基于约束非负矩阵分解的多视图聚类方法与流程
[0001]
本发明涉及时间序列的数据挖掘技术领域,特别是涉及基于约束非负矩阵分解的多视图聚类方法。
背景技术:
[0002]
多元时序数据是一种在日常生活中广泛应用的数据,但是,针对多元时序数据的聚类问题,现有算法往往从单一视图进行处理,忽视了多元时序数据中隐含的多视图信息。多视图聚类能够挖掘出不同视图中存在的一致性和互补性信息,提升聚类效果,因此成为了当前的研究热点,对此,国内外学者已经提出了很多种算法。
[0003]
基于图的多视图聚类用统一的图矩阵表示数据样本之间的相似度关系,在此图矩阵的基础上进行聚类得到结果。zhan等人通过最小化不同视图间的不一致性学习得到一个一致性图。li和he采用锚点图挖掘不同视图间的一致性信息。针对基于图的聚类中需要额外的聚类步骤来产生最终结果的问题,wang等学者提出了一种可以学习统一的图矩阵的方法,直接获得最终的聚类结果。文献:k.zhan,f.nie,j.wang and y.yang,“multiview consensus graph clustering,”ieee trans.image process.,vol.28,no.3,pp.1261-1270,mar.2019;l.li and h.he,“bipartite graph based multi-view clustering,”ieee trans.knowl.data eng.,2020;h.wang,y.yang and b.liu,“gmc:graph-based multi-view clustering,”ieee trans.knowl.data eng.,vol.32,no.6,pp.1116-1129,jun.2020.
[0004]
基于矩阵分解的多视图聚类通过矩阵分解办法整合多视图信息。luong和nayak结合耦合矩阵分解和非负矩阵分解方法同时学习多视图数据中的一致性和互补性信息。非负矩阵分解可以有效地将高维数据投影至低维空间,能够处理广泛的数据分布。为了提高非负矩阵分解在聚类问题上的效果,liang等学者提出了一种带有正交约束的非负矩阵分解模型,能够有效提取不同视图中的多样性信息。文献:k.luong and r.nayak,“a novel approach to learning consensus and complementary information for multi-view data clustering,”in proc.ieee int.conf.data eng.(icde),dallas,tx,usa,2020,pp.865-876;liang,n.,yang,z.,li,z.,sun,w.and xie,s.,“multi-view clustering by non-negative matrix factorization with co-orthogonal constraints,”knowl.based syst.,vol.194,apr.2020.
[0005]
基于子空间的多视图聚类假设所有视图共享一个具有视图间一致性信息的潜在子空间。挖掘不同视图中的高阶信息是该类算法的关键。zhu等学者利用结构一致性和多样性正则化来学习视图的一般和特殊表示。kang等人采用分阶段整合多视图信息的方法来获取隐含的聚类结构。文献:w.zhu,j.lu and j.zhou,“structured general and specific multi-view subspace clustering,”pattern recognit.,vol.93,pp.392-403,september 2019;z.kang,x.zhao,c.peng,et al.“partition level multiview subspace clustering,”neural netw.,vol.122,pp:279-288,,feb.2020.
[0006]
上述研究主要针对多视图聚类问题展开研究,然而,现有研究在多元时序数据上的表现欠佳。时序数据在医学、工商业和军事等领域有着广泛的应用,并且多元时序数据往往具有较高的维度和复杂的数据结构,因此,对于多元时间序列的聚类具有很高的实际意义和价值。
技术实现要素:
[0007]
为了克服上述现有技术的不足,本发明提供了一种基于约束非负矩阵分解的多视图聚类方法。
[0008]
步骤1,对多元时间序列数据,计算多重关系网络;
[0009]
步骤2,基于步骤1中计算得到的多重关系网络,采用层次方法,通过计算变量子空间之间的不相关度,进行子空间合并,生成多个独立视图;
[0010]
步骤3,基于步骤2中所得的多视图数据,采用约束非负矩阵分解进行聚类;
[0011]
步骤4,采用交替迭代优化的方法进行聚类求解,基于求解的结果进而得到表示矩阵,对表示矩阵进行k均值聚类得到聚类结果。
[0012]
而且,步骤1中,多元时序数据的多重关系网络的计算为,对于多元时序数据x中的各样本,计算样本中的各单元时间序列的均值和方差,基于均值和方差进行样本的零均值标准化,表示如下:
[0013][0014]
其中,表示x中第i个多元时序样本的第r个变量下的单元时间序列,表示时间序列上按照时间排列的数据均值,表示时间序列上按照时间排列的数据标准差;
[0015]
在每个变量下,计算多元时序数据x中的任意一对样本之间的基于动态时间规划的距离,基于样本之间的距离,计算样本在整个数据集上的p近邻,得到多元时序数据在各个变量下的邻接矩阵,构成多重关系网络a;对于变量r构造的邻接矩阵如下:
[0016][0017]
其中,a
r
表示变量r下的多重关系网络,表示的p近邻。
[0018]
而且,步骤2中,独立视图的层次生成方法的计算为,每个变量视为一个子空间,基于子空间之间的不相关度,将不相关度最小的子空间对不断合并,直至获得v个包含多个变量的独立子空间,视为v个独立视图;两个子空间l
i
和l
j
之间的不相关度计算为:
[0019]
indep(l
i
,l
j
)=i(l
i
,l
j
)-i(l
i
)-i(l
j
)
[0020][0021][0022]
其中,indep(l
i
,l
j
)表示子空间l
i
和l
j
之间的不相关度,i(l
i
,l
j
)表示l
i
和l
j
的变量
之间的不相关系数,a
m
和a
u
分别表示变量m和变量u下的多重关系网络,表示弗罗贝尼乌斯范数。
[0023]
而且,步骤2中,步骤3中,约束非负矩阵分解的计算为,基于多视图非负矩阵分解,将多重关系网络a分解为软分配矩阵p和基矩阵q;将软分配矩阵p表达为一致矩阵c与特殊矩阵d的和,从而将多重关系网络a分解为一致矩阵c,特殊矩阵d和基矩阵q;引入矩阵正则化,对一致矩阵c,特殊矩阵d和基矩阵q,分别计算弗罗贝尼乌斯范数并求和,并用权衡参数λ1进行矩阵正则化的权衡;引入图正则化,对于多重关系网络a,计算其在各视图下的拉普拉斯矩阵,基于拉普拉斯矩阵,一致矩阵c和特殊矩阵d,计算图正则化,并用权衡参数λ2进行图正则化的权衡,具体为:
[0024]
多视图非负矩阵分解中,多重关系网络a分解为软分配矩阵p和基矩阵q的表示如下:
[0025][0026]
其中,表示第v个视图下第i个变量的关系网络,表示第v个视图中第i个变量的基矩阵;
[0027]
同时考虑视图间的一致信息各个视图的特殊信息,将软分配矩阵p表达为一致矩阵与特殊矩阵的和,则该矩阵分解表示如下:
[0028][0029]
其中,c表示所有视图共享的一致矩阵,d
(v)
表示第v个视图下的特殊矩阵;
[0030]
非负矩阵分解的目标是使构造误差最小化,因此目标函数为:
[0031][0032]
s.t.c≥0,d≥0,q≥0
[0033]
其中,φ表示目标函数,d
v
表示第v个视图中包含的变量数目;
[0034]
同时,为避免过拟合问题,引入矩阵正则化,表示如下:
[0035][0036]
其中,ψ
m
表示矩阵正则化
[0037]
考虑数据自身的空间结构,引入图正则化,表示如下:
[0038][0039]
l
(v)
=u
(v)-m
(v)
[0040]
其中,ψ
g
表示图正则化,tr(
·
)表示矩阵的秩,l
(v)
表示第v个视图的拉普拉斯矩阵,u
(v)
是对角矩阵,对角元素计算为:
[0041][0042]
m
(v)
是边的权重矩阵,采取基于动态时间规划距离的高斯核函数定义权重,计算为:
[0043][0044][0045]
其中,表示第v个视图下的第i个多元时序数据样本,表示的p近邻,表示边的权重,表示两个单元时间序列和之间基于动态时间规划的距离,σ表示高斯核函数的参数;
[0046]
引入矩阵正则化和图正则化后的目标函数为:
[0047][0048]
s.t.c>0,d>0,q>0
[0049]
其中,λ1表示矩阵正则化权衡参数,λ2表示图正则化权衡参数。
[0050]
而且,步骤4中,交替迭代优化的计算为,基于约束非负矩阵分解,首先固定一致矩阵c与特殊矩阵d,更新基矩阵q;其次,固定一致矩阵c和基矩阵q,更新特殊矩阵d;最后,固定特殊矩阵d和基矩阵q,更新一致矩阵c;
[0051]
当c和d固定时,q的更新的计算为:
[0052][0053]
其中,表示第v个视图中的第i个变量下的基矩阵,为该矩阵的第n行第k个元素;
[0054]
当c和q固定时,d的更新的计算为:
[0055][0056]
当d和q固定时,c的更新的计算为:
[0057]
[0058]
迭代更新求解得到矩阵c和d后,数据集的表示矩阵s的计算为:
[0059][0060]
然后对s进行k均值聚类获得聚类结果。
[0061]
本发明针对多元时间序列的聚类问题,提出了一种基于多视图的算法,通过基于约束非负矩阵分解方法进行聚类,能够有效提高多元时序数据聚类的准确性。与现有技术相比,本发明的有益效果为:
[0062]
(1)采用多视图方法对多元时序数据进行处理,提出一种从多元时序数据生成多视图数据的方法。
[0063]
(2)提出一种约束非负矩阵分解方法,同时考虑多个视图间数据的一致性信息和各视图下的特殊性信息。
附图说明
[0064]
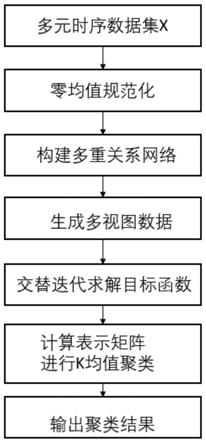
图1为本发明实例针对多元时序数据的多视图聚类的方法流程图;
[0065]
图2为采用单视图聚类和多视图聚类策略对auslan数据集进行聚类后的聚类结果的准确度;
[0066]
图3为不采用矩阵正则化和图正则化,只采用矩阵正则化,只采用图正则化,以及同时采用矩阵正则化和图正则化时对auslan数据集进行聚类后得到的聚类结果的准确度;
[0067]
图4为在矩阵正则化的权衡参数和图正则化的权衡参数的不同设定值下对auslan数据集进行聚类后的聚类结果的准确度;
[0068]
图5为对多重关系网络设置不同近邻数目时对auslan数据集进行聚类后的聚类结果的准确度;
[0069]
图6为设置不同的多视图生成数量时对auslan数据集进行聚类后的聚类结果的准确度。
具体实施方式
[0070]
以下结合附图和实施例详细说明本发明技术方案。
[0071]
本发明针对高维多元时间序列的聚类问题,提出了一种基于约束非负矩阵分解的多视图聚类方法,同时考虑不同视图间的一致性和各个视图的特殊性信息,实现对多元时序数据高准确性的聚类。
[0072]
本发明实施例以auslan数据集为具体实例,auslan数据含95个类别,每个数据包括22个变量,即每个数据包括3个变量的时间序列,每个数据中的时间序列长为45至316不等,共包含1140个数据。多重关系网络的近邻数目为7,生成的多视图数目为2,矩阵正则化权衡参数和图正则化权衡参数设置为最优值。为降低对k均值聚类初始化的敏感性,进行二十次试验取最优结果。
[0073]
图1为本发明实例针对多元时序数据的多视图聚类的方法流程图;
[0074]
图2为采用单视图聚类和多视图聚类策略对auslan数据集进行聚类后的聚类结果的准确度;
[0075]
图3为不采用矩阵正则化和图正则化,只采用矩阵正则化,只采用图正则化,以及同时采用矩阵正则化和图正则化时对auslan数据集进行聚类后得到的聚类结果的准确度;
[0076]
图4为在矩阵正则化的权衡参数和图正则化的权衡参数的不同设定值下对auslan数据集进行聚类后的聚类结果的准确度;
[0077]
图5为对多重关系网络设置不同近邻数目时对auslan数据集进行聚类后的聚类结果的准确度;
[0078]
图6为设置不同的多视图生成数量时对auslan数据集进行聚类后的聚类结果的准确度。
[0079]
如图1所示,基于以上数据集,实施例通过以下步骤对数据集实施多视图聚类算法:
[0080]
步骤1,对多元时间序列数据,计算多重关系网络;
[0081]
实施例针对多重关系网络进行计算。多重关系网络的计算为,对于多元时序数据x中的各样本,计算样本中的各单元时间序列的均值和方差,基于均值和方差进行样本的零均值标准化,表示如下:
[0082]
其中,表示x中第i个多元时序样本的第r个变量下的单元时间序列,表示时间序列上按照时间排列的数据均值,表示时间序列上按照时间排列的数据标准差。
[0083][0084]
在每个变量下,计算多元时序数据x中的任意一对样本之间的基于动态时间规划的距离,基于样本之间的距离,计算样本在整个数据集上的p近邻,得到多元时序数据在各个变量下的邻接矩阵,构成多重关系网络a。对于变量r构造的邻接矩阵如下:
[0085][0086]
其中,a
r
表示变量r下的多重关系网络,表示的p近邻。
[0087]
通过上述过程,已经对auslan数据集求得多重关系网络a。
[0088]
步骤2,基于步骤1中计算得到的多重关系网络,采用层次方法,通过计算变量子空间之间的不相关度,进行子空间合并,生成多个独立视图;
[0089]
实施例对于多元时序数据中的每个变量视为一个子空间,基于子空间之间的不相关度,将不相关度最小的子空间对不断合并,直至获得v个包含多个变量的独立子空间,视为v个独立视图。两个子空间l
i
和l
j
之间的不相关度计算为:
[0090]
indep(l
i
,l
j
)=i(l
i
,l
j
)-i(l
i
)-i(l
j
)
[0091][0092][0093]
其中,indep(l
i
,l
j
)表示子空间l
i
和l
j
之间的不相关度,i(l
i
,l
j
)表示l
i
和l
j
的变量
之间的不相关系数,a
m
和a
u
分别表示变量m和变量u下的多重关系网络,表示弗罗贝尼乌斯范数。
[0094]
计算两两子空间对之间的不相关度,将不相关度最小的子空间对进行合并。此过程不断迭代,直至得到v个独立子空间,每个子空间中包含多个变量,子空间内部变量具有较小不相关度,子空间之间变量具有较大不相关度。获得的v个子空间可视为v个视图。
[0095]
通过上述过程,已经对auslan数据集生成多视图数据。
[0096]
步骤3,基于步骤2中所得的多视图数据,采用约束非负矩阵分解进行聚类。
[0097]
经过以上步骤,已经得到多视图数据,接下来采用约束非负矩阵分解对该多视图数据进行聚类。基于多视图非负矩阵分解,将多重关系网络a分解为软分配矩阵p和基矩阵q;将软分配矩阵p表达为一致矩阵c与特殊矩阵d的和,从而将多重关系网络a分解为一致矩阵c,特殊矩阵d和基矩阵q。多视图非负矩阵分解中,多重关系网络a分解为软分配矩阵p和基矩阵q的表示如下:
[0098][0099]
其中,表示第v个视图下第i个变量的关系网络,表示第v个视图中第i个变量的基矩阵。
[0100]
同时考虑视图间的一致信息各个视图的特殊信息,将软分配矩阵p表达为一致矩阵与特殊矩阵的和,则该矩阵分解表示如下:
[0101][0102]
其中,c表示所有视图共享的一致矩阵,d
(v)
表示第v个视图下的特殊矩阵。
[0103]
非负矩阵分解的目标是使构造误差最小化,因此目标函数为:
[0104][0105]
s.t.c≥0,d≥0,q≥0
[0106]
其中,φ表示目标函数,d
v
表示第v个视图中包含的变量数目。
[0107]
同时,为避免过拟合问题,引入矩阵正则化,表示如下:
[0108][0109]
其中,ψ
m
表示矩阵正则化
[0110]
考虑数据自身的空间结构,引入图正则化,表示如下:
[0111][0112]
l
(v)
=u
(v)-m
(v)
[0113]
其中,ψ
g
表示图正则化,tr(
·
)表示矩阵的秩,l
(v)
表示第v个视图的拉普拉斯矩阵,u
(v)
是对角矩阵,对角元素计算为:
[0114][0115]
m
(v)
是边的权重矩阵,采取基于动态时间规划距离的高斯核函数定义权重,计算为:
[0116][0117][0118]
其中,表示第v个视图下的第i个多元时序数据样本,表示的p近邻,表示边的权重,表示两个单元时间序列和之间基于动态时间规划的距离,σ表示高斯核函数的参数。
[0119]
引入矩阵正则化和图正则化后的目标函数为:
[0120][0121]
s.t.c>0,d>0,q>0
[0122]
其中,λ1表示矩阵正则化权衡参数,λ2表示图正则化权衡参数。
[0123]
步骤4,采用交替迭代优化的方法进行聚类求解,基于求解的结果进而得到表示矩阵,对表示矩阵进行k均值聚类得到聚类结果。
[0124]
目标函数的求解目标是获得一致矩阵c,特殊矩阵d和基矩阵q,使得目标函数最小化。交替迭代优化的计算为,基于约束非负矩阵分解,首先固定一致矩阵c与特殊矩阵d,更新基矩阵q;其次,固定一致矩阵c和基矩阵q,更新特殊矩阵d;最后,固定特殊矩阵d和基矩阵q,更新一致矩阵c。当c和d固定时,q的更新的计算为:
[0125][0126]
其中,表示第v个视图中的第i个变量下的基矩阵,为该矩阵的第n行第k个元素;
[0127]
当c和q固定时,d的更新的计算为:
[0128][0129]
当d和q固定时,c的更新的计算为:
[0130][0131]
迭代更新求解得到矩阵c和d后,数据集的表示矩阵s的计算为:
[0132][0133]
然后对s进行k均值聚类获得聚类结果。
[0134]
具体实施时,本发明技术人员可以自行设计相应运行流程。为便于实施参考起见,提供建议建立规则的伪代码:
[0135]
algorithm1:multi-view clustering based on non-negative matrix factorization with constraints input:a mts dataset x,matrix regularization parameterλ1,graph regularization parameterλ2,number of nearest neighbors p
[0136]
output:the cluster label set of x.
[0137][0138]
在多视图聚类过程中,各符号说明:algorithm 1表示本发明的算法1,multi-view clustering based on non-negative matrix factorization with constraints为算法1的名称,即基于约束非负矩阵分解的多视图聚类,input、output分别表示算法1的输入、输出,x表示多元时间序列数据集,λ1表示矩阵正则化权衡参数,λ2表示图正则化权衡参数,p表示步骤1中生成多重关系网络的近邻数目,a表示步骤1中得到的多重关系网络,v表示步骤2中生成的多视图的数目,(l1,...,l
v
)表示步骤2中生成的多个视图,c表示一致矩阵,d
(v)
表示第v个视图下的特殊矩阵,表示第v个视图下的第i个变量的基矩阵,s表示表示矩阵。
[0139]
算法流程:首先对多元时序数据x进行零均值标准化,并通过步骤1中的算法构造
多重关系网络a,见行1;再通过步骤2中的多视图生成算法产生多个独立视图,见行2;接下来,进行一致矩阵c,特殊矩阵d和基矩阵q的初始化,见行3;在达到收敛之前,迭代进行如下过程:对于各视图下的各变量,更新基矩阵q,见行7;然后对各个视图,更新特殊矩阵d,见行8;,最后更新一致矩阵c,见行9;迭代完成后,根据c和d计算表示矩阵s,见行11;最后采用k均值算法对s进行聚类得到聚类结果,见行12。
[0140]
综上所述,本发明提出了一种基于约束非负矩阵分解的多视图聚类算法,为了有效的进行样本聚类,首先将多元时序数据投影至一个多重关系网络,然后采用层次方法生成多个独立视图。其次,采用约束非负矩阵分解方法,对生成的多个视图进行聚类。最后,采用交替迭代优化的方式进行求解,对求解结果获得的表示矩阵进行k均值聚类得到聚类结果。
[0141]
本文中所描述的具体实施例仅仅是对本发明精神作举例说明。本发明所属技术领域的技术人员可以对所描述的具体实施例做各种各样的修改或补充或采用类似的方式替代,但并不会偏离本发明的精神或者超越所附权利要求书所定义的范围。
相关技术
网友询问留言
已有0条留言
- 还没有人留言评论。精彩留言会获得点赞!
1