一种多形态知识图谱驱动的知识服务创新方法与流程
本发明属于创新方法应用领域,特别涉及一种多形态知识图谱驱动的知识服务创新方法。
技术背景
创新是提高企业核心竞争力的有效途径之一。中国制造业企业亟需通过产品“提质增效降本”的创新模式打破西方固有“中国制造”的思维定式,具体而言,企业如何生产解决生产过程中具体质量、效率等难题是当前的必由之路。
创新方法是一种解决制造企业的具体技术、管理与服务难题的方法学,通过提供系统性工具辅助,达到启发企业创新思维,挖掘难题解决线索的功能,企业利用创新方法整合、发展和创成并使用领域专用技术解决生产活动的所遇到的难题。然而,企业实施创新方法的过程中仍存在一些问题:(1)企业中的领域知识分散的存在于各类软件系统、员工以及纸质文档中,缺少有效的管理,使得创新方法的应用遇到了一定阻碍;(2)对于已经收集到的领域知识,缺少一种科学有效的利用手段,不能尽可能的发挥其价值;(3)在应用创新方法流模型工具解决难题的过程中缺乏领域知识的支撑。此外,目前学术界也缺乏系统整合创新方法应用的理论研究。
综上所述,在创新方法使用过程中,企业缺乏一套可以将企业领域知识及创新方法工具有效整合的知识服务创新方法,对创新方法的应用过程流模型进行知识推荐服务,帮助企业工作人员正确决策。
技术实现要素:
为了克服现有技术的缺陷,解决制造企业人员使用创新方法工具过程集成领域知识服务的需求问题,本发明的目的提出一种多形态知识图谱驱动的知识服务创新方法,首先整合制造企业多源异构数据的特性,构建制造领域多形态知识图谱,通过科学的工作流模型辅助创新方法工具及决策,降低企业领域知识重用难度和复杂度,更加高效地解决企业工程难题,提高行业竞争力。
为了达到上述目的,本发明采用的技术方案是:
一种多形态知识图谱驱动的知识服务创新方法,具体包括以下步骤:
步骤一:构建多形态领域知识图谱,从知识建模、知识提取、知识存储进行多形态领域知识图谱构建
所述的知识建模:采用网络本体语言owl规范化描述制造企业资源概念,protégé本体建模软件进行本体模式层知识建模,利用owl文件导出对应资源描述框架rdf,在数据层对多形态的知识源提取使用统一知识表达的rdf三元组实体-关系实体<e,r,e>及实体-属性-属性值<e,a,v>;
所述的知识提取:采集车间的多源异构数据,根据不同的数据结构类型,将数据转化为知识,并链接到模式层的概念上,使数据层受到模式层的规范;制造领域知识图谱用于描述制造车间中的资源,分为三类:结构化数据、半结构化数据和非结构化的数据,针对结构化数据,采用数据映射的办法及d2r工具从制造领域的关系型数据库中抽取rdf三元组(s,p,o):其中s是一个由唯一确定的uri所标识的资源;p是s的一个属性,或者是一条关系;o是该属性的性值,也可以是另一个资源;针对半结构化的数据,采用xml、json或表格的格式进行描述;针对非结构化的数据,采用的方法是将非结构化的数据存储到磁盘或者关系型数据库中,在知识图谱中对应的实体上设置文件路径或数据库路径作为标识属性,将其转化成rdf三元组;根据文件路径或者数据库路径,对文件系统或数据库进行检索;
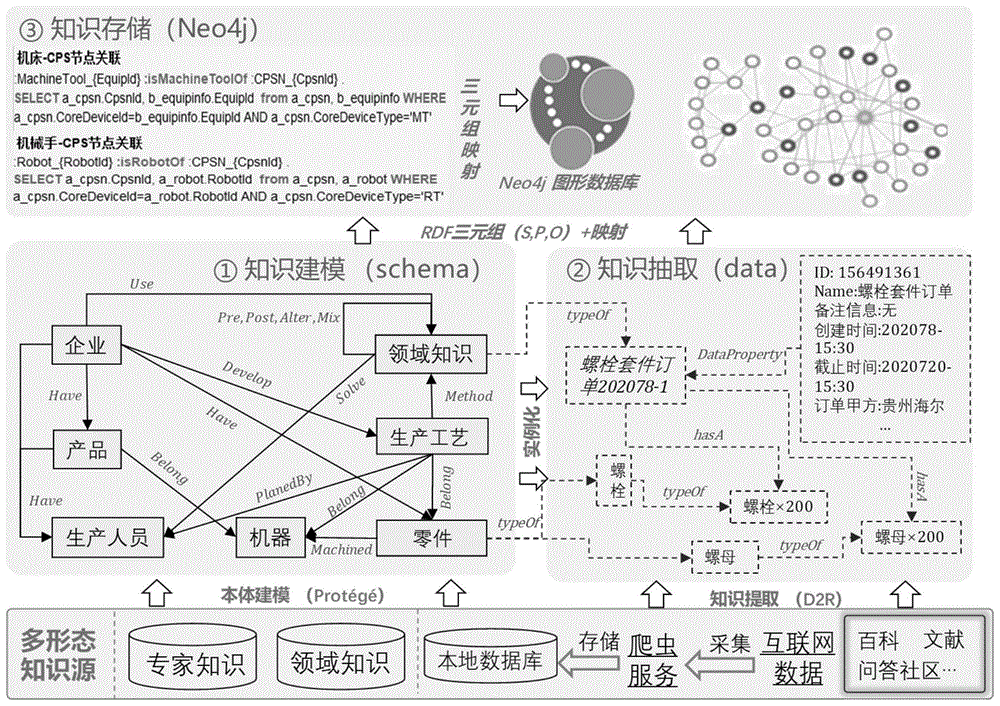
所述的知识存储:用节点以及节点之间的关系描述数据,通过不同的标签来识别不同类型,且节点和关系可拥有若干个key-value形式的属性,一个关系由一个起始节点和一个终止节点构成,因其描述结构的方式与rdf模型不同,采用基于规则的方式将rdf模型映射成为neo4j数据模型,相关映射规则;
步骤二:基于步骤一多形态知识图谱构建,构建一个三层深度建模的知识服务工作流模型,该模型分别从知识服务活动组织流模型、知识资源计算流模型和过程决策流模型三方面对知识图谱驱动的知识服务创新方法解决工程难题的过程进行建模,辅助企业在模板应用层的改善活动。
所述的知识服务活动组织流模型,根据企业实际生产难题的询问,将知识服务活动组织流模型定义为一种组织基于任务的控制活动流模型,包括:编排一个基于元事件的细化、检索、计算和验证的任务循环,其中任务划分为具有特定分解粒度的子任务;检索基于相似性的知识解决方案;协作通过协调代理实现中小企业基于偏好的效用价值,一个事件表示一个子任务的处理过程,该子任务是通过正确的操作结合正确的知识来解决的,表示为:
em={(t,at,pt,st)|t∈t(i)∧at∈a∧pt∈p{i/o}∧st∈s}
知识服务活动组织流模型中的任务t表示具体工程问题任务;at表示针对任务查询知识图谱得到的候选方案;知识服务活动组织流模型中的事件活动状态st是由事件虚拟接口pt输入/输出控制。
所述的知识资源计算流模型为领域知识图谱驱动方案计算过程,以相似性为中心的传递路径,用来计算相关的决策知识元素,以支持知识服务活动组织流模型的输入-活动-输出过程,表示为:
在知识资源计算流模型过程中相似度
dos(ti,kj)=ωrs(i,j)+(1-ω)is(i,j)
公式中:is(i,j)为数值计算的内在相似性;rs(i,j)为概念计算的关系相似性;系数ω可根据训练模型动态调优,本模型设定为0.5;
所述的关系相似性rs:提出了基于关系的知识概念识别方法,将相似知识概念对作为训练实例进行识别;知识概念对ei,ej的相似性用余弦值来度量,表示为:
公式中:
所述的内在相似性(is)是在关系相似性计算知识元素基础上对其属性值计算,进一步提高了具有相同属性集{a1,…,an}的预处理知识对(ei,ej)的检索质量;内在相似性由满足对称性、最小性、传递性和等自相似性的属性相似性来度量,表示为:
公式中:au(ei)表示概念术语实体ei的属性u的值,au(ej)表示概念术语实体ej的属性u的值。
所述的过程决策流模型,在相似性计算的基础上,根据相似性得分对一组备选方案进行排序,将过程决策流模型定义为一种决策逻辑,用来描述将多学科中专家的经验知识与基于效用的决策程度相结合,以验证基于领域知识相似性的方案在难题解决实际任务中的可行性,表示为:
dm={(at,dt,et|at∈al∧dt∈[0,1]∧et∈e)}
其中,dt表示针对任务task(t)的备选方案的专家决策度,即dod;et表示在过程决策过程中的决策者,其依据自身经验及喜好对备选方案at的各属性进行打分求解个体决策值,决策者指围绕产品全生命周期过程中相关专家,分为产品提供者:设计者、制造者、装配者、销售者等相关人员;产品使用者:主指用户;领域专家:知识工程师、软件工程师。
所述的过程决策流模型,其过程决策算法流程执行步骤包括:
第一、构建基于属性的方案矩阵am:
其中矩阵元素xij表示第ith备选方案
第二,构建单属性效用函数,针对单属性采用指数函数构建单属性效用函数u(x)=aedx+bx+c,将效应函数曲线分为五个层次
第三,采用模糊语义方法作为控制方法,即采用解模糊的中心粒度方法将语言值[lij,mij,uij]正则化为模糊值n(oij)∈[0,1],并提出一个基于距离的知识非一致性去表针单属性知识一致性ic:
第四,计算方案期望效用值,选择单属性知识一致性ic大于设定阈值的属性效用值,采用求和方式计算多属性期望效用值:
第五,基于群体决策度计算:
本发明的有益效果为:
1)本发明构建的基于多形态领域知识图谱构建技术,能够为企业使用流模型实例化模板提供领域知识决策服务,在充分整合多形态制造知识的前提下,一定程度上解决了传统企业难题解决过程依靠经验的问题。
2)面向知识图谱驱动的知识服务的三层深度流模型应用,可为企业解决具体生产难题决策提供了一种难题实例化知识服务创新方法应用模板的科学工作流。
附图说明
图1为多形态领域知识图谱构建流程。
图2为过程决策算法流程。
图3为rdf三元组提取及映射规则。
图4基于工作流的知识服务流模型。
图5为知识计算算法流程。
具体实施方式
下面结合附图和实例对本发明作详细的说明,此处所说明的附图是本申请的一部分,用来对本发明作进一步解释,但并不构成对本发明的限定。
本发明具体步骤内容包括多形态指示图铺,以及三层深度知识服务流模型构建及流模型实例化配置。具体步骤如下:
一种多形态知识图谱驱动的知识服务创新方法,具体包括以下步骤:
步骤一:构建多形态领域知识图谱,从知识建模、知识提取、知识存储进行多形态领域知识图谱构建。
所述的知识建模:是专家等对知识图谱所描述领域的概念进行建模,目的是统一规范数据层的知识实体,保证整个知识图谱的精确度。本发明聚焦制造企业,采用网络本体语言(owl)规范化描述制造企业资源概念,protégé本体建模软件进行本体模式层知识建模。鉴于知识图谱模式层的可扩展性、不完善性、粗糙性,利用owl文件导出对应资源描述框架rdf,在数据层对多形态的知识源提取使用统一知识表达的rdf三元组实体-关系实体<e,r,e>及实体-属性-属性值<e,a,v>。
所述的知识提取:采集车间的多源异构数据,根据不同的数据结构类型,采用相应的手段进行知识提取,将数据转化为知识,并链接到模式层的概念上,使数据层受到模式层的规范。制造领域知识图谱主要用于描述制造车间中的资源,其多形态数据类型可分为三类:结构化数据(如:mes、erp、pdm等车间系统中的关系型数据库中的数据)、半结构化数据(如:产品bom、数控程序和制造工艺信息等)和非结构化的数据(如:传感数据、文档、图片、视频以及纯文本等)。本发明针对结构化数据具有高质量、小规模、可控性强的特点,采用数据映射的办法及d2r(datatorelation)工具从制造领域的关系型数据库中抽取rdf三元组(s,p,o):其中s是一个由唯一确定的uri所标识的资源;p是s的一个属性,或者是一条关系;o是该属性的性值,也可以是另一个资源,其规则参见图3(左);针对半结构化的数据,采用xml、json或表格的格式进行描述;针对非结构化的数据时效性强、结构简单、信息量小的特点,采用的方法是将非结构化的数据存储到磁盘或者关系型数据库中,在知识图谱中对应的实体上设置文件路径或数据库路径作为标识属性,将其转化成rdf三元组;根据文件路径或者数据库路径,对文件系统或数据库进行检索。
所述的知识存储:决定了知识图谱的对外服务的质量与效率。neo4j是一种图相关的概念描述数据模型高性能的nosql图数据库,用节点以及节点之间的关系描述数据,通过不同的标签来识别不同类型,且节点和关系可拥有若干个key-value形式的属性,一个关系由一个起始节点和一个终止节点构成。因其描述结构的方式与rdf模型不同,故本发明采用基于规则的方式将rdf模型映射成为neo4j数据模型,相关映射规则,参见图3(右)所示。
步骤二:基于步骤一多形态知识图谱构建,构建一个三层深度建模的知识服务工作流模型,该模型分别从知识服务活动组织流模型、知识资源计算流模型和过程决策流模型三方面对知识图谱驱动的知识服务创新方法解决工程难题的过程进行建模,辅助企业在模板应用层的改善活动。参见图4。
所述的知识服务活动组织流模型,根据企业实际生产难题的询问,将知识服务活动组织流模型定义为一种组织基于任务的控制活动流模型,包括:编排一个基于元事件的细化、检索、计算和验证的任务循环,其中任务划分为具有特定分解粒度的子任务;检索基于相似性的知识解决方案;协作通过协调代理实现中小企业基于偏好的效用价值。一个事件表示一个子任务的处理过程,该子任务是通过正确的操作结合正确的知识来解决的,表示为:
em={(t,at,pt,st)|t∈t(i)∧at∈a∧pt∈p{i/o}∧st∈s}
知识服务活动组织流模型中的任务t表示具体工程问题任务;at表示针对任务查询知识图谱得到的候选方案;组织模型中的事件活动状态st是由事件虚拟接口pt输入/输出控制。
所述的知识资源计算流模型是知识服务解决难题过程中不可缺少的因素,在知识服务活动组织开展过程中,必须得到领域知识资源的支持,提供难题解决过程中的备选方案。为此,本发明将知识计算流模型定义为领域知识图谱驱动方案计算过程,其本质是一个以相似性为中心的传递路径,用来计算相关的决策知识元素,知识服务活动组织流模型的输入-活动-输出过程,表示为:
在知识资源计算流模型过程中相似度
dos(ti,kj)=ωrs(i,j)+(1-ω)is(i,j)
公式中:is(i,j)为数值计算的内在相似性;rs(i,j)为概念计算的关系相似性;系数ω可根据训练模型动态调优,本模型设定为0.5;
所述的关系相似性(rs):提出了基于关系的知识概念识别方法,将相似知识概念对作为训练实例进行识别。知识概念对(ei,ej)的相似性用余弦值来度量的。因为余弦距离能很好地表示结构等价性,并且在一致性度量方面具有很高的稳定性,可表示为:
所述的内在相似性(is)是在关系相似性计算知识元素基础上对其属性值计算,进一步提高了具有相同属性集{a1,…,an}的预处理知识对(ei,ej)的检索质量;内在相似性由满足对称性、最小性、传递性和等自相似性的属性相似性来度量,表示为:
所述的过程决策流模型,在相似性计算的基础上,根据相似性得分(dos)对一组备选方案进行排序。然而,在实践中,一种常见的情况是:在专家决策的基础上,一个排名第一的方案可能被视为最后一个方案,这似乎有悖于基于知识的计算。以一个场景为例:在制造过程中,零件的表面粗糙度越高,性能越好,使用寿命越长,但实际上,在合理的时间和成本下,基于专家的经验知识,对粗糙表面质量较低做出了明智的决定。为此,本发明将过程决策流模型定义为一种决策逻辑,用来描述将多学科中专家的经验知识与基于效用的决策程度相结合,以验证基于领域知识相似性的方案在难题解决实际任务中的可行性。可表示为:
dm={(at,dt,et|at∈al∧dt∈[0,1]∧et∈e)}
其中,dt表示针对任务task(t)的备选方案的专家决策度,即dod;et表示在过程决策过程中的决策者,其依据自身经验及喜好对备选方案at的各属性进行打分求解个体决策值,决策者指围绕产品全生命周期过程中相关专家,分为产品提供者:设计者、制造者、装配者、销售者等相关人员;产品使用者:主指用户;领域专家:知识工程师、软件工程师。
如图2所示,所述的过程决策流模型,其过程决策算法流程执行步骤包括:
第一、构建基于属性的方案矩阵am(attributematrix):
其中矩阵元素xij表示第ith备选方案
第二,构建单属性效用函数,针对单属性采用指数函数构建单属性效用函数u(x)=aedx+bx+c,决策者可通过回答博彩问题将效应函数曲线分为五个层次
第三,基于属性的知识一致性分析与验证,设计一种模糊语义方法作为控制方法,其采用解模糊的中心粒度方法将语言值[lij,mij,uij]正则化为模糊值n(oij)∈[0,1],并提出一个基于距离的知识非一致性去表针单属性知识一致性(individualknowledgeconsistencydegree,ic):
第四,计算方案期望效用值,选择单属性知识一致性ic大于设定阈值的属性效用值,采用求和方式计算方案的多属性期望效用值:
第五,基于群体决策度计算:
- 还没有人留言评论。精彩留言会获得点赞!