一种保证分布式存储系统服务器端读尾延迟的方法及系统与流程
1.本发明涉及分布式存储系统技术领域,尤其是保证延迟敏感型应用低尾延迟需求技术领域。
背景技术:
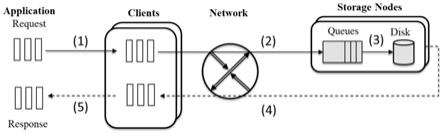
2.分布式存储系统采取典型的客户端-服务器(client-server)模型。访问分布式存储系统的请求处理过程为:(1)应用(application)请求访问分布式存储系统的客户端;(2)客户端将请求通过网络发送给服务器;(3)服务器从网络上接受请求并开始处理,请求到达服务器后会首先进入队列中排队,若有空闲线程,则会从队列中取请求并进行处理;(4)请求在服务器端被处理完成后,其响应将通过网络发送给客户端;(5)客户端接收到请求的响应后将其发送给应用。至此,一个请求就被处理完成,如图1所示。上述步骤(3)中在服务器端对请求的处理过程复杂,同时涉及到请求排队,线程处理,存储访问等。服务器端从网络上接收请求后,将请求放入到相应的队列上,服务器端的请求队列可采取单队列或多队列模式,真正处理请求是存储节点上的io线程。线程根据不同出队策略从队列上取请求并进行处理,请求处理过程中会访问存储设备获取响应,最终将响应经网络发送给客户端。线程在同一时刻只能处理一个请求,一个请求处理完成后才能处理下一个请求。
3.部署在分布式存储系统上的延迟敏感型应用(latency-sensitive application)需要保证其尾延迟slo。为避免多个延迟型应用由于资源竞争产生干扰,而对尾延迟造成影响,最简单的方法是在存储系统上单独部署该类应用,使其独占系统资源,或者按照其峰值压力为其预分配系统资源,以保证其尾延迟需求能够被满足。很显然,这导致系统资源不能被充分利用,利用率较低,相关研究表明:数据中心存储系统资源利用率介于10%~45%之间。存储系统通常是大规模部署的,涉及成百上千个服务节点,如此低的资源利用率将消耗巨大的资本和运营成本。为提高存储系统资源利用率,将多种延迟型应用混合部署,势必会竞争存储资源,继而对尾延迟产生影响。
4.因此,目前有大量工作围绕“针对多种延迟型应用混合部署在分布式存储系统中时,如何高效地管理存储节点所提供的吞吐量资源并采取合适的应用准入控制,在满足多种应用差异化的高百分位尾延迟slo需求的前提下,尽可能多地处理应用请求,以提高系统资源利用率”进行展开:
5.(1)一种反馈式的存储节点线程分配方法cake。cake每隔固定的时间间隔(如10s)对线程资源进行调整,根据上一个时间间隔内应用的尾延迟slo与目标slo的比值,优先使用按比例共享策略来设定线程服务不同应用的请求,经过调整后,若按比例共享策略仍不能满足目标slo需求,则会采取预留策略,也即为应用预留单独的线程,其余线程仍为共享线程。
6.(2)一种反馈式的客户端限流方法pslo。pslo每隔固定的时间间隔(如10s)统计应用请求延迟满足尾延迟slo的概率,如果该概率低于应用要求的尾延迟slo的概率,则对该应用以及与该应用有着相同的目标存储节点的应用进行限流。通过在客户端降低应用的发
送iodepth来达到限流的效果,待统计的应用请求延迟满足尾延迟slo的概率高于应用要求的尾延迟slo的概率之后,再不断降低对应用的限流程度。
7.(3)一种先验式存储节点优先级调度方法prioritymeister。prioritymeister首先基于应用提供的具有代表性的trace分析应用的负载特征,根据存储节点所提供的平均吞吐量,预测每个应用在不同优先级下的请求最大延迟,如果预测的延迟不超过应用的尾延迟slo,则允许该应用按照设定的优先级接入系统。通过预先不断调整应用的优先级,来寻找允许接入应用数量最多的优先级配置。prioritymeister分析应用的负载特征基于漏桶(leaky token bucket),延迟预测方法基于network calculus。
8.(4)一种先验式的存储节点优先级调度方法snc-meister。snc-meister首先基于应用提供的具有代表性的trace分析应用的负载特征,根据存储节点所提供的平均吞吐量,预测每个应用在预分配的优先级下的请求百分位延迟,如果预测的百分位延迟不超过应用的尾延迟slo,则允许该应用按照预分配的优先级接入系统。应用的尾延迟slo的要求越高,则为该应用分配的优先级越高。snc-meister分析应用的负载特征基于markov-modulated poisson process,延迟预测方法基于stochastic network calculus。
9.(5)一种先验式的存储节点固定服务速率限流方法silo。silo首先基于应用提供的具有代表性的trace分析应用的负载特征,根据存储节点所提供的平均吞吐量,预测每个应用在预分配的服务速率下的请求百分位延迟,如果预测的最大延迟不超过应用的尾延迟slo,则允许该应用按照预分配的服务速率接入系统。silo分析应用的负载特征基于漏桶(leaky token bucket),延迟预测方法基于network calculus。
10.应用的负载大小随着时间是不断变化的。现有的先验式资源管理策略如prioritymeister、snc-meister和silo均静态地分配资源,不能精准地切合应用不断变化的负载,造成了较高的资源超量配置。而反馈式资源管理策略如cake和silo虽然可以周期性地分配资源,但这些方法无法预见到应用突发流量(trace)的产生,由于从收集信息、反馈到最终决策中间的延迟较长,将可能导致应用的延迟slo被违反,因此只能保证百分位较低(如95th)的延迟slo。
技术实现要素:
11.本发明的目的是解决上述现有技术中资源分配的可预测性与资源分配的灵活性之间的矛盾而导致保证多应用差异化尾延迟slo的工作系统资源利用率低的问题,提出了一种基于动态可预测资源管理机制的应用准入控制方法。本发明要保证的延迟slo指的就是百分位延迟。例如99百分位延迟,假设应用共发送了1000个请求,将所有请求的延迟按照从低到高排序,则第990个请求的延迟即为99百分位延迟(1000*99%=990)。
12.针对现有技术的不足,本发明提出一种保证分布式存储系统服务器端读尾延迟的方法,其中包括:
13.步骤1、根据应用的负载特征与延迟需求,将分布式存储系统中每一个应用分类为服务可延后的pt应用或服务不可延后pi应用;
14.步骤2、根据预设保证延迟值,计算pt应用借出的最大资源数量;
15.步骤3、pi应用所获得的服务速率为其平均发送速率,计算百分位延迟发生时的排队请求数量pqd_avg=pql_avg*ar_avg。pi应用延迟slo不被违反,百分位延迟发生时的排
队请求数量最大值pqd_slo=slo*ar_avg,ar_avg为应用的请求平均发送速率,pql_avg为百分位排队延迟,slo为应用的延迟需求,通过pqd_avg减去pqd_slo,得到pi应用借用的资源数量最大值qd_reduce;
16.步骤4、根据pi应用借用相同资源所获得的收益大小,为各pi应用借用资源的优先级;
17.步骤5、设最小服务速率为pi应用的平均发送速率ar_avg,最大服务速率为该pi应用的最大发送速率ar_max,设pi应用借用的资源数量为qd_reduce,通过二分查找,找到使借用资源后的百分位延迟pql_borrowed=(pqd_sr_borrowed-qd_reduce)/sr_borrowed,以得到pi应用借用资源后所需的平均服务速率;
18.步骤6、根据pi应用借用资源的优先级和pi应用借用的资源数量最大值和每个pt应用借出的最大资源数量,通过动态规划的方法为当前pi应用分配多个pt应用,每次匹配后,从pt应用集合中剔除已匹配的pt应用,直到每个pi应用均借到资源或者pt应用全部匹配完毕;
19.步骤7、已匹配应用组合的总服务速率为pi应用借用资源后的预分配服务速率与应用组合中pt应用各平均发送速率之和;
20.步骤8、pi应用与其相匹配的pt应用共享该总服务速率,为每个pi应用以及与其相匹配的pt应用分配独立的队列,为应用组合中pi应用和各pt应用分配相应服务速率,并监控pt应用因出借资源造成的额外请求排队数量qd_add,当qd_add小于最大资源数量时,pi应用的服务优先级高于pt应用,允许该pi应用借用该pt应用的资源,当qd_add与最大资源数量相同时,该pt应用的服务优先级高于pi应用,为pt应用预留与pt应用的平均发送速率相同的服务速率,若pi应用的请求发送速率低于pi应用的平均发送速率,则剩余的服务速率用于服务pt应用;
21.步骤9、应用接入分布式存储系统的存储节点时,为其分配一个队列,并根据存储节点当前的虚拟时间戳为队列分配虚拟时间戳ts
i
,为该应用的队列分配一个时间戳增加间隔ti
i
,ti
i
为预分配服务速率的倒数,对分布式存储系统中所有应用的时间戳进行排序,io线程空闲后查找拥有最小时间戳的队列从中取出请求,并增加该最小时间戳的队列的时间戳ts
i
=ts
i
+ti
i
。
22.所述的保证分布式存储系统服务器端读尾延迟的方法,其中还包括:
23.步骤10、pt应用接入该存储节点时,为pt应用的队列设定可借出资源数量初值为该最大资源数量qd_add_max;当io线程空闲后查找拥有最小时间戳的队列,若该队列归属于pt应用,增加该队列的时间戳tsi=tsi+tii,并读取可借出资源数量;若可借出资源数量大于0且对应的pi队列不为空,将pt应用的可借出资源数量减1,取出pi应用的请求进行服务;若可借出资源数量大于0且对应的pi队列为空,则取出pt队列中的请求服务,pt应用的借出资源数量不变;若可借出资源数量等于0,则取出pt队列中的请求进行服务,pt应用的可借出资源数量不变。
24.所述的保证分布式存储系统服务器端读尾延迟的方法,其中还包括:
25.步骤11、当io线程空闲后查找拥有最小时间戳的队列,若该队列归属于pi应用,修改该队列的时间戳,并读取该队列中请求的数量;若该队列不为空,则从该队列中读取请求服务;若该队列为空,则从所有pt应用中寻找可借出资源数量最小的pt队列,从该pt队列中
取出请求服务,并将该pt队列的可借出资源数量加1。
26.所述的保证分布式存储系统服务器端读尾延迟的方法,其中该步骤1包括:
27.每个应用提供一个代表其负载特征的请求轨迹,将该请求轨迹中请求发送总量与请求发送的持续时间的比值作为该应用的请求平均发送速率ar_avg,设该应用获得的请求服务速率与请求的平均发送速率相同为ar_avg,计算百分位排队延迟pql_avg,该百分位与应用延迟slo的百分位相同,该请求轨迹提供请求入队的时间间隔,ar_avg提供请求出队的时间间隔,以计算该请求轨迹中所有请求的排队延迟,将延迟从低到高进行排序,计算百分位延迟。比较pql_avg与该应用的延迟slo,如果pql_avg大于等于slo,则该应用为pi应用,否则该应用为pt应用。
28.所述的保证分布式存储系统服务器端读尾延迟的方法,其中该步骤2包括:
29.pt应用被延后服务的时间postponement=slo-pql_avg,pt应用借出的最大资源数量为pt应用因资源出借而增加的排队请求数量qd_add_max=postponement*ar_avg。
30.本发明还提供了一种保证分布式存储系统服务器端读尾延迟的系统,其中包括:
31.模块1、用于根据应用的负载特征与延迟需求,将分布式存储系统中每一个应用分类为服务可延后的pt应用或服务不可延后pi应用;
32.模块2、用于根据预设保证延迟值,计算pt应用借出的最大资源数量;
33.模块3、用于根据pi应用所获得的服务速率为其平均发送速率,计算百分位延迟发生时的排队请求数量pqd_avg=pql_avg*ar_avg。pi应用延迟slo不被违反,百分位延迟发生时的排队请求数量最大值pqd_slo=slo*ar_avg,ar_avg为应用的请求平均发送速率,pql_avg为百分位排队延迟,slo为应用的延迟需求,通过pqd_avg减去pqd_slo,得到pi应用借用的资源数量最大值qd_reduce;
34.模块4、用于根据pi应用借用相同资源所获得的收益大小,为各pi应用借用资源的优先级;
35.模块5、用于将最小服务速率设为pi应用的平均发送速率ar_avg,最大服务速率为该pi应用的最大发送速率ar_max,设pi应用借用的资源数量为qd_reduce,通过二分查找,找到使借用资源后的百分位延迟pql_borrowed=(pqd_sr_borrowed-qd_reduce)/sr_borrowed,以得到pi应用借用资源后所需的平均服务速率;
36.模块6、用于根据pi应用借用资源的优先级和pi应用借用的资源数量最大值和每个pt应用借出的最大资源数量,通过动态规划的方法为当前pi应用分配多个pt应用,每次匹配后,从pt应用集合中剔除已匹配的pt应用,直到每个pi应用均借到资源或者pt应用全部匹配完毕;
37.模块7、用于将已匹配应用组合的总服务速率设为pi应用借用资源后的预分配服务速率与应用组合中pt应用各平均发送速率之和;
38.模块8、用于根据pi应用与其相匹配的pt应用共享该总服务速率,为每个pi应用以及与其相匹配的pt应用分配独立的队列,为应用组合中pi应用和各pt应用分配相应服务速率,并监控pt应用因出借资源造成的额外请求排队数量qd_add,当qd_add小于最大资源数量时,pi应用的服务优先级高于pt应用,允许该pi应用借用该pt应用的资源,当qd_add与最大资源数量相同时,该pt应用的服务优先级高于pi应用,为pt应用预留与pt应用的平均发送速率相同的服务速率,若pi应用的请求发送速率低于pi应用的平均发送速率,则剩余的
服务速率用于服务pt应用;
39.模块9、用于应用接入分布式存储系统的存储节点时,为其分配一个队列,并根据存储节点当前的虚拟时间戳为队列分配虚拟时间戳ts
i
,为该应用的队列分配一个时间戳增加间隔ti
i
,ti
i
为预分配服务速率的倒数,对分布式存储系统中所有应用的时间戳进行排序,io线程空闲后查找拥有最小时间戳的队列从中取出请求,并增加该最小时间戳的队列的时间戳ts
i
=ts
i
+ti
i
。
40.所述的保证分布式存储系统服务器端读尾延迟的系统,其中还包括:
41.模块10、用于pt应用接入该存储节点时,为pt应用的队列设定可借出资源数量初值为该最大资源数量qd_add_max;当io线程空闲后查找拥有最小时间戳的队列,若该队列归属于pt应用,增加该队列的时间戳tsi=tsi+tii,并读取可借出资源数量;若可借出资源数量大于0且对应的pi队列不为空,将pt应用的可借出资源数量减1,取出pi应用的请求进行服务;若可借出资源数量大于0且对应的pi队列为空,则取出pt队列中的请求服务,pt应用的借出资源数量不变;若可借出资源数量等于0,则取出pt队列中的请求进行服务,pt应用的可借出资源数量不变。
42.所述的保证分布式存储系统服务器端读尾延迟的系统,其中还包括:
43.模块11、用于当io线程空闲后查找拥有最小时间戳的队列,若该队列归属于pi应用,修改该队列的时间戳,并读取该队列中请求的数量;若该队列不为空,则从该队列中读取请求服务;若该队列为空,则从所有pt应用中寻找可借出资源数量最小的pt队列,从该pt队列中取出请求服务,并将该pt队列的可借出资源数量加1。
44.所述的保证分布式存储系统服务器端读尾延迟的系统,其中该模块1包括:
45.每个应用提供一个代表其负载特征的请求轨迹,将该请求轨迹中请求发送总量与请求发送的持续时间的比值作为该应用的请求平均发送速率ar_avg,设该应用获得的请求服务速率与请求的平均发送速率相同为ar_avg,计算百分位排队延迟pql_avg,该百分位与应用延迟slo的百分位相同,该请求轨迹提供请求入队的时间间隔,ar_avg提供请求出队的时间间隔,以计算该请求轨迹中所有请求的排队延迟,将延迟从低到高进行排序,计算百分位延迟。比较pql_avg与该应用的延迟slo,如果pql_avg大于等于slo,则该应用为pi应用,否则该应用为pt应用。
46.所述的保证分布式存储系统服务器端读尾延迟的系统,其中该模块2包括:
47.pt应用被延后服务的时间postponement=slo-pql_avg,pt应用借出的最大资源数量为pt应用因资源出借而增加的排队请求数量qd_add_max=postponement*ar_avg。
48.由以上方案可知,本发明的优点在于:
49.使用8台物理机作为存储节点,8台物理机作为客户端。每台物理机包括1块intel(r)xeon(r)cpu e5-2650 v4 processor(2.20ghz)cpu,一块intel p3700400gb ssd,一块intel corporation 82599es 10-gigabit网卡。操作系统为centos 7.5.1804,调度方法及应用准入控制构建在存储系统ceph 10.2.0之上。对比系统采用snc-meister和silo。实验负载为microsoft production server traces和microsoft enterprise traces。实验结果如图2所示,将本发明创造gecko与silo和snc-meister进行了对比,结果按snc-meister的结果进行了归一化,实验结果表明,本发明创造可承载的应用数量平均增加了44%。
50.该发明创造与现有技术相比,能够根据应用负载的变化实时动态地分配资源,既
消除了周期性分配资源因反馈链过长导致延迟slo违反的弊端,又降低了静态分配资源造成的资源超配程度,显著提升了存储系统的资源利用率。
附图说明
51.图1为分布式存储系统请求处理流程图;
52.图2为本发明gecko、silo和snc-meister三者间承载应用的数量对比图;
53.图3为预分配服务速率图;
54.图4为pt应用根据延迟slo的需求选择是否出借资源图;
55.图5为pi应用根据根据负载的变化选择是否借用资源图。
具体实施方式
56.发明人在进行存储系统服务节点内资源管理策略研究时,发现现有技术中技术缺陷是由于资源管理所需的灵活性与可预测性之间的矛盾导致的,具体表现在:先验式管理策略静态地划分资源便于预测应用请求的百分位延迟,但应用获得的资源与其不断变化的负载并不匹配,导致较高的资源超量配置;反馈式管理策略周期性地充分配资源有利于按照应用的负载变化分配恰好的资源,但由于反馈链过长,且缺少对负载变化的预见性,导致应用的尾延迟slo无法保证。发明人经过对资源管理所需的灵活性与可预测性进行研究发现,解决该项缺陷可以基于应用负载特征预测,通过限定的资源交换与极短反馈链的动态资源管理策略来实现,该方案的全过程如下所述。
57.(1)该方案根据每个应用负载的突发burst特征与延迟slo需求将应用分类为服务可延后应用和服务不可延后应用,为每个应用预分配服务速率。(2)在分布式存储系统的存储节点内部将不同类型的应用进行配对,令其在预分配的资源的基础上相互交换资源以降低资源超配,即超量配置,分配的资源超出了需求,产生浪费。(3)该方案对应用资源交换的最大数量进行了限制,可预期的资源交换符合了先验式资源管理的标准,以支持先验式的应用准入控制。(4)通过监控每个应用的请求排队深度,动态地调整应用的优先级,从而使应用获得的资源能够适应随时间不断变化的负载。后文将详细描述应用分类和配对方法,资源预分配、资源交换的设定以及动态调整优先级的过程。
58.基于上述前提,本发明是一种针对多种延迟敏感型应用共同部署于分布式存储系统,通过应用负载特征建模对应用分为不可延后服务应用与可延后服务应用两类,对两类应用预分配资源。存储节点服务应用时,对不同类型的应用进行匹配,使匹配的应用组合共享服务速率。根据应用负载的变化动态地交换资源,以保证应用尾延迟slo的应用准入控制方法。
59.系统运行过程中,将根据应用的尾延迟slo,应用提供的可以代表其负载特征的请求轨迹(trace)等信息进行应用的分类、资源预分配和资源交换数量的设定,并在应用接入系统后动态地分配资源,以保证应用满足目标slo需求。资源分配过程中涉及的参数如表1所示:
[0060][0061][0062]
本发明技术方案包括以下关键点:
[0063]
关键点1,应用分类方法。根据应用的负载特征和延迟slo将应用分为两类,一类为不允许延后服务(postponement-intolerable,pi)的应用,另一类为允许延后服务(postponement-tolerable,pt)的应用。分类方法如下,(1)每个应用提供一个可以代表其负载特征的请求轨迹(trace),该trace需要提供一段请求发送的标记,包括请求的大小,读取位置和发送时间。(2)根据trace计算该应用的请求平均发送速率ar_avg,即trace中请求发送总量与请求发送的持续时间的比值。(3)假设该应用获得的请求服务速率与请求的平均发送速率相同为ar_avg,计算百分位排队延迟pql_avg,该百分位与应用延迟slo的百分位相同,trace提供了请求入队的时间间隔,ar_avg提供了请求出队的时间间隔。即可以计算trace中所有请求的排队延迟。将延迟从低到高进行排序,计算百分位延迟。(4)比较pql_avg与该应用的延迟slo,如果pql_avg大于等于slo,则该应用为pi应用,不能延后该应用的
服务,否则不能保证该应用的延迟slo;如果pql_avg小于slo,则该应用为pt应用,可以在保证应用slo的前提下,适当延后应用的服务。技术效果:通过应用分类来区分不同应用对资源需求的迫切程度。
[0064]
关键点2,计算pt应用允许借出的资源数量。默认情况下,为pt应用提供的服务速率达到该应用的平均发送速率,则该应用的延迟slo就可以得到保证,并且其百分位延迟小于延迟slo。因此,在保证尾延迟slo的前提下,该应用可以借给其他应用一定大小的资源。这里的资源指的是服务请求数量,借出资源意味着相同时间内,本应服务该应用的请求数量降低了,转而服务其他应用。计算方法如下,(1)计算pt应用可以被延后服务的时间postponement=slo-pql_avg。(2)该pt应用允许借出的资源数量为延后服务时间内该应用被减少服务的请求数量,即pt应用因资源出借而增加的排队请求数量qd_add_max=postponement*ar_avg。技术效果:量化pt应用允许交换资源的最大数量,假如该pt应用借出的资源数量不超过此值,则该pt应用的百分位延迟依然可以得到保证。
[0065]
关键点3,计算pi应用可以借用的资源数量最大值。当pi应用的burst产生时,允许该应用向pt应用借用资源,这样可以降低该pi应用所需的平均服务速率。当pi应用所需的平均服务速率低于平均发送速率,所额外借用的资源将被浪费。因此pi应用借用资源后,所需的平均服务速率最低为该pi的平均发送速率。计算方法如下,(1)假设该pi应用所获得的服务速率为其平均发送速率,计算百分位延迟发生时的排队请求数量pqd_avg=pql_avg*ar_avg。(2)假设该pi应用所获得的服务速率为其平均发送速率,若该应用的延迟slo可以得到保证,则百分位延迟发生时的排队请求数量最大值pqd_slo=slo*ar_avg。(3)计算该pi应用可以借用的资源数量最大值,即该pi应用因借到资源而减少的排队请求数量qd_reduce_max=pqd_avg-pqd_slo。技术效果:量化pi应用可以借用资源的最大值,防止资源浪费。
[0066]
关键点4,设定pi应用借用资源的优先级。不同pi应用借用相同资源所获得的收益是不同的,所需的平均发送速率降低的越多,则单位收益越高。单位收益的计算方法如下,(1)计算pi应用的最大发送速率ar_max,即是该pi应用的trace中相邻请求的发送时间间隔的最小值的倒数。(2)计算pi应用不借资源时,为了保证延迟slo所需的服务速率sr_slo。设最小服务速率为平均发送速率ar_avg,最大服务速率为该pi应用的最大发送速率ar_max,通过二分查找,找到使pql_sr_slo=slo的服务速率sr_slo,其中pql_sr_slo为该pi应用获得服务速率sr_slo下的百分位延迟。(3)计算pi应用借用最大资源后,所需平均服务速率下降的程度,即该应用的最大收益revenue_max=sr_slo-ar_avg。(4)计算单位收益revenue_unit=revenue_max/qd_reduce_max。按照单位收益设定应用借用资源的优先级,单位收益更高的应用优先级更高。技术效果:基于贪心算法设定pi应用借用资源的优先级,以最大化资源利用率。
[0067]
关键点5,计算pi应用借用资源后所需的平均服务速率。当pi应用的burst产生时,允许该应用向pt应用借用资源,这样可以降低该pi应用所需的平均服务速率。计算方法如下,(1)设最小服务速率为该pi应用的平均发送速率ar_avg,最大服务速率为该pi应用的最大发送速率ar_max,设借用的资源数量为qd_reduce,通过二分查找,找到使借用资源后的百分位延迟pql_borrowed=(pqd_sr_borrowed-qd_reduce)/sr_borrowed与slo相同的sr_borrowed即为所求,其中pqd_sr_borrowed为该pi应用未借资源时获得服务速率sr_
borrowed下的百分位排队深度,sr_borrowed为pi应用借用资源后,百分位延迟与slo相同情况下,pi所需的平均服务速率sr_borrowed。技术效果,量化pi应用借用资源后所需的平均服务速率,则该pi应用的尾延迟slo可以得到保证。借用资源后,pi应用的百分位延迟是可预测的,以支持先验式的应用准入控制。
[0068]
关键点6,pi应用与pt应用的匹配方法。按照pi应用借用资源的优先级从高到低遍历所有pi应用。已知当前pi应用可借用的最大资源数量和每个pt应用可出借的最大资源数量。通过动态规划的方法为当前pi应用分配若干个pt应用,使这些pt应用出借的最大资源数量之和超出当前pi应用可借用的最大资源数量,并且浪费的资源数量最低。每次匹配后,从pt应用集合中剔除已匹配的pt应用,直到每个pi应用均借到资源或者pt应用全部匹配完毕。技术效果,pt应用的资源不能同时借给多个pi应用,因此通过最小化借出资源的浪费,提升系统的资源利用率。
[0069]
关键点7,计算为了保证已匹配应用组合的延迟slo所需的总服务速率。pi应用与若干个pt应用相匹配,为pi应用借用资源后预分配服务速率sr_borrowed,为pt应用出借资源后预分配服务速率为该pt应用的平均发送速率ar_avg,则该总服务速率为上述服务速率的总和。技术效果,pi应用pt应用交换资源后对资源需求是可预测的,支持先验式的应用准入控制。
[0070]
关键点8,基于资源交换的动态优先级调度方法。pi应用与其相匹配的pt应用总服务速率,为每个应用分配独立的先入先出(fifo)队列,针对上述已匹配应用的调度方法如下,(1)为pi应用预分配服务速率为pi应用借用资源后所需的平均服务速率sr_borrowed,为每个pt应用预分配服务速率为该pt应用的平均发送速率ar_avg。(2)监控pt应用因出借资源造成的额外的请求排队数量qd_add,当qd_add小于允许的最大出借资源数量qd_add_max时,pi应用的服务优先级高于该pt应用,允许该pi应用借用该pt应用的资源。(3)当qd_add与qd_add_max相同时,使该pt应用的服务优先级高于上述pi应用,为该pt应用预留服务速率,大小与该pt应用的平均发送速率相同。若pi应用的请求发送速率低于pi应用的平均发送速率时,剩余的服务速率用于服务该pt应用,剩余的服务速率为pi应用预分配服务速率sr_borrowed,如果某段时间pi应用的发送速率小于sr_borrowed,则会产生剩余的服务速率。qd_add最大不会超出qd_add_max,否则无法保证pt应用的延迟slo。技术效果:通过资源交换与实时检测请求的排队情况,提升了资源管理的灵活性,使资源可以按照应用负载的变化进行动态分配,提升了系统的资源利用率。
[0071]
关键点9,服务请求时,为应用预分配服务速率的方法。(1)应用接入存储节点时,为该应用分配一个fifo队列。并为该应用的队列分配一个虚拟时间戳ts
i
,该时间戳与存储节点当前的虚拟时间戳相同。为该应用的队列分配一个时间戳增加间隔ti
i
为预分配服务速率的倒数。(2)对所有应用的时间戳进行排序,io线程空闲后查找拥有最小时间戳的队列,并增加该队列的时间戳,即ts
i
=ts
i
+ti
i
。(3-1)如果该队列为空,返回(2)。(3-2)如果该队列不为空,则从该队列中取出请求。技术效果,在存储节点服务请求时,使应用的请求可以按照预分配的速率出队。
[0072]
关键点10,监测pt应用的额外请求排队数量,选择服务pt应用请求或pi应用请求的方法。(1)pt应用接入存储节点时,为该应用的队列设定可借出资源数量初值为qd_add_max。(2)当io线程空闲后查找拥有最小时间戳的队列,若该队列归属于某pt应用,增加该队
列的时间戳,即ts
i
=ts
i
+ti
i
,并读取可借出资源数量。(3-1)如果可借出资源数量大于0,并且pi应用的队列不为空,将上述pt应用的可借出资源数量减1,取出pi应用的请求进行服务。(3-2)如果可借出资源数量大于0,并且pi应用的队列为空,则取出该pt队列的请求服务,该pt应用的可借出资源数量不变。(3-3)如果可借出资源数量等于0,则取出该pt应用队列的请求进行服务,该pt应用的可借出资源数量不变。技术效果,使pt应用可以根据延迟slo的需求选择是否借出资源。
[0073]
关键点11,监测pi应用的请求排队情况,选择服务pi应用请求或pt应用请求的方法。(1)当io线程空闲后查找拥有最小时间戳的队列,若该队列归属于某pi应用,修改该队列的时间戳ts
i
=ts
i
+ti
i
,并读取该队列中请求的数量。(2-1)如果该pi应用队列不为空,则从该队列中读取请求服务。(2-2)如果该pi应用队列为空,则从所有pt应用中寻找可借出资源数量最小的pt队列,从该pt队列中取出请求服务,并将该pt队列的可借出资源数量加1。注意,该pt应用的时间戳不需要修改。技术效果,使pi应用可以根据负载的变化选择是否借用资源。
[0074]
为让本发明的上述特征和效果能阐述的更明确易懂,下文特举实施例,并配合说明书附图作详细说明如下。
[0075]
在分布式存储系统存储节点内部,多个延迟敏感型应用共享存储服务,本发明创造的技术方案核心是基于资源交换的动态资源分配方法。
[0076]
假设三个延迟敏感型应用接入分布式存储系统,本发明将上述三个应用分类为pi应用和pt应用,分别为pi、pt1和pt2。本发明预测了上述应用所需的预分配服务速率和可交换的资源数量。其中,pi应用的预分配服务速率为sr_borrowed,pt1和pt2的预分配服务速率分别为ar_avg1和ar_avg2,可借出的资源数量分别为qd_add_max1和qd_add_max2。
[0077]
1.存储节点为应用预分配服务速率
[0078]
(1)如图3所示,存储节点为每个应用各分配了一个fifo的io队列。为每个队列设定了一个虚拟时间戳分别为ts1、ts2和ts3,初值均为0。为每个队列分配了时间戳增加间隔,分别为ti1=1/sr_borrowed、ti2=1/ar_avg1以及ti3=1/ar_avg2。
[0079]
(2)对上述应用的时间戳进行排序,io线程空闲后查找拥有最小时间戳的队列即pi的队列,并增加该队列的时间戳,即ts1=ts1+ti1,并重新对时间戳排序。
[0080]
(3)如图3(a)所示,pi队列此时为空,则返回(2)重新选择拥有最小时间戳的队列即pt1的队列。
[0081]
(4)如图3(b)所示,此时pt1的时间戳最小,增加pt1队列的时间戳,即ts2=ts2+ti2,由于pt1队列不为空,则io线程从pt1队列的队头取出请求进行服务。
[0082]
2.pt应用根据延迟slo需求选择是否出借资源。
[0083]
(1)如图4所示,两个pt应用接入存储节点时,为对应的队列设定可借出资源数量初值分别为qd_add_max1和qd_add_max2。
[0084]
(2)假设应用运行一段时间后,pt1队列当前时间戳最小,增加该队列的时间戳,即ts2=ts2+ti2,并读取其可借出资源数量的数值。
[0085]
(3-1)如图4(a)所示,假设此时pt1可借出资源数量为1大于0,并且此时pi队列为不为空,服务pi队列队头请求,将pt1可借出资源数量减1。
[0086]
(3-2)如图4(b)所示,假设此时pt1可借出资源数量为1大于0,并且此时pi队列为
空,则服务pt1队列队头请求,pt1可借出资源数量不变。
[0087]
(3-3)如图4(c)所示,假设可借出资源数量为0,则服务pt1队列队头请求,pt1可借出资源数量不变。
[0088]
3.pi应用根据负载的变化选择是否借用资源。
[0089]
(1)如图5所示,假设应用运行一段时间后,pi队列当前时间戳最小,增加该pi队列的时间戳,即ts1=ts1+ti1,并读取该pi队列中的请求数量。
[0090]
(2-1)如图5(a)所示,如果该pi队列不为空,则服务该pi队列队头请求。
[0091]
(2-2)如图5(b)所示,如果该pi队列为空,则从所有pt队列中寻找可借出资源数量最小的pt应用队列,即pt2队列。服务pt2队列的队头请求,并将pt2队列的可借出资源数量加1。
[0092]
以下为与上述方法实施例对应的系统实施例,本实施方式可与上述实施方式互相配合实施。上述实施方式中提到的相关技术细节在本实施方式中依然有效,为了减少重复,这里不再赘述。相应地,本实施方式中提到的相关技术细节也可应用在上述实施方式中。
[0093]
本发明还提供了一种保证分布式存储系统服务器端读尾延迟的系统,其中包括:
[0094]
模块1、用于根据应用的负载特征与延迟需求,将分布式存储系统中每一个应用分类为服务可延后的pt应用或服务不可延后pi应用;
[0095]
模块2、用于根据预设保证延迟值,计算pt应用借出的最大资源数量;
[0096]
模块3、用于根据pi应用所获得的服务速率为其平均发送速率,计算百分位延迟发生时的排队请求数量pqd_avg=pql_avg*ar_avg。pi应用延迟slo不被违反,百分位延迟发生时的排队请求数量最大值pqd_slo=slo*ar_avg,ar_avg为应用的请求平均发送速率,pql_avg为百分位排队延迟,slo为应用的延迟需求,通过pqd_avg减去pqd_slo,得到pi应用借用的资源数量最大值qd_reduce;
[0097]
模块4、用于根据pi应用借用相同资源所获得的收益大小,为各pi应用借用资源的优先级;
[0098]
模块5、用于将最小服务速率设为pi应用的平均发送速率ar_avg,最大服务速率为该pi应用的最大发送速率ar_max,设pi应用借用的资源数量为qd_reduce,通过二分查找,找到使借用资源后的百分位延迟pql_borrowed=(pqd_sr_borrowed-qd_reduce)/sr_borrowed,以得到pi应用借用资源后所需的平均服务速率;
[0099]
模块6、用于根据pi应用借用资源的优先级和pi应用借用的资源数量最大值和每个pt应用借出的最大资源数量,通过动态规划的方法为当前pi应用分配多个pt应用,每次匹配后,从pt应用集合中剔除已匹配的pt应用,直到每个pi应用均借到资源或者pt应用全部匹配完毕;
[0100]
模块7、用于将已匹配应用组合的总服务速率设为pi应用借用资源后的预分配服务速率与应用组合中pt应用各平均发送速率之和;
[0101]
模块8、用于根据pi应用与其相匹配的pt应用共享该总服务速率,为每个pi应用以及与其相匹配的pt应用分配独立的队列,为应用组合中pi应用和各pt应用分配相应服务速率,并监控pt应用因出借资源造成的额外请求排队数量qd_add,当qd_add小于最大资源数量时,pi应用的服务优先级高于pt应用,允许该pi应用借用该pt应用的资源,当qd_add与最大资源数量相同时,该pt应用的服务优先级高于pi应用,为pt应用预留与pt应用的平均发
送速率相同的服务速率,若pi应用的请求发送速率低于pi应用的平均发送速率,则剩余的服务速率用于服务pt应用;
[0102]
模块9、用于应用接入分布式存储系统的存储节点时,为其分配一个队列,并根据存储节点当前的虚拟时间戳为队列分配虚拟时间戳ts
i
,为该应用的队列分配一个时间戳增加间隔ti
i
,ti
i
为预分配服务速率的倒数,对分布式存储系统中所有应用的时间戳进行排序,io线程空闲后查找拥有最小时间戳的队列从中取出请求,并增加该最小时间戳的队列的时间戳ts
i
=ts
i
+ti
i
。
[0103]
所述的保证分布式存储系统服务器端读尾延迟的系统,其中还包括:
[0104]
模块10、用于pt应用接入该存储节点时,为pt应用的队列设定可借出资源数量初值为该最大资源数量qd_add_max;当io线程空闲后查找拥有最小时间戳的队列,若该队列归属于pt应用,增加该队列的时间戳tsi=tsi+tii,并读取可借出资源数量;若可借出资源数量大于0且对应的pi队列不为空,将pt应用的可借出资源数量减1,取出pi应用的请求进行服务;若可借出资源数量大于0且对应的pi队列为空,则取出pt队列中的请求服务,pt应用的借出资源数量不变;若可借出资源数量等于0,则取出pt队列中的请求进行服务,pt应用的可借出资源数量不变。
[0105]
所述的保证分布式存储系统服务器端读尾延迟的系统,其中还包括:
[0106]
模块11、用于当io线程空闲后查找拥有最小时间戳的队列,若该队列归属于pi应用,修改该队列的时间戳,并读取该队列中请求的数量;若该队列不为空,则从该队列中读取请求服务;若该队列为空,则从所有pt应用中寻找可借出资源数量最小的pt队列,从该pt队列中取出请求服务,并将该pt队列的可借出资源数量加1。
[0107]
所述的保证分布式存储系统服务器端读尾延迟的系统,其中该模块1包括:
[0108]
每个应用提供一个代表其负载特征的请求轨迹,将该请求轨迹中请求发送总量与请求发送的持续时间的比值作为该应用的请求平均发送速率ar_avg,设该应用获得的请求服务速率与请求的平均发送速率相同为ar_avg,计算百分位排队延迟pql_avg,该百分位与应用延迟slo的百分位相同,该请求轨迹提供请求入队的时间间隔,ar_avg提供请求出队的时间间隔,以计算该请求轨迹中所有请求的排队延迟,将延迟从低到高进行排序,计算百分位延迟。比较pql_avg与该应用的延迟slo,如果pql_avg大于等于slo,则该应用为pi应用,否则该应用为pt应用。
[0109]
所述的保证分布式存储系统服务器端读尾延迟的系统,其中该模块2包括:
[0110]
pt应用被延后服务的时间postponement=slo-pql_avg,pt应用借出的最大资源数量为pt应用因资源出借而增加的排队请求数量qd_add_max=postponement*ar_avg。
相关技术
网友询问留言
已有0条留言
- 还没有人留言评论。精彩留言会获得点赞!
1