一种基于罗马化维吾尔语的神经机器翻译系统的制作方法
本发明涉及机器翻译技术领域,主要涉及一种基于罗马化维吾尔语的神经机器翻译系统。
背景技术:
机器翻译是利用计算机将源语言自动转换为目标语言的技术。目前常用的翻译方法为统计机器翻译和神经机器翻译。神经机器翻译(neuralmachinetranslation,nmt)在前几年取得了令人印象深刻的结果,它的翻译效果优于传统的基于短语的统计机器翻译(phrase-basedstatisticalmachinetranslation,pbsmt)方法。最先进的nmt系统依赖于编码器解码器架构,并引入注意机制来模拟字对齐;模型随后将源句编码为固定长度的矢量,然后逐字解码,以从矢量表示输出目标字符串。
nmt和统计机器翻译(statisticalmachinetranslation,smt)模型对训练数据的噪音敏感,尤其是快速记住不良示例的nmt。许多研究都建议在平行语料中过滤掉噪声。数据过滤可以减少数据大小和噪声,因此,可以提高培训时间和质量的有效性。但是,找到筛选数据的最佳标准具有挑战性,尤其是在资源不足的语言(如维吾尔语)中。原因是缺乏已知的高质量数据集,这是大多数已知的筛选和选择方法所需的。
nmt通常使用有限词汇来组成输入和输出序列的固定词汇表,但翻译是一个处理开放词汇的过程。因此,错误翻译的稀有词或用未知单词(unknownwords,unk)符号用于表示每个可能的未登录单词(out-of-vocabulary,oov)。除了国家文字系统无法翻译稀有词语外,使用unk符号表示oov单词也增加了句子的模糊性,因为符号打破了这些句子的结构。因此,词汇中的翻译和重新排序受到负面影响。
sennrich等人建议使用字节对编码(bytepairencoder,bpe)算法,在数据压缩的基础上将单词分割成子词单位。bpe切分表明,在缓解有限的词汇和unk方面,情况有望有改善。bpe尽管具有优势,但仍存在某些限制。例如,当词根以各种形态形式出现时,bpe通常会进行不同的分段,从而增加数据歧义并导致翻译错误。此外,bpe可能会将一个罕见或未知的单词拆分为没有意义的子词单位或语义上不同的已知单位,这些子词可以输出语义上不正确的翻译。
目前的机器翻译主要针对英语、汉语、俄语、法语等常见语种,而对小语种(如维吾尔语)的研究较少,目前针对汉维的机器翻译专利多是针对翻译的算法、词语对齐方法、词干提取方法、网站开发等,缺少与预处理相关的专利发明。
现有的翻译模型构建方法多是使用分词、清理长短句、bpe处理、模型训练、模型测试等步骤构建一个完整的翻译系统。这种方法对于汉语、英语这类词形变化较小的语种来说是十分有效的,但是对于形态丰富的语种(如维吾尔语,维吾尔由8个元音和24个辅音组成,共32个字母。维吾尔字母不同于汉语、英语等常用语言的书写规则。维吾尔字母不是单一形式的,而是每个字母可能有几种不同的形式。在无法连接的单词后,前链接出现在连接的字母之前,中间链接出现在两个可以连接的字母的中间,并且后连接出现在连接的字母之后。维吾尔语可以通过在词干后附加词缀来形成新词。有丰富的形态变化和特定的词缀规则,同时还遵循语音和谐规律,生成过程中还会出现弱化、增音、脱落等音变现象),这种模型构建方法会带来一些问题,主要是缺少针对特定语法和词汇形态的分词方法;以及bpe现有的局限性。
目前基于神经网络的汉维翻译存在的问题是:
1)由于存在大量稀有单词,翻译在结构上丰富而复杂的语言时(如维吾尔语)会产生大量未登录单词(oov);
2)对于具有高度变形和形态变化的语言(如维吾尔语),bpe不能对句子进行正确切分,从而降低翻译质量;
3)针对汉语-维吾尔语神经机器翻译的研究较少。
技术实现要素:
发明目的:本发明提供了一种基于罗马化维吾尔语的神经机器翻译系统,使用罗马化处理后的维吾尔语料进行翻译模型训练,以提高bpe的处理效率,防止切分过程中出现误导性问题,缓解oov对翻译质量产生的影响,最终提高针对汉维神经机器翻译的效果。
技术方案:为实现上述目的,本发明采用的技术方案为:
一种基于罗马化维吾尔语的神经机器翻译系统,包括以下处理步骤:
步骤s1、维吾尔语料预处理;
步骤s1.1、“词根+词缀”形态分词;
采用有限状态自动机fsm对维吾尔语料进行切分;通过以下步骤生成后缀集:
步骤s1.1.1、构造后缀集并创建根驱动的有限状态自动机fsa;
步骤s1.1.2、反转fsa并获得非确定性有限状态自动机nfa;
步骤s1.1.3、将nfa转换为确定性有限自动机dfa;
步骤s1.2、对切分后的维吾尔语料进行罗马化处理;
步骤s2、将预处理完成的维吾尔语料输入至transformer翻译模型中,进行翻译;
步骤s3、输出翻译结果。
进一步地,所述步骤s2中transformer翻译模型构建方法如下:
步骤s2.1、将获取的汉维双语平行语料分为中文预处理阶段和维吾尔语预处理阶段,分别进行预处理;具体地,
步骤s2.2、中文语料预处理;首先对输入的中文语料进行jieba分词如下;
步骤s2.2.1、对句子进行清理,将特殊字符标注为未知词性;使用基于前缀词典实现高效的词图扫描,生成句子中汉字所有可能成词情况所构成的有向无环图dag;
步骤s2.2.2、采用了动态规划查找最大概率路径,找出基于词频的最大切分组合;
步骤s2.2.3、对已登录词按字典标注标识;对于未登录词,对其中的汉字采用基于汉字成词能力的隐马尔可夫模型,并使用维特比算法取得分词和标注;对其中的英文、数字给予相应标注;
步骤s2.3、对进行jieba分词后的中文语料进行字节对编码;具体地,
步骤s2.3.1、准备输入的训练语料;
步骤s2.3.2、确定期望的subword词表大小;
步骤s2.3.3、将单词拆分为字节序列,并在末尾添加后缀“</w>”,统计单词频率;所述subword的粒度是字节;
步骤s2.3.4、统计每一个连续字节对的出现频率,选择最高频者合并成新的subword;
步骤s2.3.5、当合并后的subword词表大小满足步骤s2.3.2期望或下一个最高频字节出现频率为1时,结束合并过程,完成字节对编码;
步骤s2.4、维吾尔语料预处理;
根据步骤s1.1-s1.2,获取罗马化后的维吾尔语料;将获取的维吾尔语料采用步骤s2.3所述字节对编码方法进行编码,完成预处理;
步骤s2.5、采用transformer模型对预处理后的汉维语料进行模型构建及训练;
所述transformer模型包括编码器和解码器;在编码器的主层中,每一个层包括两个子层,其中第一子层是含有自注意机制的层,第二子层是全连接的前馈神经网络层;每一个子层的输出都进行残差连接和归一化操作;
所述编码器的每一个层el,其中第一个子层的输出
其中,layernorm(·)是归一化函数;attention(·)代表自注意机制;fc(·)代表全连接前馈神经网络层;
fc(x)=max(0,xw[1]+b[1])w2+b[2]
其中q、k、v是transformer模型需要学习的三个参数向量;dk、α和β为预设参数;μ代表输入向量x的均值,σ代表输入向量x的标准差;w和b是需要训练的权重和偏置参数,在实验开始阶段随机初始化;ε是指定小数;
所述解码器每个层中包括第一子层
其中,
进一步地,所述步骤s1.2中采用开元罗马化工具uroman对切分后的维吾尔语进行处理,具体包括:
(1)采用启发式方法对unicode数据进行罗马化;给定unicode描述的语音标记,uroman使用第二组探针来预测这些语音标记的罗马化表示;
(2)采用更正表法对非组合罗马化字符的序列进行罗马化处理;手动创建更正表,将一个或多个字符的序列映射到所需的罗马化字符;
(3)针对无unicode描述的字符进行罗马化表示;针对汉字,通过汉语拼音表进行罗马化处理;针对朝鲜语,采用标准韩文进行罗马化处理;针对埃及象形文字,在uroman的其他表格中添加单音语音字符和数字进行罗马化处理;
(4)数字的罗马化处理;通过创建特殊数字模块,将不同语言中的数字字符一一映射到西方阿拉伯数字0-9;
(5)拉丁文字的罗马化处理;采用替代的罗马化形式,uroman保留原始的拉丁语拼写,减去任何变音符号,作为最大的罗马化替代方案。
有益效果:本系统以"词根+词缀"的形式对维吾尔语料进行切分,可以有效降低由于维吾尔语形态多变带来的稀疏性问题。而罗马化维吾尔语可以增加词汇的重复出现率,从而产生许多常见的子词,并在提取bpe规则时为bpe切分提供良好的灵活性。本发明可以防止出现bpe切分问题,从而提高翻译质量。与使用原始维吾尔形式相比,优点在于易于读取和可以对实体进行适当的切分。bpe编码可以进一步减少数据的稀疏性问题。通过以上三种方法对维吾尔语进行预处理可以有效提高transformer模型对语料的识别度,进而提高汉维翻译的质量。
附图说明
图1是本发明提供的汉维翻译模型构建流程图;
图2是本发明提供的字节对编码流程图;
图3是本发明提供的jieba处理流程图;
图4是本发明提供的罗马化处理流程图;
图5是本发明提供的transformer模型示意图;
图6是本发明提供的维吾尔语罗马化过程示意图;
图7是本发明提供的中文字节对编码处理示例图;
图8是本发明提供的维吾尔语预处理示例图。
具体实施方式
下面结合附图对本发明作更进一步的说明。
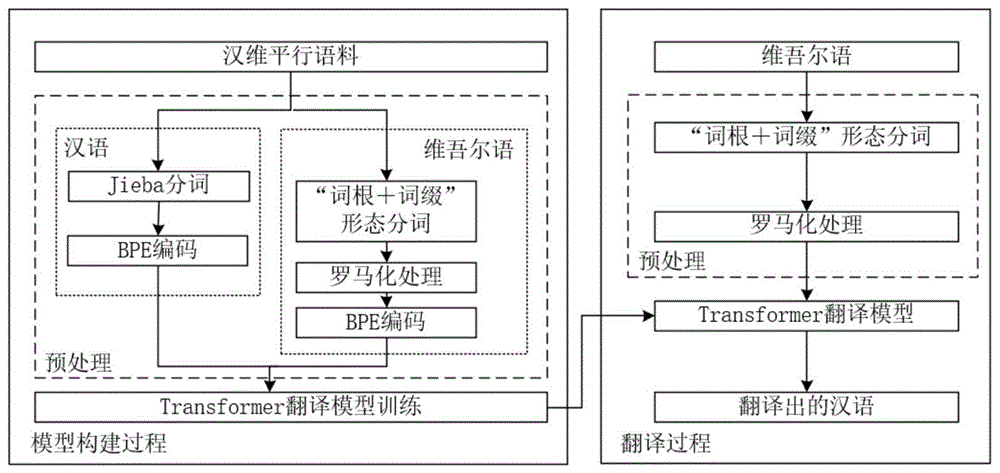
如图1所示的汉维翻译模型构建流程图。汉维翻译系统包括模型构建过程和翻译过程。本翻译系统对汉语语料和维吾尔语语料分别进行不同的预处理。在得到双语平行语料之后,构建双语统计翻译系统之前,都会有一个双语数据预处理的过程,为后续例如词对齐处理提供分好词且格式恰当的双语数据。本系统的预处理根据语料不同的特性,对语料进行不同的预处理过程,即对中文语料使用jieba分词,并使用bpe编码继续切割单词,而对维吾尔语语料首先进行“词根+词缀”形态分词,接着对分词后的维吾尔语进行罗马化处理,最后使用bpe编码进行处理。对于预处理好的语料,使用tansformer模型进行翻译模型训练,以得到最后的翻译模型。对于翻译过程,首先同样对维吾尔语进行预处理,即“词根+词缀”分词和罗马化处理,接着使用训练好的模型翻译处理好的语料,最终将得到翻译好的汉语。具体步骤如下:
步骤s1、维吾尔语料预处理。
步骤s1.1、“词根+词缀”形态分词;
采用有限状态自动机fsm对维吾尔语料进行切分;通过以下步骤生成后缀集:
步骤s1.1.1、构造后缀集并创建根驱动的有限状态自动机fsa;
步骤s1.1.2、反转fsa并获得非确定性有限状态自动机nfa;
步骤s1.1.3、将nfa转换为确定性有限自动机dfa。
维吾尔语中"词根+词缀"的词语构成导致大多数词汇是一个罕见的词,在自然语言处理任务中很容易面对数据不足的问题。在nmt中,由于词汇稀疏性问题的限制,oov更有可能发生。为了缓解这一现象,本发明尝试对原始数据目标词汇,即维吾尔语词汇,以"词根+词缀"的形式进行切分,示例如下表1所示。
表1维吾尔语分词方法
步骤s1.2、对切分后的维吾尔语料进行罗马化处理。本发明采用开源的的罗马化工具uroman对切分后的维吾尔语进行处理,如图4所示,包括以下几个处理部分:
1)unicode数据
uroman使用unicode表的字符描述作为基础。对于大多数脚本的字符,unicode表包含诸如cyrillicsmalllettershortuorcyrilliccapitallettertewithmiddlehook的描述。uroman使用一些启发式方法来识别该描述中的语音标记,即上述示例中的u和te。启发式方法使用一系列锚定关键字(例如字母和音节)以及许多可以丢弃的修饰词模式。给定unicode描述的语音标记,然后uroman使用第二组探针来预测这些语音标记的罗马化表示,即u和t。如果语音标记是多个辅音之一,随后是一个或多个元音,则预测的罗马化字符是辅音的前导序列,例如sha→sh。
2)附加表
启发式方法有时会失败。现实存在非组合罗马化字符的序列。例如,希腊语序列omikron+upsilon(ου)的标准罗马化字符是拉丁字母ou而不是逐个字符的罗马化字符oy。作为补救措施,此方法手动创建了其他更正表,这些表将一个或多个字符的序列映射到所需的罗马化字符,当前有1,088个条目。这些表中的条目可能会受到条件(例如,特定语言或单词开头)的限制,并且可以表示替代的罗马化形式。该数据表是该工具的核心贡献。uroman还包括一些用代码强制转换的特殊试探法,例如用于多种印度语言和藏语的元音化,与变音符号的交替,特定语言的特殊性,例如日语sokuon和泰国辅音-元音的互换。
3)没有unicode描述的字符
unicode表不包括所有脚本的字符描述。对于汉字,该方法使用汉语拼音表进行罗马化。对于朝鲜语,使用简短的标准韩文罗马化算法。对于埃及象形文字,在uroman的其他表格中添加了单音语音字符和数字。
4)数字
uroman还以数字形式罗马化数字。对于某些脚本,数字字符一对一映射到西方阿拉伯数字0-9,例如孟加拉语,东部阿拉伯语和北印度语。对于其他文字,例如阿姆哈拉文,中文和埃及象形文字,其书写数字在结构上是不同的,例如amharic数字字符序列10·9·100·90·8=1998,而中文数字字符序列2·10·5·10000·6·1000=256000。uroman包括一个特殊的数字模块来完成后一种映射。
5)拉丁文字的罗马化
一些基于拉丁文字的语言剃须词,其拼写和发音差异很大,例如英文名称knight(ipa:/nait/)和法属波尔多(/bok.do/),如果非拉丁语脚本中单词的相应拼写基于发音,则会使字符串相似性匹配变得复杂。因此,uroman为诸如knight和bordeaux之类的单词提供了替代的罗马化形式,但是作为一项策略,uroman始终保留原始的拉丁语拼写,减去任何变音符号,作为最大的罗马化替代方案。
本发明使用uroman对维吾尔语进行罗马化处理,该工具依赖于unicode数据和其他一些表,并能处理几乎所有字符集,包括一些非常晦涩的字符集。此转化过程使用音译也被认为是一种罗马化方法。这是根据近似的拼音或拼写等价物,将给定的源语言文本转换为另一种语言的过程。这种技术已被许多领域所利用,如mt和信息检索(ir)中。
这种方法可以增加词汇的重复出现率,从而产生许多常见的子词,并在提取bpe规则时为bpe切分提供良好的灵活性。这种方法可以防止之前阐明的bpe切分问题,从而提高翻译质量。与使用原始维吾尔形式相比,本发明的其他优点是易于读取和可以对实体进行适当的切分。
具体使用方法为:uroman.pl[-l<lang-code>][--chart][--no-cache]<stdin。
步骤s2、将预处理完成的维吾尔语料输入至transformer翻译模型中,进行翻译;具体地,
步骤s2.1、将获取的汉维双语平行语料分为中文预处理阶段和维吾尔语预处理阶段,分别进行预处理;
步骤s2.2、中文语料预处理;首先对输入的中文语料进行jieba分词,如图2所示。
步骤s2.2.1、对句子进行清理,将特殊字符标注为未知词性;使用基于前缀词典实现高效的词图扫描,生成句子中汉字所有可能成词情况所构成的有向无环图dag;
步骤s2.2.2、采用了动态规划查找最大概率路径,找出基于词频的最大切分组合;
步骤s2.2.3、对已登录词按字典标注标识;对于未登录词,对其中的汉字采用基于汉字成词能力的隐马尔可夫模型,并使用维特比算法取得分词和标注;对其中的英文、数字给予相应标注。
其中隐马尔可夫模型是用来描述一个含有隐含未知参数的马尔可夫过程的统计模型。维特比算法涉及多步骤每步多选择模型的最优选择问题。在每一步的所有选择都保存了前续所有步骤到当前步骤当前选择的最小总代价(或者最大价值)以及当前代价的情况下前继步骤的选择。依次计算完所有步骤后,通过回溯的方法找到最优选择路径。可以用来解决隐马尔可夫模型的解码问题。
jieba分词算法使用了基于前缀词典实现高效的词图扫描,生成句子中汉字所有可能生成词情况所构成的有向无环图,再采用了动态规划查找最大概率路径,找出基于词频的最大切分组合,对于未登录词,采用了基于汉字成词能力的hmm模型,使用了维特比算法。本发明使用jieba对中文语料进行切分处理,具体命令行语句为:
python-mjieba-d<inputfile>outputfile
下表2给出了中文状态下jieba分词结果:
表2jieba分词结果
步骤s2.3、对进行jieba分词后的中文语料进行字节对编码,如图3所示。
步骤s2.3.1、准备输入的训练语料;
步骤s2.3.2、确定期望的subword词表大小;
步骤s2.3.3、将单词拆分为字节序列,并在末尾添加后缀“</w>”,统计单词频率;所述subword的粒度是字节;
步骤s2.3.4、统计每一个连续字节对的出现频率,选择最高频者合并成新的subword;
步骤s2.3.5、当合并后的subword词表大小满足步骤s2.3.2期望或下一个最高频字节出现频率为1时,结束合并过程,完成字节对编码。
步骤s2.4、维吾尔语料预处理;
根据步骤s1.1-s1.2,获取罗马化后的维吾尔语料;将获取的维吾尔语料采用步骤s2.3所述字节对编码方法进行编码,完成预处理。
字节对编码总是将出现频率较高的字符合并起来,它通常将词根与其词缀分开。因此,nmt的词汇仅具有词素,从而为不包含在词汇中的不常用单词留出了空间。但是,字节对编码分割仅对词汇的前缀和后缀有效,而不考虑词汇的形态,特别是在诸如维吾尔语之类的形态变化较多的语言上。因此,字节对编码没有对句子进行正确切分,从而导致翻译的错误性。
罗马化可以将字符串相似性度量标准应用于来自不同脚本的文本,而无需中间语音表示形式的需求和复杂性。本发明将罗马化定义为根据原文的近似发音将字符映射到拉丁文脚本(ascii)的过程。同时,严格使用拉丁语ascii字符的音译系统代表源语言的发音,具体转化过程如图6所示。
字节对编码是nmt研究和生产中用于分词的常见标准方法。它是一种数据压缩算法,它根据字符对的出现频率合并字符序列,并将单词分割成较小的单元。因此,在bpe分割时,每个单词都被视为一个字符序列。然后,将最常见的字符组合为一个由这些字符组成的对。当达到预定义的操作数或没有令牌对出现一次以上时,算法将停止,处理结果如图7所示。
通过拆分稀有单词并保留不频繁使用的单词,可以证明该技术是解决稀有单词和unk问题的有效解决方案。因为nmt通常使用固定大小的词汇表,所以这种方式可以满足nmt分段的要求。
在本发明中,我们通过使用bpe作为预处理步骤来训练子词级nmt系统,以克服数据稀疏性问题并进一步消除unk,总体的预处理流程图如图8所示。
步骤s2.5、采用transformer模型对预处理后的汉维语料进行模型构建及训练;
本发明选择使用transformer模型对预处理后的汉维语料进行模型构建及训练。transformer模型是google团队在2017年提出的一种nlp经典模型。它使用了自注意力(self-attention)机制,而不采用rnn的顺序结构,使得模型可以并行化训练,而且能够拥有全局信息。模型主要由编码器和解码器组成,如图5所示。
所述transformer模型包括编码器和解码器;在编码器的主层中,每一个层包括两个子层,其中第一子层是含有自注意机制的层,第二子层是全连接的前馈神经网络层;每一个子层的输出都进行残差连接和归一化操作;
所述编码器的每一个层el,其中第一个子层的输出
其中,layernorm(·)是归一化函数;attention(·)代表自注意机制;fc(·)代表全连接前馈神经网络层;
fc(x)=max(0,xw[1]+b[1])w2+b[2]
其中q、k、v是transformer模型需要学习的三个参数向量;dk、α和β为预设参数;μ代表输入向量x的均值,σ代表输入向量x的标准差;w和b是需要训练的权重和偏置参数,在实验开始阶段随机初始化;ε是一个很小的小数,防止在计算中除数为0。
所述解码器每个层中包括第一子层
其中,
模型训练时使用pytorch深度学习框架库和fairseq开源序列建模工具包。使用的命令是fairseq-train,在参数中需要指定训练数据、模型、优化器等参数。fairseq-train提供了大量的训练参数,从而进行定制化的训练过程,其中主要的参数可以分为数据(data)、模型(model)、优化(optimizing)、训练(分布式和多gpu等)、日志(log)和模型保存(checkpointing)等。
(1)数据部分
数据部分的常用参数主要有训练数据的位置(路径),训练时的batch-size等。其中,batch-size可以通过两种方法指定,--max-tokens是按照词的数量来分的batch,比如“--max-tokens4096”指每个batch中包含4096个词;另外还可以通过句子来指定,如“--max-sentences128”指每个batch中包含128个句子。
(2)模型部分
模型部分的参数主要有--arch,用指定所使用的网络模型结构,有大量预设的可以选择。其命名一般为“model_setting”,如“transformer_iwslt_de_en”就是使用transformer模型和预设的iwslt_de_en超参数。在大数据上进行训练的时候,可以选择“transformer_wmt_en_de”、“transformer_wmt_en_de_big”等设置。除了transformer之外,还有lstm、fconv等模型及对应的预设超参数可以选择。
在使用预设模型的同时,还可以通过额外的命令行参数来覆盖已有的参数,如“transformer_wmt_en_de”中预设的编码器层数是6,可以通过“--encoder-layers12”将编码器改为12层。
(3)优化部分
通过--criterion可以指定使用的损失函数,如cross_entropy等。和arch参数一样,也可以通过命令行参数来覆盖特定损失的默认参数,比如通过--label-smoothing0.1,可以将label_smoothed_cross_entropy损失中默认为0的label-smoothing值改为0.1。通过--optimizer可以指定所使用的优化器,如adam、sgd等;通过--lr-scheduler可以指定学习率缩减的方式。
通常来说,参数优化紧跟梯度计算,即每计算一次梯度,就会进行一次参数更新。在某些时候,我们希望在多次梯度计算之后进行一次更新,来模拟多gpu训练,可以通过--update-freq来指定,比如在单个gpu上指定“--update-freq4”来训练,结果和4个gpu训练是基本等价的。
(4)训练部分
fairseq支持单gpu/多gpu/多机器等多种训练方式,在默认情况下,会根据当前机器的gpu数量来确定训练方式。在绝大多数情况下,通过系统环境变量的方式,即cuda_visible_devices=0,1,来指定单卡/多卡训练。
如果所使用的gpu支持半精度,那么可以通过参数--fp16来进行混合精度训练,可以极大提高模型训练的速度。通过torch.cuda.get_device_capability可以确定gpu是否支持半精度,如果该值小于7则不支持,大于等于7则支持。
(5)日志和模型保存
在默认情况下,fairseq使用tqdm和进度条来展示训练过程,但是这种方法不适合长时间在后台进行模型训练。通过--no-progress-bar参数可以改为逐行打印日志,方便保存。默认情况下,每训练100步之后会打印一次,通过--log-interval参数可以进行修改。
fairseq在训练过程中会保存中间模型,保存的位置可以通过--save-dir指定,其默认为checkpoints。中间模型保存的频率有两种指定方式,--save-interval指定了每n个epoch(遍历训练数据n次)保存一次;--save-interval-updates指定了每n步保存一次,这种通过step来保存模型的方法目前更为常用。
步骤s2、将预处理完成的维吾尔语料输入至transformer翻译模型中,进行翻译;
步骤s3、输出翻译结果。
在实际进行翻译测试时使用“词根+词缀”方法对维吾尔语进行分词,然后使用uroman对维吾尔语进行罗马化处理,处理后的语料用训练好的模型进行翻译,即可得到汉语。
以上所述仅是本发明的优选实施方式,应当指出:对于本技术领域的普通技术人员来说,在不脱离本发明原理的前提下,还可以做出若干改进和润饰,这些改进和润饰也应视为本发明的保护范围。
- 还没有人留言评论。精彩留言会获得点赞!