基于时频分割及卷积神经网络的鲁棒环境声音识别方法与流程
[0001]
本发明属于声音信号识别领域,涉及一种环境声音信号检测方法,特别是一种基于时频分割及卷积神经网络的鲁棒环境声音识别方法。
背景技术:
[0002]
环境声音信号识别是声音信号处理领域的重要研究课题,其在军事和民用领域中的应用得到了研究人员的广泛关注,被应用于故障检测、声监控、环境感知和音频标注等领域。完整的环境声音识别框架分为信号预处理、特征提取和分类三个部分。伴随着城市智能化管理概念的提出,针对真实环境背景下环境声音信号的感知与识别具有十分重大的实际意义,因此高噪声背景下的环境声音信号识别成为研究热点之一。
[0003]
文献“噪声环境下基于能量检测的生态声音识别,计算机工程,2013,39(02):168-171”公开了一种基于能量检测与mel频率倒谱系数特征的噪声背景下环境声音信号识别方法。该方法通过高斯分布对虚警概率进行预测,进一步结合信号能量及噪声方差实现对环境声音信号中事件声音片段的检测。在对环境声音信号进行事件声音检测的基础上,利用傅里叶变换得到事件声音片段的频谱信息。同时,建立模仿人类耳蜗听觉特性的梅尔滤波器,通过滤波把声音信号的线性频谱映射到基于非线性的mel频谱中,然后利用离散余弦变换得到音频信号的峰值及包络信息,从而实现对环境声音信号特征的有效提取。文献所述方法需要预设虚警概率和确定噪声方差才能实现事件声音片段检测,算法适应性不强;利用傅里叶变换得到环境声音信号的频谱信息,而傅里叶变换难以对非稳态信号进行有效表征;使用多分类支持向量机进行分类,分类速度慢且鲁棒性差。
技术实现要素:
[0004]
本发明解决的技术问题是:为了解决现有的环境声音信号识别方法鲁棒性差、缺少有效的时频表征方法的问题,本发明提供了一种基于时频分割去噪及深度卷积神经网络的鲁棒环境声音信号识别方法。
[0005]
本发明的技术方案是:一种基于时频分割及卷积神经网络的鲁棒环境声音识别方法,包括以下步骤:
[0006]
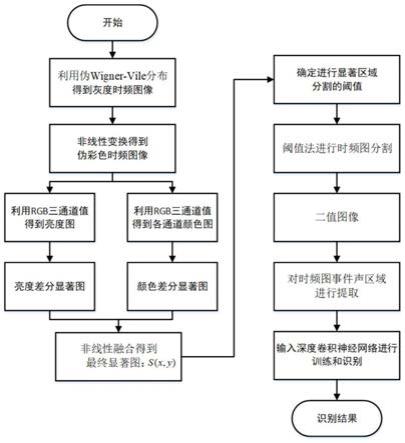
步骤1:利用伪wigner-vile时频分布得到灰度时频图像,包括以下子步骤:
[0007]
步骤1.1:利用伪wigner-vile分布的定义,得到环境声音信号的时频分布:
[0008][0009]
其中,h(τ)为高斯核函数,*表示二维卷积,imf表示环境声音信号,pwvd(t,f)表示pwvd时频图像;
[0010]
步骤1.2:引入阈值,计算对数频谱:
[0011]
pwvd(t,f)=log(max[pwvd(t,f)-max(pwvd),-80db])
[0012]
步骤1.3:通过归一化,得到灰度时频图:
[0013][0014]
其中,g(t,f)表示归一化后的灰度时频图像;
[0015]
步骤2:将灰度图转换为伪彩色时频图:
[0016]
m
c
(f,t)=h
c
(g(t,f)) c=red,green,blue
[0017]
其中,m
c
(f,t)为第c个单色图像,h
c
为第c个单色图像的非线性映射函数;将灰度图映射到hot伪彩色时频图对应的非线性变换为:
[0018][0019]
步骤3:根据步骤2得到的三个通道下的参数值,分别能够得到亮度图和颜色图;
[0020]
其中亮度图为:
[0021]
i=(r+g+b)/3
[0022]
其中,r,g,b为伪彩色时频图的三个通道;
[0023]
经过调整后的各通道颜色图为:
[0024]
r=r-(g+b)/2
[0025]
g=g-(r+b)/2
[0026]
b=b-(r+g)/2
[0027]
y=(r+g)/2-|r-g|/2-b
[0028]
其中,r,g,b,y分别表示红色、绿色、蓝色、黄色四种颜色通道;
[0029]
步骤4:根据步骤3得到的亮度显著图,计算得到亮度差分显著图;
[0030]
s
i
(x,y)=|i
μ-i(x,y)|
[0031]
其中,i
μ
表示亮度差分显著图的像素平均值;
[0032]
根据颜色图,得到颜色差分显著图:
[0033]
s
n
(x,y)=|μ
n-c
n
(x,y)| n=r、g、b、y
[0034]
其中,μ
n
表示相应颜色图的像素平均值,s
n
(x,y)表示相应颜色通道的颜色显著图;步骤5:将步骤四得到的亮度差分显著图和颜色差分显著图进行非线性融合,得到最终显著图为:
[0035]
s(x,y)=max(s
i
(x,y),s
r
(x,y),s
g
(x,y),s
b
(x,y),s
y
(x,y))
[0036]
步骤6:进行时频图事件声区域提取,包括以下子步骤:
[0037]
步骤6.1:根据时频显著图s(x,y)的像素值确定显著区域分割的阈值:
[0038][0039]
其中,n、m分别为时频显著图的高、宽;
[0040]
步骤6.2:阈值法进行时频图分割,得到分割后的二值图像s
seg
(x,y):
[0041][0042]
s
seg
中像素值为1的区域即为事件声在时频图中的分布区域,像素值为0的区域即为背景噪声的分布区域;
[0043]
步骤6.3:根据步骤6.2中,阈值法分割得到二值图像;
[0044]
步骤6.4:对时频图事件声区域进行提取:
[0045][0046]
其中,img
r
,img
g
,img
b
表示伪彩色时频图中三个通道对应的像素点;
[0047]
步骤7:利用基于神经网络的识别模型进行环境声音信号的训练与识别。
[0048]
本发明的进一步技术方案是:所述得到伪彩色时频图后,利用lancazos插值算法将时频图像大小调整。
[0049]
本发明的进一步技术方案是:所述步骤2中,对非线性变换公式中的超参数{l2,l1,u1,u2}在red、green和blue三个颜色通道下进行赋值即可得到hot伪彩色时频图变换对应的非线性公式,相应的参数值为:
[0050]
c
red
={0,(3/8)
×
250,(31/40)
×
250}
[0051]
c
green
={(2/5)
×
250,(31/40)
×
250,(21/20)
×
250}
[0052]
c
blue
={(31/40)
×
250,(21/20)
×
250,(21/20)
×
250}。
[0053]
本发明的进一步技术方案是:所述图像大小调整为:
[0054]
m_resize
c
(f,t)=lancazos(m
c
(f,t))c=red,green,blue。
[0055]
本发明的进一步技术方案是:所述步骤6中确定显著区域后,对于非显著区域,利用img
r
=255,img
g
=0,img
b
=0将非显著区域变为纯色的背景区域,实现对噪声背景的去除。
[0056]
本发明的进一步技术方案是:所述步骤4中的亮度显著图,
[0057][0058]
其中,i(x,y)是亮度差分显著图;g为高斯差分滤波器,ρ为高斯标准差比例系数;σ为截止频率。
[0059]
本发明的进一步技术方案是:所述步骤4公式中,
[0060][0061]
其中,r、g、b、y表示各颜色通道,c
n
(x,y)表示相应颜色通道的颜色差分显著图。
[0062]
本发明的进一步技术方案是:所述步骤7中,所述神经网络共26层,包含了7层卷积层,9层激活层,7层池化层,3层全连接层。
[0063]
发明效果
[0064]
本发明的技术效果在于:本发明提供了一种基于时频分割去噪及深度卷积神经网络的鲁棒环境声音信号识别方法。该方法首先提出将二次型时频分析算法伪wigner-vile分布应用于环境声音信号的时频表征,通过其可以得到更加直观和合理的时频表征图像;
在时频图像基础上,应用伪彩色变换将灰度时频图像转换为伪彩色时频图像,进一步提升了时频表征的鲁棒性;其次,设计了一种基于图像显著性的时频分割算法,利用其对时频图像的环境声音信号分布区域进行提取,从而实现对时频图像噪声的去除;最后,将深度学习应用于环境声音信号识别,构建了一个基于深度卷积神经网络的环境声音信号识别模型,将经过时频分割去噪的伪彩色时频图像输入该模型进行训练和识别,有效提高了识别算法的鲁棒性。具体增益效果如下:
[0065]
(1)传统使用的短时傅里叶变换需要采用分帧的方法对非平稳信号进行近似表示,无法获得信号的瞬时时频分布。在步骤1(权利书中)中,通过引用伪wigner-vile算法对环境声音信号进行时频表征,可以得到时频图像的瞬时时频分布,具有更加明确的物理意义。
[0066]
(2)步骤2中采用伪彩色时频图像,通过映射灰度图像到高维彩色空间,环境噪声对声学特性的影响可以进一步减少,进一步提升了时频图像的抗噪能力。
[0067]
(3)在步骤6、7中,使用基于图像显著性的时频分割算法对时频图像进行去噪,不需要任何噪声的先验知识,方法具有更强的适应性有效降低了噪声对时频图像的污染;利用卷积神经网络对时频图像进行特征提取和分类,进一步提升了算法的泛化能力和鲁棒性。
附图说明
[0068]
图1是算法流程图。
[0069]
图2是事件声区域提取结果图
[0070]
图3是卷积神经网络示意图
具体实施方式
[0071]
参见图1—图2,本发明解决其技术问题所采用的技术方案:一种基于时频分割去噪及深度卷积神经网络的鲁棒环境声音信号识别方法,其特点是包括下述步骤:
[0072]
(a)计算环境声音信号的时频分布:
[0073][0074]
其中,imf表示输入的环境声音信号,h(τ)为高斯核函数,*表示二维卷积,pwvd(t,f)表示利用伪wigner-vile分布得到的pwvd时频图像。
[0075]
(b)引入阈值并进行归一化:
[0076]
pwvd(t,f)=max[pwvd(t,f)-max(pwvd),-80db]
ꢀꢀꢀ
(2)
[0077][0078]
其中,g(t,f)表示归一化后的灰度时频图像。
[0079]
(c)非线性变换得到伪彩色时频图:
[0080]
m
c
(f,t)=h
c
(g(t,f)) c=red,green,blue
ꢀꢀꢀ
(4)
[0081]
其中,m
c
(f,t)为第c个单色图像,h
c
为第c个单色图像的非线性映射函数。
[0082]
(d)图像大小调整:
[0083]
m_resize
c
(f,t)=lancazos(m
c
(f,t)) c=red,green,blue
ꢀꢀꢀ
(5)
[0084]
得到伪彩色时频图后,利用lancazos(a=3)插值算法将时频图像大小调整为512
×
512。
[0085]
(e)时频图像的亮度显著图:
[0086][0087]
s
i
(x,y)=|i
μ-i(x,y)|
ꢀꢀꢀ
(7)
[0088]
其中,i(x,y)表示亮度差分显著图,s
i
(x,y)为亮度显著图,g表示高斯差分滤波器,ρ为高斯标准差比例系数,σ为截止频率,i
μ
为亮度差分显著图的像素平均值。
[0089]
(f)时频图像的颜色显著图:
[0090][0091]
s
n
(x,y)=|μ
n-c
n
(x,y)| n=r、g、b、y
ꢀꢀꢀ
(9)
[0092]
其中,r、g、b、y表示各颜色通道,c
n
(x,y)表示相应颜色通道的颜色差分显著图,μ
n
表示相应颜色图的像素平均值,s
n
(x,y)表示相应颜色通道的颜色显著图。
[0093]
(g)亮度、颜色域融合得到最终的时频显著图:
[0094]
s=max(s
i
(x,y),s
r
(x,y),s
g
(x,y),s
b
(x,y),s
y
(x,y))
ꢀꢀꢀ
(10)
[0095]
(h)图像显著区域分割:
[0096][0097][0098]
其中,n、m表示时频显著图的高和宽,s
seg
(x,y)表示分割后的二值图像。
[0099]
(i)事件声区域提取:
[0100][0101]
其中,img
r
,img
g
,img
b
表示伪彩色时频图中三个通道对应的像素点。
[0102]
(j)构建深度卷积神经网络
[0103]
本发明构建的神经网络共包含26层,其中包含7层卷积层,9层激活层,7层池化层,3层全连接层,深度卷积神经网络的输入为尺寸为512
×
512的rgb三通道彩色图像,每一层卷积层都加入了relu激活函数和批标准化。其整体结构和具体参数见下表1-1。将环境声音信号对应的伪彩色时频图像直接输入到卷积神经网络中进行特征提取、网络训练和分类,从而实现对环境声音信号的鲁棒识别。
[0104]
表1-1深度卷积神经网络结构和参数
[0105][0106][0107]
为下面结合附图对本发明的技术方案进行详细说明。
[0108]
本发明基于时频分割去躁和深度卷积神经网络的鲁棒环境声音信号识别方法,具体实施方式包括以下步骤:
[0109]
下面结合对环境声音数据集中的音频样本进行处理和识别的实例说明本发明的具体实施方式,但本发明的技术内容不限于所述的范围。
[0110]
本发明基于时频分割去躁和深度卷积神经网络的鲁棒环境声音信号识别方法,包括以下步骤:步骤1:利用伪wigner-vile时频分布得到灰度时频图像;步骤2:利用非线性变换将灰度时频图像转换为伪彩色时频图像;步骤3:利用高斯差分滤波器分别在亮度、颜色域求显著图,然后将两个包含不同域信息的显著图进行融合得到最终的时频显著图;步骤4:利用显著图进行事件声区域的提取;步骤5:利用基于神经网络的识别模型进行环境声音信号的训练与识别。
[0111]
步骤一、环境声音信号的时频图像表征。
[0112]
为了提高事件声音识别算法的精度和鲁棒性,本发明提出了用时频图像来表征环境声音信号。环境声音信号属于非稳态信号,传统的时频分析方法难以对其进行有效表征,因此引入二次型时频分析方法对其进行表征。在其基础上,通过非线性函数将灰度时频图映射到r、g、b三个通道,从而得到三通道的伪彩色时频图。通过将灰度图经过非线性函数映
射到高维颜色空间,可以进一步降低环境噪声对声特征的影响。具体步骤如下:
[0113]
(1)直接利用伪wigner-vile分布的定义得到环境声音信号的时频分布:
[0114][0115]
其中,h(τ)为高斯核函数,*表示二维卷积,imf表示环境声音信号,pwvd(t,f)表示pwvd时频图像。
[0116]
(2)引入阈值,计算对数频谱:
[0117]
pwvd(t,f)=log(max[pwvd(t,f)-max(pwvd),-80db])
ꢀꢀꢀ
(15)
[0118]
引入阈值,防止因像素值过小导致对数谱值出现无穷值。
[0119]
(3)通过归一化得到灰度时频图:
[0120][0121]
其中,g(t,f)表示归一化后的灰度时频图像。
[0122]
(4)将灰度图转换为伪彩色时频图:
[0123]
m
c
(f,t)=h
c
(g(t,f)) c=red,green,blue
ꢀꢀꢀ
(17)
[0124]
其中,m
c
(f,t)为第c个单色图像,h
c
为第c个单色图像的非线性映射函数;将灰度图映射到hot伪彩色时频图对应的非线性变换为:
[0125][0126]
对非线性变换公式中的超参数{l2,l1,u1,u2}在red、green和blue三个颜色通道下进行赋值即可得到hot伪彩色时频图变换对应的非线性公式,相应的参数值为:
[0127][0128]
(5)图像大小调整:
[0129]
m_resize
c
(f,t)=lancazos(m
c
(f,t)) c=red,green,blue
ꢀꢀꢀ
(20)
[0130]
得到伪彩色时频图后,利用lancazos(a=3)插值算法将时频图像大小调整为512
×
512。
[0131]
步骤二、计算时频显著图。
[0132]
针对时频图像的纹理特性,在人对图像的两个最基本的感知领域亮度、颜色分别利用高斯差分滤波器求显著图,然后将两个包含不同域信息的显著图进行融合得到最终的时频显著图。
[0133]
(1)利用图像的rgb三通道,得到亮度图i:
[0134]
i=(r+g+b)/3
ꢀꢀꢀ
(21)
[0135]
其中,r,g,b为伪彩色图像的三个通道。
[0136]
(2)利用高斯差分滤波器来获得亮度图像的显著边缘信息,并将多个差分滤波器
相加得到基于高斯差分滤波器的亮度差分显著图:
[0137][0138]
其中,i(x,y)是亮度差分显著图;g为高斯差分滤波器,为了去掉高频噪声和纹理,要使用一个小的高斯核,高斯核取ρ为高斯标准差比例系数,取定值1.6;σ为截止频率,取σ=π/2.75。
[0139]
(3)最终的亮度显著图:
[0140]
s
i
(x,y)=|i
μ-i(x,y)|
ꢀꢀꢀ
(23)
[0141]
其中,i
μ
表示亮度差分显著图的像素平均值。
[0142]
(4)利用r,g,b三通道矩阵得到各颜色图:
[0143][0144]
y=(r+g)/2-|r-g|/2-b
ꢀꢀꢀ
(25)
[0145]
(5)利用高斯差分滤波器分别得到各颜色通道的颜色差分显著图:
[0146][0147]
其中,r、g、b、y表示各颜色通道,c
n
(x,y)表示相应颜色通道的颜色差分显著图
[0148]
(6)得到各颜色通道最终的显著图:
[0149]
s
n
(x,y)=|μ
n-c
n
(x,y)| n=r、g、b、y
ꢀꢀꢀ
(27)
[0150]
其中,μ
n
表示相应颜色图的像素平均值,s
n
(x,y)表示相应颜色通道的颜色显著图。
[0151]
(7)亮度、颜色域显著图非线性融合得到最终的显著图:
[0152]
s(x,y)=max(s
i
(x,y),s
r
(x,y),s
g
(x,y),s
b
(x,y),s
y
(x,y))
ꢀꢀꢀ
(28)
[0153]
步骤三、进行时频图事件声区域提取。
[0154]
通过阈值法对时频显著图进行时频图分割,利用得到的二值图像对原时频图进行事件声区域的提取,从而将事件声在时频图中分布的区域与背景噪声分割开,最终达到对时频图像降噪的目的。
[0155]
(1)根据时频显著图s(x,y)的像素值确定显著区域分割的阈值:
[0156][0157]
其中,n、m分别为时频显著图的高、宽。
[0158]
(2)阈值法进行时频图分割,得到分割后的二值图像s
seg
(x,y):
[0159][0160]
s
seg
中像素值为1的区域即为事件声在时频图中的分布区域,像素值为0的区域即为背景噪声的分布区域。
[0161]
(3)确定显著区域后,对时频图中的显著区域保留,非显著区域去除,从而实现对时频图事件声区域的提取:
[0162][0163]
其中,img
r
,img
g
,img
b
表示伪彩色时频图中三个通道对应的像素点。
[0164]
对于非显著区域,利用img
r
=255,img
g
=0,img
b
=0将非显著区域变为纯色的背景区域,从而实现对噪声背景的去除。
[0165]
步骤四、利用基于神经网络的识别模型进行环境声音信号的训练与识别。
[0166]
本发明通过构建一个基于深度卷积神经网络的识别模型来实现对环境声音信号的识别。该神经网络共26层,包含了7层卷积层,9层激活层,7层池化层,3层全连接层,其整体结构和具体参数在表1-1中已详细列出,这里不再赘述。首先需要构建环境声音数据库,数据库中的声音信号通过上述步骤变换后得到伪彩色时频图像,最后将其输入到神经网络中进行训练,在训练过程中需要设置批大小、学习率、动量、训练批次等超参数。训练好的神经网络模型即可实现对相应类型环境声音信号的识别。
相关技术
网友询问留言
已有0条留言
- 还没有人留言评论。精彩留言会获得点赞!
1