例包含篇章级连接词“while”,其在上下文语境中的含义为“而”表示转折。
[0096]
例2:
[0097]
源语言数据:
[0098]
前一句:everything is so difficult in life,for me.
[0099]
当前句:while for others it’s all child’s play.
[0100]
目标语言数据:
[0101]
前一句:对于我,生活一切都很艰难。
[0102]
当前句:对于别人却都像儿戏一样。
[0103]
省略测试集先通过字符匹配将源语言数据当前句中包含助动词的句子对过滤出
来,即包含“do”、“does”、“can”、“could”、“should”、“is”、“am”、“are”、“may”的句子对,然后需要源语言数据的前一句中包含动词,即词性为“vc”、“ve”、“vv”,再检查目标语言数据中的当前句中的动词和前一句中动词的一致性,最后选取一定数量的测试用例组成省略测试集。
[0104]
然后检查源语言数据的前一句中包含的动词,即词性标注为“vc”、“ve”、“vv”,再检查目标语言数据中的当前句中的动词和前一句中动词的一致性。例3中是省略测试集中的一个测试用例,源语言数据的当前句省略了前一句中的“know”,而目标语言数据中的当前句将其按照前一句中的动词正确翻译为“知道”。
[0105]
例3:
[0106]
源语言数据:
[0107]
前一句:you see,she doesn’t know.
[0108]
当前句:neither do i.
[0109]
目标语言数据:
[0110]
前一句:看,她不知道。
[0111]
当前句:我也不知道。
[0112]
步骤四,将挑选出来的测试用例进行人工检查,纠正翻译错误。
[0113]
表1:bleu自动评分结果
[0114] 代词篇章级连接词省略thumt12.49.818.2cadec19.115.325.5bert-nmt13.912.719.1
[0115]
从表1可以看出:从bleu(双语评估替补)值的角度来看,cadec(结合上下文解码器)模型在三种语言现象上的bleu值最高,表示该模型在三种篇章级语言现象上的翻译效果最好,bert-nmt(融合bert的神经机器翻译)融合bert的神经机器翻译)模型的bleu值排名第二,而thumt(清华大学机器翻译)模型的bleu值最低,说明该模型在三种语言现象上翻译效果最差。
[0116]
表2、人工评测结果:
[0117]
[0118][0119]
表2中的数据含义为正确率(单位为%),正确率越高说明翻译效果越好,从表2中可以看出:一共有13个统计指标,其中有9个指标cadec模型的正确率最高,说明该模型在这9个指标上翻译结果最好。thumt模型在三个指标上正确率最高,而bert-nmt模型在“它们”一词的翻译上正确率最高。整体上来看,cadec模型的翻译效果最好,这与bleu值的结果一致。
[0120]
以上所述的实施例仅用于说明本发明的技术思想及特点,其目的在于使本领域内的技术人员能够理解本发明的内容并据以实施,不能仅以本实施例来限定本发明的专利范围,即凡本发明所揭示的精神所作的同等变化或修饰,仍落在本发明的专利范围内。
相关技术
网友询问留言
已有0条留言
- 还没有人留言评论。精彩留言会获得点赞!
1