一种基于欧氏距离的机载LiDAR数据建筑物提取方法与流程
一种基于欧氏距离的机载lidar数据建筑物提取方法
技术领域
[0001]
本发明属于机载激光lidar点云数据分类技术领域,特别是涉及一种基于欧氏距离的机载lidar数据建筑物提取方法。
背景技术:
[0002]
城市是人类生活的聚居地,也是社会经济活动的重心,城市化已经深刻地改变了人类的生存环境和生活方式。随着城市化进程的快速推进,如何对快速扩张的城市进行合理的管理、规划成为每个发展中城市亟待解决的问题。城市中最容易发生变化的部分是建筑物,人们对城市地区建筑物变化探测的要求也在不断提高,主要表现在两个方面:1.在变化信息获取方式上,希望更快捷地获取变化信息;2.在变化信息获取内容上,人们希望了解变化区域更丰富、更精准的变化属性信息以及空间变化信息。长期以来,学者们大多使用遥感影像数据,采用图像处理的方法进行建筑物检测。由于遥感影像缺乏直接三维数据信息,存在异物同谱、同谱异物、阴影与投影等问题,因此遇到很大挑战。激光雷达(light detecting and ranging,lidar)是一种先进的主动遥感技术,它能够快速获取地表目标高精度的高度信息和三维结构信息,且具有抗干扰能力强、低空探测性能好等优点。随着无人机技术的快速发展,无人机激光雷达为快速、准确的植被精细分类提供了有力的技术支撑。
[0003]
近年来,利用机载lidar数据提取建筑物的方法取得了很好的发展,根据提取方法的不同可以大致分为两大类:直接提取和间接提取。建筑物点云直接提取方法是通过点云分割分类手段将建筑物从地面、树木以及其他地物直接分离出来。这种方法由于较难建立分割分类结果与建筑物屋顶准确的对应关系,容易造成漏提取和误分类,导致检测出的建筑物区域不完整。常用的直接提取方法大致可分为基于边缘分割、基于区域分割、基于特征聚类和基于模型拟合等四个方面。建筑物点云间接提取方法一般先滤波分离地面点云,再从非地面点云中识别出属于建筑物屋顶的点集,较适用于缺乏其他辅助数据的情况。建筑物点云间接提取与前文直接提取方法内的建筑物点云提取方法具有很强的相关性,区别仅在与在间接提取方法中不用考虑地面点云的参与。根据数据结构的不同,将建筑物间接提取方法分为基于原始点云、基于规则格网、基于不规则三角网(tin)、基于剖面和基于体元五类。
[0004]
目前,基于tin的提取方法应用最为广泛,该方法在获得激光脚点邻近关系的同时,较好地保持了数据的精度和信息量,但存在数据结构复杂、占用大量存储空间、难以进行空间分析等缺点。基于规则格网的提取方法也比较成熟,能够引用许多既有的影像处理技术,拥有高效的空间分析与计算能力,但容易受到格网的尺度选择和数据内插等因素影响,造成数据精度损失。此外,这些研究在计算前都需要进行参数的设置,且参数的大小对提取结果的影响时十分大的。而针对大范围城区内的建筑物提取,以上算法无法同时保证效率与准确性。另一方面,由于城区内总存在高大植物或大面积规整植物,对建筑物提取的结果是同样巨大的。大部分算法都无法精确的避开植物提取建筑物,或者在去除植物的同时也会去除建筑物的一部分,导致提取的建筑物不完整。
技术实现要素:
[0005]
针对上述存在的技术问题,提供一种基于欧氏距离的机载lidar数据建筑物提取方法,研究对象从传统的离散点转换为有规律的扫描线,同分利用线内点云之间的联系,利用建筑物点云分布规律,植物点云分布散漫无规律的特性,通过计算点云之间的距离数据波动,基于欧氏距离实现无人机lidar数据的建筑物提取。
[0006]
本发明的目的是通过以下技术方案来实现的:
[0007]
本发明一种基于欧氏距离的机载lidar数据建筑物提取方法,包括以下步骤:
[0008]
步骤s1,加载机载lidar数据;
[0009]
步骤s2,去除机载lidar数据的噪声点,并高程约束以滤除地面点和低点;
[0010]
步骤s3,提取扫描线,按坐标排序每条扫描线中的所有点,并依次计算有序点之间欧氏距离和各点距离的方差,标记方差为特征值;
[0011]
步骤s4,根据数据量变化确定初始l值;
[0012]
步骤s5,自动减小l值,计算剩余点的特征值,对比新的l值和特征值并迭代,根据数据量变化趋势停止迭代,输出结果;
[0013]
步骤s6,利用该算法对不同城区进行实验测试有效性。
[0014]
进一步地,所述步骤s2包括以下步骤:
[0015]
(21)对每一个点搜索相同个数的邻域点,并计算该点到邻域点的距离平均值d
mean
及其中值m和标准差σ,计算最大距离d
max
:
[0016]
d
max
=m+k*σ
[0017]
其中k为标准差倍数,设置为5,若d
mean
大于d
max
,则认为该点为噪点,将其去除;
[0018]
(22)以地面高度为基准滤除高差为1米内的点云,确保地面点和低点不在计算数据内。
[0019]
进一步地,所述步骤s3包括以下步骤:
[0020]
(31)读取飞行器内置gps的“time”属性,数值相同聚类为同一条扫描线;
[0021]
(32)对同一条扫描线内的点以x坐标重新进行排序;
[0022]
(33)按顺序计算前后相邻两点之间的欧几里得空间距离并依次计算每相邻两段距离之间的方差值,每组方差值对应三个点。
[0023]
进一步地,所述步骤s4包括以下步骤:
[0024]
(41)设定l值为1.0与所述特征值比较,保留方差值小于l值的三个点,当特征值大于l时观察下一组方差值与l比较的结果,若同样超限,则标定第一组的最后一个点为危险点,否则,保留该组三个点;
[0025]
(42)以0.1为步长减小l值,分别使用不同的l值对原始数据按照(41)的规则进行计算筛点,记录不同l值计算后的数据总量,绘制数据总量的曲线;
[0026]
(43)根据曲线变化趋势,得到相邻前后两点之间的斜率,当数据总量斜率变化最小时,取该点的l值作为迭代计算的初始l值。
[0027]
进一步地,所述步骤s5包括以下步骤:
[0028]
(51)以0.0001的步长减小l值;
[0029]
(52)重新计算除危险点外的所有点的方差值;
[0030]
(53)根据步骤s4的判定规则进行判定,并记录每次计算后的安全点数据总量;
[0031]
(54)重复以上步骤进行迭代,数据点总量变化最为平缓时停止迭代,输出结果。
[0032]
本发明的有益效果为:
[0033]
1.本发明基于城市样区内获取的无人机激光雷达点云数据,研究对象从离散的点转换为扫描线进行计算,能够充分利用同一条扫描线内所有点之间存在的空间联系。
[0034]
2.本发明提出一种利用计算点间欧氏距离提取建筑物的方法,该方法简单高效,且无需设置参数。在两个不同地区的城市数据中实现了97.1%的总体正确率以及2.2%的错误率和3.2%的遗漏率,并通过实验验证在该数据集中,初始l值设置取为l,迭代结束值取为0.04便可满足高效与高精准。
[0035]
3.本发明创造性的将研究对象从传统的离散点转换为扫描线,能够充分利用邻近点之间的空间关系,为其他提取建筑物方法提供了新的思路。
附图说明
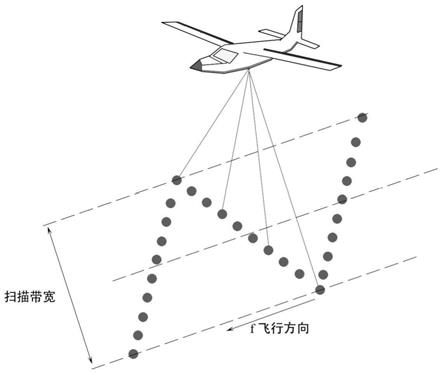
[0036]
图1为“z”字型扫描线示意图。
[0037]
图2为本发明的方法流程图。
[0038]
图3(a)为无人机lidar原始数据图
[0039]
图3(b)为滤波后效果图
[0040]
图4为基于分水岭分割的单木分割结果图。
[0041]
图5为基于点云距离的单木分割结果图。
[0042]
图6为本发明使用的神经网络模型图。
[0043]
图7为t-net网络结构图。
[0044]
图8为pointnet(vanilla)网络结构图。
[0045]
图9为三种算法的错误率。
[0046]
图10为三种算法的遗漏率。
具体实施方式
[0047]
为能清楚说明本方案的技术特点,下面通过具体实施方式,并结合其附图,对本发明进行详细阐述。应当注意,在附图中所图示的部件不一定按比例绘制。本发明省略了对公知组件和处理技术及工艺的描述以避免不必要地限制本发明。
[0048]
实施例:针对基于机载激光雷达数据建筑物提取的需要,本发明提供了一种基于欧氏距离的机载lidar数据建筑物提取方法,通过提取扫描线,并利用一条扫描线内的点之间的空间关系,解决了目前基于机载lidar数据的大范围建筑物快速准确提取的问题。
[0049]
如图2所示流程图,针对利用机载激光雷达数据建筑物提取的需要,本发明提供一种基于欧氏距离的机载lidar数据建筑物提取方法,包括以下步骤:
[0050]
步骤s1,加载机载lidar数据;
[0051]
步骤s2,去除噪声点,并高程约束以滤除地面点和低点;
[0052]
步骤s3,提取z字型扫描线,如图1所示,按坐标排序每条扫描线中的所有点,并依次计算有序点之间欧氏距离和各点距离的方差,标记方差为特征值;
[0053]
步骤s4,根据数据量变化确定初始l值;
[0054]
步骤s5,自动减小l值,计算剩余点的特征值,对比新的l值和特征值并迭代,根据
数据量变化趋势停止迭代,输出结果;
[0055]
步骤s6,利用该算法对不同城区进行实验测试有效性。
[0056]
所述步骤s2具体包括以下步骤:
[0057]
(21)由于城市环境的复杂性,获取无人机lidar数据的过程中会产生粗差,因此必须先对原始点云数据去噪。对每一个点搜索相同个数(设置为10)的邻域点,并计算该点到邻域点的距离平均值d
mean
及其中值m和标准差σ。计算最大距离d
max
:
[0058]
d
max
=m+k*σ
[0059]
其中k为标准差倍数,设置为5;若d
mean
大于d
max
,则认为该点为噪点,将其去除;
[0060]
(22)由于城区内的地面点在形态上与建筑物相仿,相邻点之间欧氏距离变化程度不大,所有在计算前剔除地面点是非常有必要的。以地面高度为基准滤除高差为1米内的点云,确保地面点和低点不在计算数据内,又由于大部分建筑物高度不会小于1米,所有不必使用复杂的滤波算法对数据进行计算。
[0061]
所述步骤s3具体包括以下步骤:
[0062]
(31)读取飞行器内置gps的“time”属性,数值相同聚类为同一条扫描线;
[0063]
(32)对同一条扫描线内的点以x坐标重新进行排序。
[0064]
(33)按照顺序从头至尾计算一条扫描线内前后相邻两点的欧几里得空间距离,每个距离值对应两个点,再从头至尾计算每相邻两段距离的方差值作为计算的特征值,每个方差值对应三个点。
[0065]
所述步骤s4具体包括以下步骤:
[0066]
(41)设定l值为1.0与特征值比较,保留方差值小于l值的三个点,当特征值大于l时观察下一组方差值与l比较的结果,若同样超限,则标定第一组的最后一个点为危险点,否则,保留该组三个点;
[0067]
(42)以0.1为步长减小l值并重复上述步骤,分别使用不同的l值对原始数据按照(41)的规则进行计算筛点,记录不同l值计算后的数据总量,绘制数据总量的曲线;
[0068]
(43)根据曲线变化趋势求得斜率,即图4所示的相邻前后两点之间的斜率,当数据总量变化斜率最小时,取该点的l值作为迭代计算的初始l值。
[0069]
所述步骤s5具体包括以下步骤:
[0070]
(51)以0.0001的步长减小l值;
[0071]
(52)重新计算除危险点外的所有点的方差值;
[0072]
(53)根据步骤s4的判定规则进行判定,并记录每次计算后的安全点数据总量;
[0073]
(54)重复以上步骤进行迭代,数据点总量变化最为平缓时停止迭代,输出结果。
[0074]
为了验证上述建筑物检测方法的性能,以某单位提供的实测无人机lidar数据作为实验数据,通过实验验证欧氏距离作为特征是提取建筑物的可行性。
[0075]
本发明选取沈阳市(41.749477
°
n,123.522408
°
e)的一部分和盘锦市(41.411438
°
n,122.438642
°
e)的一部分作为研究区,两者都是典型的城市内高密度建筑物覆盖地区,同时绿化率高,植被形态复杂。实验数据由大疆无人机搭载的riegl公司minivux 1uav激光雷达扫描仪于2019年8月24日获取,航线间距40m,航高50m,飞行速度5m/s,激光雷达扫描角90
°-
270
°
,扫描线速度100m/s。基于该无人机激光雷达系统获得的建筑物样例数据如图1所示。
[0076]
以试验区1为例,通过上述去噪实和高程约束验得到了非地面点,无人机lidar原始数据与实验后效果对比如图3(a)和图3(b)所示。对于初始l值的确定,需要通过数据总量变化曲线进行判定,该区域数据点总数为2579932个,如图4所示,选取不同的l初始值进行数据计算可以得到不同的数据总量,而曲线总体趋近平缓,到最后急剧下跌,取曲率最小处作为初始l值的选取。
[0077]
完成初始计算后,迭代要逐步减小l值,以此对数据进行更加精确的计算。如5所示,迭代计算l值的步长设置为0.001,从图5中可以得知当l值大于0.091和小于0.009时,数据点数量变化剧烈;在0.091与0.009之间时,数据量变化缓慢(由于在0.091至0.009间点云变化幅度较小且数据密度较大,为了直观感受点云数量的体现,删除0.09至0.01间数据变化不大且密集的数据点数量)。计算每相邻步长的数据点个数差求平均,确定当l值迭代为0.05之后数据量变化幅度基本不变,为了减少计算时间,本例采取l值为0.04时停止计算。
[0078]
为了证明本实验方法的优越性,本实验与以下两种方法进行比较。
[0079]
方法1—参考何曼芸等提出的基于不规则三角网(tin)方法,首先利用原始点云数据建立不规则三角网,利用三角网中突起物边缘点所在三角形的法向量、边长及高程特征,提取突起物边缘点。然后以提取出的边缘点作为种子点,根据三角网连接关系进行区域生长,提取突起物点集合,最后删除集合中点数量较少的非建筑物点集得到建筑物点集。
[0080]
方法2—参考k-meand聚类方法,k均值聚类算法(k-means clustering algorithm)是一种迭代求解的聚类分析算法,其步骤是,预将数据分为k组,则随机选取k个对象作为初始的聚类中心,然后计算每个对象与各个种子聚类中心之间的距离,把每个对象分配给距离它最近的聚类中心。聚类中心以及分配给它们的对象就代表一个聚类。本文采用高程与回波强度作为分类标准,将数据分为5类,最终得到建筑物点云集合。
[0081]
如图6、图7、图8分别为sled,tin和k-means算法的结果图。其中相同部分的红框1与红框2为三者之间细节的差距,从图7红圈可以看出,tin算法无法避免密集高大植被所带来的的影响,而k-means算法则将部分的建筑物作为非建筑物而未检测出。
[0082]
提取结果如表1所示。
[0083]
表1试验区1的各算法检测面积与重叠面积
[0084]
[0085][0086]
图9与图10分别为三种算法错误率和遗漏率的柱状堆积图,能够直观的看出三者的差距。其中本文方法综合准确率达到97.1%,错误率和遗漏率分别低至2.2%和3.7%。而tin法综合准确率达到89.6%。错误率和遗漏率分别为4.9%和16.0%。k-means算法综合准确率83.4%,错误率及遗漏率分别为7.3%和25.9%
[0087]
通过上述全部实验得到以下结论:
[0088]
(1)本发明(sled)在包含大量高大和浓密植物的城市数据集上实现了97.1%的总体精度及2.2%和3.7%错误率和遗漏率。
[0089]
(2)在该数据集中,对初始l值选取为0.1,迭代步长设置为0.0001,终止l值选取为0.04时,建筑物提取准确率最高,且计算之间短。
[0090]
(3)通过将研究对象从传统的离散点转换为扫描线,能够充分利用邻近点之间的空间关系,为建筑物全自动提取提供了新思路。
[0091]
可以理解的是,以上关于本发明的具体描述,仅用于说明本发明而并非受限于本发明实施例所描述的技术方案,本领域的普通技术人员应当理解,仍然可以对本发明进行修改或等同替换,以达到相同的技术效果;只要满足使用需要,都在本发明的保护范围之内。
相关技术
网友询问留言
已有0条留言
- 还没有人留言评论。精彩留言会获得点赞!
1