一种短时海洋鱼群和鱼量的预测方法与流程
[0001]
本发明涉及海洋渔业领域,具体涉及一种短时海洋鱼群和鱼量的预测方法。
背景技术:
[0002]
海洋渔业资源在人类生存和发展中起着不可替代的作用,是现代社会主要经济活动的一部分。但随着捕捞区域的扩大和超出渔业资源再生速度的高强度捕捞,近海渔业资源环境遭到严重破坏,海洋渔业资源岌岌可危。为了维持渔业资源和环境的可持续发展,其中最重要的一点就是实现渔业资源的合理配置,保障适度捕捞。而未来渔业资源的合理预测则对于进行以上工作具有重要的意义。
[0003]
预测未来的鱼群的位置与鱼量,需要有关的历史数据,但是由于海洋中的传感器的数量相对较少,无法获得海洋中准确的鱼群位置与数量,且每艘渔船的捕捞量对于各公司也都是保密的,这给鱼群预测带来了极大的挑战。因此,以往的研究仅从长远的角度探索海洋渔业资源的变化趋势与鱼群的迁徙状况,但该视角的时间跨度很长,往往以年为单位,对于现时的指导意义并不大。此外,有研究者通过渔船的行驶轨迹来预测未来捕鱼区域。从公开的ais渔船轨迹数据集着手,需要从轨迹中尽可能准确地提取出渔船作业区域。目前,对于渔船作业状态(停泊、行驶、捕鱼)的识别多采用基于规则的方法(如基于速度阈值、角度阈值的方法)和基于密度的聚类方法(如dbscan算法)。由于渔船在驶离港口时载有燃油、食物等,而在返回港口时又满载鱼类,这就导致渔船的行驶速度较为缓慢,基于速度的方法很难过滤掉近港区域的轨迹点。渔船在进行捕鱼时,渔船的行驶方向往往会不断变化,基于角度阈值的方法可以获取捕鱼区域,但该方法需设置多个参数,如角度阈值,最小持续时间(过滤掉角度变化大,但并没有持续很长时间的轨迹点),最大容忍时间(两个大于角度阈值的轨迹点的时间差若小于该容忍时间,则将这两点之间的所有轨迹点置为作业状态点),参数的设置会对结果产生重大的影响。传统的dbscan聚类算法在单次出海轨迹聚类中取得了较好的效果,但该方法需要首先划分渔船的单次出海轨迹。由于传统的dbscan算法没有将时间考虑在内,若是选取的时间段内包含多次渔船出海轨迹,那么就会导致港口附近轨迹密集,从而形成错误的聚类。
技术实现要素:
[0004]
针对现有技术存在的海洋短时鱼群和鱼量无法有效预测的问题,本发明提供了一种短时海洋鱼群和鱼量的预测方法。
[0005]
本发明采用以下的技术方案:
[0006]
一种短时海洋鱼群和鱼量的预测方法,包括以下步骤:
[0007]
步骤1:选取海洋中要预测的区域,获得该区域的所有渔船轨迹数据并进行预处理;
[0008]
步骤2:利用3d-dbscan聚类算法对预处理后的渔船轨迹数据进行聚类获得捕鱼点,将捕鱼点投影到栅格矩阵进行数据的格式转换;
[0009]
步骤3:搭建残差网络模型,将转换后的栅格矩阵数据分为训练集和测试集,将训练集送入残差网络模型进行模型的训练;
[0010]
步骤4:测试集送入训练好的残差网络模型进行验证,最终得到短时海洋鱼群和鱼量的预测模型。
[0011]
优选地,步骤1中的所有渔船轨迹数据为所有渔船完整的轨迹数据。
[0012]
优选地,3d-dbscan聚类算法对预处理后的渔船轨迹数据进行聚类获得捕鱼点的具体过程为:
[0013]
步骤2.1:设定3d-dbscan聚类算法用参数:eps、minpts和t,其中,eps为扫描半径,minpts为最小包含点数,t为扫描最小时间间隔;
[0014]
步骤2.2:对一条渔船在单位时间长度内的渔船轨迹数据进行聚类,任选一个未被访问的点为出发点,找出与出发点距离在小于等于eps之内的所有附近点,如果附近点的数量≥minpts,且附近点与出发点的时间间隔小于t,则出发点与其附近点形成一个簇,并且出发点被标记为已访问,然后递归,以相同的方法处理该簇内所有未被标记为已访问的点,从而对簇进行扩展;如果簇充分地被扩展,即簇内的所有点被标记为已访问,然后用同样的算法去处理簇外未被访问的点,最终形成多个有用簇;
[0015]
步骤2.3:对所有渔船在单位时间长度内的渔船轨迹数据利用步骤2.2进行聚类,得到所有渔船轨迹数据聚类后的有用簇,有用簇内的点即为捕鱼点。
[0016]
优选地,将预测的区域划分为(i
×
j)个栅格,将获得的捕鱼点在(i
×
j)个栅格中进行投影,求得在第t天在第(i
×
j)栅格区域内渔船捕鱼的总时间间接代表栅格区域内的鱼量多少;进而得到在第t天所有栅格区域的鱼量多少情况x
t
;
[0017][0018]
进而得到总天数内的栅格区域的鱼量多少情况(x1,x2,
…
,x
t
)。
[0019]
优选地,步骤3具备包括以下步骤:
[0020]
步骤3.1:将总天数内的栅格区域的鱼量多少情况(x1,x2,
…
,x
t
)进行划分,每连续k天为一组,用每连续k天为一组的数据输入残差网络模型预测出接下来一天的数据,这样就能得到总的数据集为[t-k,k,i,j],其中选取80%作为训练集,20%作为测试集,将数据归一化到[-1,1]区间;
[0021]
步骤3.2:设定残差网络模型的输入,残差网络模型的输入包括训练集和外部因素数据,外部因素数据包括海洋的温、盐数据;用代表训练集中连续k天为一组的数据,输入残差网络模型的第一层卷积层后变为:
[0022][0023]
其中,*为卷积操作,w
(1)
和b
(1)
表示在第一层卷积中的权重和偏置系数;
[0024]
外部因素获取:
[0025]
由于只能获得每个栅格区域的四个角坐标点处的温、盐数据,所以将每个栅格的四个角坐标点处的温、盐数据经过一层均值池化层,得到四个角坐标中温、盐数据的平均值,用平均值来表示对应栅格区域的温、盐数据值;
[0026]
e表示外部因素的输入,即栅格区域的温、盐数据值;
[0027]
则经过均值池化层与卷积层后变为:
[0028]
e
(1)
=f
卷积
(f
均值池化
(e))
[0029]
步骤3.3:再将与e
(1)
在一层卷积层进行融合,得到融合后的数据y0,y0作为残差块的输入:
[0030][0031]
步骤3.4:由于残差学习单元允许原始输入的信息直接传输到后层的执行机构,因此可以搭建深层网络;在这项工作中,每个残差块由卷积层和线性整流单元组成,第l个残差块的输出为:
[0032]
y
l
=f
残差
(y
l-1
;θ
l
)+y
l-1
,l=1,
…
,l
[0033]
其中f
残差
为残差函数,表示为两个线性整流单元和两个卷积层的叠加,θ
l
表示第l个残差块的所有可训练参数,l为残差块的个数。y
l-1
与y
l
分别表示第l个残差块的输入与输出;
[0034]
y
l
在经过只有一个卷积核的卷积层,最后再通过tanh激活层将结果映射到[-1,1],这样就得到了连续k天后接下来一天的鱼量预测的结果
[0035]
采用均方误差mse来衡量预测值与真实值之间的差距;
[0036][0037]
其中,n为栅格区域的总个数,g
(i,j)
为通过渔船轨迹所获取的(i,j)区域的真实值,为(i,j)区域的预测值;
[0038]
步骤3.5:利用训练集和外部因素数据一直训练残差网络模型,直到残差网络模型中的参数达到最优,均方误差mse得到的预测值与真实值之间的差距最小。
[0039]
优选地,步骤4具体包括:
[0040]
将测试集送入训练好的模型进行测试,测试完成后就能得到短时海洋鱼群和鱼量的预测模型:
[0041][0042]
其中,模型中的参数均已通过训练求得最优;
[0043]
通过短时海洋鱼群和鱼量的预测模型就能在输入要预测天之前的连续k天的栅格区域的鱼量多少情况下,得到要预测天的栅格区域中的鱼量分布情况。
[0044]
本发明具有的有益效果是:
[0045]
本发明提供的短时海洋鱼群和鱼量的预测方法,通过挖掘渔船轨迹数据,从而获取渔船进行捕鱼活动的轨迹点,这里利用了全新的3d-dbscan聚类算法,将时间因素考虑在内,从而避免了一些错误的聚类,可以在不划分渔船单次出海轨迹的情况下完成捕鱼点的提取,获得的捕鱼点更加准确。原始的轨迹序列数据不能直观的表现出鱼群的时空分布状况,且不容易被神经网络提取时空依赖性。因此将海域进行栅格区域划分,将取得的捕鱼轨迹点在该海域进行投影,同时以渔船在每一栅格区域内的作业总时间来表示该区域鱼量的
多少。这样原始的序列数据就转换为了栅格矩阵形式,转换后的数据更容易被神经网络所接受,并且能更加直观地表现鱼群的时空分布状况。在捕获空间依赖性上,卷积网络具有明显的优越性,同时为了搭建深层的网络,本发明选取的残差网络这一特殊的卷积网络,模型的结构简单,参数较少,训练、预测时间短且准确率高。同时,海洋温、盐会对鱼群的时空分布产生影响,本发明通过加入海洋温、盐数据,使得预测的准确度进一步提高,最终得到短时海洋鱼群和鱼量的预测模型,利用短时海洋鱼群和鱼量的预测模型就可以对短时间内的栅格区域内是否有鱼群及鱼群数量进行预测。
附图说明
[0046]
图1为实施例1中一艘渔船一次出海的轨迹聚类图。
[0047]
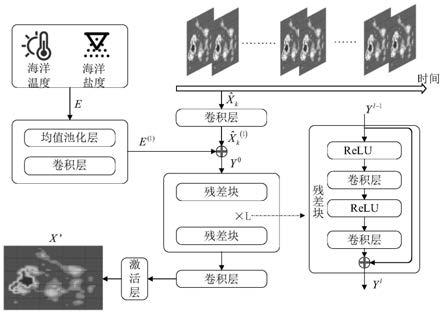
图2为残差网络模型的结构图。
具体实施方式
[0048]
下面结合附图和具体实施例对本发明的具体实施方式做进一步说明:
[0049]
实施例1
[0050]
结合图1和图2,一种短时海洋鱼群和鱼量的预测方法,包括以下步骤:
[0051]
步骤1:选取海洋中要预测的区域,获得该区域的所有渔船轨迹数据并进行预处理。
[0052]
上述所有渔船轨迹数据为所有渔船完整的轨迹数据。
[0053]
在该实施例中,该预测的区域范围为:经度:121
°
e~128
°
e,纬度:28
°
n~34
°
n。
[0054]
选取的是该预测的区域内所有的渔船1年时间内完整的轨迹数据。
[0055]
步骤2:利用3d-dbscan聚类算法对预处理后的渔船轨迹数据进行聚类获得捕鱼点,将捕鱼点投影到栅格矩阵进行数据的格式转换。
[0056]
3d-dbscan聚类算法的概念是在传统的dbcsan算法中加入了时间参数,原因在于:
[0057]
1、在一年时间范围内,一艘渔船往往有多次出海轨迹,这就会使港口附近轨迹重叠,导致轨迹点密度增加,从而形成错误的聚类。
[0058]
2、一艘渔船的一次出海轨迹会存在轨迹重叠,导致出现错误的聚类。
[0059]
下面用一个例子进行说明,如图1为一艘渔船一次出海的轨迹,利用传统的dbscan算法将eps设为圆的半径,minpts设置为3,可以得到两个停留点的聚类。但是会发现,聚类1是一个错误的聚类,原因在于仅仅考虑了点之间的平面距离,而没有考虑时间。聚类1中两个实心点与两个空心点在时间上并不是联系的。
[0060]
而3d-dbscan聚类算法将时间考虑在内,给定扫描最小时间间隔t,若两点间的时间间隔大于t,且不能够通过它点连续可达,那么这两点将不能成簇。即聚类1中的实心点和空心点将不会被聚为一类,只有聚类2是正确的。
[0061]
由此,3d-dbscan聚类算法就可以将一条渔船在单位时间长度内的渔船轨迹数据进行很好的聚类,去掉了港口出多次出海轨迹带来的错误聚类,也去掉了单次出海轨迹重叠带来的错误聚类,能在不划分渔船单次出海轨迹的情况下完成捕鱼点的提取。
[0062]
具体包括:
[0063]
步骤2.1:设定3d-dbscan聚类算法用参数:eps、minpts和t,其中,eps为扫描半径,
minpts为最小包含点数,t为扫描最小时间间隔;
[0064]
在本实施例中,由于渔船在正常行驶的情况下,速度大于10节/小时,即18.52千米/小时。轨迹数据的采样点时间间隔为1分钟,两个采样点之间的距离间隔大于308米。因此将这一距离值作为扫描半径eps。航行状态下,以308为扫描半径的区域圆中将最多包含3个点,而在渔船处于捕鱼状态时,轨迹点数会大于3,因此将3作为临界值,通过逐次增加点数与可视化结果分析得到最佳minpts等于7。对于时间间隔t的设置,由于渔船出海捕鱼往往以天为单位,同时渔船回港,卸载、整休再到下次出海也会间隔几天,因此将时间间隔设置为一天,即24小时。
[0065]
步骤2.2:对一条渔船在1年时间长度内的渔船轨迹数据进行聚类,任选一个未被访问的点为出发点,找出与出发点距离在小于等于eps之内的所有附近点,如果附近点的数量≥minpts,且附近点与出发点的时间间隔小于t,则出发点与其附近点形成一个簇,并且出发点被标记为已访问,然后递归,以相同的方法处理该簇内所有未被标记为已访问的点,从而对簇进行扩展;如果簇充分地被扩展,即簇内的所有点被标记为已访问,然后用同样的算法去处理簇外未被访问的点,最终形成多个有用簇;
[0066]
步骤2.3:对所有渔船在单位时间长度内的渔船轨迹数据利用步骤2.2进行聚类,得到所有渔船轨迹数据聚类后的有用簇,有用簇内的点即为捕鱼点。
[0067]
捕鱼点获取后,为了描述鱼群位置与数量的时空分布,同时能更好的利用神将网络提取时空特征,本实施例中将预测的区域海域划分为(24
×
28)个栅格,每个栅格的精度为0.25
°×
0.25
°
。
[0068]
将获得的捕鱼点在(24
×
28)个栅格中进行投影,求得在第t天在第(i
×
j)栅格区域内渔船捕鱼的总时间间接代表栅格区域内的鱼量多少;进而得到在第t天所有栅格区域的鱼量多少情况x
t
;
[0069][0070]
进而得到总天数内的栅格区域的鱼量多少情况(x1,x2,
…
,x
t
)。
[0071]
在本实施例中捕鱼的总天数为200,即t的最大取值为200。
[0072]
步骤3:搭建残差网络模型,将转换后的栅格矩阵数据分为训练集和测试集,将训练集送入残差网络模型进行模型的训练。
[0073]
步骤3.1:将总天数内的栅格区域的鱼量多少情况(x1,x2,
…
,x
t
)进行划分,每连续k天为一组,用每连续k天为一组的数据输入残差网络模型预测出接下来一天的数据,这样就能得到总的数据集为[t-k,k,i,j],其中选取80%作为训练集,20%作为测试集,为了加快训练,将数据归一化到[-1,1]区间。
[0074]
在本实施例中,k=3,即以连续3天的鱼量多少情况数据为一组数据。例如,用第1到第3天的鱼量多少情况数据预测第4天的鱼量多少情况数据,用第2天到第4天的鱼量多少情况数据预测第5天的鱼量多少情况数据,依次类推,直到用第197天至199天的鱼量多少情况数据预测第200天的鱼量多少情况数据,总计197组数据。
[0075]
上述每组数据有(3
×
24
×
28)的张量。
[0076]
步骤3.2:设定残差网络模型的输入,残差网络模型的输入包括训练集和外部因素数据,外部因素数据包括海洋的温、盐数据。已有的研究表明,海洋温度、盐度会对鱼群的分
布产生影响,因此本发明考虑了海洋温度和盐度两种外部因素。
[0077]
用代表训练集中连续k天为一组的数据,输入残差网络模型的第一层卷积层后变为:
[0078][0079]
其中,*为卷积操作,w
(1)
和b
(1)
表示在第一层卷积中的权重和偏置系数。
[0080]
外部因素获取:
[0081]
由于只能获得每个栅格区域的四个角坐标点处的温、盐数据,所以将每个栅格的四个角坐标点处的温、盐数据经过一层均值池化层,得到四个角坐标中温、盐数据的平均值,用平均值来表示对应栅格区域的温、盐数据值。
[0082]
e表示外部因素的输入,即栅格区域的温、盐数据值;
[0083]
则经过均值池化层与卷积层后变为:
[0084]
e
(1)
=f
卷积
(f
均值池化
(e))
[0085]
步骤3.3:再将与e
(1)
在一层卷积层进行融合,得到融合后的数据y0,y0作为残差块的输入:
[0086][0087]
其中+为张量的拼接操作,即将(3
×
24
×
28)的轨迹数据与(2
×
24
×
28)的外部因素数据拼接为(5
×
24
×
28)的张量。
[0088]
步骤3.4:由于残差学习单元允许原始输入的信息直接传输到后层的执行机构,因此可以搭建深层网络;在这项工作中,每个残差块由卷积层和线性整流单元(relu)组成,第l个残差块的输出为:
[0089]
y
l
=f
残差
(y
l-1
;θ
l
)+y
l-1
,l=1,
…
,l
[0090]
其中f
残差
为残差函数,表示为两个线性整流单元(relu)和两个卷积层的叠加,θ
l
表示第l个残差块的所有可训练参数,l为残差块的个数。y
l-1
与y
l
分别表示第l个残差块的输入与输出。
[0091]
因为需要的输出为(24
×
28)的张量,即接下来一天内的栅格区域的鱼量多少情况,y
l
再经过只有一个卷积核的卷积层,最后再通过tanh激活层将结果映射到[-1,1],这样就得到了连续k天后接下来一天的鱼量预测的结果
[0092]
采用均方误差mse来衡量预测值与真实值之间的差距;
[0093][0094]
其中,n为栅格区域的总个数,g
(i,j)
为通过渔船轨迹所获取的(i,j)区域的真实值,为(i,j)区域的预测值;
[0095]
步骤3.5:利用训练集和外部因素数据一直训练残差网络模型,直到残差网络模型中的参数达到最优,均方误差mse得到的预测值与真实值之间的差距最小。
[0096]
步骤4:测试集送入训练好的残差网络模型进行验证,最终得到短时海洋鱼群和鱼量的预测模型。
[0097]
测试完成后就能得到短时海洋鱼群和鱼量的预测模型:
[0098][0099]
其中,模型中的参数均已通过训练求得最优;
[0100]
通过短时海洋鱼群和鱼量的预测模型就能在输入要预测天之前的连续k天的栅格区域的鱼量多少情况下,得到要预测天的栅格区域中的鱼量分布情况。
[0101]
当然,上述说明并非是对本发明的限制,本发明也并不仅限于上述举例,本技术领域的技术人员在本发明的实质范围内所做出的变化、改型、添加或替换,也应属于本发明的保护范围。
相关技术
网友询问留言
已有0条留言
- 还没有人留言评论。精彩留言会获得点赞!
1