优化深度学习降维重构参数的油藏自动历史拟合方法与流程
本发明属于地球物理领域,具体地,涉及一种优化深度学习降维重构参数的自动历史拟合方法及系统。
背景技术:
油藏自动历史拟合是油藏开发管理的重要组成部分,基于油藏数值模拟技术通过拟合油气井的生产观测数据对储层数值模型的不确定性参数如渗透率、孔隙度等进行反演调整,为井网规划、生产优化及方案设计等提供可靠的储层数值模型。由于储层地质特征的复杂性,往往需要足够精细的网格构建储层数值模型,导致自动历史拟合需要调整的参数通常达数十万乃至数百万。油藏数值模型降维重构方法通常被用于解决高维网格变量难以直接反演调整的难题。
近年来,随着高性能计算机、传感器等广泛应用,计算能力、实时数据等显著增加。因此机器学习方法在图像处理、计算机视觉等领域获得了巨大的成功,在工程领域机器学习方法也显示出巨大的应用潜力。数据驱动求解和机器学习回归预测模型等研究证明了机器学习方法能够有效的应用于复杂系统数值建模、参数反演和优化决策。目前机器学习方法在自动历史拟合领域的应用尚处于起步阶段,但机器学习领域近年来的变革性突破为自动历史拟合技术的更新换代带来了新的契机。
技术实现要素:
为克服现有技术存在的缺陷,本发明提供一种优化深度学习降维重构参数的油藏自动历史拟合方法,采用自动编码器(autoencoder,ae)对大规模网格油藏静态参数进行降维与重构处理,同时利用进化算法优化自编码模型的结构,对复杂地质特征进行特征提取及降维分解,特征压缩的同时保留了足够的信息实现保持与复杂地质特征一致的油藏模型重构,结合降维后的低维空间连续特征与数据光滑多次数据同化方法(es-mda)进行自动历史拟合,解决了数据同化方法对复杂离散特征难以有效应用的问题。
为实现上述目的,本发明采用下述方案:
优化深度学习降维重构参数的油藏自动历史拟合方法,包括以下步骤:
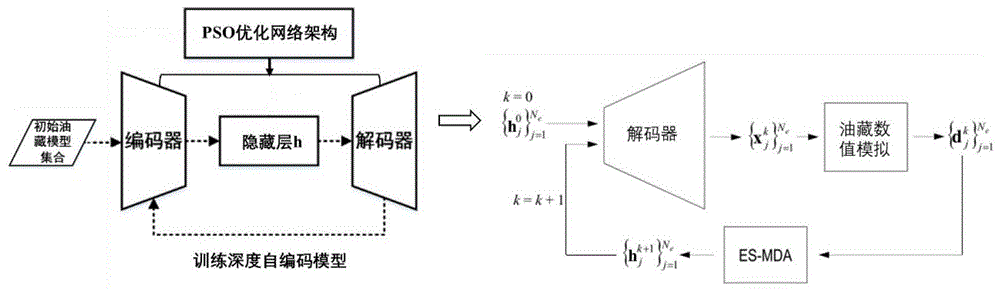
步骤一、构建初始油藏模型,通过自动编码器方法训练深度自编码模型,使用解码器进行降维参数化表征
步骤二、利用粒子群优化算法优化自编码模型的神经网络结构
步骤三、es-mda方法迭代同化数据更新潜变量,自编码模型解码器重构油藏模型并进行数值模拟
步骤四、多次迭代进行观测数据拟合,最终输出拟合模型,完成自动历史拟合流程。
相对于现有技术,本发明的有益效果如下:通过深度自编码模型、粒子群优化算法的结合可将高维地质特征如渗透率映射到低维连续高斯空间进行重参数化表征,结合集合光滑多次数据同化(es-mda)方法吸收生产历史实现复杂大规模油藏自动历史拟合高效求解。
附图说明
图1是优化深度学习降维重构参数的自动历史拟合方法流程示意图;
图2a是连续相油藏算例的真实油藏模型;
图2b是连续相油藏算例的随机初始油藏模型集合;
图3a是优化前后深度自编码(dae)模型生成渗透率场效果对比的初始油藏模型;
图3b为是优化前深度自编码模型重构结果(隐层节点数为519-391-60);
图3c是优化后深度自编码模型重构结果(隐层节点数为3905-256-41);
图4a是es-mda结合深度自动编码器-粒子群优化方法生产观测数据拟合结果的生产井1的日产油量,其中圆点表示观测数据点,细实线是初始油藏模型集合数值模拟预测结果,虚线是历史拟合更新模型集合的数值模拟预测结果;
图4b是生产井2的日产油量的历史拟合结果;
图4c是生产井3的日产油量的历史拟合结果;
图4d是生产井4的日产油量的历史拟合结果;
具体实施方式
参照图1,优化深度学习降维重构参数的油藏自动历史拟合方法,包括以下步骤:
步骤一、构建初始油藏模型,通过自动编码器方法训练深度自编码模型,使用解码器进行降维参数化表征,具体过程如下:
1.1:构建初始油藏模型
将油藏开发生产动态响应dobs和油藏模型参数m看作是油藏系统的输入与输出:
dobs=g(m)+ε(1)
其中g(·)表示油藏系统的数值模型或油藏数值模拟器,ε表示生产动态响应的观测误差,使用贝叶斯概率推理方法建立油藏模型参数估计数学模型:
其中,p(m)称为先验概率,表示模型参数的已知信息;p(dobs|m)称为似然函数,用于量化观测数据与估计模型参数进行数值模拟预测之间的拟合误差;p(m|dobs)即后验概率,表示在已知观测数据dobs的情形下模型参数m的概率分布;
根据油藏的静态观测数据,使用随机地质统计建模方法可以建立大量的随机初始油藏模型mi(i×1,2,...,ne),结合高斯概率模型建立油藏模型参数的先验概率表达:
假设观测误差ε服从高斯分布,即ε~n(0,cd),根据式(1)可以推得似然函数:
结合式(2)、(3)、(4)可得到油藏模型参数的后验概率表达:
1.2:训练自编码模型,使用解码器进行降维参数化表征
读取大规模网格油藏静态参数即高维油藏静态参数,并采用自动编码器对所述大规模网格油藏静态参数进行降维,得到降维后的油藏静态参数。用初始油藏模型数据训练深度自编码模型,应根据不同模型设置不同的网络层数,隐层数通常设为3-5层,根据训练效果设置训练迭代次数,通常设为100-200次;
构造自动编码器目标函数,并根据所述自动编码器目标函数将自动编码器输入层中的所述高维油藏静态参数压缩至隐藏层并去掉数据中的冗余信息,然后在输出层中对压缩至隐藏层中的数据进行降维,得到降维后的油藏静态参数,其中,所述高维油藏静态参数具体包括各划分网格的渗透率以及孔隙度。
步骤二、利用粒子群优化算法优化自编码模型的神经网络结构,过程如下:
将生成的深度ae模型网络各层节点个数xi作为粒子群优化算法的优化参数,模型训练后的训练误差作为优化目标函数:
粒子群优化算法初始化为一群随机粒子(随机解),各层节点的初始化范围如表1中所示,然后通过迭代找到最优解。当粒子的训练误差更小时,则该粒子位置作为局部极值pbest,所有粒子的最小训练误差所在位置作为全局极值gbest。在每一次的迭代中,粒子通过跟踪两个“极值”(pbest,gbest)来更新自己。在找到这两个最优值后,粒子通过下面的公式来更新自己的速度和位置。设置适当的终止条件,在到达预设的迭代次数后,优化结束并得到最优组合。
vi=vi+c1×rand()×(phesti-xi)+c2×rand()×(gbesti-xi)(6)
xi=xi+vi(7)
其中,i=1,2,…,n,n是此群中粒子的总数。vi:粒子的速度;rand():介于(0,1)之间的随机数;xi:粒子的当前位置;c1和c2:学习因子,通常c1=c2=2;利用优化后得到的结果作为隐层节点数组合训练深度自编码模型,将模型参数输入进行降维处理得到潜变量。
步骤三、es-mda方法迭代同化数据更新潜变量,自编码模型解码器重构油藏模型并进行数值模拟,过程如下:
3.1es-mda方法迭代同化数据更新潜变量:
使用es-mda方法对式(5)后验概率表达进行数值求解,通过使用观测数据的误差协方差矩阵cd乘以一个膨胀因子α多次迭代进行数据同化,es-mda方法中油藏模型参数的估计如下所示:
其中αt为膨胀因子,αt=1/n,n是迭代次数通常取4~10;
3.2自编码模型解码器重构油藏模型并进行数值模拟:
将es-mda更新后的参数作为深度自编码模型解码器的输入参数,输入解码层即可实现从低维表征重构相应的油藏模型,进行数值模拟计算用于下一次潜变量迭代更新。
步骤四、多次迭代进行观测数据拟合,最终输出拟合模型,完成自动历史拟合流程:
多次迭代求解直至满足收敛条件如达到提前设定的迭代次数,输出最终拟合模型,完成自动历史拟合流程。
实例:实际实验中的数据,优化深度学习降维重构参数的油藏自动历史拟合方法,包括以下步骤:
(1)实验数据及参数确定
以spe-10模型为例,对一个二维连续相油藏进行自动历史拟合研究,拟合参数为渗透率。该油藏真实渗透率分布如图2a所示,渗透率分布为10~4000毫达西,图2b为初始模型集合中随机抽取的4个模型,初始模型可根据训练图像采用多点地质统计随机建模方法生成。该油藏模型有220×60网格,每个网格20m×10m,厚度是2m,含有一口注水井、四口生产井,采用eclipse软件作为油藏数值模拟器。为增加历史拟合预测模型的挑战性,仅使用3600天共18个时间步的生产数据进行自动历史拟合测试,以4口生产井的日产水量和日产油量数值模拟结果作为观测数据。
(2)结果
2.1)训练深度自编码模型
利用自动编码器方法对5000个随机初始油藏模型进行训练,其中3500个模型作为训练样本,1500个模型作为验证样本,深度自编码模型共包含3个隐层。
2.2)利用粒子群优化算法优化自编码模型结构
设置种群粒子数为10,迭代次数为10次,优化的变量为3个隐层的节点个数。
随机选取优化前后的一个粒子的参数对深度自编码模型重构结果进行分析,如图3所示,上部分为初始油藏模型,中间部分为优化前自编码模型(隐层节点数为519-391-60)的渗透率场的重构结果,下部分为优化后自编码模型(隐层节点数为3905-256-41)的渗透率场的重构结果,可以看出优化前的自编码模型重构出来的图像较为模糊,相边界不明显。而优化后的自编码模型重构出来的高渗相的分布趋势都能够得到较好地重构,相边界更加清晰,且降维后维数更小,重构效果更好。
2.2)历史拟合测试
将优选出来的深度自编码模型作为降维算法辅助es-mda进行自动历史拟合测试。图4对四口生产井的日产油量历史拟合结果进行了说明,其中圆点表示观测数据点,细实线是初始油藏模型集合数值模拟预测结果,虚线是历史拟合更新模型集合的数值模拟预测结果。与初始随机油藏模型集合相比,es-mda结合ae-pso自动历史拟合方法预测的油藏模型集合能够很好地反映真实观测数据的变化。
表1自编码模型结构
- 还没有人留言评论。精彩留言会获得点赞!