一种数据收集方法、装置和电子设备与流程
[0001]
本申请涉及大数据领域,特别涉及一种数据收集方法、装置和电子设备。
背景技术:
[0002]
大数据(big data),是一种规模大到在获取、存储、管理、分析方面大大超出了传统数据库软件工具能力范围的数据集合,其具有海量的数据规模、快速的数据流转、多样的数据类型和价值密度低四大特征。
[0003]
随着云时代的来临,大数据也吸引了越来越多的关注。大数据技术的战略意义不在于掌握庞大的数据信息,而在于对这些含有意义的数据进行专业化处理。换而言之,如果把大数据比作一种产业,那么这种产业实现盈利的关键,在于提高对数据的“加工能力”,通过“加工”实现数据的“增值”。而在对大数据进行专业化处理之前,一个无法绕过的环节就是大数据的收集,因此,需要一种针对大数据的收集方法。
技术实现要素:
[0004]
针对现有技术中大数据应用场景下如何收集数据的问题,本申请提供了一种数据收集方法、装置和电子设备。
[0005]
本申请实施例采用下述技术方案:
[0006]
第一方面,本申请提供一种数据收集方法,包括:
[0007]
基于超文本传送协议服务获取上报数据;
[0008]
将所述上报数据保存到分布式队列;
[0009]
从所述分布式队列中读取所述上报数据,处理所述上报数据以获取目标数据;
[0010]
将所述目标数据写入数据库。
[0011]
在上述第一方面的一种可行的实现方式中,所述上报数据采用json格式。
[0012]
在上述第一方面的一种可行的实现方式中,所述分布式队列为基于kafka平台所构建的分布式队列。
[0013]
在上述第一方面的一种可行的实现方式中,所述方法还包括:
[0014]
根据获取所述上报数据的节点数以及处理所述上报数据的节点数,设定所述分布式队列的分区数。
[0015]
在上述第一方面的一种可行的实现方式中:
[0016]
所述方法还包括,在kafka中创建数据主题,所述数据主题与所述上报数据的类型对应;
[0017]
所述将所述上报数据保存到分布式队列,包括,直接将所述上报数据写入对应的所述数据主题。
[0018]
在上述第一方面的一种可行的实现方式中,所述方法还包括:
[0019]
监控所述分布式队列的运行状况;
[0020]
根据所述分布式队列的运行状况确认当前数据收集状况;
[0021]
根据所述当前数据收集状况调配系统资源。
[0022]
在上述第一方面的一种可行的实现方式中,所述基于超文本传送协议服务获取上报数据,其中,基于分布式组件获取所述上报数据。
[0023]
在上述第一方面的一种可行的实现方式中,所述基于超文本传送协议服务获取上报数据,其中,当第一ip地址的上报次数在单位时间内到达预设的上报数阈值时,在预设时长内不再响应所述第一ip地址的上报。
[0024]
在上述第一方面的一种可行的实现方式中,所述基于超文本传送协议服务获取上报数据,包括:
[0025]
获取所述上报数据;
[0026]
基于所述上报数据的头部令牌,验证所述上报数据的真伪性。
[0027]
在上述第一方面的一种可行的实现方式中,所述基于超文本传送协议服务获取上报数据,包括:
[0028]
获取所述上报数据;
[0029]
为所述上报数据添加上报时间和/或上报ip地址。
[0030]
在上述第一方面的一种可行的实现方式中,所述处理所述上报数据以获取目标数据,其中,基于分布式组件处理所述上报数据。
[0031]
第二方面,本申请提供一种数据收集装置,包括:
[0032]
分布式队列,其用于保存上报数据;
[0033]
数据获取模块,其用于基于超文本传送协议服务获取上报数据,并且,将所述上报数据保存到所述分布式队列;
[0034]
数据处理模块,其用于从所述分布式队列中读取所述上报数据,处理所述上报数据以获取目标数据,并且,将所述目标数据写入数据库。
[0035]
第三方面,本申请提供一种电子设备,所述电子设备包括用于存储计算机程序指令的存储器和用于执行程序指令的处理器,其中,当该计算机程序指令被该处理器执行时,触发所述电子设备执行如上述第四方面所述的方法步骤。
[0036]
根据本申请实施例所提出的上述技术方案,至少可以实现下述技术效果:
[0037]
根据本申请实施例的方法,可以大大提高数据收集方案应对大流量应用场景的能力,以及,提高数据收集方案对不同业务的适应性。
附图说明
[0038]
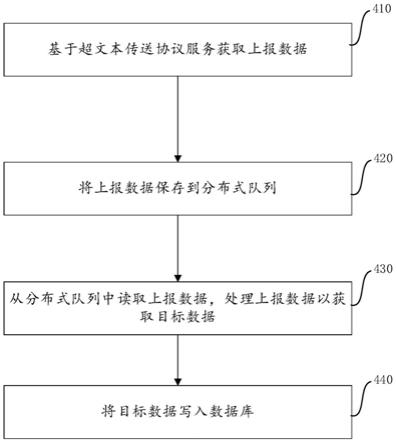
图1所示为根据一实施例的数据收集系统结构示意图;
[0039]
图2所示为根据一实施例的数据收集系统结构示意图;
[0040]
图3所示为根据一实施例的数据收集系统结构示意图;
[0041]
图4所示为根据本申请一实施例的数据收集方法流程图
[0042]
图5所示为根据本申请一实施例的数据收集装置结构框图;
[0043]
图6所示为根据本申请一实施例的数据收集装置结构示意图;
[0044]
图7所示为根据本申请一实施例的方法部分流程图;
[0045]
图8所示为根据本申请一实施例的方法部分流程图;
[0046]
图9所示为根据本申请一实施例的方法部分流程图;
[0047]
图10所示为根据本申请一实施例的装置部分结构框图。
具体实施方式
[0048]
为使本申请的目的、技术方案和优点更加清楚,下面将结合本申请具体实施例及相应的附图对本申请技术方案进行清楚、完整地描述。显然,所描述的实施例仅是本申请一部分实施例,而不是全部的实施例。基于本申请中的实施例,本领域普通技术人员在没有做出创造性劳动前提下所获得的所有其他实施例,都属于本申请保护的范围。
[0049]
本申请的实施方式部分使用的术语仅用于对本申请的具体实施例进行解释,而非旨在限定本申请。
[0050]
在大数据应用场景下,通常的数据收集流程为:
[0051]
获取终端设备所上报的上报数据;
[0052]
对获取到的上报数据进行处理以获取目标数据,例如,对上报数据进行过滤、清洗、合并或转化以获取目标数据;
[0053]
将获取到的目标数据保存到数据库。
[0054]
针对现有技术中大数据应用场景下如何收集数据的问题,一种可行的解决方案是:针对不同的场景,做不同的处理。例如,创建两个相互独立的模块,一个模块用于收集终端上报的超文本传送协议服务(http)数据(自定义http服务),另一个模块用于处理定时任务离线文件;每个模块单独维护自身的每个组件。
[0055]
图1所示为根据一实施例的数据收集系统结构示意图。如图1所示,基于简单网络服务(web service)构建网络服务器(webserver)110。在网络服务器(webserver)110中构建用于数据收集的收集模块111以及用于数据处理的处理模块112。
[0056]
上报数据直接发到网络服务器110的收集模块111,处理模块112基于web服务,直接处理收集模块111接收到的上报数据,并将处理结果写入数据库(database,db)120。
[0057]
在图1所示实施例中,由于网络服务器110采用web服务,因此其对流量敏感,其无法应对大流量。并且,网络服务器110的处理配置与上报数据对应的应用场景匹配。因此,针对不同的业务,需要重新开发webserver端代码。这就使得图1所示的数据收集方案对现有业务存在绑定性,无法适应性匹配新业务,存在单点故障问题。一旦网络服务器110出现故障,会直接影响现有业务。
[0058]
进一步的,针对现有技术中大数据应用场景下如何收集数据的问题,另一种可行的解决方案是:基于内存队列接收上报数据,由内存队列将上报数据分配发送到多个处理模块以对上报数据进行处理。
[0059]
图2所示为根据一实施例的数据收集系统结构示意图。如图2所示,上报数据直接发到内存队列210,内存队列210将上报数据分发到处理模块221、222、223,处理模块221、222、223分别处理自身所接收到的上报数据,并将处理结果写入数据库230。
[0060]
图2所示的数据收集方案,在流量平稳的状态下,可以支持较大流量。但是,当流量突然峰值到来,后端数据处理模块处理来不及,可能将前端内存队列撑爆。与此同时,内存队列本身存在单点故障问题。并且,进一步的,对于数据处理模块而言,其与上报数据对应的应用场景匹配,当新业务添加时,资源不能复用,开发成本较大。
[0061]
进一步的,针对现有技术中大数据应用场景下如何收集数据的问题,另一种可行
的解决方案是:基于快速增量备份(rsync),在主节点上同步终端节点上的数据以获取上报数据。在主节点统一使用本地代码处理上报数据,并且,由主节点将处理后的数据保存到数据库。
[0062]
图3所示为根据一实施例的数据收集系统结构示意图。如图3所示,终端节点301上存在上报数据311、312、313,终端节点302上存在上报数据321、322、323,终端节点303上存在上报数据331、332、333。主节点304通过rsync将终端节点301、302、303上的上报数据同步过来,统一使用本地代码处理,并将处理后的数据保存到数据库305。
[0063]
图3所示的数据收集方案,由于基于rsync同步数据,因此对内存要求很低。并且,由于统一使用本地代码处理上报数据,从而大大提高了针对不同业务的适应性。但是,由于资源传输管理是以文件形式,效率很低,这就导致主节点304处理能力一般,很容易因为数据量太大,导致文件堆积。
[0064]
针对上述数据收集方案存在的问题,在本申请一实施例中,提出了一种数据收集方法。在本申请实施例的方法中,基于分布式队列将数据收集与数据处理隔开,从而大大增强对大流量的适应性。并且,数据收集与数据处理隔开后数据收集端可以固定,而数据处理端可以针对不同业务做定制化处理,增加系统的灵活性、可用性。
[0065]
进一步的,在数据收集端,采用超文本传送协议(http)服务,将所有的上报数据限制为采用http方式上传,从而实现对上报数据的统一收集以及后续的统一处理,以大大提高数据收集方案对不同业务的适应性。根据本申请实施例的方法,可以大大提高数据收集方案应对大流量应用场景的能力,以及,提高数据收集方案对不同业务的适应性。
[0066]
图4所示为根据本申请一实施例的数据收集方法流程图。如图4所示,自行下述步骤以收集数据:
[0067]
步骤410,基于超文本传送协议服务获取上报数据;
[0068]
步骤420,将上报数据保存到分布式队列;
[0069]
步骤430,从分布式队列中读取上报数据,处理上报数据以获取目标数据;
[0070]
步骤440,将目标数据写入数据库。
[0071]
基于图4所示实施例的方法,本申请一实施例中还提出了一种数据收集装置。图5所示为根据本申请一实施例的数据收集装置结构框图。如图5所示,装置包括:
[0072]
分布式队列510,其用于保存上报数据;
[0073]
数据获取模块520,其用于基于超文本传送协议服务获取上报数据,并且,将上报数据保存到分布式队列510;
[0074]
数据处理模块530,其用于从分布式队列中读取上报数据,处理上报数据以获取目标数据,并且,将目标数据写入数据库540。
[0075]
图5所示实施例的装置,基于模块化的特点,数据获取模块520与数据处理模块530被隔开,从而大大增强对大流量的适应性。并且,数据获取模块520与数据处理模块530被隔开后数据获取模块520可以固定,数据获取模块520自动完成数据获取。而数据处理模块530的主要工作集中在数据处理部分,开发者只需关注数据处理模块530如何处理数据,在旧业务发生变动时,只需相应修改数据处理模块530的处理端逻辑,数据获取模块520无需改变,从而可以大大提高工作效率,增加系统的稳定性。
[0076]
进一步的,为了便于对上报数据实现统一收集以及统一处理,在本申请一实施例
中,限定上报数据采用统一的数据结构。例如,js对象简谱(javascript object notation,json)是一种轻量级的数据交换格式。它基于欧洲计算机协会制定的js规范(ecmascript)的一个子集,其采用完全独立于编程语言的文本格式来存储和表示数据,具有简洁和清晰的层次结构。因此,在本申请一实施例中,上报数据采用json格式。
[0077]
进一步的,在实际应用场景中,图4所示实施例的方法流程的各个步骤可以采用多种不同的实现方式,图5所示实施例的装置的各个模块也可以采用多种不同的实现结构。
[0078]
例如,在本申请一实施例中,基于分布式组件实现数据获取模块520;和/或,基于分布式组件实现数据处理模块530。这样,就可以有效避免装置的单点故障,从而大大提高装置可靠性。进一步的,在本申请一实施例中,基于分布式组件实现数据库540,从而大大提高数据库540的稳定性以及流量承载能力。
[0079]
图6所示为根据本申请一实施例的数据收集装置结构示意图。如图6所示,数据获取模块610包含输入均衡器600以及http服务器节点611、612、613以及614。
[0080]
均衡器600的作用是将上报数据的压力分散到http服务器节点,避免由于数据倾斜导致过载,导致节点异常。均衡器600也可以使http服务器节点的其中一个节点异常后,服务无影响。具体的,可以使用软件负载均衡器构建均衡器600,也可以部署硬件负载均衡器实现均衡器600。进一步的,均衡器本身不是分布式设计,但是可以主备部署,增强系统可靠性。
[0081]
均衡器600将输入的上报数据均衡的分发到http服务器节点611、612、613以及614。分布式队列620包含分布式队列节点621、622、623、624。数据获取模块610中的每一个http服务器节点均连接到所有的分布式队列节点上。
[0082]
数据处理模块630包含处理节点631~642;处理节点631~642分为三组,每组处理节点对应连接数据库650的一个数据库节点(数据库节点651、652、653)。每组处理节点中,一个处理节点对应连接一个分布式队列节点。
[0083]
当http服务器节点611、612、613以及614中的任意一个节点、或者分布式队列节点621、622、623、624中的任意一个节点、或者处理节点631~642中的任意一个节点、或者数据库节点651、652、653中的任意一个节点宕机时,不会影响数据收集装置的数据收集业务,从而大大提高装置可靠性。
[0084]
进一步的,当装置吞吐突然加大(上报数据流量突然加大),每个模块(数据获取模块610、分布式队列620、数据获取模块630、数据库650)均可以动态增加处理节点,以提高装置吞吐能力。同时,当装置吞吐减小(上报数据流量减少),每个模块(数据获取模块610、分布式队列620、数据获取模块630、数据库650)也可以动态减少处理节点,以节省资源占用。
[0085]
具体的,在数据处理模块630的一种实现方式中,数据处理模块630被虚拟化部署在容器中,根据上报数据的上报流量情况,动态的增减数据处理模块630的处理节点,以实现资源的高效利用,节省成本。
[0086]
图7所示为根据本申请一实施例的方法部分流程图。如图7所示,在收集数据的过程中,执行下述判断流程以动态配置数据处理模块630的处理容器:
[0087]
步骤710,判断1小时内,每分钟数据堆积是否在10万以上;
[0088]
当判断结果为是时,执行步骤720,检查装置是否还有容器资源;
[0089]
如果有容器资源,执行步骤721,增加一个处理容器,跳到步骤700;
[0090]
如果没有容器资源,执行步骤722,判断是否发出告警;
[0091]
如果已发告警,跳到步骤700;
[0092]
如果未发告警,执行步骤723,发出告警信息(例如,邮件、短信、电话),跳到步骤700;
[0093]
当步骤710的判断结果为否时,执行步骤730,判断一天内,数据堆积是否持续小于1000;
[0094]
如果判断结果为是,执行步骤731,减少一个处理容器,跳到步骤700;
[0095]
如果判断结果为否,跳到步骤700;
[0096]
步骤700,等待1小时,返回步骤710。
[0097]
进一步的,在本申请一实施例中,通过对分布式队列的监控来确认数据收集的运行状况。具体的,数据收集方法还包括:监控分布式队列的运行状况;根据分布式队列的运行状况确认当前数据收集状况;根据当前数据收集状况调配系统资源。如图6所示,装置还包括监控模块660,监控模块660用于监控分布式队列620中各个节点上的上报数据写入/取出状况,从而确认当前数据收集状况(上报数据的上报流量),进而对数据处理模块630的处理容器个数进行动态调配。
[0098]
进一步的,nginx是一个高性能的http服务器/反向代理web服务器,同时也提供了imap/pop3/smtp服务,其特点是占有内存少,并发能力强。具体的,nginx存在以下特点:纯c语言实现,其性能较好;nginx http处理,可以抽象出11个处理逻辑,且每个逻辑都可以代码介入,可以较为方便的实现业务代码;nginx作为高性能web服务器的代表,拥有众多好用的插件、工具、同时也是开源可控项目。因此,在本申请一实施例中,基于nginx构建数据获取模块520。
[0099]
在实际应用场景中,存在非法用户通过上传上报数据来恶意攻击数据收集装置的情况。针对该情况,在步骤410的具体实现流程中,构建有安全防护机制。即,数据获取模块520中包含有安全防护单元。
[0100]
一般的,非法用户恶意攻击数据收集装置是通过连续多次发起数据上传的方式实现的,例如,非法用户高频率上传上报数据,使得上报数据的流量短期内骤然增大,从而导致数据收集装置的数据传输、数据处理无法应对,出现数据传输溢出或是数据处理模块崩溃。针对该攻击模式,在步骤410的一种实现方式中,当第一ip地址的上报次数在单位时间内到达预设的上报数阈值时,在预设时长内不再响应第一ip地址的上报。
[0101]
具体的,在远程字典服务(remote dictionary server,redis)中维护上报次数。数据获取模块520中每个分布式服务组件(webserver组件)接收到的上报数据的上报,统一在redis中维护,当某一个ip的上报次数在单位时间内到达预设的上报数阈值后,即判定该ip进行恶意攻击。redis中将该ip记录在黑名单中,数据获取模块520中的所有分布式服务组件在预设的时间范围内不再响应该ip的上报。黑名单过期后,该ip可以正常上报。
[0102]
图8所示为根据本申请一实施例的方法部分流程图。如图8所示,在步骤410的一种实现方式中,针对来自第一ip地址:
[0103]
步骤810,更新第一ip地址单位时间内的上报数据的上报次数,例如,保存格式为<ip,次数>;
[0104]
步骤820,判断上报次数是否大于预设的上报数阈值;
[0105]
当上报次数大于预设的上报数阈值时,执行步骤821,添加第一ip地址到redis黑名单;
[0106]
当上报次数大于预设的上报数阈值时,执行步骤822,正常处理第一ip地址的上报数据。
[0107]
进一步的,非法用户还可以通过伪造上报数据的方式来恶意攻击数据收集装置。针对该攻击模式,在步骤410的一种实现方式中,需要对获取到的上报数据进行真伪性验证,只保留真伪性结果为真的上报数据进入到下一处理环节,而抛弃真伪性验证结果为伪的上报数据,从而阻止恶意用户的攻击,筛出伪造数据,避免伪造数据对数据传输以及数据处理产生不必要的流量压力。
[0108]
具体的,在步骤410的一种实现方式中,基于上报数据的头部令牌(token),验证上报数据的真伪性,包括:数据获取模块520的webserver组件从上报数据的token中提取时间,相比webserver组件当前时间超过3分钟(或者慢3分钟以上,3分钟可以配置),即认为token无效,丢弃该上报数据。时间验证正确后,取webserver组件配置的多个种子,根据规则,依次生成token。如果上报数据的token匹配webserver组件生成的token,则上报数据的真伪性验证结果为真;如果上报数据的token不匹配webserver组件生成的token,则上报数据的真伪性验证结果为伪。
[0109]
图9所示为根据本申请一实施例的方法部分流程图。如图9所示,在步骤410的一种实现方式中:
[0110]
步骤910,获取上报数据头部token的(指纹(md5)+时间戳);
[0111]
步骤920,判断时间戳与当前系统时间的间隔是否小于3分钟;
[0112]
如果判定结果为否,上报数据为无效数据,当前真伪性验证结束;
[0113]
如果判定结果为是,执行步骤930,获取数据获取模块的分布式组件的配置种子列表,设定i初始值为0;
[0114]
步骤931,判断当前是否遍历配置种子列表;
[0115]
如果判定结果为是,上报数据为无效数据,当前真伪性验证结束;
[0116]
如果判定结果为否,执行步骤940,提取配置种子列表中的第i个种子值,i=i+1;
[0117]
步骤950,根据时间戳+种子值生成新的指纹;
[0118]
步骤960,判断新的指纹与token中的旧指纹是否一致;
[0119]
如果一致,判定上报数据为有效数据,执行步骤970,正常处理上报数据;
[0120]
如果不一致,返回步骤931。
[0121]
进一步的,在实际应用场景中,针对大数据的分析处理,很多时候需要确定数据上报时间以及数据来源。但是,在终端设备将上报数据上报时,虽然很多上报数据携带有时间信息,但终端设备的物理环境无法保证上报数据携带的时间信息为上报时间,同时,也无法保证上报数据携带的时间信息是准确时间。进一步的,在很多应用场景下,终端设备无法获取自己的ip地址,上报数据中也就无法携带终端设备的ip地址。
[0122]
针对上述情况,在步骤410的一种实现方式中,在获取到上报数据后,由数据获取模块(webserver)为上报数据添加上报时间和/或上报ip地址。
[0123]
例如,原始上报数据为:
[0124]
{"id":12345,"name":"test","number":9000}。
[0125]
webserver接收到原始上报数据后获取上报时间"2019-10-17 10:00:00"以及上报该原始上报数据的终端设备的ip地址:"127.0.0.1"。webserver将原始上报数据末尾的"}"替换成",",添加时间,ip字符串到末尾,然后末尾添加"}",最终生成上报数据:
[0126]
{"id":12345,"name":"test","number":9000,"time":"2019-10-17 10:00:00","ip":"127.0.0.1"}。
[0127]
进一步的,kafka是由apache软件基金会开发的一个开源流处理平台,由scala和java编写。kafka是一种高吞吐量的分布式发布订阅消息系统,它可以处理消费者在网站中的所有动作流数据,并且,kafka支持分布式接入。因此,在本申请一实施例中,基于kafka平台构建分布式队列510。由于kafka基于磁盘的特点,加上其读写主要在管理文件偏移的特性。当流量高峰期到来时,分布式队列510的缓冲能力很强,并不耗费太多内存、以及处理器资源。同时,基于kafka平台构建的分布式队列510支持一次写、多次读,并且,相较于一次读,多次读并没有耗费太多性能。
[0128]
具体的,基于kafka平台构建的分布式队列510基于上报数据的主题/类型管理上报数据。具体的,在基于kafka平台构建的分布式队列510中,根据上报数据的类型,在kafka中创建对应的数据主题(topic),nginx节点不做其它处理,直接把上报数据的主体(body)主体写入对应topic。
[0129]
进一步的,为合理利用硬件资源,在本申请一实施例中,根据数据获取模块520以及数据获取模块520的节点数,设定基于kafka平台构建分布式队列510的分区数。具体的,设置分布式队列510的kafka分区数是数据获取模块520的nginx节点个数的6倍。每一个nginx节点连接上所有的kafka分区。
[0130]
进一步的,flume是cloudera提供的一个高可用的、高可靠的、分布式的海量日志采集、聚合和传输的系统。flume支持在日志系统中定制各类数据发送方,用于收集数据;同时,flume提供对数据进行简单处理,并写到各种数据接受方(可定制)的能力。因此,在本申请一实施例中,基于flume构建数据处理模块530。这样,不仅可以实现将数据从kafka取出,做过滤、清洗、合并、转化等以得到目标数据,而且在将目标数据写入数据库540时,数据处理模块530可以适配多种目标数据库。
[0131]
具体的,基于flume构造的数据处理模块中可以同时配置多个flume进程。在一个flume进程中,包含源模块(soure)、通道模块(channel)以及汇聚结点模块(sink)三类模块,source、sink都可以配置线程数。
[0132]
例如,图10所示为根据本申请一实施例的装置部分结构框图。如图10所示,为基于kafka平台构建的分布式队列中包含kafka集群1010,kafka集群1010包含kafka节点1011、1012、1013、1014。flume进程1020为基于flume构造的数据处理模块中配置的一个进程,配置flume进程1020的输入源为kafka集群1010,配置内存构建flume进程1020的channel模块,并且,在flume进程1020的输出sink中自定义上报数据的处理流程。
[0133]
flume进程1020包含source线程1021、source线程1022、source线程1023、source线程1024、channel1025、sink线程1026、sink线程1027、sink线程1028、sink线程1029。source线程1021、source线程1022、source线程1023、source线程1024将上报数据从kafka集群1010的kafka节点1011、1012、1013、1014中取出,经channel1025传输后由sink线程1026、sink线程1027、sink线程1028、sink线程1029处理,处理后生成的目标数据被sink线
程1026、sink线程1027、sink线程1028、sink线程1029写入到数据库1030。具体的,在实际应用场景中,可以根据实际需要配置输入源(kafka集群1010)与source线程之间的连接关系,例如,当source数量少于kafka节点数时,一个source会连接多个kafka分区,自动完成均衡。
[0134]
进一步的,在本申请的其他实施例中也可以基于其他平台/组件构建数据处理模块530。例如,logstash、spark、spark-stream、flink或者storm。进一步的,在本申请一实施例中,使用java代码构建数据处理模块530。
[0135]
一般的,对于一个技术的改进可以很明显地区分是硬件上的改进(例如,对二极管、晶体管、开关等电路结构的改进)还是软件上的改进(对于方法流程的改进)。然而,随着技术的发展,当今的很多方法流程的改进已经可以视为硬件电路结构的直接改进。设计人员几乎都通过将改进的方法流程编程到硬件电路中来得到相应的硬件电路结构。因此,不能说一个方法流程的改进就不能用硬件实体模块来实现。例如,可编程逻辑器件(programmable logic device,pld)(例如现场可编程门阵列(field programmable gate array,fpga))就是这样一种集成电路,其逻辑功能由访问方对器件编程来确定。由设计人员自行编程来把一个数字装置“集成”在一片pld上,而不需要请芯片制造厂商来设计和制作专用的集成电路芯片。而且,如今,取代手工地制作集成电路芯片,这种编程也多半改用“逻辑编译器(logic compiler)”软件来实现,它与程序开发撰写时所用的软件编译器相类似,而要编译之前的原始代码也得用特定的编程语言来撰写,此称之为硬件描述语言(hardware description language,hdl)。本领域技术人员也应该清楚,只需要将方法流程用上述几种硬件描述语言稍作逻辑编程并编程到集成电路中,就可以很容易得到实现该逻辑方法流程的硬件电路。
[0136]
因此,本申请实施例所提出的方法流程可以以硬件方式实现,例如,图5所示实施例的装置即为图4所示实施例的方法流程的一种硬件实现方式。又例如,使用控制器,控制器控制功能模块/设备以实现本申请实施例所提出的方法流程。
[0137]
进一步的,控制器可以按任何适当的方式实现,例如,控制器可以采取例如微处理器或处理器以及存储可由该(微)处理器执行的计算机可读程序代码(例如软件或固件)的计算机可读介质、逻辑门、开关、专用集成电路(application specific integrated circuit,应用服务器ic)、可编程逻辑控制器和嵌入微控制器的形式,控制器的例子包括但不限于以下微控制器:arc 625d、atmel at91sam、microchip pic18f26k20以及silicone labs c8051f320,存储器控制器还可以被实现为存储器的控制逻辑的一部分。本领域技术人员也知道,除了以纯计算机可读程序代码方式实现控制器以外,完全可以通过将方法步骤进行逻辑编程来使得控制器以逻辑门、开关、专用集成电路、可编程逻辑控制器和嵌入微控制器等的形式来实现相同功能。因此这种控制器可以被认为是一种硬件部件,而对其内包括的用于实现各种功能的装置也可以视为硬件部件内的结构。或者甚至,可以将用于实现各种功能的装置视为既可以是实现方法的软件模块又可以是硬件部件内的结构。
[0138]
进一步的,在本申请实施例的描述中,为了描述的方便,描述装置时以功能分为各种功能模块分别描述,各个功能模块的划分仅仅是一种逻辑功能的划分,在实施本申请实施例时可以把各功能模块的功能在同一个或多个软件和/或硬件中实现。具体的,本申请实施例所提出的装置在实际实现时可以全部或部分集成到一个物理实体上,也可以物理上分
开。装置的功能模块可以全部以软件通过处理元件调用的形式实现;也可以全部以硬件的形式实现;还可以部分模块以软件通过处理元件调用的形式实现,部分模块通过硬件的形式实现。
[0139]
进一步的,本申请一实施例还提出了一种电子设备,电子设备包括用于存储计算机程序指令的存储器和用于执行程序指令的处理器,其中,当该计算机程序指令被该处理器执行时,触发电子设备执行如本申请实施例所述的方法步骤。
[0140]
具体的,在本申请一实施例中,上述一个或多个计算机程序被存储在上述存储器中,上述一个或多个计算机程序包括指令,当上述指令被上述设备执行时,使得上述设备执行本申请实施例所述的方法步骤。
[0141]
具体的,在本申请一实施例中,电子设备的处理器可以是片上装置soc,该处理器中可以包括中央处理器(central processing unit,cpu),还可以进一步包括其他类型的处理器。例如,电子设备的处理器可以是pwm控制芯片。
[0142]
具体的,在本申请一实施例中,涉及的处理器可以例如包括cpu、dsp、微控制器或数字信号处理器,还可包括gpu、嵌入式神经网络处理器(neural-network process units,npu)和图像信号处理器(image signal processing,isp),该处理器还可包括必要的硬件加速器或逻辑处理硬件电路,如应用服务器ic,或一个或多个用于控制本申请技术方案程序执行的集成电路等。此外,处理器可以具有操作一个或多个软件程序的功能,软件程序可以存储在存储介质中。
[0143]
具体的,在本申请一实施例中,电子设备的存储器可以是只读存储器(read-only memory,rom)、可存储静态信息和指令的其它类型的静态存储设备、随机存取存储器(random access memory,ram)或可存储信息和指令的其它类型的动态存储设备,也可以是电可擦可编程只读存储器(electrically erasable programmable read-only memory,eeprom)、只读光盘(compact disc read-only memory,cd-rom)或其他光盘存储、光碟存储(包括压缩光碟、激光碟、光碟、数字通用光碟、蓝光光碟等)、磁盘存储介质或者其它磁存储设备,或者还可以是能够用于携带或存储具有指令或数据结构形式的期望的程序代码并能够由计算机存取的任何计算机可读介质。
[0144]
具体的,在本申请一实施例中,处理器可以和存储器可以合成一个处理装置,更常见的是彼此独立的部件,处理器用于执行存储器中存储的程序代码来实现本申请实施例所述方法。具体实现时,该存储器也可以集成在处理器中,或者,独立于处理器。
[0145]
本领域普通技术人员可以意识到,本申请实施例中描述的装置、模块、设备及方法步骤,能够以电子硬件、计算机软件和电子硬件的结合来实现。这些功能究竟以硬件还是软件方式来执行,取决于技术方案的特定应用和设计约束条件。专业技术人员可以对每个特定的应用来使用不同方法来实现所描述的功能,但是这种实现不应认为超出本申请的范围。所属领域的技术人员可以清楚地了解到,为描述的方便和简洁,上述描述的设备、装置的具体工作过程,可以参考前述方法实施例中的对应过程,在此不再赘述。
[0146]
进一步的,本领域内的技术人员应明白,本申请实施例可提供为方法、装置、设备或计算机程序产品。本申请实施例阐明的装置、模块、设备,具体可以由计算机芯片或实体实现,或者由具有某种功能的产品来实现。
[0147]
在本申请所提供的几个实施例中,任一功能如果以软件功能单元的形式实现并作
为独立的产品销售或使用时,可以存储在一个计算机可读取存储介质中。基于这样的理解,本申请的技术方案本质上或者说对现有技术做出贡献的部分或者该技术方案的部分可以以软件产品的形式体现出来,该计算机软件产品存储在一个存储介质中,包括若干指令用以使得一台计算机设备(可以是个人计算机,服务器,或者网络设备等)执行本申请各个实施例所述方法的全部或部分步骤。
[0148]
具体的,本申请一实施例中还提供一种计算机可读存储介质,该计算机可读存储介质中存储有计算机程序,当其在计算机上运行时,使得计算机执行本申请实施例提供的方法。
[0149]
本申请一实施例还提供一种计算机程序产品,该计算机程序产品包括计算机程序,当其在计算机上运行时,使得计算机执行本申请实施例提供的方法。
[0150]
本申请中的实施例描述是参照根据本申请实施例的方法、设备、装置和计算机程序产品的流程图和/或方框图来描述的。应理解可由计算机程序指令实现流程图和/或方框图中的每一流程和/或方框、以及流程图和/或方框图中的流程和/或方框的结合。可提供这些计算机程序指令到通用计算机、专用计算机、嵌入式处理机或其他可编程数据处理设备的处理器以产生一个机器,使得通过计算机或其他可编程数据处理设备的处理器执行的指令产生用于实现在流程图一个流程或多个流程和/或方框图一个方框或多个方框中指定的功能的装置。
[0151]
这些计算机程序指令也可存储在能引导计算机或其他可编程数据处理设备以特定方式工作的计算机可读存储器中,使得存储在该计算机可读存储器中的指令产生包括指令装置的制造品,该指令装置实现在流程图一个流程或多个流程和/或方框图一个方框或多个方框中指定的功能。
[0152]
这些计算机程序指令也可装载到计算机或其他可编程数据处理设备上,使得在计算机或其他可编程设备上执行一系列操作步骤以产生计算机实现的处理,从而在计算机或其他可编程设备上执行的指令提供用于实现在流程图一个流程或多个流程和/或方框图一个方框或多个方框中指定的功能的步骤。
[0153]
还需要说明的是,本申请实施例中,“至少一个”是指一个或者多个,“多个”是指两个或两个以上。“和/或”,描述关联对象的关联关系,表示可以存在三种关系,例如,a和/或b,可以表示单独存在a、同时存在a和b、单独存在b的情况。其中a,b可以是单数或者复数。字符“/”一般表示前后关联对象是一种“或”的关系。“以下至少一项”及其类似表达,是指的这些项中的任意组合,包括单项或复数项的任意组合。例如,a,b和c中的至少一项可以表示:a,b,c,a和b,a和c,b和c或a和b和c,其中a,b,c可以是单个,也可以是多个。
[0154]
本申请实施例中,术语“包括”、“包含”或者其任何其他变体意在涵盖非排他性的包含,从而使得包括一系列要素的过程、方法、商品或者设备不仅包括那些要素,而且还包括没有明确列出的其他要素,或者是还包括为这种过程、方法、商品或者设备所固有的要素。在没有更多限制的情况下,由语句“包括一个
……”
限定的要素,并不排除在包括所述要素的过程、方法、商品或者设备中还存在另外的相同要素。
[0155]
本申请可以在由计算机执行的计算机可执行指令的一般上下文中描述,例如程序模块。一般地,程序模块包括执行特定任务或实现特定抽象数据类型的例程、程序、对象、组件、数据结构等等。也可以在分布式计算环境中实践本申请,在这些分布式计算环境中,由
通过通信网络而被连接的远程处理设备来执行任务。在分布式计算环境中,程序模块可以位于包括存储设备在内的本地和远程计算机存储介质中。
[0156]
本申请中的各个实施例均采用递进的方式描述,各个实施例之间相同相似的部分互相参见即可,每个实施例重点说明的都是与其他实施例的不同之处。尤其,对于装置实施例而言,由于其基本相似于方法实施例,所以描述的比较简单,相关之处参见方法实施例的部分说明即可。
[0157]
以上所述,仅为本申请的具体实施方式,任何熟悉本技术领域的技术人员在本申请揭露的技术范围内,可轻易想到变化或替换,都应涵盖在本申请的保护范围之内。本申请的保护范围应以所述权利要求的保护范围为准。
相关技术
网友询问留言
已有0条留言
- 还没有人留言评论。精彩留言会获得点赞!
1