一种针对直播过程中诱导性不良行为的检测系统及方法与流程
[0001]
本发明涉及计算机视觉识别技术与卷积神经网络领域,特别是一种针对直播过程中诱导性不良行为的检测系统及方法,用于检测直播过程连续动作序列中是否混杂诱导性不良行为。
背景技术:
[0002]
随着信息技术的发展和智能硬件的普及,尤其是移动智能终端设备的大众化,智能手机和个人掌上电脑已逐渐成为人们在选择办公设备和娱乐设备时的最佳选择。线上直播平台将传统的线下曲艺社、茶馆、脱口秀剧场相整合,入驻网络直播平台的直播主播可以通过直播平台实时展示才艺,通过直播观众的礼物赠送获取相应的收入。据已公开资料显示,中国网络直播用户规模已达4.33亿,占整体网民的50.7%,仅2018年,头部直播平台的新增主播人数高达200多万。直播行业现已形成一条软、硬件结合的完善产业链,人社部也于2020年7月将“直播销售员”划定为拟新增的工种之一。网络主播的数量剧增和直播平台的迅猛发展带来的是直播场次的增加和平台直播总时长的暴涨。
[0003]
网络主播或为在直播间吸引更多观看流量,或受自身行为习惯的影响,可能会在直播间做出一些具有诱导性的不良行为,比如:吸烟、自残、虐杀动物等,若青少年观众对此类行为模仿,会严重损害青少年观众的身心健康。这些动作混杂在常规连续动作序列中,存在着持续时长短,难被发现的问题。面对良莠不齐的直播内容,传统的小型直播平台通过直播平台管理员的不定时巡查机制和直播观众的举报机制,来实现对于主播诱导性不良行为的识别与审查。
[0004]
然而,面对直播场次和直播时长的迅速增长,传统的诱导性不良行为识别方法对直播平台巡查管理员的需求量依赖较大,加剧了直播平台的运营负担。同时,传统的人工审核机制,对部分细节识别能力较弱,对违规行为的识别准确率较低。从违规视频的识别效率上看,在对视频中诱导性不良行为的识别过程中,识别者需要观看整段视频,对于部分判定不清的视频片段需要反复观看进行判定,极易产生效率低的问题。此外,针对人工识别出的违规视频内容,为防止人工误判,平台为主播提供违规申诉功能,故此可能存在主播与管理员沆瀣一气、逃避处罚等情况。
[0005]
因此,亟需一种识别准确率高的方法来检测直播过程中是否存在诱导性不良行为。
技术实现要素:
[0006]
本发明的目的是要解决现有检测方法识别速度慢、准确率低的问题,提供一种针对直播过程中诱导性不良行为的检测系统及方法。
[0007]
为达到上述目的,本发明是按照以下技术方案实施的:
[0008]
一种针对直播过程中诱导性不良行为的检测系统,包括:
[0009]
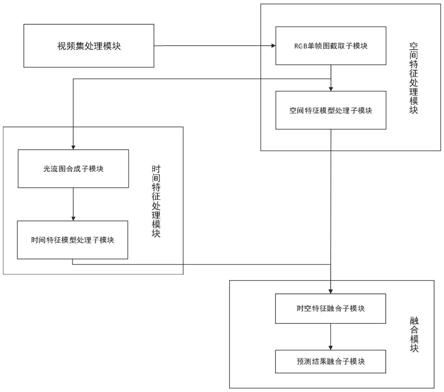
视频集处理模块,其输出端与空间特征处理模块的输入端相连接,所述视频集处
理模块用于处理视频集内容,包括获取存储在直播平台数据库内的违规诱导性不良行为视频案例,抓取实时直播内容保存为待识别视频;对于已确认为诱导性不良行为的视频案例进行分割,按照违规类型标签对每一分段视频做标注;将待识别长时长视频,按照等长度方法划分为多段短时长视频,对于划分好的短时长视频按统一格式命名,保证多个分段视频的连续性和易读性;
[0010]
空间特征处理模块,其输出端分别与时间特征处理模块和融合模块的输入端相连接,所述空间特征处理模块用于对已经处理好的短时长视频进行视频单帧截取rgb单帧图,并从截取到的rgb单帧图中提取空间特征,然后输入到针对空间特征的诱导性不良行为识别模型中,输出预测结果;
[0011]
时间特征处理模块,其输出端与融合模块的输入端相连接,所述时间特征处理模块用于截取得到的时序相邻的两帧rgb单帧图间计算,通过计算得到瞬时光流信息,合成光流图;并从合成得到的光流图中提取时间特征,然后输入到针对时间特征的诱导性不良行为识别模型中,输出预测结果;
[0012]
融合模块,用于将得到的针对空间特征的诱导性不良行为识别模型预测结果与针对时间特征的诱导性不良行为识别模型预测结果相融合,得到融合了空间特征与时间特征的数据,融合数据经过分类处理得到该分段视频的预测结果。在对所有分段视频完成预测后,将多个分段视频的预测结果进行融合计算,得到最终预测结果,最终预测结果就是从直播服务器获取到的长时长视频识别结果。
[0013]
进一步地,所述空间特征处理模块包括:
[0014]
rgb单帧图截取子模块,rgb单帧图截取子模块的输入端与视频集处理模块的输出端相连接,rgb单帧图截取子模块的输出端分别与空间特征模型处理子模块和时间特征处理模块的输入端相连接;所述rgb单帧图截取子模块用于对已经处理好的短时长视频进行视频单帧截取rgb单帧图;
[0015]
空间特征模型处理子模块,其输出端与融合模块的输入端相连接,所述空间特征模型处理子模块用于从截取到的rgb单帧图中提取空间特征,然后输入到针对空间特征的诱导性不良行为识别模型中,输出预测结果。
[0016]
进一步地,所述时间特征处理模块包括:
[0017]
光流图合成子模块,其输入端与rgb单帧图截取子模块的输出端相连接,光流图合成子模块的输出端与时间特征模型处理子模块的输入端相连接,所述光流图合成子模块用于视频中截取得到的时序相邻的两帧rgb单帧图间计算,得到瞬时光流信息合成光流图;
[0018]
时间特征模型处理子模块,其输出端与融合模块的输入端相连接,所述时间特征模型处理子模块用于从合成得到的光流图中提取时间特征,然后输入到针对时间特征的诱导性不良行为识别模型中,输出预测结果。
[0019]
进一步地,所述融合模块包括:
[0020]
时空特征融合子模块,其输入端分别与空间特征模型处理子模块和时间特征模型处理子模块的输出端相连接,所述时空特征融合子模块用于将得到的针对空间特征的诱导性不良行为识别模型预测结果与针对时间特征的诱导性不良行为识别模型预测结果相融合,得到融合了空间特征与时间特征的数据,融合数据经过分类处理得到一个分段视频的预测结果;
[0021]
预测结果融合子模块,其输入端与时空特征融合子模块的输出端相连接,所述预测结果融合子模块用于在所有分段视频完成预测后,将多个分段视频的预测结果进行融合计算,得到最终预测结果,最终预测结果就是从直播服务器获取到的长时长视频的识别结果。
[0022]
进一步地,所述针对空间特征的诱导性不良行为识别模型和针对时间特征的诱导性不良行为识别模型的原始模型均为卷积神经网络模型resnet152。
[0023]
另外,本发明还提供了一种针对直播过程中诱导性不良行为的检测方法,利用上述针对直播过程中诱导性不良行为的检测系统对直播过程中诱导性不良行为进行检测,包括以下步骤:
[0024]
步骤1:将直播平台视频资料库内存储的违规视频案例进行提取处理,选取出目标视频分割成多段包含违规诱导性行为的短时长视频,记录违规诱导性行为的类型标签;
[0025]
步骤2:对视频进行处理,获取视频的rgb单帧图和光流图;
[0026]
步骤3:使用rgb单帧图和光流图中的时空特征分别对识别空间特征的模型和识别时间特征的模型进行训练,得到针对空间特征的诱导性不良行为识别模型与针对时间特征的诱导性不良行为识别模型;
[0027]
步骤4:获取直播视频片段,从直播平台服务器获取实时直播缓存,切割成多段时长为2秒-3秒的直播视频分段;
[0028]
步骤5:针对步骤4中切割得到一段的直播视频分段,重复进行步骤2的内容,获得直播视频片段的rgb单帧图和光流图;
[0029]
步骤6:随机选取一张步骤5中得到的rgb单帧图,放入步骤3中得到的针对空间特征的诱导性不良行为识别模型中,输出预测结果;
[0030]
步骤7:将步骤5中得到的光流图放入步骤3中得到的针对时间特征的诱导性不良行为识别模型中,输出预测结果;
[0031]
步骤8:对步骤6和步骤7中得到的数据进行数据融合,通过平均法,将两项结果进行融合,将融合后的结果输出,对融合结果进行判断,得到某一视频分段的预测结果;
[0032]
步骤9:对长时长视频分割成的多段视频分段的预测结果进行融合,若存在至少一段视频分段的预测结果为“存在不良行为”,则判定当前的待识别视频存在诱导性不良行为。
[0033]
进一步地,所述步骤2具体包括:
[0034]
步骤2.1:对视频分段进行rgb单帧图获取,对视频分段进行帧抽取,根据视频帧率特性,对视频内包含的全部rgb单帧图进行抽取;
[0035]
步骤2.2:对rgb单帧图进行光流信息处理,通过两帧相邻单帧图间计算,合成光流图;
[0036]
步骤2.3:对获得的rgb单帧图和光流图进行处理,将同类型诱导性不良行为存放在一起。
[0037]
进一步地,所述步骤3具体包括:
[0038]
步骤3.1:加载通过imagenet训练集预训练过的卷积神经网络模型resnet152;
[0039]
步骤3.2:使用经过处理的rgb单帧图和标记好的视频标签对resnet152模型进行有针对性地训练,不断调整训练参数,更新模型以达到最好的模型识别准确率,保存得到的
针对空间特征的诱导性不良行为识别模型;
[0040]
步骤3.3:使用经过处理的光流图和视频标签对resnet152模型进行有针对性地训练,调整训练过程的训练参数,更新模型以达到最好的模型识别准确率,保存得到的针对时间特征的诱导性不良行为识别模型。
[0041]
与现有技术相比,本发明通过将长视频分割成多个短时长分段,将时空特征进行融合并且对多个分段视频的识别结果融合,保证在常规连续动作序列中混杂的诱导性不良行为能够被及时有效地识别,大幅提高复杂状态下的识别准确率。
附图说明
[0042]
图1为本发明实施例提供的方法流程图;
[0043]
图2为本发明实施例提供的系统模块图;
[0044]
图3为本发明实施例提供的空间流训练方法流程图;
[0045]
图4为本发明实施例提供的时间流训练方法流程图。
具体实施方式
[0046]
为使本发明的目的、技术方案及优点更加清楚明白,以下结合实施例,对本发明进行进一步的详细说明。此处所描述的具体实施例仅用于解释本发明,并不用于限定发明。
[0047]
为了满足网络直播平台对于与日俱增直播场次的监管需求,形成一套识别速度更快、识别准确率更高的针对直播视频中诱导性不良行为的检测服务,需要通过信息化工具提升识别效能,减少对人工审核的依赖。单纯通过rgb单帧图像获取视频图像帧包含的表观特征,用来判断直播视频内容是否存在诱导性不良行为,会产生识别准确率低的问题。视频是具有时间特征的连续帧集合,除单帧rgb图片提供的表观特征外,视频较图片还提供了额外的时间特征信息,即物体的运动信息,可以借助光流图内存储的光流信息来获取物体的运动信息。图像的光流可分为x方向与y方向,x方向包含了某点位移矢量场的水平方向的分量,y方向包含了某点位移矢量场的竖直方向的分量。光流图将两个不同方向上的运动信息分开存储,通过相邻两帧单帧图间计算可获取到两张不同方向上的光流图。
[0048]
时空特征的获取,是将得到的rgb单帧图与光流图分别输入卷积神经网络中进行特征提取,获得rgb单帧上的空间特征和光流图内包含的时间特征。时空特征结合既考虑到根据时间特征得到的预测结果,又考虑到根据空间特征得到的预测结果,结合方法采用平均值融合法,对得到的两项预测结果求和后再求平均值,获得融合数据,将融合数据与预设值比对,输出最终判定结果。
[0049]
一段待识别视频的时长可能很长,在这段长时长视频内可能包含多个动作,如何在连续动作序列中精准高效地识别出诱导性不良行为,提高识别准确率是本发明实例的关键。
[0050]
具体地,如图1所示,本实施例详细描述了一种针对直播过程中诱导性不良行为的检测系统,模块间相互协作实现对直播过程中的诱导性不良行为检测工作;本实施例的针对直播过程中诱导性不良行为的检测系统包括:
[0051]
视频集处理模块,其输出端与空间特征处理模块的输入端相连接,所述视频集处理模块用于处理视频集内容,包括获取存储在直播平台数据库内的违规诱导性不良行为视
频案例,抓取实时直播内容保存为待识别视频;对于已确认为诱导性不良行为的视频案例进行分割,按照违规类型标签对每一分段视频做标注;将待识别长时长视频,按照等长度方法划分为多段短时长视频,对于划分好的短时长视频按统一格式命名,保证多个分段视频的连续性和易读性;
[0052]
所述空间特征处理模块包括:
[0053]
rgb单帧图截取子模块,rgb单帧图截取子模块的输入端与视频集处理模块的输出端相连接,rgb单帧图截取子模块的输出端分别与空间特征模型处理子模块和时间特征处理模块的输入端相连接;所述rgb单帧图截取子模块用于对已经处理好的短时长视频进行视频单帧截取rgb单帧图;
[0054]
空间特征模型处理子模块,其输出端与融合模块的输入端相连接,所述空间特征模型处理子模块用于从截取到的rgb单帧图中提取空间特征,然后输入到针对空间特征的诱导性不良行为识别模型中,输出预测结果;
[0055]
时间特征处理模块包括:
[0056]
光流图合成子模块,其输入端与rgb单帧图截取子模块的输出端相连接,光流图合成子模块的输出端与时间特征模型处理子模块的输入端相连接,所述光流图合成子模块用于在时序相邻的两帧rgb单帧图间进行计算,得到瞬时光流信息合成光流图;
[0057]
时间特征模型处理子模块,其输出端与融合模块的输入端相连接,所述时间特征模型处理子模块用于从合成得到的光流图中提取时间特征,然后输入到针对时间特征的诱导性不良行为识别模型中,输出预测结果;
[0058]
融合模块包括:
[0059]
时空特征融合子模块,其输入端分别与空间特征模型处理子模块和时间特征模型处理子模块的输出端相连接,所述时空特征融合子模块用于将得到的针对空间特征的诱导性不良行为识别模型预测结果与针对时间特征的诱导性不良行为识别模型预测结果相融合,得到融合了空间特征与时间特征的数据,融合数据经过分类处理得到一个分段视频的预测结果;
[0060]
预测结果融合子模块,其输入端与时空特征融合子模块的输出端相连接,所述预测结果融合子模块用于在对所有分段视频完成预测后,将多个分段视频的预测结果进行融合计算,得到最终预测结果,最终预测结果就是从直播服务器获取到的长时长视频的识别结果。
[0061]
利用上述实施例的针对直播过程中诱导性不良行为的检测系统针对直播过程中诱导性不良行为的检测方法,如图2所示,具体步骤如下:
[0062]
步骤1:将直播平台视频资料库内存储的违规视频案例进行提取处理,选取出目标视频分割成多段包含违规诱导性行为的短时长视频,记录违规诱导性行为的类型标签;
[0063]
步骤2:对视频进行处理,获取视频的rgb单帧图和光流图:
[0064]
步骤2.1:对视频分段进行rgb单帧图获取,对视频分段进行帧抽取,根据视频帧率特性,对视频内包含的全部rgb单帧图进行抽取;
[0065]
步骤2.2:对rgb单帧图进行光流信息处理,通过两帧相邻单帧图间计算,合成光流图;
[0066]
步骤2.3:对获得的rgb单帧图和光流图进行处理,将同类型诱导性不良行为存放
在一起;
[0067]
步骤3:使用rgb单帧图和光流图中的时空特征分别对识别空间特征的模型和识别时间特征的模型进行训练,得到针对空间特征的诱导性不良行为识别模型与针对时间特征的诱导性不良行为识别模型,具体,如图3、图4所示:
[0068]
步骤3.1:加载通过imagenet训练集预训练过的卷积神经网络模型resnet152;
[0069]
步骤3.2:使用经过处理的rgb单帧图和标记好的视频标签对resnet152模型进行有针对性地训练,不断调整训练参数,更新模型以达到最好的模型识别准确率,保存得到的针对空间特征的诱导性不良行为识别模型,如图3所示;
[0070]
步骤3.3:使用经过处理的光流图和视频标签对resnet152模型进行有针对性地训练,调整训练过程的训练参数,更新模型以达到最好的模型识别准确率,保存得到的针对时间特征的诱导性不良行为识别模型,如图4所示;
[0071]
步骤4:获取直播视频片段,从直播平台服务器获取实时直播缓存,切割成多段时长为2秒-3秒的直播视频分段;
[0072]
步骤5:针对步骤4中切割得到一段的直播视频分段,重复进行步骤2的内容,获得直播视频片段的rgb单帧图和光流图;
[0073]
步骤6:随机选取一张步骤5中得到的rgb单帧图,放入步骤3中得到的针对空间特征的诱导性不良行为识别模型中,输出预测结果;
[0074]
步骤7:将步骤5中得到的光流图放入步骤3中得到的针对时间特征的诱导性不良行为识别模型中,输出预测结果;
[0075]
步骤8:对步骤6和步骤7中得到的数据进行数据融合,通过平均值融合方法,将两项结果进行融合,将融合后的结果输出,对融合结果进行判断,得到某一视频分段的预测结果;
[0076]
步骤9:对由长时长视频分割成的多段视频分段的预测结果进行融合,若存在至少一段视频分段的预测结果为“存在不良行为”,则判定当前的待识别视频存在诱导性不良行为。
[0077]
综述,本发明通过将长视频分割成多个短时长分段,通过时空特征融合处理以及对多个分段视频的识别结果融合,保证在常规连续动作序列中混杂的诱导性不良行为能够被及时有效地识别,大幅提高复杂状态下的识别准确率。
[0078]
本发明的技术方案不限于上述具体实施例的限制,凡是根据本发明的技术方案做出的技术变形,均落入本发明的保护范围之内。
相关技术
网友询问留言
已有0条留言
- 还没有人留言评论。精彩留言会获得点赞!
1