基于ReID特征的强数据关联一体化实时多目标跟踪方法与流程
本发明属于计算机视觉
技术领域:
,更为具体地讲,涉及一种基于reid特征的强数据关联一体化实时多目标跟踪方法。
背景技术:
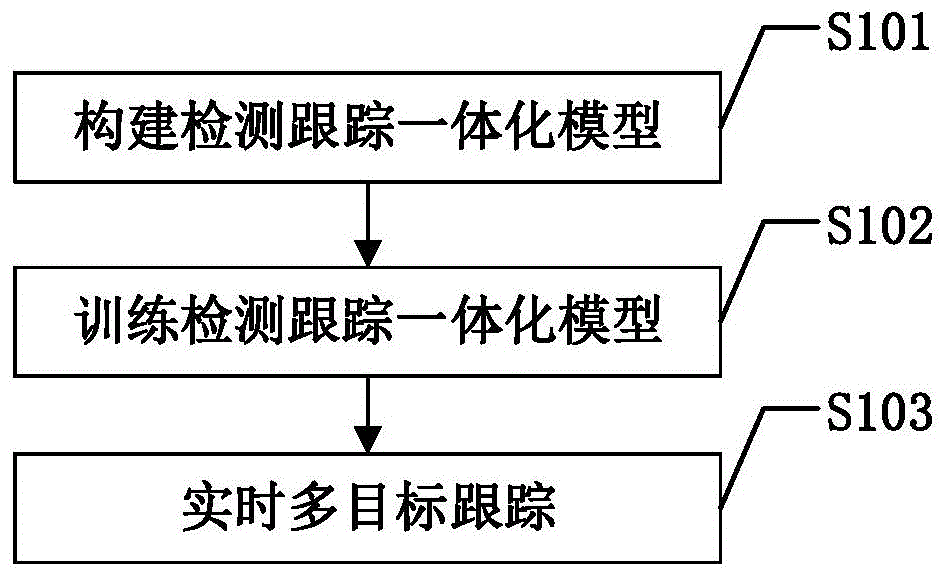
:多目标跟踪技术结合了模式识别、机器学习、计算机视觉、图像处理以及计算机应用等多个学科,构成了一种在连续视频帧中获取多个目标位置并与之前目标轨迹序列做数据关联的手段,为后续的高层识别应用比如视频内容理解以及目标行为分析奠定了基础。目前,多目标跟踪技术广泛应用于智能交通、行为分析、人机交互、智能监控、智能驾驶系统等领域中,有着广泛的应用前景及巨大的潜在经济价值。而行人作为实际生活中存在最为广泛的对象,如何在公共场所及重要的工业生产等环境中实现对多个行人目标稳定长时的跟踪一直是计算机视觉领域中的热门应用问题。随着深度学习的发展,多目标跟踪方法越来越依赖于高性能的目标检测器以及行人重识别(reid)模型,现在主流的方案都是基于在检测上进行跟踪的范式来实现。这一类方法将多目标跟踪任务分为两个单独的任务来做,如sort,deepsort,poi等。第一步是通过检测获取每一帧行人目标的位置并预测框的尺度,第二步通过提取每一个目标框内的id相关信息来做帧间匹配。这一类方法十分灵活,性能优异的目标检测器和行人重识别模型相互搭配就可以获得很好的性能。但是这也意味着这一类多目标跟踪系统中要包含两个计算密集的组件,尤其是对每一个检测框都需要运行一次reid模型,这会花费大量时间进行推理,并不能达到实时。随着多任务的发展,将检测器和id特征提取网络集成为一个统一的多目标跟踪系统得以构建,其中以jde、retaintrack为代表。它们多数将id特征提取网络作为一个分支添加到检测器上来同时获得检测结果和对应的reid特征,这种结构减少了模型参数和计算量,速度获得了很大的提升。不幸的是,与二步方法相比,它们的跟踪性能要较低一些。除此之外,还存在一些新颖的联合检测和跟踪的一体化模型,它们通过非reid信息来完成数据关联工作,如centertrack通过上一帧的检测信息利用下一帧的特征进行位置回归实现帧间关联,ctracker设计了链式模型结构,将相邻两帧作为输入,直接输出检测和关联结果,tubetk将视频分割为三维输入,通过3d卷积挖掘帧与帧之间的关联信息。这一类方法简单且在mot(multipleobjecttracking,多目标跟踪)challange有不俗的表现,但是与基于reid网络的两阶段方法相比,其数据关联能力依然有较大差距。经过分析,一体化模型尤其是基于reid方法的一体化模型性能退化主要来自于以下两方面原因:1)检测和reid任务之间的过度竞争:在一体化多目标跟踪方法中,通常用一段共享的嵌入向量来表示对象类置信度、目标尺度和id信息。虽然效率很高,但不同任务之间的内在差异却被忽略了。这会造成学习的混淆,即为了获得一个任务的高性能造成另一个任务的停滞或者退化。具体来说,检测任务最理想的状态是同一类别的不同对象具有相同的语义,且与背景点位置的嵌入信息有高区分度,类内趋同。而在reid任务中却要同一类别的不同对象具有高度区分的语义,有类内区分性,这和检测的最终目的是相矛盾的。2)在mot任务中目标的大尺度变化:与reid数据集中将目标图像统一成一个尺寸(如256x128)不同,mot数据集中的目标尺寸差异大,且存在更严重的相互遮挡问题。因此在mot任务中,reid网络的特性需要具有尺度感知能力,以适应目标的尺度在帧间发生了巨大的变化。此外与reid中将每一个目标作为独立的输入不同,mot中的输入为整个场景的图片,这使得一体化模型中所有目标共用同一特征图,目标间重叠处特征是相同的。这也意味着reid任务中用来聚合高具有区分性的全局平均池化操作在mot任务中容易引入噪声,并不能提高目标表征能力。技术实现要素:本发明的目的在于克服现有技术的不足,提供一种基于reid特征的强数据关联一体化实时多目标跟踪方法,可以改善在一体化mot框架下多任务的竞争和协同问题,提高不同分支所需的特征表示,以提高在行人多目标跟踪任务中的跟踪性能。为了实现上述发明目的,本发明基于reid特征的强数据关联一体化实时多目标跟踪方法包括以下步骤:s1:构建检测跟踪一体化模型,包括检测器模块、k个不同尺度的互相关网络ccn模块、k个不同尺度的检测头部模块和尺度感知注意力网络saan模块,k表示检测器模块输出的特征图尺度数量,其中:检测器模块用于将输入图像编码为k个不同尺度的高阶语义特征图fk,k=1,2,…,k,然后分别输入至对应尺度的互相关网络ccn模块;互相关网络ccn模块对于对输入的特征图fk进行分离处理,得到特征图gk,1和特征图gk,2,然后将特征图gk,1发送给对应尺度的检测头部模块,将特征图gk,2发送给尺度感知注意力网络saan模块;互相关网络ccn模块包括平均池化层、输入图像维度变换层、第一卷积层、第一维度变换层、第一通道注意力层、第二卷积层、第二维度变换层、第二通道注意力层、第三通道注意力层、第四通道注意力层、第一通道注意力图融合层、第一图像增强层、第三维度变换层、第二通道注意力图融合层、第二图像增强层和第四维度变换层,其中:平均池化层用于对输入的对应尺度的特征图fk进行平均池化操作得到特征图f′k,记特征图fk的大小为ck×hk×wk,其中ck表示特征图fk的通道数量,hk×wk表示特征图fk中单通道特征图的大小,记特征图f′k的大小为ck×h′k×w′k,其中h′k×w′k表示特征图f′k中单通道特征图的大小,h′k<hk且w′k<wk;平均池化层将得到的特征图f′k分别发送给第一卷积层和第二卷积层;输入图像维度变换层用于将输入的大小为ck×hk×wk的特征图fk转换为大小为ck×nk的输入图像数据矩阵f″k,其中nk=hk×wk,然后分别发送给第一图像增强层和第二图像增强层;第一卷积层用于对输入的特征图f′k进行卷积操作得到大小为ck×h′k×w′k的特征图tk,1,然后发送给第一维度变换层;第一维度变换层用于对输入的大小为ck×h′k×w′k的特征图tk,1转换为大小为ck×n′k的数据矩阵mk,1,其中n′k=h′k×w′k,然后发送给第一通道注意力层、第三通道注意力层和第四通道注意力层;第一通道注意力层用于采用行向softmax根据输入的数据矩阵mk,1计算得到大小为ck×ck的通道注意力图wk,1,然后发送给第一通道注意力图融合层,通道注意力图wk,1中每个像素值wk,1(i,j)的计算公式如下:其中,(i,j)表示像素点坐标,i,j=1,2,…,ck,mk,1[i]、mk,1[j]表示数据矩阵mk,1中第i行、第j行向量,exp表示以自然常数e为底的指数函数;第二卷积层用于对输入的特征图f′k采用与第一卷积层不同的参数进行卷积操作得到大小为ck×h′k×w′k的特征图tk,2,然后发送给第二维度变换层;第二维度变换层用于对输入的大小为ck×h′k×w′k的特征图tk,2转换为大小为ck×n′k的数据矩阵mk,2,然后分别发送给第二通道注意力层、第三通道注意力层和第四通道注意力层;第二通道注意力层用于采用行向softmax根据输入的数据矩阵mk,2计算得到大小为ck×ck的通道注意力图wk,2,然后发送给第二通道注意力图融合层,通道注意力图wk,2中每个像素值wk,2(i,j)的计算公式如下:其中,mk,2[i]、mk,2[j]表示数据矩阵mk,2中第i行、第j行向量;第三通道注意力层用于采用行向softmax根据输入的数据矩阵mk,1和数据矩阵mk,2计算得到大小为ck×ck的通道注意力图wk,3,然后发送给第一通道注意力图融合层,通道注意力图wk,3中每个像素值wk,3(i,j)的计算公式如下:第四通道注意力层用于采用行向softmax根据输入的数据矩阵mk,1和数据矩阵mk,2计算得到大小为ck×ck的通道注意力图wk,4,然后发送给第二通道注意力图融合层,通道注意力图wk,4中每个像素值wk,4(i,j)的计算公式如下:第一通道注意力图融合层用于对通道注意力图wk,1和通道注意力图wk,3进行加权融合,得到大小为ck×ck的融合通道注意力图w′k,1,然后发送给第一图像增强层,融合通道注意力图w′k,1的计算公式如下:w′k,1=λkwk,1+(1-λk)wk,3其中,λk表示权重参数;第一图像增强层用于对接收到的大小为ck×nk的输入图像数据矩阵f″k和大小为ck×ck的融合通道注意力图w′k,1进行矩阵乘法,得到大小为ck×nk增强的图像数据矩阵g′k,1=w′k,1·f′k,然后输入至第三维度变换层;第三维度变换层将大小为ck×nk增强的图像数据矩阵g′k,1转换为大小为ck×hk×wk的特征图gk,1,然后发送给对应尺度的检测头部模块;第二通道注意力图融合层用于对通道注意力图wk,2和通道注意力图wk,4进行加权融合,得到大小为ck×ck的融合通道注意力图w′k,2,然后发送给第二图像增强层,融合通道注意力图w′k,2的计算公式如下:w′k,2=λkwk,2+(1-λk)wk,4第二图像增强层用于对接收到的大小为ck×nk的输入图像数据矩阵f″k和大小为ck×ck的融合通道注意力图w′k,2进行矩阵乘法,得到大小为ck×nk增强的图像数据矩阵g′k,2=w′k,2·f′k,然后输入至第四维度变换层;第四维度变换层将大小为ck×nk增强的图像数据矩阵g′k,2转换为大小为ck×hk×wk的特征图gk,2,然后发送给对应尺度的尺度感知注意力网络saan模块;检测头部模块用于对接收到的对应尺度的特征图gk,1进行目标检测,得到该尺度下的目标检测框;尺度感知注意力网络saan模块用于根据接收到的k个特征图gk,2得到目标的reid特征向量;尺度感知注意力网络saan模块包括k个尺度分支处理模块、通道拼接层、通道注意力模块、拼接特征图处理层和特征向量层,其中:尺度分支处理模块用于采用空间注意力机制对对应尺度特征图gk,2进行处理,得到特征图qk,2;尺度分支处理模块包括尺度变换层、卷积层、空间注意力模块、掩膜层,其中尺度变换层用于将大小为ck×hk×wk的特征图gk,2变换至最大尺度,得到大小为的特征图g″k,2,然后发送给卷积层和掩膜层;卷积层用于对特征图g″k,2进行卷积操作得到大小为的特征图pk,2,然后发送给空间注意力模块和掩膜层;空间注意力模块用于对特征图pk,2生成空间注意力的掩膜图maskk,2,然后发送给掩膜层;掩膜层用于采用空间注意力的掩膜图maskk,2对特征图pk,2进行掩膜处理得到特征图qk,2,然后发送给通道拼接层;通道拼接层用于将每个尺度分支处理模块得到的特征图qk,2拼接为大小为的拼接特征图q2,然后发送给通道注意力模块和拼接特征图处理层;通道注意力模块用于根据拼接特征图q2生成维度为的通道注意力向量,发送给拼接特征图处理层;拼接特征图处理层用于计算拼接特征图q2中每个像素点的通道向量与通道注意力向量进行对应元素相乘,然后将所得到的特征图与拼接特征图q2相加,得到特征图q′2,然后发送给特征向量层;特征向量层用于对特征图q′2进行卷积操作得到大小为的特征图i,目标的reid特征即为特征图i中目标像素点的通道向量;s2:根据需要设置训练样本集,对步骤s1构建的跟踪一体化模型进行训练;s3:对于需要进行多目标跟踪的视频序列中的每一帧图像,均采用检测跟踪一体化模型获取当前帧的目标检测结果和reid特征,采用预设的跟踪机制基于目标检测结果和reid特征获取各个目标的跟踪结果。本发明基于reid特征的强数据关联一体化实时多目标跟踪方法,首先构建检测跟踪一体化模型,包括检测器模块、k个不同尺度的互相关网络ccn模块、k个不同尺度的检测头部模块和尺度感知注意力网络saan模块,互相关网络ccn模块对于对检测器模块输出的特征图进行分离处理,得到两个特征图分别输入至检测头部模块和尺度感知注意力网络saan模块进行目标检测和reid特征获取,根据需要设置训练样本集对跟踪一体化模型进行训练,对于需要进行多目标跟踪的视频序列中的每一帧图像,均采用检测跟踪一体化模型获取当前帧的目标检测结果和reid特征,采用预设的跟踪机制基于目标检测结果和reid特征获取各个目标的跟踪结果。本发明采用互相关网络ccn模块将检测和reid解耦为分离分支,提高不同分支所需的特征表示,以提高在行人多目标跟踪任务中的跟踪性能。附图说明图1是本发明基于reid特征的强数据关联一体化实时多目标跟踪方法的具体实施方式流程图;图2是本发明中互相关网络ccn模块的结构图;图3是本发明中尺度感知注意力网络saan模块的结构图;图4是本发明中尺度分支处理模块的结构图;图5是本实施例中空间注意力模块的结构图;图6是本实施例中通道注意力模块的结构图。具体实施方式下面结合附图对本发明的具体实施方式进行描述,以便本领域的技术人员更好地理解本发明。需要特别提醒注意的是,在以下的描述中,当已知功能和设计的详细描述也许会淡化本发明的主要内容时,这些描述在这里将被忽略。实施例图1是本发明基于reid特征的强数据关联一体化实时多目标跟踪方法的具体实施方式流程图。如图1所示,本发明一种基于reid特征的强数据关联一体化实时多目标跟踪方法的具体步骤包括:s101:构建检测跟踪一体化模型:为了解决由于mot任务和reid任务输入差异性造成id特征区分度不足的问题,提高一体化mot模型的数据关联能力,本发明中将检测和reid解耦为分离分支,以此为基础构建检测跟踪一体化模型,包括检测器模块、k个不同尺度的互相关网络ccn(cross-correlationnetwork)模块、k个不同尺度的检测头部(detectionhead)模块和尺度感知注意力网络saan(scale-awareattentionnetwork)模块,k表示检测器模块输出的特征图尺度数量。接下来分别对每个模块进行具体说明。检测器模块用于将输入图像编码为k个不同尺度的高阶语义特征图fk,k=1,2,…,k,然后分别输入至对应尺度的互相关网络ccn模块。检测器模块是本领域的常用模块,且不是本发明的技术发明点,本实施例中选用的检测器模块可以参见参考文献“z.wang,l.zheng,y.liu,ands.wang,“towardsreal-timemulti-objecttracking,”ineuropeanconferenceoncomputervision(eccv),2020.”,其具体原理和实现在此不再赘述。互相关网络ccn模块对于对输入的特征图fk进行分离处理,得到特征图gk,1和特征图gk,2,然后将特征图gk,1发送给对应尺度的检测头部模块,将特征图gk,2发送给尺度感知注意力网络saan模块。互相关网络ccn模块的主要作用是提高不同任务的特征表示,改善了检测和reid任务在一体化mot框架中的协作学习。图2是本发明中互相关网络ccn模块的结构图。如图2所示,本发明中互相关网络ccn模块包括平均池化层、输入图像维度变换层、第一卷积层、第一维度变换层、第一通道注意力层、第二卷积层、第二维度变换层、第二通道注意力层、第三通道注意力层、第四通道注意力层、第一通道注意力图融合层、第一图像增强层、第三维度变换层、第二通道注意力图融合层、第二图像增强层和第四维度变换层,其中:平均池化层用于对输入的对应尺度的特征图fk进行平均池化操作得到特征图f′k,记特征图fk的大小为ck×hk×wk,其中c表示通道数量,hk×wk表示特征图fk中单通道特征图的大小,记特征图f′k的大小为ck×h′k×w′k,其中h′k×w′k表示特征图f′k中单通道特征图的大小,h′k<hk且w′k<wk。平均池化层将得到的特征图f′k分别发送给第一卷积层和第二卷积层。输入图像维度变换层用于将输入的大小为ck×hk×wk的特征图fk转换为大小为ck×nk的输入图像数据矩阵f″k,其中nk=hk×wk,然后分别发送给第一图像增强层和第二图像增强层。第一卷积层用于对输入的特征图f′k进行卷积操作得到大小为ck×h′k×w′k的特征图tk,1,然后发送给第一维度变换层。第一维度变换层用于对输入的大小为ck×h′k×w′k的特征图tk,1转换为大小为ck×n′k的数据矩阵mk,1,其中n′k=h′k×w′k,然后发送给第一通道注意力层、第三通道注意力层和第四通道注意力层。第一通道注意力层用于采用行向softmax根据输入的数据矩阵mk,1计算得到大小为ck×ck的通道注意力图wk,1,然后发送给第一通道注意力图融合层,通道注意力图wk,1中每个像素值wk,1(i,j)的计算公式如下:其中,(i,j)表示像素点坐标,i,j=1,2,…,ck,mk,1[i]、mk,1[j]表示数据矩阵mk,1中第i行、第j行向量,exp表示以自然常数e为底的指数函数。通道注意力图wk,1的主要目的是为了学习该任务的自相关性,即表示自相关权重映射。第二卷积层用于对输入的特征图f′k采用与第一卷积层不同的参数进行卷积操作得到大小为ck×h′k×w′k的特征图tk,2,然后发送给第二维度变换层。第二维度变换层用于对输入的大小为ck×h′k×w′k的特征图tk,2转换为大小为ck×n′k的数据矩阵mk,2,然后分别发送给第二通道注意力层、第三通道注意力层和第四通道注意力层。第二通道注意力层用于采用行向softmax根据输入的数据矩阵mk,2计算得到大小为ck×ck的通道注意力图wk,2,然后发送给第二通道注意力图融合层,通道注意力图wk,2中每个像素值wk,2(i,j)的计算公式如下:其中,mk,2[i]、mk,2[j]表示数据矩阵mk,2中第i行、第j行向量。同样的,通道注意力图wk,2的主要目的也是为了学习该任务的自相关性。第三通道注意力层用于采用行向softmax根据输入的数据矩阵mk,1和数据矩阵mk,2计算得到大小为ck×ck的通道注意力图wk,3,然后发送给第一通道注意力图融合层,通道注意力图wk,3中每个像素值wk,3(i,j)的计算公式如下:第四通道注意力层用于采用行向softmax根据输入的数据矩阵mk,1和数据矩阵mk,2计算得到大小为ck×ck的通道注意力图wk,4,然后发送给第二通道注意力图融合层,通道注意力图wk,4中每个像素值wk,4(i,j)的计算公式如下:通道注意力图wk,3和通道注意力图wk,4的主要目的是为了学习两个不同任务之间的共性,即表示互相关权重映射。本发明通过注意力机制得到自相关和互相关权重图,前者促使隐藏节点学习任务依赖特征,后者可以提高两个任务的协同学习。第一通道注意力图融合层用于对通道注意力图wk,1和通道注意力图wk,3进行加权融合,得到大小为ck×ck的融合通道注意力图w′k,1,然后发送给第一图像增强层,融合通道注意力图w′k,1的计算公式如下:w′k,1=λkwk,1+(1-λk)wk,3其中,λk表示权重参数,具体的值通过训练得到。第一图像增强层用于对接收到的大小为c×n的输入图像数据矩阵f″k和大小为ck×ck的融合通道注意力图w′k,1进行矩阵乘法,得到大小为ck×nk增强的图像数据矩阵g′k,1=w′k,1·f′k,然后输入至第三维度变换层。第三维度变换层将大小为ck×nk增强的图像数据矩阵g′k,1转换为大小为ck×hk×wk的特征图gk,1,然后发送给对应尺度的检测头部模块。第二通道注意力图融合层用于对通道注意力图wk,2和通道注意力图wk,4进行加权融合,得到大小为ck×ck的融合通道注意力图w′k,2,然后发送给第二图像增强层,融合通道注意力图w′k,2的计算公式如下:w′k,2=λkwk,2+(1-λk)wk,4第二图像增强层用于对接收到的大小为ck×nk的输入图像数据矩阵f″k和大小为ck×ck的融合通道注意力图w′k,2进行矩阵乘法,得到大小为ck×nk增强的图像数据矩阵g′k,2=w′k,2·f′k,然后输入至第四维度变换层。第四维度变换层将大小为ck×nk增强的图像数据矩阵g′k,2转换为大小为ck×hk×wk的特征图gk,2,然后发送给对应尺度的尺度感知注意力网络saan模块。检测头部模块用于对接收到的对应尺度的特征图gk,1进行目标检测,得到该尺度下的目标检测框。尺度感知注意力网络saan模块用于根据接收到的k个特征图gk,2得到目标的reid特征向量。尺度感知注意力网络saan模块的主要作用是在mot领域中获取高区分度特征,学习判别不同尺度的嵌入信息并将他们进行聚合,即将空间和通道注意力机制应用于特征,然后通过元素添加将增强的特征合并到原始输入中。空间和通道注意力能够调整在不同尺度上的特征与对象相关的嵌入的关注情况。然后将不同分辨率的特性聚合到单个尺度下进行输出,这有助于学习尺度感知表示。图3是本发明中尺度感知注意力网络saan模块的结构图。如图3所示,本发明中尺度感知注意力网络saan模块包括k个尺度分支处理模块、通道拼接层、通道注意力模块、拼接特征图处理层和特征向量层,其中:尺度分支处理模块用于采用空间注意力机制对对应尺度特征图gk,2进行处理,得到特征图qk,2。图4是本发明中尺度分支处理模块的结构图。如图4所示,本发明中尺度分支处理模块包括尺度变换层、卷积层、空间注意力模块、掩膜层,其中:尺度变换层用于将大小为ck×hk×wk的特征图gk,2变换至最大尺度,得到大小为的特征图g″k,2,然后发送给卷积层。显然,即为最大尺度特征图的大小,采用这种方式即可将不同尺度的特征图进行尺度统一。卷积层用于对特征图g″k,2进行卷积操作得到大小为的特征图pk,2,然后发送给空间注意力模块和掩膜层。卷积层的作用是对特征图进行编码,以便后续操作。本实施例中采用3×3的卷积操作。空间注意力模块用于对特征图pk,2生成空间注意力的掩膜图maskk,2,然后发送给掩膜层。图5是本实施例中空间注意力模块的结构图。如图5所示,本实施例中空间注意力模块包括最大池化层、平均池化层、通道拼接层、卷积层和sigmoid层,其中最大池化层和平均池化层分别用于对特征图pk,2进行最大池化和平均池化得到特征图,将得到的两个特征图发送给通道拼接层,通道拼接层对两个特征图进行通道拼接后发送至卷积层;卷积层用于对输入的特征图进行卷积操作,将得到的特征图发送至sigmoid层;sigmoid层用于对输入的特征图采用sigmoid函数进行处理,得到掩膜图maskk,2。掩膜层用于采用空间注意力的掩膜图maskk,2对特征图pk,2进行掩膜处理得到特征图qk,2,然后发送给通道拼接层。本实施例中掩膜处理的具体过程为:将掩膜图maskk,2与特征图pk,2中单个通道的图像进行对应像素点相乘,将得到的图像再和该单个通道图像进行对应像素点相加,从而得到特征图qk,2。本发明中采用空间注意力机制来获取掩膜图并进行处理,主要为了借助空间注意力机制对每个尺度的特征图在空间上做权重调制,使得每个目标在不同尺度下获得的关注不同,以增强目标相关特征、抑制背景噪声,从而缓解mot任务中目标尺寸变化大和目标重叠问题。通道拼接层用于将每个尺度分支处理模块得到的特征图qk,2拼接为大小为的拼接特征图q2,然后发送给通道注意力模块和拼接特征图处理层。通道注意力模块用于根据拼接特征图q2生成维度为的通道注意力向量,发送给拼接特征图处理层。通道注意力层是通过注意力机制学习对每一个特征语义通道的注意力权重,实现对通道关注度的调节。图6是本实施例中通道注意力模块的结构图。如图6所示,本实施例中通道注意力模块包括平均池化层、最大池化层、共享卷积层、共享全连接层、求和运算层和sigmoid层,其中最大池化层和平均池化层分别用于对特征图q2进行最大池化和平均池化得到特征向量并发送给共享卷积层;共享卷积层分别对两个特征向量进行卷积操作并发送给共享全连接层;共享全连接层分别对输入的两个特征向量进行处理后发送给求和运算层;求和运算层将输入的两个特征向量进行相加后发送给sigmoid层;sigmoid层用于对输入的特征向量采用sigmoid函数进行处理,得到通道注意力向量。拼接特征图处理层用于计算拼接特征图q2中每个像素点的通道向量与通道注意力向量进行对应元素相乘,然后将所得到的特征图与拼接特征图q2相加,得到特征图q′2,然后发送给特征向量层。特征向量层用于对特征图q′2进行卷积操作得到大小为的特征图i,目标的reid特征即为特征图i中目标像素点的通道向量,其中c′的大小根据需要设置。s102:训练检测跟踪一体化模型:根据需要设置训练样本集,对步骤s101构建的跟踪一体化模型进行训练。为了方便比较,本实施例中使用了和jde相同的6个行人目标数据集混合成一个大数据集进行训练,他们分别是:eth,cityperson,caltech,mot17,cudk-sysu,prw。其中eth和cityperson只有行人检测标签标注,另外四个数据集可以提供检测和id信息的标注。此外,还引入了crowdhuman数据集,以便获得更好的跟踪性能。在指标评价方法,采用了clearmetric中提出来的mota来评价跟踪性能,采用了idf1来评价id的匹配情况,用fps来评价模型的实时性。在训练参数上,先迁移了在coco数据集上预训练的模型参数来初始化检测跟踪一体化模型。在训练模型时采用sgd作为优化器,初始化学习率为0.005,在第20次迭代的时候将学习率将为0.0005,之后训练到第30个迭代结束训练。batchsize的设定为10,在一张rtx2080tigpu上训练了30个小时。s103:实时多目标跟踪:对于需要进行多目标跟踪的视频序列中的每一帧图像,均采用检测跟踪一体化模型获取当前帧的目标检测结果和reid特征,采用预设的跟踪机制基于目标检测结果和reid特征获取各个目标的跟踪结果。具体的跟踪机制可以根据实际需要进行设置,本实施例中沿用了jde的跟踪机制,其对视频序列的跟踪过程简述如下:1)通过本发明中的检测跟踪一体化模型获取当前帧检测结果和reid特征,根据设置的置信度筛选检测框和检测框对应的reid特征。2)通过计算当前帧的reid特征和之前已存在序列的reid特征的余弦距离,构建度量矩阵。3)融合运动特征,计算卡尔曼滤波与当前检测直接的距离,如果距离过大则将度量矩阵中的距离设置为无限大,这是考虑不存在太大的位移情况,接着将卡尔曼滤波预测的结果和特征的结果进行距离加权,获得考虑了运动状态的度量矩阵。4)执行匈牙利算法(linear_assignment)获得匹配结果,将匹配成功的序列激活。5)没有激活成功的序列进入iou匹配。通过序列的最新帧和当前帧的框计算iou,如果iou高于阈值则匹配成功,低于阈值则设置当前帧检测为新的序列。没有匹配上的序列将进入未激活状态,如果多次未激活则认为目标已经不在该场景中,完成该序列的跟踪。为了更好地说明本发明的技术效果,将本发明与mot16和mot17上的其他最先进的在线跟踪方法进行了比较验证。对比方法大致分为两类,第一类是两阶段方法,包括deepsort、rar16wvgg、tap、cnnmtt和poi。第二类是联合检测和跟踪的一体化方法,有jde、ctrackerv1、tubetk和centertrack。表1是本次比较验证中本发明和各对比方法在mot16和mot17上的跟踪性能对比表。表1表1中标示“*”的方法为联合检测和跟踪的一体化方法,mota表示跟踪的准确度,它用于衡量三个量错误检测,遗漏检测和目标间的错误切换,idf1表示目标正确识别的检测与真实标签和计算得到的检测的平均数之比,mt表示表示轨迹重合率超过80%的目标在总轨迹数中的占比,ml表示轨迹重合率低过20%的目标在总轨迹数中的占比,ids表示表示获得的轨迹在不同轨迹之间切换的次数,fps表示方法的整体(检测加关联)运行时间。如表1所示,本发明在mot16和mot17两个基准的私有检测器赛道上实现了新的最先进得分,即mot16的70.7和mot17的70.6。值得注意的是,与其他所有联合检测和跟踪的一体化方法相比,本发明显著提高了数据关联能力,即idf1在mot16上提高了12.4个点~16.0个点,在mot17上提高了11.7个点~14.2个点。此外,本发明数据关联能力与两阶段方法相当,但是具有更快的推理速度。由于在mot任务中检测器模块多目标跟踪算法的最终性能影响很大,为了进行公平比较并探究本发明方法的上限所在,本次对比验证中还采用了真实标签(groundtruth,gt)的检测结果替代检测器的检测结果,在mot16的训练集上做的实验。表2是本次比较验证中采用真实标签后本发明和各对比方法在mot16的跟踪性能对比表。methodmota↑idf1↑idp↑idr↑ids↓jde97.687.688.386.9871deepsort_298.995.695.995.393本发明98.996.697.196.1162表2如表2所示,本发明方法与jde相比idf1提高了9个点,同时ids大量减少,仅仅为原来的18.6%。此外,本发明方法的idf1评分超过了广泛使用的两阶段方法deepsort-2。这进一步验证了本发明方法具有很强的扩展性,在检测器性能高的情况可以获得更加优异的多目标跟踪效果。尽管上面对本发明说明性的具体实施方式进行了描述,以便于本
技术领域:
的技术人员理解本发明,但应该清楚,本发明不限于具体实施方式的范围,对本
技术领域:
的普通技术人员来讲,只要各种变化在所附的权利要求限定和确定的本发明的精神和范围内,这些变化是显而易见的,一切利用本发明构思的发明创造均在保护之列。当前第1页12
相关技术
网友询问留言
已有0条留言
- 还没有人留言评论。精彩留言会获得点赞!
1